前面已经爬取了代理,今天我们使用Selenium&PhantomJS的方式爬取快代理 :快代理 - 高速http代理ip每天更新。
首先分析一下快代理,如下
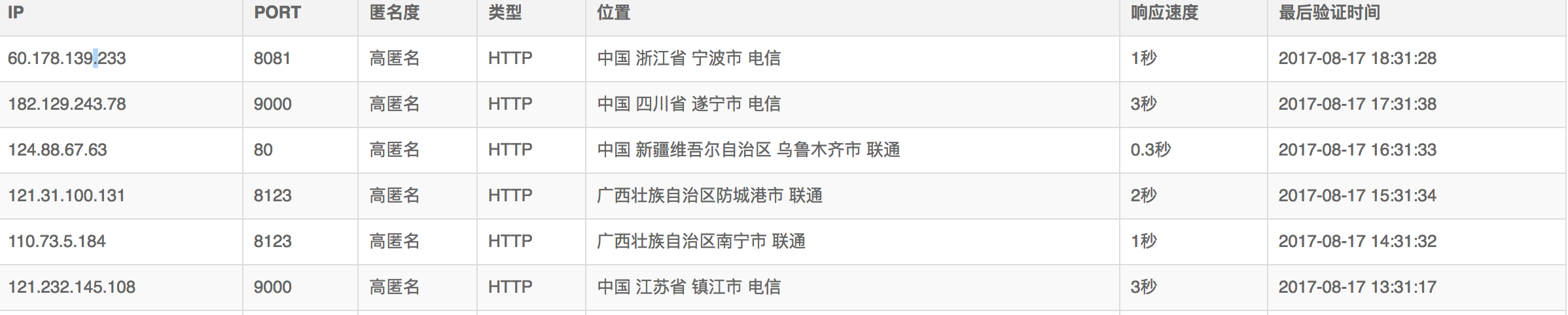
使用谷歌浏览器,检查,发现每个代理信息都在tr里面,每个tr里面包含多个td,就是IP的信息。
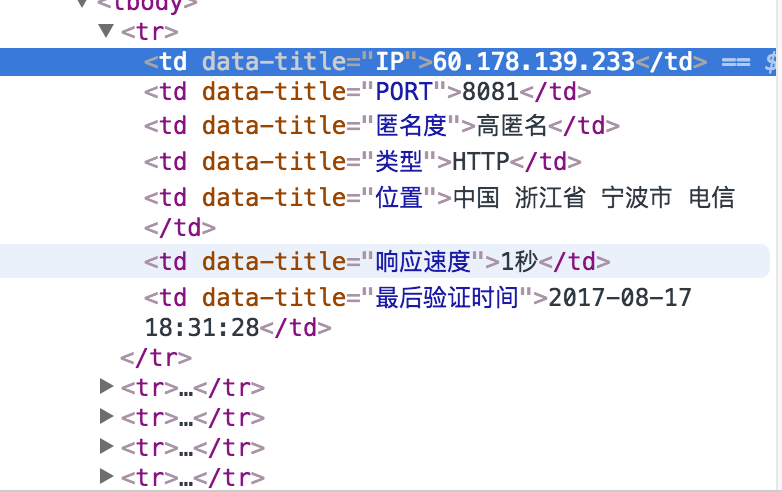
这个结构我们可以通过多种方法抓取,例如bs4、xpath、selenium等
这里我们演示selenium方法。具体解释在下面代码中都有的。
1 from selenium import webdriver 2 3 class Item(object): 4 ''' 5 模拟scrapy框架 6 写item类 7 用以表示每个代理 8 ''' 9 ip = None #IP地址 10 port = None #端口 11 anonymous = None #是否匿名 12 type = None #http 或者https 13 local = None #物理地址 14 speed = None #速度 15 16 class GetProxy(object): 17 def __init__(self): 18 self.starturl = 'http://www.kuaidaili.com/free/inha/' 19 self.urls = self.get_urls() 20 self.proxylist = self.get_proxy_list(self.urls) 21 self.filename = 'proxy.txt' 22 self.saveFile(self.filename,self.proxylist) 23 24 25 def get_urls(self): 26 ''' 27 :return: 返回代理url列表 28 ''' 29 urls = [] 30 for i in range(1,3): 31 url = self.starturl + str(i) 32 urls.append(url) 33 return urls 34 35 def get_proxy_list(self,urls): 36 ''' 37 爬取代理列表 38 :param urls: 39 :return: 40 ''' 41 browser = webdriver.PhantomJS() 42 proxy_list = [] 43 44 for url in urls: 45 browser.get(url) # 通过get方法打开 46 browser.implicitly_wait(3) 47 elements = browser.find_elements_by_xpath('//tbody/tr') #找到每个代理的位置 48 for element in elements: 49 item = Item() 50 item.ip = element.find_element_by_xpath('./td[1]').text 51 item.port = element.find_element_by_xpath('./td[2]').text 52 item.anonymous = element.find_element_by_xpath('./td[3]').text 53 item.local = element.find_element_by_xpath('./td[4]').text 54 item.speed = element.find_element_by_xpath('./td[5]').text 55 print(item.ip) 56 proxy_list.append(item) 57 58 browser.quit() 59 return proxy_list 60 61 def saveFile(self,filename,proxy_list): 62 ''' 63 将爬取的信息保存到本地 64 :param filename: 65 :param proxy_list: 66 :return: 67 ''' 68 with open(filename,'w') as f: 69 for item in proxy_list: 70 f.write(item.ip + ' ') 71 f.write(item.port + ' ') 72 f.write(item.anonymous + ' ') 73 f.write(item.local + ' ') 74 f.write(item.speed + ' ') 75 76 if __name__ == '__main__': 77 Get = GetProxy()
下面我们展示一下爬取的结果

如果用到代理的话,还需要对这些IP进行测试一下。