引入
首先来看一个例子:(编译环境:VC++ 6.0 Release模式)
#include<stdio.h>
void main(){
char a,b;
scanf("%2c%2c",&a,&b);//输入 1234
printf("%c%c",a,b);
}
输入:
1234
输出:
43
是否有疑问呢?
这简单的几行代码可以延伸出很多问题来。
内存
我们先分析一下这个简单的程序:
首先,我们输入了 “1234” 并敲下回车,然后 scanf() 函数被调用,开始工作。
scanf() 首先识别到占位符 “%2c” ,于是把 {‘1’,‘2’} 写到变量 a 里,现在 a 在内存中的值为 ‘1’(0x01)。随后同理,b 在内存中的值变为 ‘3’(0x03)。
那么,为什么 printf("%c%c", a, b) 实际输出的是 “4 3”,而不是 “1 3” 呢?
这个问题涉及到 scanf() 本身,更涉及到计算机的内存。
我们知道,scanf("%2%2c",&a,&b) 的第 2 3 个参数为指针型,所以我们在变量名前加了取址符 & ,这样 scanf() 就可以通过指针找到 a b 在内存中的实际位置,直接进行写入。而其写入数据的规则为 “根据输入的数据和占位符要求,从指定地址开始向高地址写入数据,直到写入结束”。
下面我将从内存的角度,详细剖析这个问题。
为了方便读者理解,我会用图文结合的方式来描述:
首先,我们在程序中连续声明多个变量时,它们在内存中的位置是连续的,并遵循从高地址向低地址方向为变量分配空间的规则。
例如,我们在上述程序中进行了如下声明,向操作系统申请了两个字节的空间来存放数据:
char a, b;
此时在内存中:(没学过HTML,表格太丑嫑在意)
| 地址 | 数据 | |
|---|---|---|
| 0x06 | … | 高地址 |
| 0x05 | … | ↓ |
| 0x04 | … | ↓ |
| 0x03 | (a) | ↓ |
| 0x02 | (b) | ↓ |
| 0x01 | … | 低地址 |
输入1234:
scanf("%2c%2c",&a,&b);
1. {‘1’,‘2’} 写入 a ,即由 a 在内存中的位置,向高地址开始写入数据。
此时在内存中:
| 地址 | 数据 | |
|---|---|---|
| 0x06 | … | 高地址 |
| 0x05 | … | ↓ |
| 0x04 | ‘2’(内存溢出) | ↓ |
| 0x03 | ‘1’(a) | ↓ |
| 0x02 | (b) | ↓ |
| 0x01 | … | 低地址 |
我们发现,当‘ 1’ 写入到 a 的位置后,scanf() 并未停止,而是选择根据占位符的规则继续向高地址 0x04继续写入 ‘2’ ,这种情况被称为 “内存溢出” 。
0x04 的位置很可能已经被分配给了其他变量,所以 “内存溢出” 会使得数据被写在了程序员意料之外的地方,从而导致程序运行错乱,甚至终止运行。
(如果在 VS2019 的 VC 环境下,程序运行完毕后会弹出错误提示,告知某变量周围的堆栈被破坏。)
那么,继续我们的分析:
2.{‘3’,‘4’} 写入 b ,同理。
此时在内存中:
| 地址 | 数据 | |
|---|---|---|
| 0x06 | … | 高地址 |
| 0x05 | … | ↓ |
| 0x04 | ‘2’(内存溢出) | ↓ |
| 0x03 | ‘4’(a)(被覆盖) | ↓ |
| 0x02 | ‘3’(b) | ↓ |
| 0x01 | … | 低地址 |
答案显而易见,变量 a 位置的数据在此次写入时被覆盖了。
此时若输出 a b 的值,当然是 ‘3’ 和 ‘4’ ,而非 ‘1’ 和 ‘2’ 了。
内存分配
以上情况并非绝对,因为C标准并未规定分配内存的方式,所以,不同编译器分配内存的方式也不同。
举几个例子:
我将在不同编译环境下执行下面的代码:
#include<stdio.h>
void main(){
char a,b;
printf("%d
%d",&a,&b);
}
- VC++ 6.0 debug 模式:
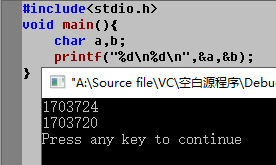
连续声明的两个变量,在内存中相差四个字节。 - VC++ 6.0 release 模式:
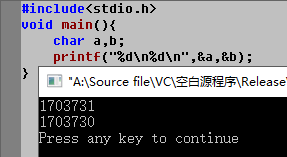
连续声明的两个变量,在内存中紧紧挨在一起。 - Dev-C++(编译器 GCC 4.9.2 64-bit)
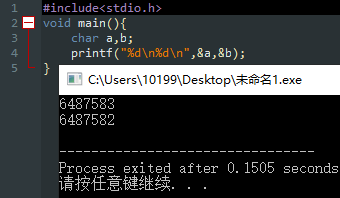
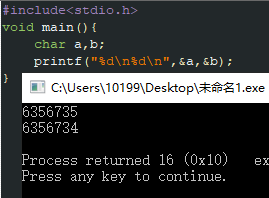
… - Code Blocks 也是GCC
.
