
论文原址:https://arxiv.org/abs/1409.1556
代码原址:https://github.com/machrisaa/tensorflow-vgg
摘要
本文主要分析卷积网络的深度对基于大数据集分类任务中准确率的影响,本文使用较小的卷积核(3x3), 应用至较深的网络中并进行评估,将网络中的深度增加至16至19层,可以有效改进分类效果。
介绍
卷积网络在大规模图片/视频分类任务中取得巨大成功的原因主要有,(1)大规模的图像数据,像ImageNet(2)高性能的计算资源(GPU)。
存在大量改善分类效果的尝试,其中一种是,通过设置网络中的第一层卷积以较小的步长及感受野的大小来改善分类性能。另一种是对与训练测试过程中,对整张图片进行密集处理,从而可以得到多尺寸的信息。而本文主要从网络的结构-深度下手,具体实现为,通过固定其他的参数,逐渐增加网络的深度,其中,所有层的卷积核的大小为3x3,因此实现上具有灵活性。
卷积网络的配置
本文主要是分析网络的深度对性能的影响,因此,网络中每层的设计都是相同的。
1 结构:训练时,卷积网络的固定输入大小为224x224的RGB图像。本文唯一的预处理方式为对训练集中的每个像素进行减均值处理。图片在一系列卷积核大小为3x3(具有较小的感受野)的卷积层中进行传递。利用1x1的卷积核对输入的通道数进行线性变换。卷积核的stride固定为1个像素。卷积的padding设置为1,因此,可以使卷积前后的分辨率得以保留。最大池化层的大小为2x2,stride为2。一系列的卷积层后面跟随的为三个全连接层。前两个每个通道数为4096,第三个全连接层包含1000个通道,代表ILSVRC中的类别数,最后一层为多分类的soft-max 层。网络中的隐藏层添加ReLU进行非线性处理。本文中为使用LRN,原因是发现LRN不仅不能改进ILSVRC分类性能,同时,还会占用大量的内存及计算时间。
2配置:网络的设计及参数如下图
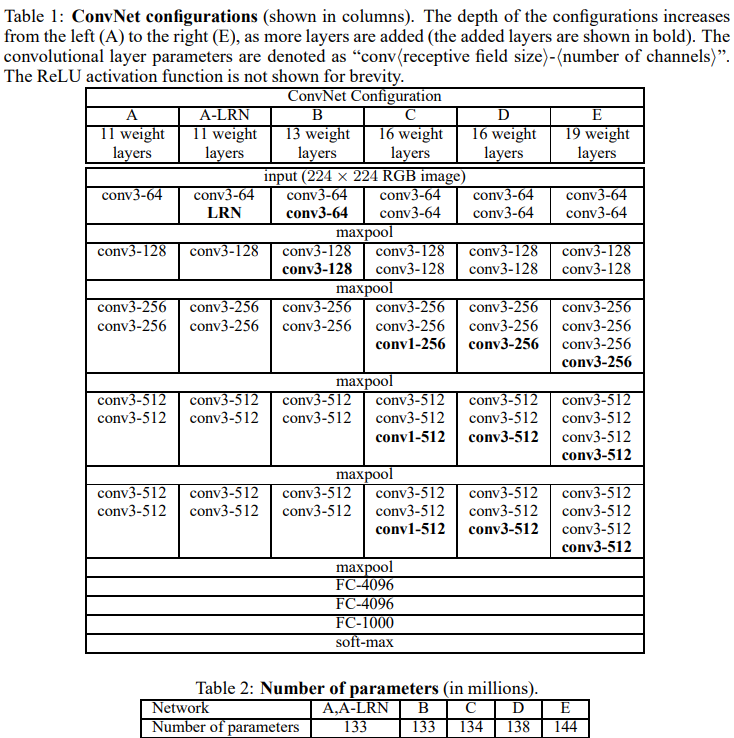
