INTRODUCTION
面对的问题,3个方面,
In modern distributed cloud services, resilience and scalability are increasingly achieved by decoupling compute from storage [10][24][36][38][39] and by replicating storage across multiple nodes.
Doing so lets us handle operations such as replacing misbehaving or unreachable hosts, adding replicas, failing over from a writer to a replica, scaling the size of a database instance up or down, etc.
为了resilience and scalability, 在云服务中,将计算和存储分离,成为一种趋势
The I/O bottleneck faced by traditional database systems changes in this environment.
Since I/Os can be spread across many nodes and many disks in a multi-tenant fleet, the individual disks and nodes are no longer hot.
Instead, the bottleneck moves to the network between the database tier requesting I/Os and the storage tier that performs these I/Os.
数据的瓶颈从磁盘io变成网络io,这是大部分分布式平台的现状
Although most operations in a database can overlap with each other, there are several situations that require synchronous operations. These result in stalls and context switches.
数据库有很多同步操作会造成高延迟,比如由于cache miss导致的读盘,transaction commit时的多阶段提交
Aurora的架构简介
In this paper, we describe Amazon Aurora, a new database service that addresses the above issues by more aggressively leveraging the redo log across a highly-distributed cloud environment.
We use a novel service-oriented architecture (see Figure 1) with a multi-tenant scale-out storage service that abstracts a virtualized segmented redo log and is loosely coupled to a fleet of database instances.
Aurora的几个关键词,只同步redo log,计算和存储分离,将存储当作多租户的scale-out服务,redo log以segment为单位,可快速恢复
Although each instance still includes most of the components of a traditional kernel (query processor, transactions, locking, buffer cache, access methods and undo management)
several functions (redo logging, durable storage, crash recovery, and backup/restore) are off-loaded to the storage service.
这样的好处,就是将分布式issue,durable storage, crash recovery, and backup/restore这些问题丢给存储service
那么db层,就大大简化,只需要关心数据库自己的事情,query processor, transactions, locking, buffer cache, access methods and undo management
这样的架构的好处,
可以看出分别对应于上面的3个问题,

所以下面的思路,就是如何用这些方法,解决这3个问题的,

DURABILITY AT SCALE
Replication and Correlated Failures

逻辑是,由于Instance的lifetime 和 storage的lifetime是无关的,所以应该解耦合开
但是由于storage和磁盘也会故障,所以一般都需要replicated,来保证存储本身的Durability

Replicated一般可以使用quorum-based的方法,最常用的使用3副本的方式
但是Amazon说3副本是不够的,大体的意思是,如果3副本,当一个AZ当掉的情况下,很容易导致不可用
Availability Zone (AZ) in AWS. An AZ is a subset of a Region that is connected to other AZs in the region through low latency links but is isolated for most faults, including power, networking, software deployments, flooding, etc.
AZ可以认为是故障独立单元,一个AZ的故障不会影响到另外一个AZ
所以比较保险的方式是,保证AZ+1节点不可用,不影响写;一个AZ不可用不影响读
We achieve this by replicating each data item 6 ways across 3 AZs with 2 copies of each item in each AZ.
We use a quorum model with 6 votes (V = 6), a write quorum of 4/6 (Vw = 4), and a read quorum of 3/6 (Vr = 3).
With such a model, we can (a) lose a single AZ and one additional node (a failure of 3 nodes) without losing read availability,
and (b) lose any two nodes, including a single AZ failure and maintain write availability.
Ensuring read quorum enables us to rebuild write quorum by adding additional replica copies.
Aurora的策略3 AZ,6副本,一个AZ两个副本
4副本可用可写,3副本可用可读
一个可用区+一个副本fail,仍然可读;一可用区fail,可写
Segmented Storage
是否我们提供AZ+1就可以保证足够的Durability?不是的,我们还需要满足下面的条件
To provide sufficient durability in this model, one must ensure the probability of a double fault on uncorrelated failures (Mean Time to Failure – MTTF) is sufficiently low over the time it takes to repair one of these failures (Mean Time to Repair –MTTR).
MTTF需要远小于MTTR,说白了我们需要比较小的恢复时间,否则还没恢复,另一个又挂了
那么我们如何降低MTTR?
思路就是把恢复的单元变的足够小
We do so by partitioning the database volume into small fixed size segments, currently 10GB in size.