我们发现,基本上大部分编译器再分配内存是均由高地址向低地址分配。
但当然也有例外: - VC++ 2019 Release 模式 win32平台
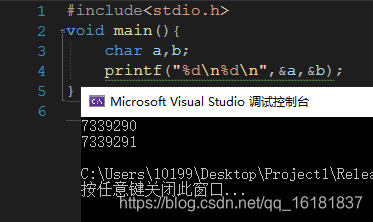
连续分配的内存地址由低至高。
指针
下面是题外话,也是预备知识:
我刚才在解释问题的时候,使用的一直是仅占 1 字节的 char 型变量,这只是为了方便,但很可能引起误解,或引起疑惑。
这里需要解释一下:虽然不同编译器在内存分配方面有多多少少的不同,但对内存的引用,一定是由低地址向高地址。
什么意思呢?
以 int 为例:我们知道,int 在内存中占 4 个字节(VC++ 6.0),而 int 中的数据是有向的,即对于 0x FF00 FF00 不能被解释为 0x 00FF 00FF,而在内存中,我们规定其方向为 低地址→高地址。
为了便于理解,我举个例子来解释清楚:
通过下面的代码声明 int 型变量 a b:
int a = 0xFF00FF00,b = 0X00FF00FF;
在内存中的情况:
| 地址 | 数据 | |
|---|---|---|
| 0x09 | … | 高地址 |
| 0x09 | 0x00 | ↓ |
| 0x08 | 0xFF | ↓ |
| 0x07 | 0x00 | ↓ |
| 0x06 | 0xFF (a) | ↓ |
| 0x05 | 0xFF | ↓ |
| 0x04 | 0x00 | ↓ |
| 0x03 | 0xFF | ↓ |
| 0x02 | 0x00 (b) | ↓ |
| 0x01 | … | 低地址 |
0x02 → 0x05 属于变量 a,0x06 → 0x09 属于变量 b。
消除疑惑后,我们进入正题。
指针对变量的引用原理
仔细观察表格,细心的可能会发现:我总是在变量的起始字节处标明变量的名称,如:0x02 → 0x05 属于变量 a,我在地址 0x02 处的内存中标明了 (a),这并不是随意标记,而是刻意为之。
实际上,我应该用 & 来标记更为准确:
| 地址 | 数据 | |
|---|---|---|
| 0x05 | 0xFF | 高地址 |
| 0x04 | 0x00 | ↓ |
| 0x03 | 0xFF | ↓ |
| 0x02 | 0x00 (&b) | ↓ |
| 0x01 | … | 低地址 |
即对于变量 b 的指针,指向的是其起始字节。
思考几个问题:对于指针类型,
- 为什么C语言要对每一种变量类型都定义一种对应的指针类型?
- 不同指针类型的本质区别在哪?
