进程的描述和进程的创建-分析Linux内核创建一个新进程的过程
符钰婧 原创作品转载请注明出处
《Linux内核分析》MOOC课http://mooc.study.163.com/course/USTC-1000029000
这次的实验是围绕着fork函数对应的系统调用处理过程来进行的。
一、首先简单阅读理解一下task_struct数据结构(配图为视频截图):
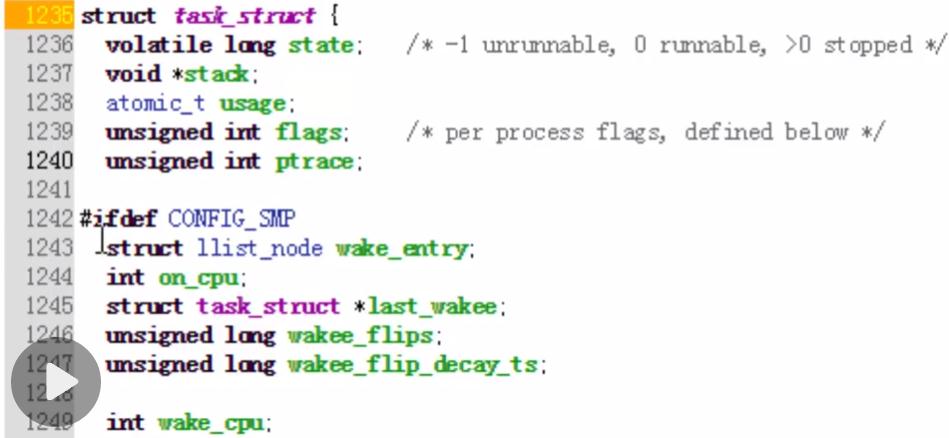
1236行【state】表示进程状态;
1237行【stack】指定了内核的进程堆栈;
1242行【SMP】是一个条件编译,多处理器时用到;

这一段代码和进程调度相关

1295行【tasks】进程链表(双向循环链表);

管理进程地址空间;
*可简单的认为:每一个进程都有自己独立的进程地址空间。

进程的父子关系(可用图直观表示)
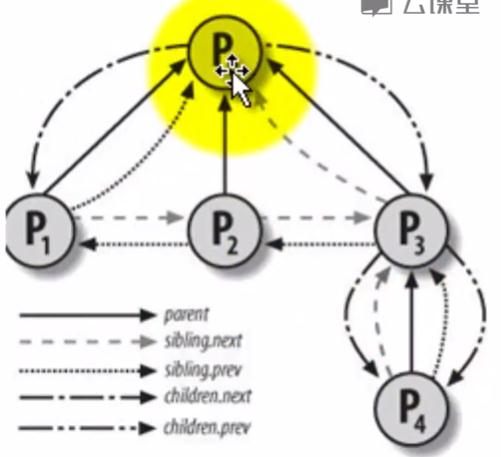
P0有三个儿子P1、P2、P3;P1有两个兄弟;P3有一个儿子。

当前任务CPU相关的状态。在进程上下文切换的时候起着关键性的作用。
二、接下来分析fork函数对应的内核处理过程sys_clone。
虽然使用的是sys_clone函数,但最终调用的还是do_fork
do_fork的内容:

这是fork的主要例程
其中有一个copy_process:

这是创建一个进程内容的主要代码

这里的if语句都是一些出错处理
进入复制:

把数据结构src加个*表示它的值,然后赋给dst

内核堆栈就是由thread_info和堆栈两个合在一起的union;
所以上面的代码就是alloc了一个内核堆栈。
实际的代码:
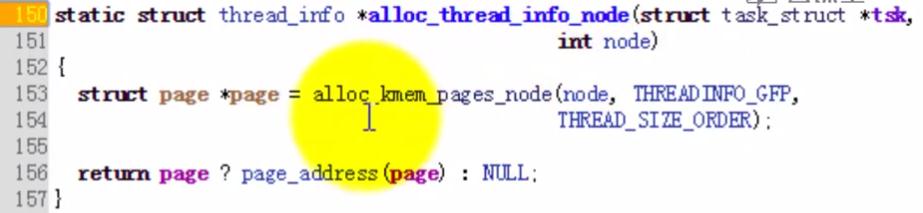
153行表示创建了两个一定大小的页(内存)
创建的页面一部分用来存放thread_info,另一部分就是内核堆栈;
这一段代码做了实际分配内核空间的效果。

这个函数也是做了一个复制的工作

回到这个位置,p指向的是进程的PCB;
代码的后面有大量修改进程的内容(初始化)。
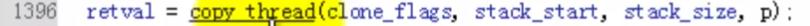
这是理解的关键。
在copy_thread的时候都做了些什么:

