pandas
参考文档:
https://pandas.pydata.org/pandas-docs/stable/
简易教程:
https://www.yiibai.com/pandas/python_pandas_quick_start.html
快速入门
环境准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
print("Hello, Pandas")
对象创建 series
s = pd.Series([1,3,5,np.nan,6,8])
print(s)
dataframe
通过传递numpy数组,使用datetime索引和标记列来创建DataFrame
dates = pd.date_range('20170101', periods=7)
print(dates)
print("--"*20)
df = pd.DataFrame(np.random.randn(7,4), index=dates, columns=list('ABCD'))
#提供二维数据组,指定索引,列标签
print(df)
#输出
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07'],
dtype='datetime64[ns]', freq='D')
----------------------------------------
A B C D
2017-01-01 -1.327582 0.281239 0.211973 0.632401
2017-01-02 -0.479155 0.152282 -0.050843 -1.516296
2017-01-03 1.016220 0.837861 0.282727 -0.013787
2017-01-04 0.116145 -0.572217 0.799886 0.424769
2017-01-05 1.106720 0.906832 0.080908 0.107534
2017-01-06 0.223071 -0.746190 0.103949 0.360859
2017-01-07 -0.143038 -0.133292 -0.522663 -0.462193
通过传递可以转换为类似系列的对象的字典来创建DataFrame
df2 = pd.DataFrame({ 'A' : 1.,
'B' : pd.Timestamp('20170102'),
'C' : pd.Series(1,index=list(range(4)),dtype='float32'),
'D' : np.array([3] * 4,dtype='int32'),
'E' : pd.Categorical(["test","train","test","train"]),
'F' : 'foo' })
#字典的键作为列标签
print(df2)
#输出
A B C D E F
0 1.0 2017-01-02 1.0 3 test foo
1 1.0 2017-01-02 1.0 3 train foo
2 1.0 2017-01-02 1.0 3 test foo
3 1.0 2017-01-02 1.0 3 train foo
查看数据
print(df.head())
print(df.tail(3))
##前后数行
print(df.index) #数据帧索引,
print(df.columns)#帧的列标签
print(df.values) #所有值
df.describe()
A B C D
count 7.000000 7.000000 7.000000 7.000000
mean 0.089982 0.123067 0.130399 -0.209379
std 0.829516 1.065122 0.878153 0.880092
min -0.857431 -1.909044 -1.272448 -1.381095
25% -0.471863 -0.251724 -0.322462 -0.705939
50% -0.054890 0.457952 -0.045655 -0.516503
75% 0.448861 0.824121 0.810718 0.429233
max 1.588198 1.167765 1.254381 0.985361
df.T 调换数据 即索引转化为列标签,列标签转化为索引
通过轴排序
print(df.sort_index(axis=1, ascending=False)) #axis=1 对列标签排序, axis=0 对行标签排序
按值排序
print(df.sort_values(by='B')) #根据列标签B进行排序 上小下大
选择区块
print(df['A']) 类似 df.A #以列标签选择 产生一个列 df数据帧相当于一个二维数据表,对该表进行选择
#####数据帧切片