例如 int* , char* ,double* …
为了解答这两个问题,我们首先要明白:对于内存中随意连续的数个字节储存的数据,这些数据的含义仅取决于我们怎样取出这些数据(或怎样理解这些数据)。
为了解释这句话,我们看一个例子:
//编译器VC++ 6.0 Debug 内存由高地址到低地址分配
int a = 0xFF00FF00,b = 0X00FF00FF;
char* c = &b;
c = c + 2;
printf("%#x",*((int*)c));
输出:
0x00FFFF00
打印的值为内存地址 0x04 → 0x07 中的数据。
在内存中的情况:
| 地址 | 数据 | 向高地址引用 |
|---|---|---|
| 0x09 | … | 高地址 |
| 0x09 | 0x00 | ↓ |
| 0x08 | 0xFF | ↓ |
| 0x07 | 0x00 ← ← (int*) c 引用扩展至此 | ↓ |
| 0x06 | 0xFF (&a) | ↓ |
| 0x05 | 0xFF | ↓ |
| 0x04 | 0x00 ← ← 指针 c 赋值后指向的位置 | ↓ |
| 0x03 | 0xFF | ↓ |
| 0x02 | 0x00 (&b) ← ← 指针 c 初始化后指向的位置 | ↓ |
| 0x01 | … | 低地址 |
指针 c 在 printf() 中进行了强制转换 (int*) c,此时 (int*) c 虽然仍然同 c 一样指向原来的地址,但其引用空间扩展至其后从自身算起第四个字节。
然后针对 (int*) c 寻址:*((int*) c),此时引用的内存空间即为 0x04 → 0x07 。
所以,我们还可以看出,操作系统对每个字节均一视同仁,不会存在 “这个字节属于这个变量,那个字节属于那个变量” 的情况来。实际上,变量仅仅是一个抽象的名字而已,C语言之所以让我们感觉到 “不同内存空间属于不同变量” 这种假象,是因为C是一种高级语言,他需要比更加底层的语言抽象,而非具体。
至此,刚才提出的两个问题已经可以回答了:
从上述例子,我们看到,char指针的引用空间仅为本身所指地址的 1 个字节,而 int指针的引用空间则为其所指地址至其后第 4 个字节。 以此类推,我们可以猜到,double指针的引用空间应为 8个字节。
那么,实际上不同指针类型的本质区别就是其所指地址往后所能引用的空间大小。
void* 空类型指针
不久前,我写过一段代码,现在想起来感到有些可笑。
但也正因为这段代码,我对指针的理解更加深入了一步,在这里我得感谢老师对我的指导。
同时,这也成为了我写这篇文章的初衷。
废话不多BB,我先把代码贴上:冒泡排序
void BubbleSort(void* array,int count)//注意第一个参数,我写的是 void*
{
int i, j, temp, flag = 1;
for (j = 0; flag == 1; j++)
{
flag = 0;
for (i = 0; i < count - j; i++)
{
if (array[i] < array[i + 1])
{
memswap(array[i + 1], array[i], sizeof array[i])
//由于我并不知道传入数组的类型,交换数据只能通过操作内存
//memcpy()用来交换内存,详细定义在下方
flag = 1;
}
}
}
}
memswap()的定义:
void memswap(void* a,void* b,int size){
void* temp = malloc(size);
memcpy(temp,a,size);memcpy(a,b,size);memcpy(b,temp,size);
free(temp);
}
介绍一下 void* ,即空类型指针:
这种指针的特殊之处在于,它不知道所指数据的大小(GNU编译器例外,对 void* 进行算数运算规则与 char* 相同,即 void* 自增 1 则内存地址 +1),即 void* 的功能仅限于指向内存地址,而无法引用任何东西。
所以,在使用这种指针前,必须进行强制转换,
如:
void* v;
int a = 3;
v = &a;
printf("%d", *((int*)v));
输出:
3
也就是说,仅当一个指针获得了引用范围后,才能取得内存中的数据。
我当时就是不明白这一点,所以才写出了这样的函数:
void BubbleSort(void* array,int count)
当然,我的出发点是好的。
我当时就想,int 数组可以排序, float 数组也可以排序,double 数组当眼也可以排序,甚至 char 数组都可以排序。于是我为了兼顾多种类型,直接声明了一个 void指针,并且想当然地以为:实参传进去,形参应该会自动转换的吧。然而编译器毫不留情的报错,提示说 unknown size 。
于是,我花了几个小时来把这些东西彻底搞清楚。
因为我在函数中使用了 array[…] 来引用数组中的成员,即引用传入指针的后续数据。
我们知道,数组名称为数组首成员的地址,array[3] 的含义为 *(array + 3),然而 array 的类型始终为 void* 即空类型指针,编译器并不知道所指数据的大小,因而对 void 指针进行算术运算均不合法,(GNU除外),所以编译器认定 array[…]是错误的。
解决方法很简单,参考标准库中的快排函数 qsort() ,其定义为:
void qsort(void *, size_t, size_t, int (* )(const void *, const void *));
