不算java、Mysql和Linux部分,每天学多少它已经分好了,严格按照这个来完成,但是你应该力求每天至少看2个day的视频,你觉得熟悉的地方应该快进。(学完一个小视频,你应该有收获和总结,但面试不考的你完全没必要总结。)
总结方法:只总结重点,一眼就明白的不用总结,关键看典型的题目怎么考你。典型的项目需要你做什么样的流程,从什么时候开始。
光大数据部分的视频如下(共计88天,这还不算java和mysql,不算看源码、调优技能)
- Hadoop:7天
- Zookeeper:0.5天
- HA:0.5天
- hive:6天
- flume:3天
- kafka:5天
- HBase:3天
- Azkaban:0.5天
- 离线数仓项目:5天+9天
- scala:8天
- spark:13天
- 实时数仓项目:13天
- Flink:9天
- 在线教育项目2.0:4天
- 面试大保健:2天
完成情况:
笔记:
Hadoop包括HDFS(存储)、Yarn(任务调度)、MapReduce(计算)三部分。
1.HDFS架构
- NameNode:记录块数据的存放位置
- DataNode:实际存数据
- Secondary NameNode:隔一段时间对NameNode做备份,但没法替代NN提供服务。 √
2.Yarn架构
我觉得没必要死记,记住了不理解也没用,其实他很像一个项目经理在给下属安排任务,只不过要正确理解下AM这个角色,他是为某一个任务而临时创建的管理者。只要能理解到这一点,整个架构就很好理解了。
以下是一个通俗的解释:
- 资源:对Yarn来说,资源就是特指CPU+内存
- Container:资源虚拟化,以Container的形式把多种资源打包在一起分配出去。
- Client:相当于客户,向主管(RM)提需求(job) ResourceManager:相当于主管,负责管理和了解整个集群的资源情况。
- 听客户(client)说需求
- 听每个员工(NM)汇报自己能做什么,手里有多少人力(节点资源)--》目的是让RM清楚整个集群,有多少人力能干多少事。
- 把每个员工(NM)安排成一个任务的临时负责人(AM)
- 听临时负责人申请需要多少人力(资源),然后分配给他--》这些资源是从整个集群的节点来调度,以资源池的形式灵活分配。比如说我需要两个前端,一个设计师来配合我。
- NodeManager:相当于员工,这个员工负责自己相关工作的人力资源。
- 向主管(RM)汇报自己手里的人力(资源)
- 成为任务的临时负责人(AM),评估领导分配的任务(job)
- 评估之后,跟主管(RM)要人力(资源)
- 持续跟进这个任务(job),直到完成后卸任“临时负责人”(AM)
- ApplicantionMaster:相当于“临时负责人”称号,为某一个任务而临时扮演管理者的角色。
- 向主管申请资源
- 一直跟进任务,直到完成后不再担任临时负责人
3.MapReduce流程:
- MR是一个计算框架,但并不是一个真正的组件,它的资源调度是由Yarn来实现。
- Map就是把任务分给每台机器去做,Reduce就是把任务汇聚起来。
4.大数据生态体系(了解)
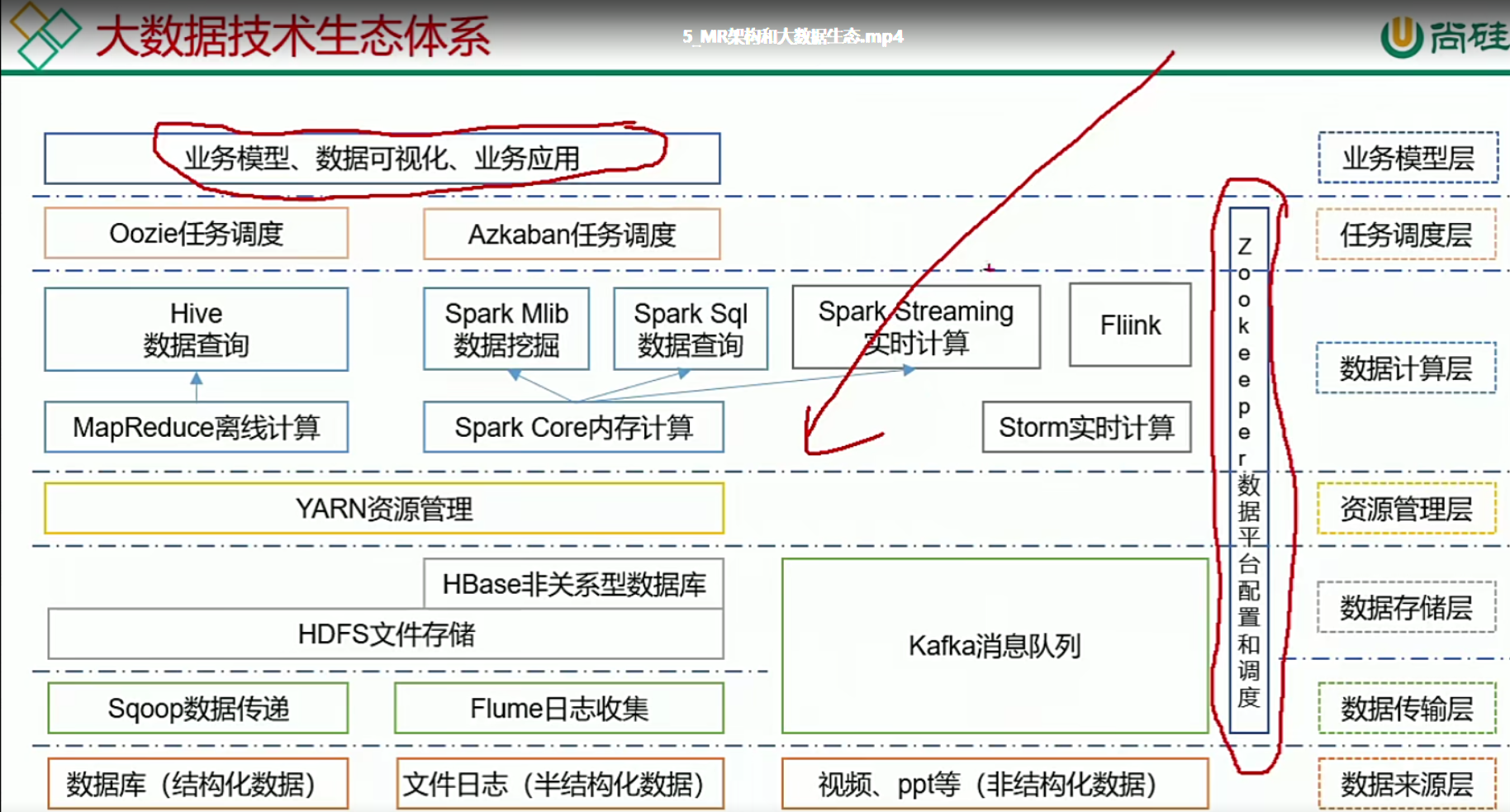
5.
总结: