本文将以iris数据集为例,梳理数据挖掘和机器学习过程中数据预处理的流程。在前期阶段,已完成了数据采集、数据格式化、数据清洗和采样等阶段。通过特征提取,能得到未经处理的特征,但特征可能会有如下问题:
- 不属于同一量纲 通常采用无量纲化进行处理;
- 信息冗余
- 定性特征不能直接使用 通常使用哑编码的方式将定性特征转换为定量特征;
- 存在缺失值
- 信息利用率低 不同的机器学习算法和模型对数据中信息的利用是不同的,之前提到在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。
首先导入iris数据集,
from sklearn.datasets import load_iris #导入IRIS数据集 iris = load_iris() #特征矩阵 iris.data #目标向量 iris.target
1 无量纲化
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
1.1 标准化
标准化需要计算特征的均值和标准差,公式表达为:
使用preproccessing库的StandardScaler类对数据进行标准化的代码如下:
from sklearn.preprocessing import StandardScaler #标准化,返回值为标准化后的数据 StandardScaler().fit_transform(iris.data)
1.2 区间缩放法
区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,公式表达为:
使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:
from sklearn.preprocessing import MinMaxScaler #区间缩放,返回值为缩放到[0, 1]区间的数据 MinMaxScaler().fit_transform(iris.data)
1.3 归一化
简单来说,标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下。归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。归一化类型包括:线性归一化、标准差归一化和非线性归一化。规则为l2的归一化公式如下: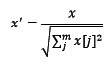
使用preproccessing库的Normalizer类对数据进行归一化的代码如下:
from sklearn.preprocessing import Normalizer #归一化,返回值为归一化后的数据 Normalizer().fit_transform(iris.data)
2 对定量特征二值化
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0,公式表达如下: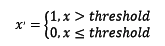
使用preproccessing库的Binarizer类对数据进行二值化的代码如下:
from sklearn.preprocessing import Binarizer #二值化,阈值设置为3,返回值为二值化后的数据 Binarizer(threshold=3).fit_transform(iris.data)
3 对定性特征哑编码
one-hot编码是指将一个无序的类别变量k个值就转换成k个虚拟变量。
使用preproccessing库的OneHotEncoder类对数据进行哑编码的代码如下:
from sklearn.preprocessing import OneHotEncoder #哑编码,对IRIS数据集的目标值,返回值为哑编码后的数据 OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))
4 缺失值计算
使用preproccessing库的Imputer类对数据进行缺失值计算的代码如下:
from numpy import vstack, array, nan from sklearn.preprocessing import Imputer #缺失值计算,返回值为计算缺失值后的数据 #参数missing_value为缺失值的表示形式,默认为NaN #参数strategy为缺失值填充方式,默认为mean(均值) Imputer().fit_transform(vstack((array([nan, nan, nan, nan]), iris.data)))
5 数据变换
常见的数据变换有基于多项式的、基于指数函数的、基于对数函数的。
使用preproccessing库的PolynomialFeatures类对数据进行多项式转换的代码如下:
from sklearn.preprocessing import PolynomialFeatures #多项式转换 #参数degree为度,默认值为2 PolynomialFeatures().fit_transform(iris.data)
基于单变元函数的数据变换可以使用一个统一的方式完成,使用preproccessing库的FunctionTransformer对数据进行对数函数转换的代码如下:
from numpy import log1p from sklearn.preprocessing import FunctionTransformer #自定义转换函数为对数函数的数据变换 #第一个参数是单变元函数 FunctionTransformer(log1p).fit_transform(iris.data)
6 sklearn数据包功能总结
|
类
|
功能
|
说明
|
|
StandardScaler
|
无量纲化
|
标准化,基于特征矩阵的列,将特征值转换至服从标准正态分布
|
|
MinMaxScaler
|
无量纲化
|
区间缩放,基于最大最小值,将特征值转换到[0, 1]区间上
|
|
Normalizer
|
归一化
|
基于特征矩阵的行,将样本向量转换为“单位向量”
|
|
Binarizer
|
二值化
|
基于给定阈值,将定量特征按阈值划分
|
|
OneHotEncoder
|
哑编码
|
将定性数据编码为定量数据
|
|
Imputer
|
缺失值计算
|
计算缺失值,缺失值可填充为均值等
|
|
PolynomialFeatures
|
多项式数据转换
|
多项式数据转换
|
|
FunctionTransformer
|
自定义单元数据转换
|
使用单变元的函数来转换数据
|