size_t 定义为:
typedef unsigned int size_t;
我们发现,它使用了一个回调函数1,让调用者来完成最关键的部分。(如果对回调函数不了解,应该先简单了解一下)
昨天刚刚发现这个函数,今天突然茅塞顿开,于是改动了一下我的代码,问题就解决了。
修改后代码:
void BubbleSort(void* array, int item_size, int count, int(* compar_fun)(void*, void*))
{//参数依次为 数组首成员指针 , 每个成员的大小 , 数组成员数 , 用来比较的回调函数指针
int i, j, flag = 1;
void* start = array;//记录首成员指针
for (j = 0; flag == 1; j++)
{
flag = 0;
array = start;
for (i = 0; i < count - 1 - j; i++, array = ((char*)array) + item_size)
{
if (compar_fun(array,(void*)((char*)array + item_size)) > 0)
{//如果仅当参数1大于参数2时返回正数,那么从小到大排列;如果仅当参数1小于参数2时返回正数,那么从大到小排列
memswap(array, (void*)((char*)array + item_size), item_size);
//memswap()的定义同上
flag = 1;
}
}
}
}
引用例程:
#include<stdio.h>
#include<stdlib.h>
int compar(void* a, void* b){
return *(int*)a - *(int*)b;
}
void main(){
int i,array [10] = {1,3,8,2,99,54,6,7,3,2};
BubbleSort(array, sizeof array[0], 10, compar);
for (i = 0;i < 10;i++)printf("%d ",array[i]);
}
输出:
1 2 2 3 3 6 7 8 54 99
scanf() 和 数组
11/25更新,
提示:本小节存在事实错误,改正后的总结在下一篇 Blog 中。
【改正总结】指针的局限性,scanf() 和 void*指针
又回到最初的起点,呆呆的站在镜子前。
文初我们讨论了 scanf() 函数在写入数据时出现的问题,对于 scanf() 函数,我还想多说一些。
可能有些人认为,这属于函数本身在设计上的缺陷和不周到。
然而我认为, scanf() 之所以这样做,实际上是对功能的妥协。
为什么我要这样说?
它是对什么功能的妥协?
我们知道,数组的名称实际上是数组首成员的地址,
即便你不知道,通过阅读上面的内容,也能发现:当我想要向函数中传入数组时,我的实参是数组名称.而我想要在函数中接收数组时,形参也写的是一个指针类型。
对于以下写法,是等价的:
void fun(int* array);
void fun(int array[]);
那么,如果声明一个指针指向一个数组的首成员地址,就可以接管这个数组。
例如:
#include<stdio.h>
void main(){
int array[10]={1,2}, *p;
p = array;
printf("%d",p[1]);
}
输出:
2
数组的本质仅仅是内存中一段连续的数据,说白了就是一种最简单的数据结构,我们可以通过指针的偏移量来直接访问数组成员:
#include<stdio.h>
void main(){
int array[10]={1,2}, *p;
p = array;
for(int i = 0 ; i < 10 ; i++)
printf("%d",*(p + i));
}
输出:
120000000
回答刚才的问题:
首先,scanf() 实际上就是对一段连续的内存进行赋值,那么也就可以对数组赋值。很显然,这样做很方便,
但对于一个指针,我们并不知道他到底是不是一个数组的首成员地址,那么对于 scanf() 函数,它也无从得知,于是就选择了对方便的功能进行妥协。即scanf() 选择相信程序员,相信我们不会把程序搞得内存溢出,就像编译器相信程序员不会使数组越界一样。
但实际上总是会有那么多粗心的程序员,怎么办呢?微软早在 VC++ 2005 中就提供了更为安全的版本 scanf_s()。
点击查看scanf_s的度娘百科
纯私货
最后是一点纯私货,可以参考但不要轻信:
我认为数组在C中是有些多余的。由于 C 非常底层的性质,数组这样比较抽象的概念有些显得不伦不类,他的功能简单,甚至没有下标检查,那么他在 C 中就没有了存在于其他高级语言那样的必要性。
因为在 C 中我可以任意构建我需要的数据结构,而数组恰恰是最简单的数据结构,仅仅通过简单地应用指针即可实现。
很多初学者会发现,在它们选择的参考书中,不论是学校给发的教材,还是经典的 《C Primer Plus》,均在目录中列着这几个大章节:
<数据类型><选择结构><循环结构><指针><数组>
这会让很多人误解为:数组和另外几个是并列关系,实际上并不是。书里给出一章讲数组,恰恰是为了让我们理解到数组的本质。数组仅仅是一个简单的数据结构而已,可以简单地由另外几个如<数据类型><选择结构><循环结构><指针>轻松实现。
再然后,欢迎各位读者斧正。
告辞
回调函数:回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。 ↩︎