辅助排序和二次排序案例(GroupingComparator)
1.需求
有如下订单数据
|
订单id |
商品id |
成交金额 |
|
0000001 |
Pdt_01 |
222.8 |
|
0000001 |
Pdt_05 |
25.8 |
|
0000002 |
Pdt_03 |
522.8 |
|
0000002 |
Pdt_04 |
122.4 |
|
0000002 |
Pdt_05 |
722.4 |
|
0000003 |
Pdt_01 |
222.8 |
|
0000003 |
Pdt_02 |
33.8 |
现在需要求出每一个订单中最贵的商品。
2.数据准备
GroupingComparator.txt
Pdt_01 222.8 Pdt_05 722.4 Pdt_05 25.8 Pdt_01 222.8 Pdt_01 33.8 Pdt_03 522.8 Pdt_04 122.4
输出数据预期:


3 222.8
2 722.4
1 222.8
3.分析
(1)利用“订单id和成交金额”作为key,可以将map阶段读取到的所有订单数据按照id分区,按照金额排序,发送到reduce。
(2)在reduce端利用groupingcomparator将订单id相同的kv聚合成组,然后取第一个即是最大值。
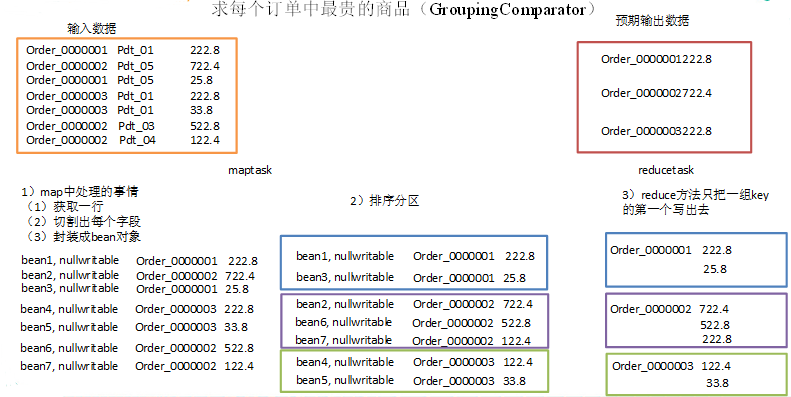
4.实现
定义订单信息OrderBean
package com.xyg.mapreduce.order; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class OrderBean implements WritableComparable<OrderBean> { private int order_id; // 订单id号 private double price; // 价格 public OrderBean() { super(); } public OrderBean(int order_id, double price) { super(); this.order_id = order_id; this.price = price; } @Override public void write(DataOutput out) throws IOException { out.writeInt(order_id); out.writeDouble(price); } @Override public void readFields(DataInput in) throws IOException { order_id = in.readInt(); price = in.readDouble(); } @Override public String toString() { return order_id + " " + price; } public int getOrder_id() { return order_id; } public void setOrder_id(int order_id) { this.order_id = order_id; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } // 二次排序 @Override public int compareTo(OrderBean o) { int result = order_id > o.getOrder_id() ? 1 : -1; if (order_id > o.getOrder_id()) { result = 1; } else if (order_id < o.getOrder_id()) { result = -1; } else { // 价格倒序排序 result = price > o.getPrice() ? -1 : 1; } return result; } }
编写OrderSortMapper处理流程
package com.xyg.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class OrderMapper extends Mapper<LongWritable, Text, OrderBean, NullWritable> {
OrderBean k = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 截取
String[] fields = line.split(" ");
// 3 封装对象
k.setOrder_id(Integer.parseInt(fields[0]));
k.setPrice(Double.parseDouble(fields[2]));
// 4 写出
context.write(k, NullWritable.get());
}
}
编写OrderSortReducer处理流程
package com.xyg.mapreduce.order;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class OrderReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
编写OrderSortDriver处理流程
package com.xyg.mapreduce.order; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class OrderDriver { public static void main(String[] args) throws Exception, IOException { // 1 获取配置信息 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 设置jar包加载路径 job.setJarByClass(OrderDriver.class); // 3 加载map/reduce类 job.setMapperClass(OrderMapper.class); job.setReducerClass(OrderReducer.class); // 4 设置map输出数据key和value类型 job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); // 5 设置最终输出数据的key和value类型 job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); // 6 设置输入数据和输出数据路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 10 设置reduce端的分组 job.setGroupingComparatorClass(OrderGroupingComparator.class); // 7 设置分区 job.setPartitionerClass(OrderPartitioner.class); // 8 设置reduce个数 job.setNumReduceTasks(3); // 9 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } OrderSortDriver
编写OrderSortPartitioner处理流程
package com.xyg.mapreduce.order;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
public class OrderPartitioner extends Partitioner<OrderBean, NullWritable> {
@Override
public int getPartition(OrderBean key, NullWritable value, int numReduceTasks) {
return (key.getOrder_id() & Integer.MAX_VALUE) % numReduceTasks;
}
}
编写OrderSortGroupingComparator处理流程
package com.xyg.mapreduce.order;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderGroupingComparator extends WritableComparator {
protected OrderGroupingComparator() {
super(OrderBean.class, true);
}
@SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean aBean = (OrderBean) a;
OrderBean bBean = (OrderBean) b;
int result;
if (aBean.getOrder_id() > bBean.getOrder_id()) {
result = 1;
} else if (aBean.getOrder_id() < bBean.getOrder_id()) {
result = -1;
} else {
result = 0;
}
return result;
}
}