These are each replicated 6 ways into Protection Groups (PGs) so that each PG consists of six 10GB segments, organized across three AZs, with two segments in each AZ.
A storage volume is a concatenated set of PGs, physically implemented using a large fleet of storage nodes that are provisioned as virtual hosts with attached SSDs using Amazon Elastic Compute Cloud (EC2).
The PGs that constitute a volume are allocated as the volume grows.
We currently support volumes that can grow up to 64 TB on an unreplicated basis.
将volume 分成10G大小的segment,
用Protection Group来管理6个segments,即六个副本,跨3个可用区,PG即逻辑segment
而volume就由PG和segments组成,最大可以到64TB
Segments are now our unit of independent background noise failure and repair.
We monitor and automatically repair faults as part of our service. A 10GB segment can be repaired in 10 seconds on a 10Gbps network link.
所以segments作为独立的恢复单元,在10G网络下,恢复只需要10秒
THE LOG IS THE DATABASE
The Burden of Amplified Writes
Our model of segmenting a storage volume and replicating each segment 6 ways with a 4/6 write quorum gives us high resilience.
Unfortunately, this model results in untenable performance for a traditional database like MySQL that generates many different actual I/Os for each application write.
The high I/O volume is amplified by replication, imposing a heavy packets per second (PPS) burden.
Also, the I/Os result in points of synchronization that stall pipelines and dilate latencies.
While chain replication and its alternatives can reduce network cost, they still suffer from synchronous stalls and additive latencies.
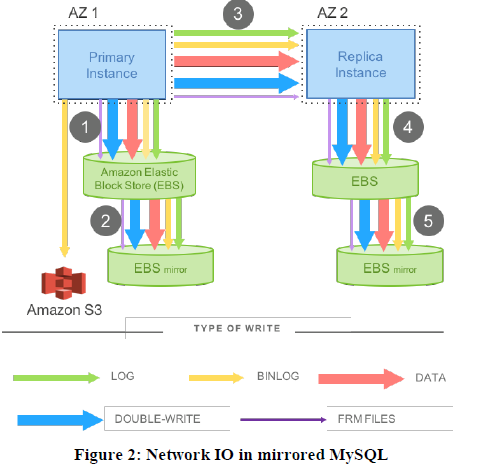
前面说,Aurora采用6副本,这会大大增加IO的负担,IO问题又会导致进一步的stall和高延迟
这里先看下,普通的同步 mirrored mysql是怎么更新数据的,
可以看到mysql的写入是非常重的,要写入data page和WAL日志
还需要写入,binlog,data page double write,meta
并且这些数据还需要在mirror之间同步,这个IO的代价太高了

Offloading Redo Processing to Storage
When a traditional database modifies a data page, it generates a redo log record and invokes a log applicator that applies the redo log record to the in-memory before-image of the page to produce its after-image.
Transaction commit requires the log to be written, but the data page write may be deferred.
但是通过观察,其实传统数据库,在做transaction commit的时候,只是要求log被写入,data page的写入可以deferred
所以这里提出Aurora最核心的思路,log即数据库,这样数据库只需要管写入,并等待log完成同步既可以commit
In Aurora, the only writes that cross the network are redo log records.
No pages are ever written from the database tier, not for background writes, not for checkpointing, and not for cache eviction.
Instead, the log applicator is pushed to the storage tier where it can be used to generate database pages in background or on demand.
Aurora在网络上只会传输redo log,而replay log,cp等机制都放到storage层
这样虽然aurora有那么多的副本,但是IO的负担反而要比传统数据库小很多
Of course, generating each page from the complete chain of its modifications from the beginning of time is prohibitively expensive.
We therefore continually materialize database pages in the background to avoid regenerating them from scratch on demand every time.
预先replay机制,不然查询来了再生成page,不现实
Note that background materialization is entirely optional from the perspective of correctness: as far as the engine is concerned, the log is the database, and any pages that the storage system materializes are
simply a cache of log applications.
很流行的观点,数据库的本质是log,而不是物化表,物化表只是优化只是cache

Let’s examine crash recovery. In a traditional database, after a crash the system must start from the most recent checkpoint and replay the log to ensure that all persisted redo records have been applied.
In Aurora, durable redo record application happens at the storage tier, continuously, asynchronously, and distributed across the fleet.
Any read request for a data page may require some redo records to be applied if the page is not current.
As a result, the process of crash recovery is spread across all normal foreground processing. Nothing is required at database startup.
