在进行爬虫的过程当中,我们经常会遇到被封IP的情况,因此我们可以搜集一些代理IP,然后使用程序去测试哪些代理IP是可用的,我在这里使用了请求如下网站的方法:
http://icanhazip.com/
请求这个网站之后,如果请求成功,没有遇到异常,就会返回当前你请求这个网站的IP地址。同时保存到一个txt文件当中,进行数据的持久化,这样我们下次需要这些代理IP的之后,也可以随手使用。我们设定如果请求的时间超过了10秒钟,服务器都没有反应,或者遇到了异常,那么均请求失败。反之,则成功。
我将自己之前搜集的代理iP储存在了文件89_ip.txt当中,你也可以将你所搜集的代理ip放在一个文件当中,这样就可以快速验证你的代理ip是否有效了。我搜集之后,进行储存的格式如下所示:
现在我们一边读取这个文件,利用requests库进行测试,同时将测试成功的代理IP地址保存到google.txt文件下。在测试的时候,我使用了多进程进行网页请求,这样能够提升得到代理IP请求是否成功的速率。使用的方法也就是进程池pool技术,我开启了8个进程进行高性能爬虫,不然等这六百多个代理IP验证完了都等到何年何月了。(一个小trick:如果自己搜集的代理IP过多,可以使用kaggle平台帮助我们爬取数据,或者colab,这样我们即使关闭了计算机,它还会帮我们进行测试)。我编写的代码如下:
import requests from multiprocessing.dummy import Pool # 下面这些代码来验证哪些动态ip是可用的,哪些是不可用的,可用的就保存到txt里。 # 因为我们本身用来请求的时候就是使用requests这个库来进行使用的, 不如直接用它来做验证哈哈 def the_right_ip(all_ip): #print("开始测试 ") try: # 设置timeout response = requests.get('http://icanhazip.com/', proxies={"http": 'http://'+all_ip},timeout=10) print("使用的Ip地址为:{}".format(all_ip)) except Exception as e: print('nothing') with open('failed_ip', 'a', encoding='utf-8') as fp: fp.write(all_ip) fp.write(' ') else: print("请求成功一次!") with open('great_ip', 'a', encoding='utf-8') as fp: fp.write(all_ip) fp.write(" ") with open('google.txt', 'a', encoding='utf-8') as fp: fp.write(response.text) if __name__ == '__main__': f = open('89_ip', 'r') line = f.readline() all_ip = [] while line: all_ip.append(line.strip()) line = f.readline() f.close() pool = Pool(8) pool.map(the_right_ip, all_ip)
爬取一段时间之后,我发现在成功返回的数据当中,也就是在google.txt文件当中,发现了这样的一行文字:
Maximum number of open connections reached.
由于我的代理IP大量不可用,造成了我本机的iP对服务器不断发起请求,因此服务器检查到我请求的次数过于多了,因此报错。这样也没有关系,我们再次运行这个程序就可以了。因为我们的程序是异步执行的,具备极小的概率会检测同样的代理IP,我们重新运行这个程序,就算遇到的同样可用的代理IP地址,遇到之后把所有成功请求的代理IP地址放置到一个文件下,进行永久地储存。
我在terminal下的输出如下所示:
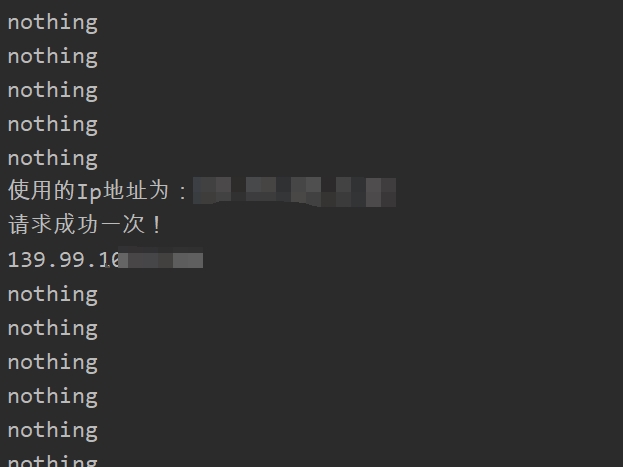
可以得知,我自己搜集的大部分代理IP都是无效的,只有少部分是有效的。但是能够有少部分有效的我就很开心了,毕竟是免费的,我自己并没有出钱,只是多加上了验证这一步而已嘛。