df[0:3] # 以索引的下标进行选择,默认获取所有的列
print(df['20170102':'20170103'])#对索引进行指定
按标签选择
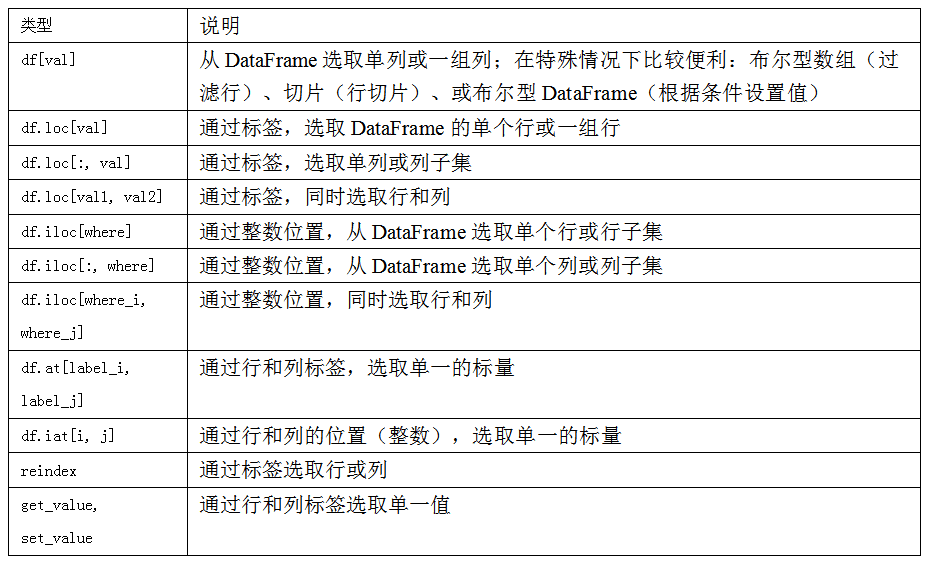
函数根据索引获取指定的数据
dates
atetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04',
'2017-01-05', '2017-01-06', '2017-01-07'],
dtype='datetime64[ns]', freq='D')
print(df.loc[dates[0]]) #根据索引值定位,获取该行所有列,产生一个series 默认选择了全部的列
通过标签选择多轴
print(df.loc[:,['A','B']]) #定位,指定所有的索引,及A B 列
print(df.loc['20170102':'20170104',['A','B']]) #手动指定索引(即行),第一个函数即为索引的值集合
print(df.loc[dates[0],'A']) #获取标量值,一个值, 指定了一个行索引和一个列名称
#快速访问标量 等同于loc
print(df.at[dates[0],'A']) #获取的值一样
通过位置选择
print(df.iloc[3]) #通过索引的位置进行获取,默认为全部列,产生一个servies
print(df.iloc[3:5,0:2]) # 索引和列序列共同获取数据
print(df.iloc[[1,2,4],[0,2]]) #另一种方式
print(df.iloc[1:3,:])
print(df.iloc[:,1:3])
print(df.iloc[1,1])
print(df.iat[1,1])
布尔索引
使用单列的值来选择数据
print(df[df.A > 0]) # 如果指定一列的每一行的值大于0,获取该行的所有数据
从满足布尔条件的DataFrame中选择值
print(df[df > 0])# 对于数据帧里的每一个数据,如果该值大于0则显示,小于0则显示NaN
isin()方法进行过滤
df2 = df.copy()
df2['E'] = ['one', 'one','two','three','four','three', 'one']
A B C D E
2017-01-01 -0.054890 0.457952 0.912951 -0.798572 one
2017-01-02 -0.526418 0.069355 1.254381 0.891169 one
2017-01-03 0.636579 -1.909044 -0.045655 0.985361 two
2017-01-04 1.588198 0.780422 -0.259735 -1.381095 three
2017-01-05 -0.417307 0.867821 -0.385189 -0.032704 four
2017-01-06 0.261142 -0.572804 0.708485 -0.613307 three
2017-01-07 -0.857431 1.167765 -1.272448 -0.516503 one
print(df2[df2['E'].isin(['two','four'])])
#拆开看
df2['E'].isin(['two','four'])
2017-01-01 False
2017-01-02 False
2017-01-03 True
2017-01-04 False
2017-01-05 True
2017-01-06 False
2017-01-07 False
Freq: D, Name: E, dtype: bool
获取每一行判定后的True 和False ,如果为真,就展示该行
pandas series 系列
pandas.Series( data, index, dtype, copy)
data : 数据采取各种形式, ndarray list constants
index: 索引值必须是唯一的和散列的,与数据的长度相同。 默认
np.arange(n)如果没有索引被传递dtype:
dtype用于数据类型。如果没有,将推断数据类型copy: 复制数据,默认为
false可以使用各种输入创建一个系列: 数组,字典,标量值或常数
series 的plot方法
Series 的 plot 方法
| 参数 | 描述 |
|---|---|
| data | 数据序列Series |
| kind | 图类型:折线图,柱形图,横向柱形图,直方图,箱线图,密度图,面积图,饼图 |
| ax | matplotlib axes 对象,默认使用gca() |
| figsize | 图像尺寸,tuple(宽度,高度),注意这里的单位是英寸 |
| use_index | 是否使用索引作为x刻度标签 |
