查询优化应该是数据库领域最难的topic
当前查询优化,主要有两种思路,
Rules-based,基于先验知识,用if-else把优化逻辑写死
Cost-based,试图去评估各个查询计划的cost,选取cost比较小的
一个sql query的处理流程,
先是Parser,生成抽象语法树ast,Binder会去做元数据对应,把parse出来的name对应到数据库中的结构,表,字段等
然后Rewriter就是Rules-based的改写,而Optimizer是cost-based的优化


Relational Algebra Equivalences
做查询优化的前提是,查询的结果是不能变的
无论你查询怎么优化,最终得到的结果是一样的,那么就称他们是,关系代数等价
对于不同的operator,有些通用的优化rules,
这里给些例子,
Selections
对于selection,尽量下推,谓词下推,尽量早做


Projections
projection也是应该尽早去做,不需要的字段就根本不用读出来

Joins
对于Join是符合交换律和结合律的,但是对于多表join,你需要尝试的可能性是非常多的

Cost Estimation
cost-based的查询优化,关键就是要能够知道cost
如何预估cost是很复杂的问题
当前的思路,就是我们会事先对数据表,列,索引做些统计,并存储到catalog里面,然后后面就根据这些统计数据来预估cost


主要的统计数据,包含两项,行数和每一列的distinct values的个数
然后有个概念,selection cardinality,两个相除,就是平均每个value多少行
这里的假设是数据是均匀分布,很naive


有了这些概念,我们就可以来定义复杂谓词,操作,的selectivity,筛选率

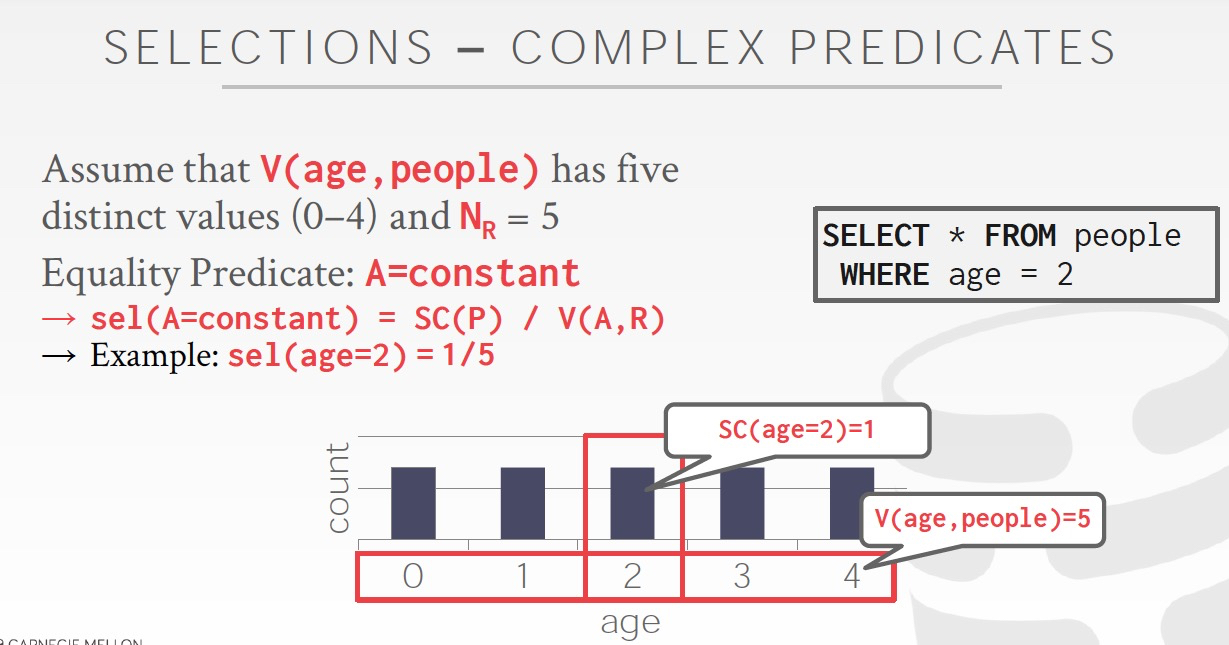
Equality,Range
Equality的定义有些confuse,SC(P),SC(age=2)啥意思?
其实以range的逻辑看,这里就应该是,A列一共有5个值,当前Equality只取其中一个,所以五分之一,就这么简单


Conjunction和Disjunction
右图中,应该是 - sel(P1 交 P2)