3讨论:以前的网络使用较大感受野的卷积核(比如7x7,stride为2或者11x11,stride为4),本文整个网络中使用的都为感受野较小的的卷积核(3x3),与输入中的每个像素进行卷积操作。两个大小为3x3的卷积效果上等价与一个5x5的卷积核,三个3x3的卷积核等价于一个7x7的卷积核。上述做法的好处有两点:(1)结合三个非线性层,而不是一个,可以使决策函数更易区分。(2)减少参数的数量,对于三个3x3的卷积层,输入输出的通道数都为C,参数量为3(3*3*C^2),同时,一个7x7的大小的卷积核为49C^2,比前面要多81%。因此,上述操作可以看作是在7x7的卷积核中通过3x3的卷积核引入正则化处理。1x1的卷积可以在不影响卷积感受野的情况下,增加决策函数的非线性。虽然1x1的卷积本质上为相同维度上的线性映射,但通过正则化函数引进非线性。本文特点之一是将小的卷积核应用至更深的网络中。
分类框架
训练:优化目标为多项式的逻辑回归,使用带动量的mini-batch梯度下降法,batch的大小设置为256,动量为0.9。权重基于L2正则化进行惩罚。在前两个全连接层中增加dropout。初始化学习率为0.01。本文中的网络可以提前收敛的原因有:(a)通过更深的层数及更小的卷积核来增加隐式的正则化。(b)网络关键层的初始化。
网络权重的初始化十分重要,由于深度网络中的梯度不稳定性,本文现在较浅层的网络中进行随机初始化训练,后在更深的网络层中基于随机初始化进行训练。因此,较差的初始化会妨碍学习,随机量服从均值为0,方差为0.01的正态分布,偏差初始化为0。在网络进行学习时,进行学习率的衰减。采用随机裁剪的方式对输入图片进行规范化处理。使用随机水平翻转及彩色变换对数据进行增强。
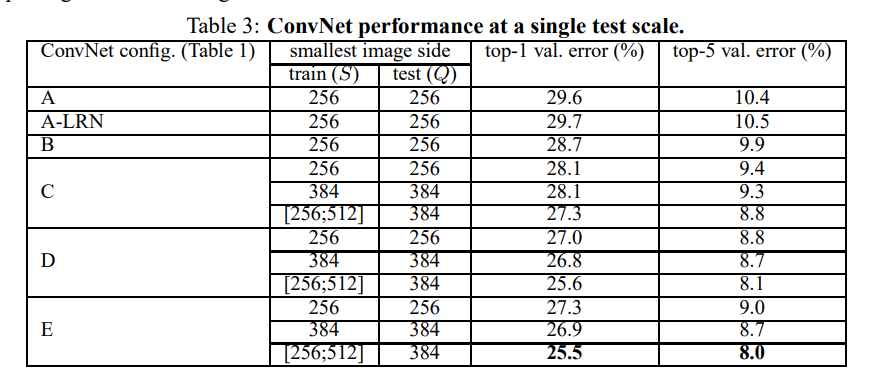
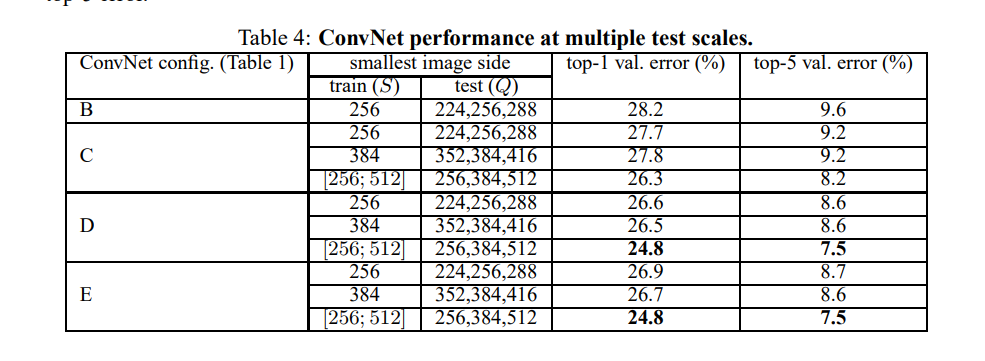
训练图片的大小:本文对数据集中的图片大小采用两个尺寸,一个为256,另一个为384,首先基于256的尺寸图片进行训练。为了加速训练384的网络,选择在256上预训练的网络得到的权重来初始化384的网络,同时,初始学习率设置为0.001。另一种方法是,多尺寸训练。每次训练的图片被单独调整为【256,512】中的一个尺寸。由于图像中的目标物存在不同的尺寸大小,因此,尺寸信息在网络训练时是值得考虑的。通过在一个单尺寸模型上(尺寸大小为384)进行微调得到多尺寸的网络模型。
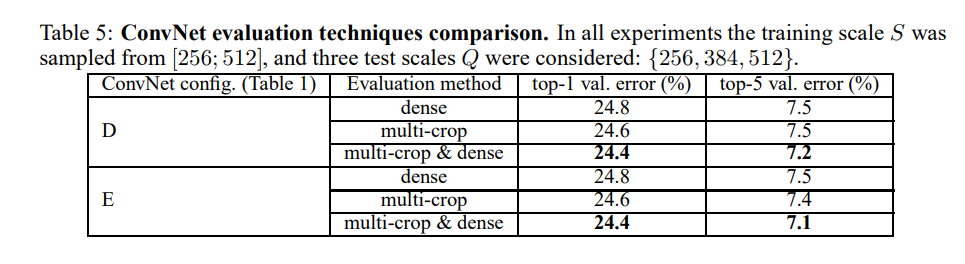