| title | 标题 |
| grid | 网格线 |
| legend | 图例 |
| style | 线的样式 |
| logx | x轴使用对数刻度 |
| logy | y轴使用对数刻度 |
| loglog | x,y轴都使用对数刻度 |
| xticks | x轴刻度标签 |
| yticks | y轴刻度标签 |
| xlim | 横轴坐标刻度的取值范围 |
| ylim | 纵轴坐标刻度的取值范围 |
| rot | 改变刻度标签(xticks, yticks)的旋转度 |
| fontsize | 设置刻度标签(xticks, yticks)的大小 |
| position | 柱形图的柱子的位置设置 |
| table | 将数据以表格的形式展示出来 |
| yerr | 带误差线的柱形图 |
| xerr | 带误差线的柱形图 |
| lable | 列的别名,作用在图例上 |
| secondary_y | 双 y 轴,在右边的第二个 y 轴 |
| mark_right | 双 y 轴时,在图例中的列标签旁增加显示 (right) 标识 |
| **kwds | matplotlib plot方法的其他参数 |
Pandas数据帧(DataFrame)
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列。
数据帧(DataFrame)的功能特点:
- 潜在的列是不同的类型
- 大小可变
- 标记轴(行和列)
- 可以对行和列执行算术运算
常用方法
1. 重复值的处理
df.drop_duplicates()删除重复多余的记录,即有n行的每一列的值都相同的记录
2. 缺失值的处理
缺失值是数据中因缺少信息而造成的数据聚类, 分组, 截断等
2.1 缺失值产生的原因
主要原因可以分为两种: 人为原因和机械原因.
-
人为原因: 由于人的主观失误造成数据的缺失, 比如数据录入人员的疏漏;
-
机械原因: 由于机械故障导致的数据收集或者数据保存失败从而造成数据的缺失.
2.2 缺失值的处理方式
缺失值的处理方式通常有三种: 补齐缺失值, 删除缺失值, 删除缺失值, 保留缺失值.
- 补齐缺失值: 使用计算出来的值去填充缺失值, 例如样本平均值.
使用fillna()函数对缺失值进行填充, 使用mean()函数计算样本平均值.
import pandas as pd
import numpy as np
df = pd.DataFrame({'ID':['A10001', 'A10002', 'A10003', 'A10004'],
"Salary":[11560, np.NaN, 12988,12080]})
#用Salary字段的样本均值填充缺失值
df["Salary"] = df["Salary"].fillna(df["Salary"].mean())
df
- 删除缺失值: 当数据量大时且缺失值占比较小可选用删除缺失值的记录
采用dropna函数对缺失值进行删除: 该值所在的行被删除
3. 删除前后空格
import pandas as pd
df = pd.DataFrame({"ID": ["A1000","A1001","A1002"],
"Surname": [" Zhao ","Qian"," Sun " ]})
df["Surname"] = df["Surname"].str.strip()
df
新版anaconda 的空格显示不出来
4. 查看数据类型
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
#查看所有列的数据类型
df.dtypes
#查看单列的数据类型
df["ID"].dtype
5. 修改数据类型
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
#将ID列的类型转化为字符串的格式
df["ID"].astype(str)
6. 字段的抽取
使用slice(start, end)函数可完成字段的抽取, 注意start是从0开始且不包含end. 比如抽取前两位slice(0, 2).
对某字段转化为字符后截取
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
3 #需要将ID列的类型转换为字符串, 否则无法使用slice()函数
4 df["ID"]= df["ID"].astype(str)
5 #抽取ID前两位
6 df["ID"].str.slice(0,2)
7. 字段的拆分
使用split()函数进行字段的拆分, split(pat=None, n = -1, expand=True)函数包含三个参数:
第一个参数则是分隔的字符串, 默认是以空格分隔
第二个参数则是分隔符使用的次数, 默认分隔所有
第三个参数若是True, 则在不同的列展开, 否则以序列的形式显示.
