论文:Contrastive Learning for Compact Single Image Dehazing, CVPR 2021
代码:https://github.com/GlassyWu/AECR-Net
1、背景
当前方法的问题:1)使用clear images结合L1/L2重建损失进行训练,容易引起结果偏色;2)侧重于加大网络的深度和宽度,导致计算开销巨大。
为了解决当前问题,作者提出了一种新的 contrastive loss。有雾图像,网络生成的图像,清晰图像分别做为 negative, anchor, 和 positive 样本,保证生成的图像在表示空间中离清晰图像更近,离有雾图像更远。同时,为了在性能和参数量间取得平衡,作者提出了一个 compact network by adopting autoencoder-like framework。
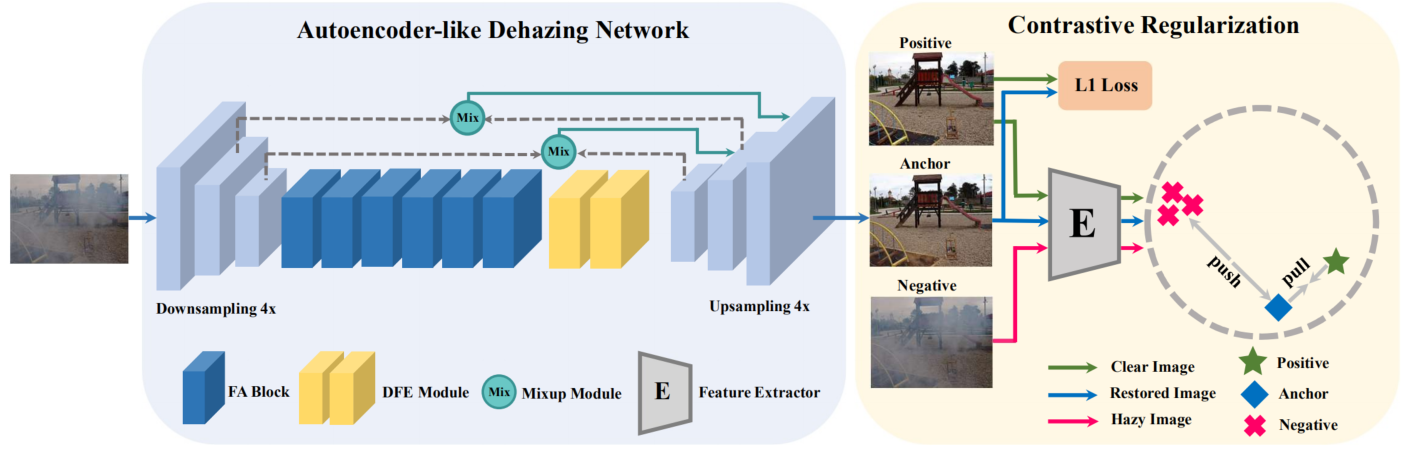
该方法框架如图所示,由 autoencoder-like dehazing network 和 contrastive regularization 组成。
2、Autoencoder-like dehazing network
网络首先是一个步长为1的卷积和两个步长为2的卷积(图中浅蓝色的块),然后,采用6个FA块处理(是在FFANet中提出的)。该模型只采用了6个FA块,但原来的FFANet采用了57个,显著减少了计算量。同时,为了促进不同层、不同尺度间特征的流动,作者提出了两种连接模式:
(1)Adaptive mixup: 用来动态融合下采样层和上采样层之间的特征。Low-level features (边缘和角点)在CNN的低层捕获,但是,随着网络层数的加深,浅层特征会退化。为了解决这一问题,本文采用adaptive mixup operation来融合下采样层和上采样层间的特征,如下图所示。

该操作可以表示为:

其中,权重是自适应可学习的参数。
(2)Dynamic feature enchancement: 传统方法经常采用固定大小3X3的卷积核(如下图中间蓝框图片所示),感受野有限,同时难以捕获结构信息。如果使用 deformable conv (如下图右边红框图片所示),就可以获得更多的结构信息。因此,作者引入了dynamic feature enhancement模块,由两个可变形卷积层组成。实验中发现,深层部署的效果比浅层部署效果要好。

3、Contrastive regularization
对比学习的目标是在度量空间上拉近正样本对间的距离,拉远负样本对间的距离。因此,作者提出了新的 contrastive regularization 来修复图像。正样本对是正样本对是清晰图像(J)和经网络修复的图像(phi(I, w)),负样本对是经网络修复的图像(phi(I, w))和有雾图像(I)。具体来说,网络的目标函数是:
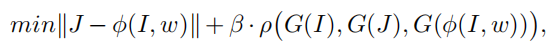
在具体实现上,作者使用了VGG19的感知损失。实验部分可以参考作者论文,这里不再多说。