基于贝叶斯公式:P(y|x) = P(y) * P(x | y) / p(x)
具体业务场景描述如下,用于分类问题。
我现在有训练集,每个训练集可以转换为一个特征值的向量Vec = [.........]和一个标签(是否是垃圾邮件,是否点击,是否患病等)
现在我们要基于训练集来预测新的特征值输进来之后应该给它一个怎样的标签。朴素贝叶斯是对于新数据,预测其输出为ci的一个概率,最后从这些ci中找到最大的,那个标签作为标签。
比如情感分析:
ci 有c1:positive c2 negative两种
我现在有word vector及其色彩:
vec1:[1,0,1,0,0,0,0,0] p
vec2:[0,1,1,0,0,0,0,0] n
vec3:[1,1,0,0,0,0,0,0] p
vec4:[0,0,0,1,1,1,1,1] n
我现在需要根据vec1 vec2 vec3 vec4预测新来的一个vec:[0,0,1,0,1,1,0,1]应该是p还是n
那么我们就预测 p(ci=p|vec) 和 p(ci=n|vec)看看哪个大,怎么计算这个值呢?利用贝叶斯公式:
p(ci|vec) = p(ci) * p(vec | ci) / p(vec)。分母都会涉及,所以这里就先不管。
p(ci)是一个已知值,根据训练数据就可以得到。
p(vec | ci) = p((vec[0],vec[1],vec[2],vec[3],vec[4],vec[5],vec[6],vec[7])|ci)
假设独立,这也是为什么叫“朴素”
p(vec | ci) = p(vec[0]|ci) * p(vec[1]|ci) *p(vec[2]|ci) *p(vec[3]|ci) *p(vec[4]|ci) *p(vec[5]|ci) *p(vec[6]|ci) * p(vec[7]|ci);
这些条件概率值都可以从训练集中得到,所以就可以得到哪个分类标签的概率大。
一些Tricks:
可能出现下溢问题,可以通过对概率取对数来解决。
获得word vector的时候,如果简单的出现与否,叫词集模型(set of words),如果是记出现的次数的话,叫做词袋模型(bag of words)
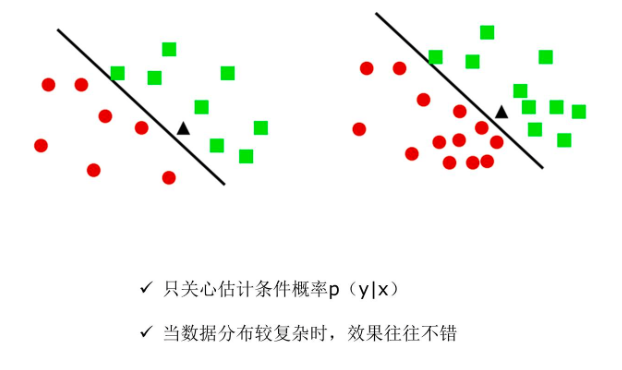
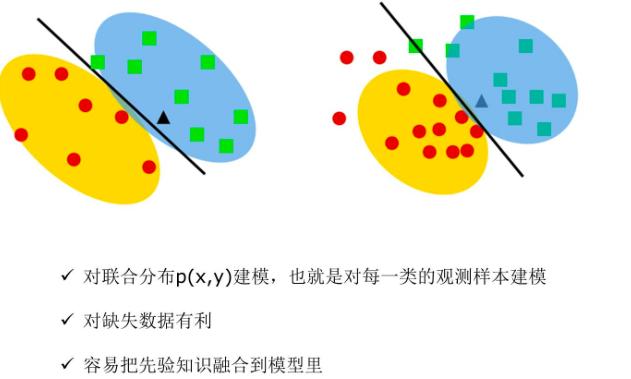
Tips: 朴素贝叶斯与Logistic回归的区别:
朴树贝叶斯是生成模型。
逻辑回归是判别模型。
还不是太清楚两者的区别,一个简单例子:比如判别一个人是男是女:
判别模型比较care男女的区别
生成模型是从男人这个整体的我去思考有什么特征这样子。