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
3 #对Surname_Age字段进行拆分
4 df_new = df["Surname_Age"].str.split("_", expand =True)
5 df_new
8. 字段的命名
有两种方式一种是使用rename()函数, 另一种是直接设置columns参数
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
#第一种方法使用rename()函数
# df_new = df["Surname_Age"].str.split("_", expand =True).rename(columns={0: "Surname", 1: "Age"})
# df_new
#第二种方法直接设置columns参数
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_new
9. 字段的合并
使用merge()函数对字段进行合并操作.
1 import pandas as pd
2 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
3 df_new = df["Surname_Age"].str.split("_", expand =True)
4 df_new.columns = ["Surname","Age"]
5 #使用merge函数对两表的字段进行合并操作.
6 pd.merge(df, df_new, left_index =True, right_index=True) #将不同的df 的列合并在一起
10. 字段的删除
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_mer= pd.merge(df, df_new, left_index =True, right_index=True)
#drop()删除字段,第一个参数指要删除的字段,axis=1表示字段所在列,inplace为True表示在当前表执行删除.
df_mer.drop("Surname_Age", axis = 1, inplace =True) #删除某一列
df_mer
df_mer.drop(0, axis = 0, inplace =True) #删除某一行
df_mer
11. 记录的抽取
1) 关系运算: df[df.字段名 关系运算符 数值], 比如抽取年龄大于30岁的记录.
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_mer= pd.merge(df, df_new, left_index =True, right_index=True)
df_mer.drop("Surname_Age", axis = 1, inplace =True)
#将Age字段数据类型转化为整型
df_mer["Age"] = df_mer["Age"].astype(int)
#抽取Age中大于30的记录
df_mer[df_mer.Age > 30]
2) 范围运算: df[df.字段名.between(s1, s2)], 注意既包含s1又包含s2, 比如抽取年龄大于等于23小于等于28的记录.
df_mer[df_mer.Age.between(23,28)]
3) 逻辑运算: 与(&) 或(|) 非(not)
df_mer[df_mer.Age.between(23,28)]就等同于df_mer[(df_mer.Age >= 23) & (df_mer.Age <= 28)]
df_mer[(df_mer.Age >= 23 ) & (df_mer.Age <= 28)]
4) 字符匹配: df[df.字段名.str.contains("字符", case = True, na =False)] contains()函数中case=True表示区分大小写, 默认为True; na = False表示不匹配缺失值.
1 import pandas as pd
2 import numpy as np
3 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28"],"SpouseAge":[np.NaN,"32",np.NaN]})
4 #匹配SpouseAge中包含2的记录
5 df[df.SpouseAge.str.contains("2",na = False)]
当na改为True时, 结果为:
5) 缺失值匹配: df[pd.isnull(df.字段名)]表示匹配该字段中有缺失值的记录.
1 import pandas as pd
2 import numpy as np
3 df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28"],"SpouseAge":[np.NaN,"32",np.NaN]})
4 #匹配SpouseAge中有缺失值的记录
5 df[pd.isnull(df.SpouseAge)]
12.记录的合并
使用concat()函数可以将两个或者多个数据表的记录合并一起, 用法: pandas.concat([df1, df2, df3.....])
1 import pandas as pd
2 df1 = pd.DataFrame({"ID": ["A10006","A10001"],"Salary": [12000, 20000]})
3 df2 = pd.DataFrame({"ID": ["A10008"], "Salary": [10000]})
4 #使用concat()函数将df1与df2的记录进行合并
5 pd.concat([df1, df2])
13. 简单计算
新建一个表
import pandas as pd
df = pd.DataFrame({"地区": ["A区","B区", "C区"],
"前半年销量": [3500, 4500,3800],
"后半年销量": [3000, 6000,5000],
"单价": [10, 18, 15]})
df
13.1 加法计算
有两种方式, 一种是利用add()函数: a.add(b) 表示a与b之和, 另一种是直接利用加法运算符号"+"
#第一种方式: 利用add()函数
2 # df["总销量"] = df["前半年销量"].add(df["后半年销量"])
3 #第二种方式: "+"
4 df["总销量"] = df["前半年销量"] + df["后半年销量"]
5 df
一种方式就是采用apply()函数, 参考文档: https://blog.csdn.net/luckarecs/article/details/72869051
这里介绍apply(func, axis = 0)函数的两个参数, apply()函数官方文档: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.apply.html?highlight=apply#pandas.DataFrame.apply
第一个参数func就是指用于每行或者每列的函数, 这里将采用lambda函数: 接收任意多个参数并返回单个计算结果.