测试:给定训练好的模型及输入图片,首先,调整尺寸至网络预定义的最小尺寸。然后,网络作用于调整后的图片。全连接层首先变化为全卷积层(第一个全连接层的大小为7x7,剩下的两个全连接层设置为1x1),得到一个全卷积网络,然后,将此网络作用至整张图片上(未进行裁剪的图片),得到一个通道数为类别数,分辨率与输入图片大小对应尺寸的的类别score map。最后,为了得到关于此图片的类别分数的固定向量。对score map进行空间均值池化操作。同时,对测试图片也采用了相同的水平反转操作进行数据扩充。对于一张图片,原始的图片及反转的图片得到的soft-max类别先验取平均作为该图最终的分数。
由于全卷积网络作用于整个图片,因此,测试时并不需要进行裁剪操作。同时,使用大量的裁剪图可以提高准确率。因为相比全卷积网络,对输入图片可以进行更适合的采样。由于不同的卷积边界的条件,多样性裁剪评估对于密集测试十分重要。当卷积网络作用于一个crop时,卷积后得到的feature maps用0进行padding,然而当进行密集测试时,对crop进行padding,本质上来自于图片中的相邻区域,由于卷积和池化操作增加了整个网络的感受野,可以捕捉更多的上下文信息。但本文认为实际上多尺寸的crops在计算时间上的消耗并不能证明准确率上有潜在的增益。
实验

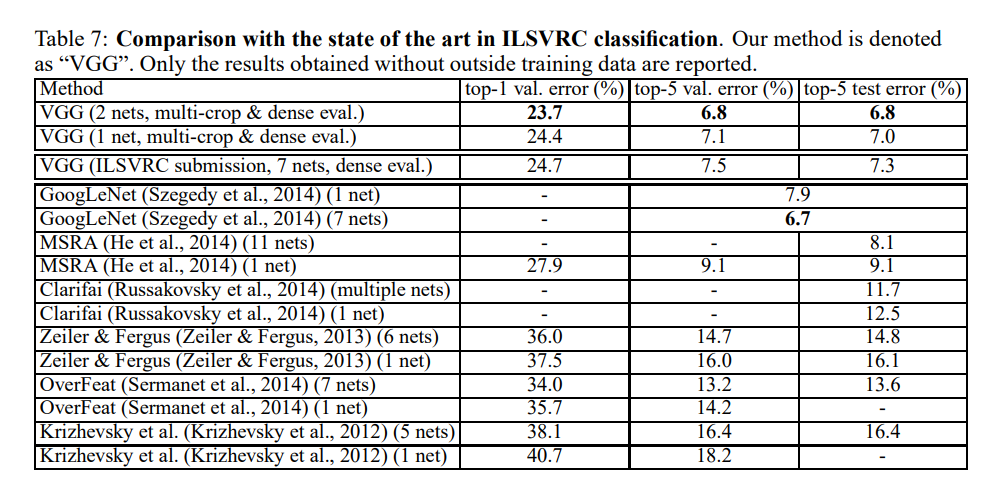
Reference
[1]Bell, S., Upchurch, P., Snavely, N., and Bala, K. Material recognition in the wild with the materials in context database. CoRR, abs/1412.0623, 2014.
[2]Chatfield, K., Simonyan, K., Vedaldi, A., and Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proc. BMVC., 2014.
[3]Cimpoi, M., Maji, S., and Vedaldi, A. Deep convolutional filter banks for texture recognition and segmentation. CoRR, abs/1411.6836, 2014.