从子进程pid(内核堆栈)的位置找到了栈空间的地址;
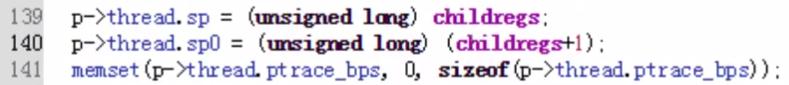
然后赋给了栈底;
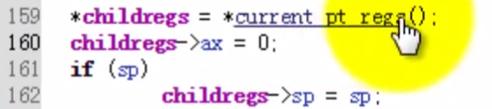
这里做的是内核堆栈中已有数据的拷贝和制定新进程的第一条指令地址;

同时还复制了thread.ip的值。
ip指向的是ret_from_fork,也就是说子进程是从这个位置开始执行的。
在复制内核堆栈的时候只复制了SAVE_ALL相关的一部分内容:

其中的内容为int指令和SAVE_ALL压到内核栈的内容。
系统调用的总控程序:

子进程从290行开始执行,此时它的内核堆栈只有一点内容;
然后进入298行:

之后内核堆栈继续执行,然后正常的返回到用户态。
三、用gdb跟踪分析sys_clone
(1)先把menu删掉,然后克隆一份新的
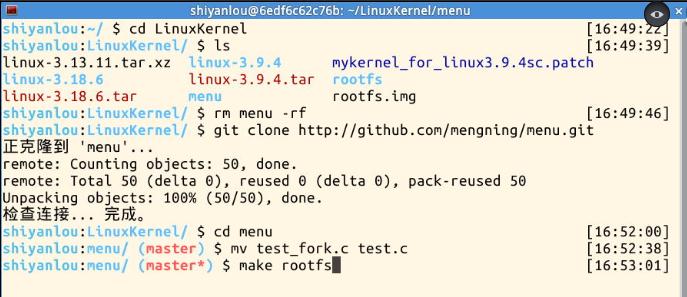
然后用test_fork.c将test.c覆盖掉,然后make_rootfs。
(2)进行编译可看到增加了fork指令
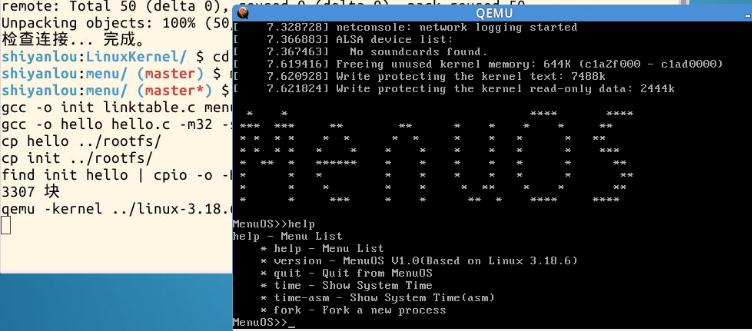
(3)进行gdb调试(准备工作)

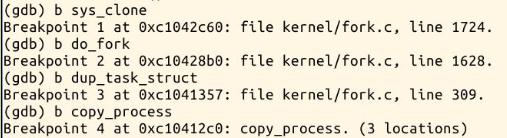
(4)设断点

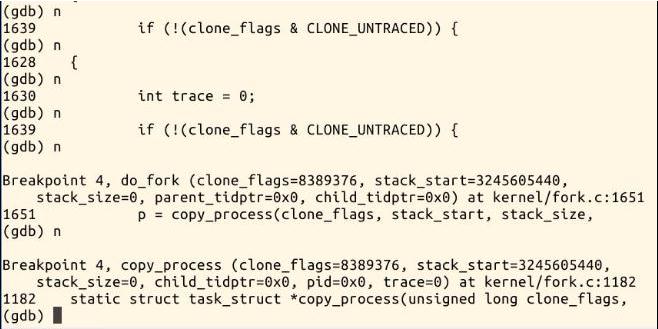
(5)按c执行,可看到执行到do_fork处

(6)按n可执行到copy_process
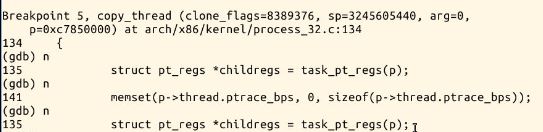
(7)之后进入了dup_task_struct:

(8)继续执行可到copy_thread
之后可跟踪到ret_form_fork,单步执行直到结束。
四、总结
当子进程获得cpu控制权开始运行的时候,它的ret_from_fork可以做一系列工作,然后返回到用户态;
此时的进程已经不是原来父进程的进程空间了。
---恢复内容结束---