一、背景
1.1 深度神经网络
深度神经网络是连接主义系统,通过它通过学习例子来完成任务,而不需要事先了解这些任务。它们可以很容易地扩展到数百万个数据点,并且可以通过随机梯度下降进行优化。
CNN是DNN的变体,能够适应各种非线性数据点。起始层学习更简单的特征,如边和角,后续层学习复杂的特征,如颜色,纹理等。此外,较高的神经元具有较大的感受野,构建在起始层上。然而,与多层感知器不同,权重共享是卷积神经网络背后的主要思想。
1.2 问题
CNN通过反向传播,根据网络权重计算损失梯度。而反向传播的超参数包括学习速率,动量,权重衰减等。找到最佳值所需的时间与数据大小成比例。
然而对于使用反向传播训练的网络,仅在网络中实现权重的点估计,从而导致对正确的类别、预测或行动做出过于自信的决定。(由于输出层的softmax函数可以实现概率得分,它压缩了一个类的输出概率得分,并使另一个类的输出概率得分最大化)。这样的网络能较好地拟合训练数据,但不能预测新数据-即产生了对现有样本的过度拟合。
目前主要通过正则化来消除过拟合,主要包括early stopping、权值衰减、L1- L2正则化,以及最流行和有效的dropout。但是,当前神经网络架构中缺少预测中的不确定性度量。
二、概率机器学习和不确定性
机器学习训练模型模型从观察到的数据(训练数据)中学习一些模式和假设,并对未观察到的数据(测试数据)进行推断。然而,由于输入数据噪声、感官噪声、测量误差、非最优超参数设置等诸多原因,该模型对预测具有不确定性。
从概率论的角度来看,用单点估计作为权重来建立任何分类都是不合理的,而且神经网络无法正确评估训练数据中的不确定性。机器学习中的概率模型指出,所有形式的不确定性不可能是一个真实的值,而更像是一个概率值,并使用概率论来回答一切问题。概率分布用于建模学习、不确定性和未观测状态。在观察数据之前,先定义一个先验概率分布,然后进行学习,一旦观察到数据,该分布就转换为后验分布。
2.1 不确定性类型
网络中的不确定性是衡量模型对其预测确定程度的指标。在贝叶斯模型中,存在两种主要的不确定性类型:偶然不确定性(Aleatoric uncertainty)和认知不确定性(Epistemic uncertainty)。
偶然不确定性测量观测中固有的噪声。这种不确定性存在于数据采集方法中,如传感器噪声或沿数据集均匀分布的运动噪声。即使收集了更多的数据,也不能减少这种不确定性。