Aurora恢复成本很小,因为log是持久化的,而log是数据库的本质,所以startup的时候,不用做特别的事情;
关键Aurora的实例是无状态的,状态的维护交给storage tier,但是这样storage tier就复杂了,问题只是转移了,并没有被解决
Storage Service Design Points
A core design tenet for our storage service is to minimize the latency of the foreground write request.
We move the majority of storage processing to the background.
Storage Service设计的目标,尽量降低前端写请求的延迟
所以把大量的工作多放到异步去做

Let’s examine the various activities on the storage node in more detail.
As seen in Figure 4, it involves the following steps:
(1) receive log record and add to an in-memory queue,
(2) persist record on disk and acknowledge,
(3) organize records and identify gaps in the log since some batches may be lost,
(4) gossip with peers to fill in gaps,
(5) coalesce log records into new data pages,
(6) periodically stage log and new pages to S3,
(7) periodically garbage collect old versions,
(8) periodically validate CRC codes on pages.
Note that not only are each of the steps above asynchronous, only steps (1) and (2) are in the foreground path potentially impacting latency.
完成前两步,就可以ack用户;
如果有六副本,这个log会同时发送到6个storage node,只有大于4个ack,才算写成功
3,4步,因为写的时候,有成功有不成功,这里要同步把空洞补上
5,产生cache 表,便于查询
6,相当于checkpoint把cache表存入S3
THE LOG MARCHES FORWARD
Solution sketch: Asynchronous Processing
Since we model the database as a redo log stream, we can exploit the fact that the log advances as an ordered sequence of changes.
In practice, each log record has an associated Log Sequence Number (LSN) that is a monotonically increasing value generated by the database.
Aurora单点写入,所以很容易保证产生递增id
其实这里没paper写的那么复杂,很简单,Aurora如何保证一致性?为何不用2PC或其他的分布式一致性协议?
一句话,因为它有master
一致性的关键是排序,你都已经由master把每个log的LSN生成了,那还有啥一致性问题
并且每个节点写入的时候,是需要通过gossip来fill gaps的,保证写入的数据是连续
后面的问题就如果node挂了,恢复的时候怎么保证各个节点的一致性?
首先,没有写成功的log需要truncated掉,比如只写了少数派,这里就是VCL point
再者,考虑transaction,Aurora如何保证事务的原子性,通过CPL,CPL就是各个transaction的边界,最大完成的CPL就是VDL
所以虽然有些log是写成功了,但是为了保证事务的原子性,还是要truncated掉
This lets us simplify a consensus protocol for maintaining state by approaching the problem in an asynchronous fashion instead of using a protocol like 2PC which is chatty and intolerant of failures.
At a high level, we maintain points of consistency and durability, and continually advance these points as we receive acknowledgements for outstanding storage requests.
The storage service determines the highest LSN for which it can guarantee availability of all prior log records (this is known as the VCL or Volume Complete LSN). During storage recovery, every
log record with an LSN larger than the VCL must be truncated.
The database can, however, further constrain a subset of points that are allowable for truncation by tagging log records and identifying them as CPLs or Consistency Point LSNs.
We therefore define VDL or the Volume Durable LSN as the highest CPL that is smaller than or equal to VCL and truncate all log records with LSN greater than the VDL.
For example, even if we have the complete data up to LSN 1007, the database may have declared that only 900, 1000, and 1100 are CPLs, in which case, we must truncate at 1000. We are complete to 1007, but only durable to 1000.
VCL是这个volume全局一致性点,VCL之后一定要trunc掉的
Aurora会将transaction切分成mini-transaction,如果mini-transaction是100条,要不全成功,要不全失败,所以可以定每100一个CPL点,这样就以mini-transaction作为恢复点,而不是单条的record
而VDL就是最大的CPL点,当然一定是小于等于VCL的,那么每次将VDL后面的数据trunc掉,就可以保证一定trunc在CPL上
“mini transaction” (MTR). An MTR is a construct only used inside InnoDB and models groups of operations that must be executed atomically (e.g., split/merge of B+-Tree pages)
On recovery, the database talks to the storage service to establish the durable point of each PG and uses that to establish the VDL and then issue commands to truncate the log records above VDL.
Normal Operation
Writes
In Aurora, the database continuously interacts with the storage service and maintains state to establish quorum, advance volume durability, and register transactions as committed.