第二个参数axis=0则表示计算行与行的数据, axis=1则表示计算列与列的数据
1 #由于地区不能参与运算, 因此在df1数据表中删除地区
2 df1 = df.drop(["地区","单价"], axis = 1, inplace = False)
3 #对df1数据表进行累加运算, 随后添加到df表中.
4 df["总销量"] = df1.apply(lambda x: x.sum(), axis = 1)
5 df
1 #删除地区和单价,分别计算前半年与后半年的三个地区总和.
2 df2 = df.drop(["地区","单价"], axis = 1, inplace = False)
3 #利用apply函数计算之后,添加至数据表中
4 df.loc["Sum"] = df2.apply(lambda x: x.sum(), axis = 0 )
5 df
13.2 减法运算
同样有两种方式: 一种是采用sub()函数, A.sub(B)表示A-B, 另一种是采用减法运算符 "-"
1 #函数法: 注意A.sub(B)表示A-B
2 df["销量增长"] = df["后半年销量"].sub(df["前半年销量"])
3 #运算符: "-"
4 df["销量增长"] = df["后半年销量"] - df["前半年销量"]
5 df
13.3 乘法运算
同样是两种方式: 一种是采用mul()函数: A.mul(B)表示: A与B之积, 另一种则是乘法运算符 "*"
1 #函数法: A.mul(B)
2 df["前半年销售额"] = df["前半年销量"].mul(df["单价"])
3 #运算符: "*"
4 df["后半年销售额"] = df["后半年销量"] * df["单价"]
5 df
13.4 除法运算
同样是两种: 一种是采用div()函数: A.div(B)表示: A除以B, 第二种则是采用除法运算符"/"
1 #函数法
2 df["前半年销量1"] = df["前半年销量"].div(100)
3 #运算符法
4 df["前半年销量2"] = df["前半年销量"] / 1000
5 df
13.5 其他运算
13.5.1 取整和取余
1 #取整符号: "//"
2 df["后半年销量1"] = df["后半年销量"] // 1000
3 #取余符号: "%"
4 df["前半年销量1"] = df["前半年销量"] // 100 % 10
5 df
13.5.2 聚合运算
采用聚合函数对一组数据进行运算, 并返回单个值, 比如最大值max()函数, 最小值min()函数, 平均值mean()函数
#求前半年销量最大值
df1 = df["前半年销量"].max()
#求后半年销量最小值
df2 = df["后半年销量"].min()
#求单价的平均值
df3 = df["单价"].mean()
df1, df2 ,df3
14. 0-1标准化
0-1标准化是对原始数据进行线性变换, 使其结果映射成[0,1]区间的值, 计算公式为: 新数据 = (原数据 - 最小值) / (最大值 - 最小值)
1 import pandas as pd
2 df = pd.DataFrame({"地区": ["A区","B区", "C区", "D区", "E区", "F区"],
3 "销量": [3500, 4500,3800,3000, 6000,5000]})
4 #利用公式对原始数据进行0-1标准化处理
5 df["0-1"] = (df["销量"] - df["销量"].min()) / (df["销量"].max() - df["销量"].min())
6 df
15. 数据分组
数据分组是根据统计研究的需求, 对原始数据按照某种标准划分为不同的组别. 主要目的是观察数据的分布特征. 在数据分组后再计算出各组中数据出现的的频数, 最终形成频数分布表.
pandas中数据分组采用的函数是cut(x, bins, right = True, labels = None)函数:
第一个参数x指的是要分组的数据
第二个参数bins指的是划分标准, 也就是定义组的上限与下限
第三个参数right = True表示右边闭合, 左边不闭合; 当right = False时表示右边不闭合, 左边闭合, 默认为True.
第四个参数则是自定义分组的内容
更多cut()函数相关参考官方文档: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.cut.html?highlight=cut#pandas.cut
import pandas as pd
df = pd.DataFrame({"地区": ["A区","B区", "C区", "D区", "E区", "F区", "G区"],
"单价": [ 8 , 20, 15, 7, 34, 25, 30]})
#对单价进行编组: (5,15),(15,25),(25,35)
bins = [5, 15, 25, 35]
#利用cut()函数对单价进行分组, 并添加至原数据表中
df["分组"] = pd.cut(df.单价, bins)
df
自定义labels:
import pandas as pd
df = pd.DataFrame({"地区": ["A区","B区", "C区", "D区", "E区", "F区", "G区"],
"单价": [ 8 , 20, 15, 7, 34, 25, 30]})
bins = [5, 15, 25, 35]
#自定义labels
labels = ["15以下", "15到25", "25以上"]
df["分组"] = pd.cut(df.单价, bins, labels = labels)
df
16. 日期转换
日期转换是指将字符类型转换成日期格式.
16.1 to_datetime方法
可使用to_datetime(arg, format = None)函数转换
第一个参数arg则是需要转化的字符串, 比如"2018/09/01"
第二个参数format则是原字符串中日期的格式, 比如"2018/09/01"的格式为 "%Y/%m/%d"
常用的格式有: %y表示两位数的年份, %Y表示四位数的年份, %m表示月份, %d表示月中的某一天, %H表示24小时制时数, %I表示12小时制时数, %M表示分钟, %S表示秒
to_datetime()函数官方文档: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.to_datetime.html?highlight=to_datetime#pandas.to_datetime
1 import pandas as pd
2 df = pd.DataFrame({"name":["A","B","D"],
3 "BirthDate": ["2011/10/20","2009/3/5","2010/5/6"]})
4 #转成日期格式
5 df["BD"] = pd.to_datetime(df.BirthDate,format = "%Y/%m/%d")
6 df
1 #查看数据类型
2 df.dtypes
16.2 datetime.strptime()方法
借助datetime模块中datetime类的strptime()方法, 将字符类型转化为日期格式.
strptime(date_string, format)方法中有两个参数, 第一个参数则是要转化的字符串, 第二个参数则为字符串中日期的格式
import pandas as pd
from datetime import datetime
df = pd.DataFrame({"name":["A","B","D"],
"BirthDate": ["2011/10/20","2009/3/5","2010/5/6"]})
#转化为日期格式
df["BD"] = df["BirthDate"].apply(lambda x: datetime.strptime(x, "%Y/%m/%d"))
df
17. 日期格式化
日期格式化就是将日期按照指定的格式输出成字符类型, 这里借助datetime模块中datetime类的strftime()方法实现:
import pandas as pd
from datetime import datetime
df = pd.DataFrame({"name":["A","B","D"],
"BirthDate": ["2011/10/20","2009/3/5","2010/5/6"]})
#转化为日期格式
df["BD"] = df["BirthDate"].apply(lambda x: datetime.strptime(x, "%Y/%m/%d"))
#日期格式化
df["BD1"] = df["BD"].apply(lambda x: datetime.strftime(x, "%d-%m-%Y %H:%M:%S"))
df
18.日期抽取
从日期格式中抽取日期的部分内容, 比如抽取年份, 月份等. 语法: 转换为日期格式的列.dt.要抽取的属性.
import pandas as pd
from datetime import datetime
df = pd.DataFrame({"name":["A","B","D"],
"BirthDate": ["2011/10/20","2009/3/5","2010/5/6"]})
df["BD"] = df["BirthDate"].apply(lambda x: datetime.strptime(x, "%Y/%m/%d"))
df["year"] = df["BD"].dt.year
df["month"] = df["BD"].dt.month
df["day"] = df["BD"].dt.day
df["hour"] = df["BD"].dt.hour
df["minute"] = df["BD"].dt.minute
df["second"] = df["BD"].dt.second
df["weekday"] = df["BD"].dt.weekday
df