偶然不确定性可以进一步分为同方差不确定性(Task-dependant or Homoscedastic uncertainty)和异方差不确定性(Data-dependant or Heteroscedastic uncertainty)
· 异方差不确定性,取决于输入数据,并预测为模型输出。其中一些输入可能具有比其他输入更多的噪声输出。异方差的不确定性尤为重要,可以防止模型输出非常自信的决策。
· 同方差不确定性,不取决于输入数据。它不是模型输出,而是一个对所有输入数据保持不变并且在不同任务之间变化的数量。因此,它可以被描述为任务相关的不确定性。
认知不确定性代表了模型本身造成的不确定性。给定更多数据可以减少这种不确定性,并且通常称为模型不确定性。
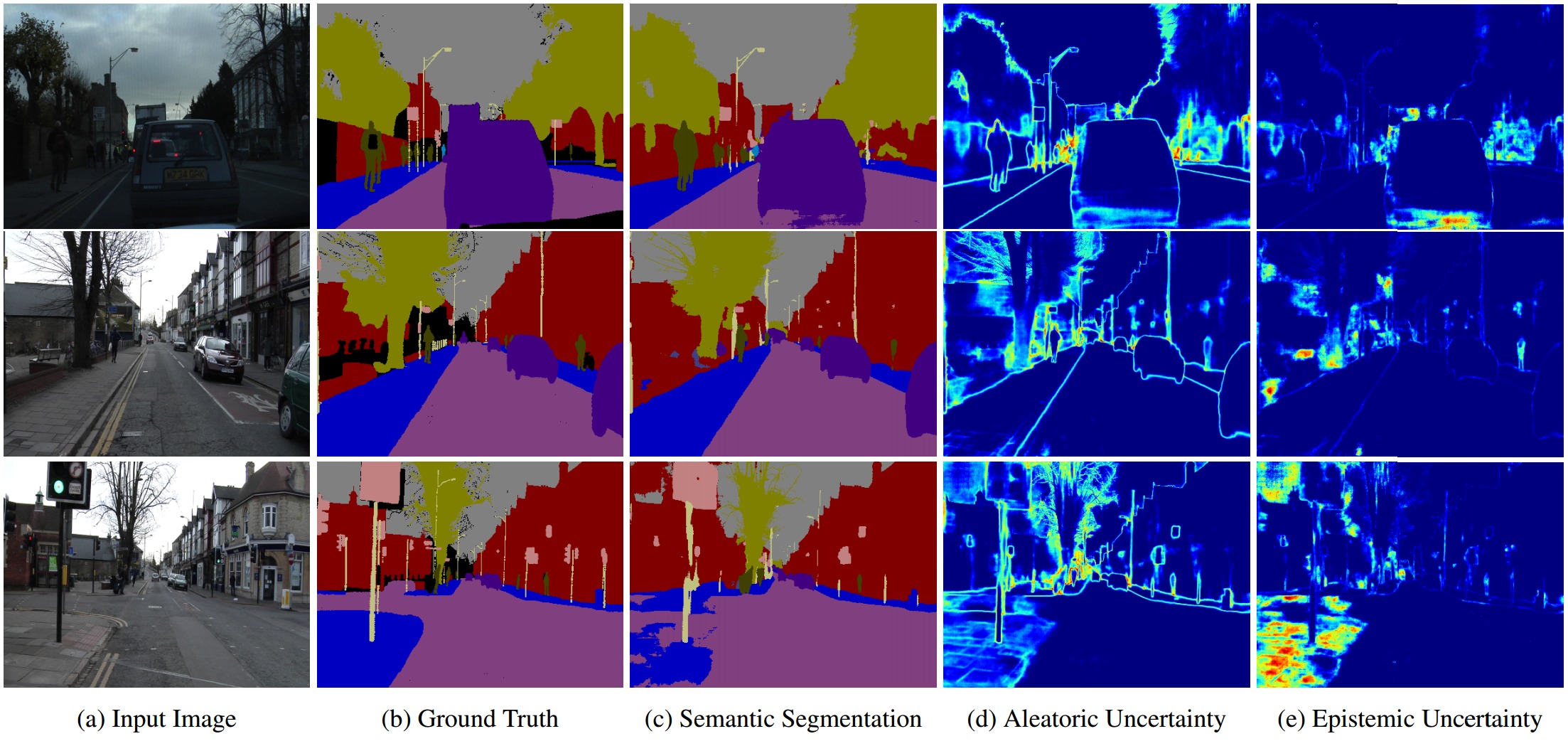
图中说明了语义分割中的偶然和认知不确定性之间的差异。 偶然不确定性捕获对象边界时,标签是有噪声的;而当模型不熟悉人行道时,以及相应的增加的认知不确定性,就导致了分割模型失败的情况。
三、贝叶斯深度学习
3.1 介绍
贝叶斯方法可以用于学习神经网络权重的概率分布。将神经网络中的wi 和 b 由确定的值变成分布(distributions)。具体而言,为弥补反向传播的不足,通过在模型参数或模型输出上放置概率分布来估计。在权重上放置一个先验分布,然后尝试捕获这些权重在给定数据的情况下变化多少来模拟认知不确定性。该方法不是训练单个网络,而是训练网络集合,其中每个网络的权重来自共享的、已学习的概率分布。
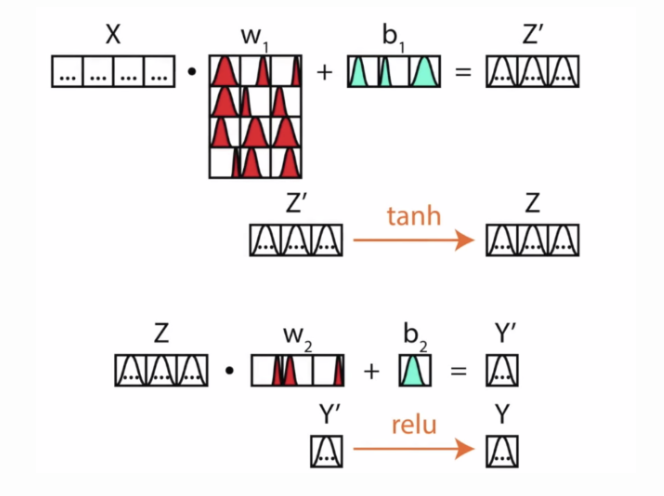
3.2 使用和训练
非贝叶斯网络中,在各种超参数固定的情况下,我们训练一个神经网络想要的就是各个层之间的权重和偏置。
而对于贝叶斯深度学习,因为权重和偏置都是分布,所以如果想进行前向传播进行参数估计,需要对参数进行多次采样。利用贝叶斯公式,求解w的后验概率p(w|x,y)*。
*贝叶斯公式

p(z|x) 被称为后验概率(posterior),p(x,z) 被称为联合概率,p(x|z) 被称为似然(likelihood),p(z) 被称为先验概率(prior),p(x) 被称为 evidence。
如果再引入全概率公式 p(x)=∫p(x|z)p(z)dz
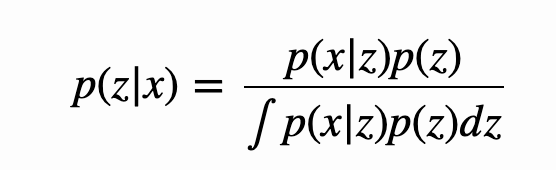
但实际操作中,由于网络的复杂性(参数众多,无法积分),直接求解w的后验概率几乎不可能,因为通常采用一下几种方式估计参数