Join,对于join,这个cost算的很粗糙,比如R表中的行数 * 每行在S中的cardinality

平均分布问题
当前算cost,都是假设平均分布,这个明显是很不合理的
但是如果对于每个value都去记录一个统计,明显不可行,太多了
所以有如下几种近似方法,
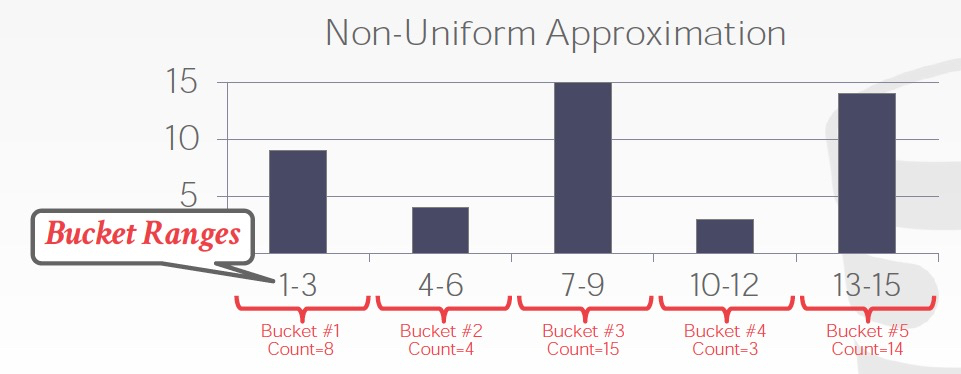
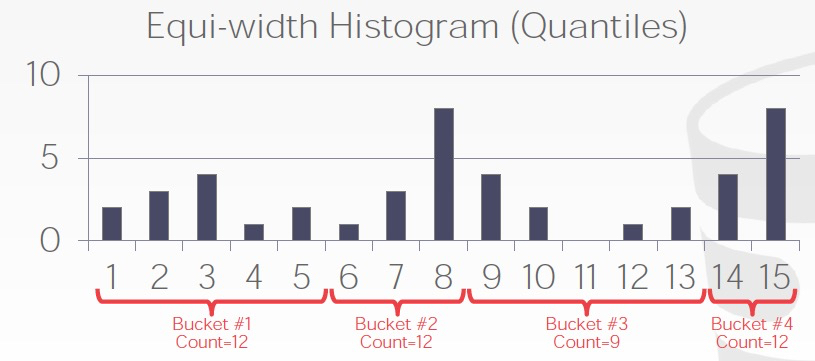
一种,每个value bucket都去统计太多,那就分组,这样每个组记录一个统计,组内仍然假设平均分布
分组可以有两种方式,第一个是固定bucket数,或者固定组内bucket统计和差不多,叫等宽
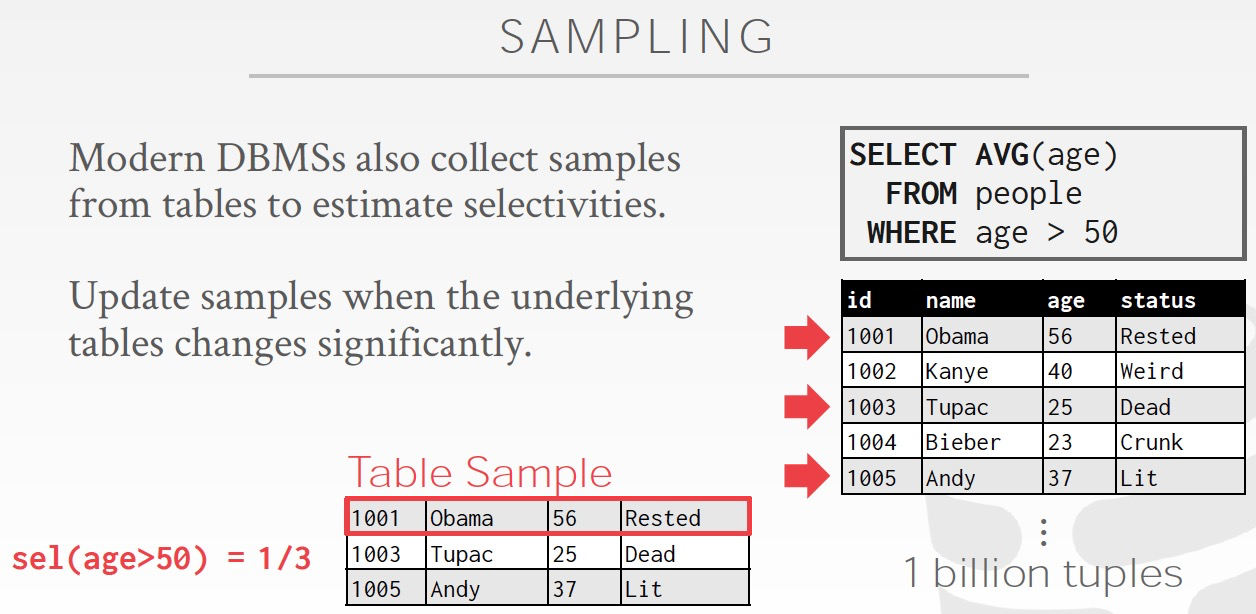
还有种更直接的方式,sampling
Query Optimization
上面说的cost estimation的方法都很naive,但是如果我们能准确的预估执行计划的cost,那么如何真正的做查询优化?
这里分为三种情况,
Single Relation,Multiple relations, Nested Sub-queries
Single Relation,比较简单,单关系表的查询
所以关键就是选择合理的access method,是顺序扫描,还是用各种索引
这里有个概念,sargable,数据库专有概念,意思是查询或执行计划可以用索引来优化的
OLTP的查询往往都是sargable的,所以通过简单的启发式的方式就可以找到优化方法


Multiple relations
多关系表join就比较复杂了
除了要选择各个表的access method
还需要选择各个表的join顺序和join算法
其中选择join顺序是个cost很高的事情,因为可能性和search space会比较的大
这里介绍IBM R的方法,它把join顺序简化成,只考虑Left-deep tree(右图最左边这个)
这样search space会大幅缩小,另外特意选择left-deep tree的原因是,这种join结构,比较容易pipeline执行,比如下图,a b的join结果直接可以用于和c join,当中间结果不是很大的时候,不需要不断地的把结果写到磁盘


对于Multiple relations,可以尝试用动态规划来选择best plan



更为形象的例子来说明如何逐步筛选plan
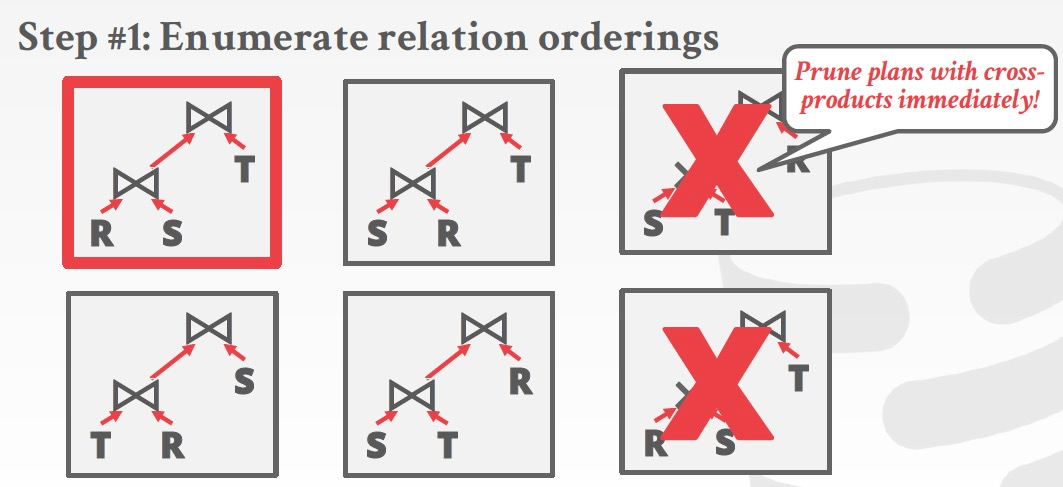
第一步是选择join的顺序,可以首先把明显低效的,比如做cross-products的Prune掉
然后根据cost model找出best的plan
第二步是选择join算法,这里有Nested Loop和Hash Join

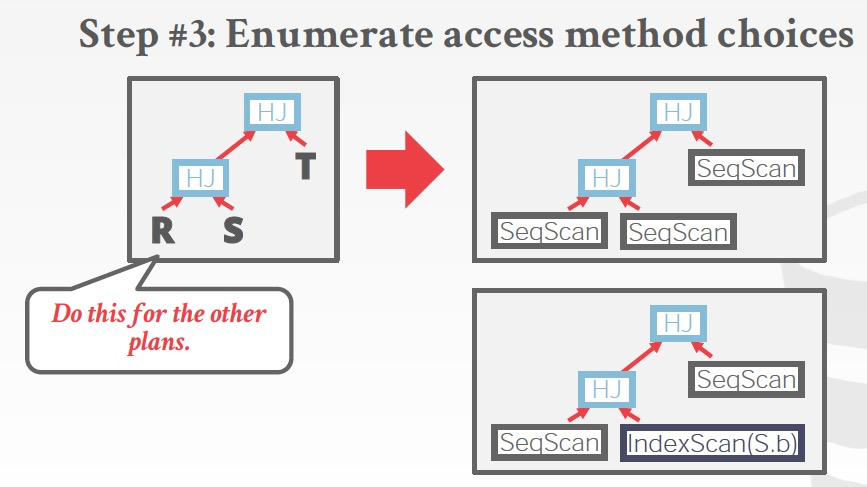
第三步是选择access method,
Nested Sub-queries
第三种更为复杂一些,在有子SQL的时候,如何优化?
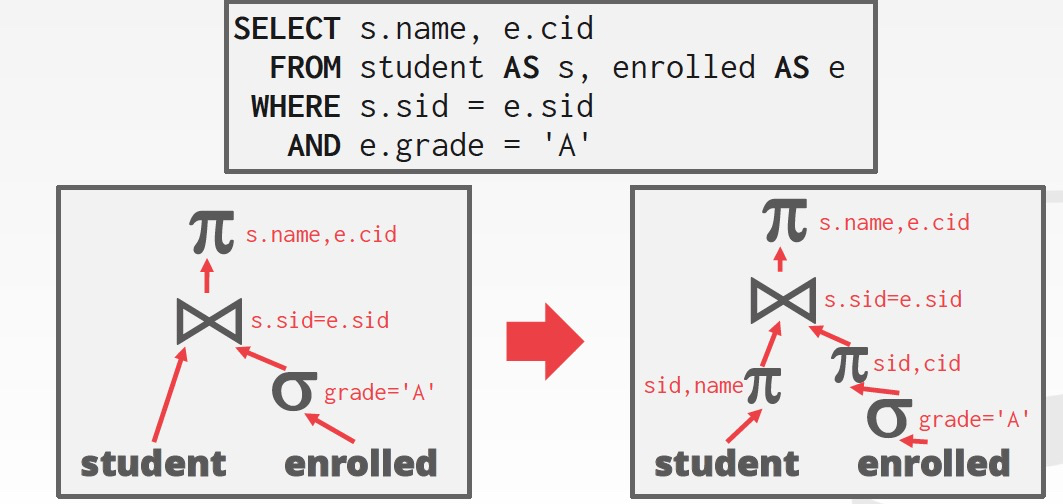
有两种方式,一种是通过rewrite,把嵌套的子语句flatten掉,如右图的例子


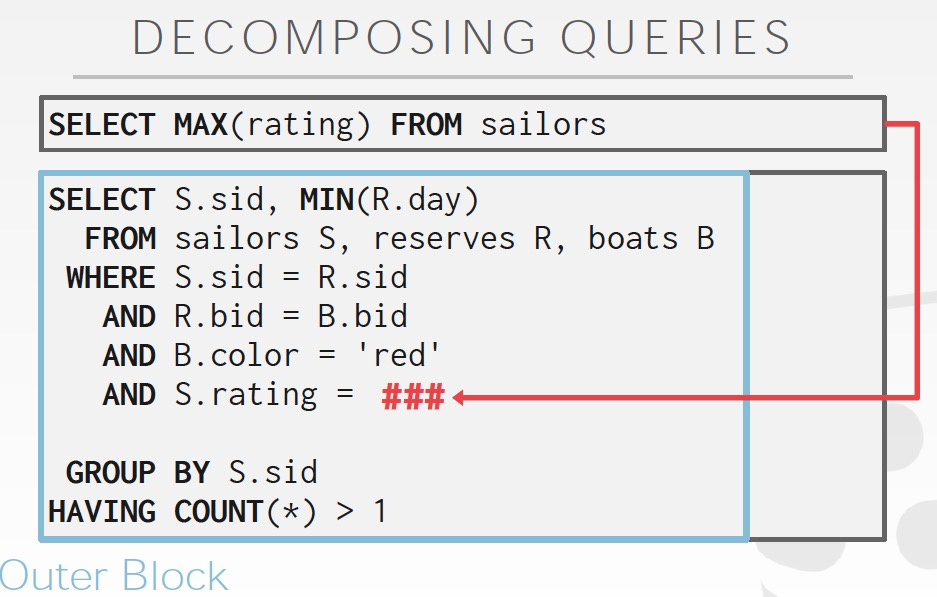
另一种方法,是decompose,如下面的例子
子句是要获取最大的rating,这个反复去执行一定是低效的,所以,干脆把这个语句拿出来单独执行,结果放在临时表,然后执行主语句的时候把值填回去