For instance, in the normal/forward path, as the database receives acknowledgements to establish the write quorum for each batch of log records, it advances the current VDL.
At any given moment, there can be a large number of concurrent transactions active in the database, each generating their own redo log records.
The database allocates a unique ordered LSN for each log record subject to a constraint that no LSN is allocated with a value that is greater than the sum of the current VDL and a constant called the LSN Allocation Limit (LAL) (currently set to 10 million). This limit ensures that the database does not get too far ahead of the storage system and introduces back-pressure that can throttle the incoming writes if the storage or network cannot keep up.
同时在db上会有大量的trancations在并行的运行
产生的LSN和当前的VDL比,差值不能大于一个阈值LAL(10 million),目的是防止db接受的transaction领先存储太多,其实就是一种反压机制;
Note that each segment of each PG only sees a subset of log records in the volume that affect the pages residing on that segment.
Each log record contains a backlink that identifies the previous log record for that PG.
These backlinks can be used to track the point of completeness of the log records that have reached each segment to establish a Segment Complete LSN (SCL) that identifies the greatest LSN below which all log records of the PG have been received. The SCL is used by the storage nodes when they gossip with each other in order to find and exchange log records that they are missing.
每个segment都只能看到和自己的数据pages相关的log,这样的问题是,log的id可能不连续
所以log之间通过backlink相关联,这样可以明确知道,每个log的前后log的id是什么,判断是否有空洞,并且用SCL来表示,最大没有空洞的point,SCL之后的需要等Gossip,否则不能apply成data page
Commits
In Aurora, transaction commits are completed asynchronously.
When a client commits a transaction, the thread handling the commit request sets the transaction aside by recording its “commit LSN” as part of a separate list of transactions waiting on commit and moves on to perform other work. The equivalent to the WAL protocol is based on completing a commit, if and only if, the latest VDL is greater than or equal to the transaction’s commit LSN.
As the VDL advances, the database identifies qualifying transactions that are waiting to be committed and uses a dedicated thread to send commit acknowledgements to waiting clients.
Worker threads do not pause for commits, they simply pull other pending requests and continue processing
transaction commit完全异步
提交一个transaction的时候,会异步的把该record的LSN作为commit LSN放在等待列表里面;最终当latest VDL大于或等于该commit LSN时;说明该transaction的redo log已经被持久化
已经被commit,可以ack clients
Reads
In Aurora, as with most databases, pages are served from the buffer cache and only result in a storage IO request if the page in question is not present in the cache.
If the buffer cache is full, the system finds a victim page to evict from the cache.
In a traditional system, if the victim is a “dirty page” then it is flushed to disk before replacement.
This is to ensure that a subsequent fetch of the page always results in the latest data.
传统数据库,在淘汰cache的时候,会把脏页刷回磁盘;而aurora却不需要
While the Aurora database does not write out pages on eviction (or anywhere else), it enforces a similar guarantee: a page in the buffer cache must always be of the latest version.
The guarantee is implemented by evicting a page from the cache only if its “page LSN” (identifying the log record associated with the latest change to the page) is greater than or equal to the VDL.
淘汰page LSN大于VDL的页,大于VDL可能是脏数据,因为这个node ack写请求后,会更新本地的cache,但在这个写可能没有达到多数派ack,失败了;
The database does not need to establish consensus using a read quorum under normal circumstances.
When reading a page from disk, the database establishes a read-point, representing the VDL at the time the request was issued.
The database can then select a storage node that is complete with respect to the read point, knowing that it will therefore receive an up to date version.
A page that is returned by the storage node must be consistent with the expected semantics of a mini-transaction (MTR) in the database.
Since the database directly manages feeding log records to storage nodes and tracking progress (i.e., the SCL of each segment), it normally knows which segment is capable of satisfying a read (the segments whose SCL is greater than the read-point) and thus can issue a read request directly to a segment that has sufficient data.
正常情况下,不会用quorum读的方式,可以采用更有效的方式
在发生读请求的时候,建立read-point,就是当时的VDL;这样数据库只要选择一个SCL大于VDL的segment去读就可以保证读到正确数据;
Given that the database is aware of all outstanding reads, it can compute at any time the Minimum Read Point LSN on a per-PG basis.
If there are read replicas the writer gossips with them to establish the per-PG Minimum Read Point LSN across all nodes.
This value is called the Protection Group Min Read Point LSN (PGMRPL) and represents the “low water mark” below which all the log records of the PG are unnecessary.
In other words, a storage node segment is guaranteed that there will be no read page requests with a read-point that is lower than the PGMRPL.
Each storage node is aware of the PGMRPL from the database and can, therefore, advance the materialized pages on disk by coalescing the older log records and then safely garbage collecting them.
DB可以知道所有的外部读,对于每个PG,可以算一个Minimum Read Point LSN (PGMRPL);即一个low water mark,可以认为没有读的read point会低于PGMRPL,这样就可以把一些过期的page gc掉
Replicas
In Aurora, a single writer and up to 15 read replicas can all mount a single shared storage volume.
As a result, read replicas add no additional costs in terms of consumed storage or disk write operations.
To minimize lag, the log stream generated by the writer and sent to the storage nodes is also sent to all read replicas.
In the reader, the database consumes this log stream by considering each log record in turn. If the log record refers to a page in the reader's buffer cache, it uses the log applicator to apply the specified redo operation to the page in the cache. Otherwise it simply discards the log record. Note that the replicas consume log records asynchronously from the perspective of the writer, which acknowledges user commits independent of the replica.
The replica obeys the following two important rules while applying log records:
(a) the only log records that will be applied are those whose LSN is less than or equal to the VDL
(b) the log records that are part of a single mini-transaction are applied atomically in the replica's cache to ensure that the replica sees a consistent view of all database objects. In practice, each replica typically lags behind the writer by a short interval (20 ms or less).
对于aurora,单点写,但可以最多有15个读副本,并且他们是共享一个shared storage volume,所以增加读副本并不会增加太多成本;
这里为了降低读写副本之间的lag,做个优化,就是writer在写存储的同时,也会将log发给读副本;
这里只会发送LSN小于等于VDL的log;
Recovery
Most traditional databases use a recovery protocol such as ARIES [7] that depends on the presence of a write-ahead log (WAL) that can represent the precise contents of all committed transactions.
These systems also periodically checkpoint the database to establish points of durability in a coarse-grained fashion by flushing dirty pages to disk and writing a checkpoint record to the log.
On restart, any given page can either miss some committed data or contain uncommitted data.
Therefore, on crash recovery the system processes the redo log records since the last checkpoint by using the log applicator to apply each log record to the relevant database page.
This process brings the database pages to a consistent state at the point of failure after which the in-flight transactions during the crash can be rolled back by executing the relevant undo log records.
Crash recovery can be an expensive operation. Reducing the checkpoint interval helps, but at the expense of interference with foreground transactions.
No such tradeoff is required with Aurora.
传统数据库依赖WAL和checkpoint来做恢复,基本方法就是把最新的checkpoint拉起后,在把之后的WAL replay恢复出最新的数据;
这里如果要恢复快,就需要checkpoint比较频繁,checkpoint本身是很好资源的,所以这里就有tradeoff
A great simplifying principle of a traditional database is that the same redo log applicator is used in the forward processing path as well as on recovery where it operates synchronously and in the foreground while the database is offline. We rely on the same principle in Aurora as well, except that the redo log applicator is decoupled from the database and operates on storage nodes, in parallel, and all the time in the background.
Once the database starts up it performs volume recovery in collaboration with the storage service and as a result, an Aurora database can recover very quickly (generally under 10 seconds) even if it crashed while processing over 100,000 write statements per second.
Aurora没有这样的问题,关键db和存储分开的,而redo log applicator是在存储层,所以无论db是否在工作,redo log的物化都是在并行进行的;所以当db恢复的时候,并没有什么需要特别做的,可以快速回复
The database does need to reestablish its runtime state after a crash.
In this case, it contacts for each PG, a read quorum of segments which is sufficient to guarantee discovery of any data that could have reached a write quorum.
Once the database has established a read quorum for every PG it can recalculate the VDL above which data is truncated by generating a truncation range that annuls every log record after the new VDL, up to and including an end LSN which the database can prove is at least as high as the highest possible outstanding log record that could ever have been seen.
The database infers this upper bound because it allocates LSNs, and limits how far allocation can occur above VDL (the 10 million limit described earlier).
The truncation ranges are versioned with epoch numbers, and written durably to the storage service so that there is no confusion over the durability of truncations in case recovery is interrupted and restarted
DB在recovery的时候,需要做的主要是恢复runtime state;这时候才需要read quorum,根据读到的数据重新计算VDL,并且把VDL后面的数据truncate掉;