(1)Approximating the integral with MCMC
(2)Using black-box variational inference (with Edward)
(3)Using MC (Monte Carlo) dropout
第(1)种情况用 MCMC(Markov Chains Monte Carlo) 采样去近似分母的积分。第(2)种直接用一个简单点的分布 q 去近似后验概率的分布 p,即不管分母怎么积分,直接最小化分布 q 和 p 之间的差异,如可以使用 KL散度计算。
3.3 贝叶斯深度学习优势
(1)由于可以多次采样,因此训练得到的权重更加robust
(2)可以得到模型的不确定性估计,由非softmax生成的概率
四、变分推理 Variational Inference
变分推理是常用的求解w后验分布的方式。一般的深度神经网络,假设θ 是神经网络的内部参数集,训练目标是要找到一个最好的 θ* ,让损失函数 Ln(θ) 最小。而在贝叶斯深度学习中,关心在数据D下模型参数θ 的分布。其中 α 是 ℝd 上的θ先验分布(可以理解为从α 中可以抽样得到 θ)。
实际中通常会使用简单的变分分布(如高斯分布)对后验进行建模,并尝试使分布的参数尽可能接近真实的后验。比如,一般用一个替代分布q(θ|φ)去逼近后验分布p(θ|D), 如果无法知道α 的真正形式,我们就先造一个q(θ|φ)分布,使得变分自由能(variational free energy)最小:
求解过程是通过最小化Kullback-Leibler(KL散度)与真实后验的分歧来完成的。这种方式采样得到的权重w用于神经网络的反向传播以学习后验分布。

但是在在贝叶斯神经网络中用来近似后验的变分方法在计算上会大大增加参数的数量,并且训练结果和dropout方法类似。为了减少网络的参数,采用模型修剪减少了深度神经网络中各种连接矩阵中的稀疏问题,从而减少了模型中表值参数的数量。
· 相关研究
采用Backprop的Bayes构建贝叶斯神经网络
用变分概率分布q_θ(w | D)接近难以处理的真实后验概率分布p(w | D),前者包含高斯分布μ∈ℝ^ d和σ∈ℝ^ d的特性。表示为N(θ | μ,σ²),其中d是定义概率分布的参数总数。这些高斯变分后验概率分布的形状由它们的方差σ²确定,表示每个模型参数的不确定性估计。
参考: