一、问题背景 - 正则表达式匹配任意字符
正则表达式中,“.”(点符号)匹配的是除了换行符“\n”以外的所有字符。但有时候我们需要匹配包括换行符在内的字符,发现了几种正则表达式匹配任意字符(包括换行符)的方法。
可以用 ([\s\S]*),也可以用 “([\d\D]*)”、“([\w\W]*)” 来匹配,就可以匹配包括换行符在内的任意字符。
然后看一下我想匹配 url 链接为 mp4 链接,起初我这样写,发现是 false,当时没注意,发现就奇怪了,咋回事,然后查资料,发现学习了下面第二章(也算是因马虎无意获得另外一个小知识点)
let reg = /^(http).(\.mp4)$/
reg.test('http://wewe.mp4') // false
其实原因是我中间的 “.” (点符号)只代表匹配的字符,我们还需要加上匹配的个数限制(不加匹配个数限制就代表只匹配 1 个,中间不是 1 个所以是 false。)
// 验证一下这样就是 true 了
reg.test('http:.mp4')
所以我们需要加上多字符匹配的匹配个数限制,一般有 6 种:*、+、?、{m}、{m,}、{m,n},如下面示例
let reg = /^(http).*(\.mp4)$/
reg.test('http://wewe.mp4') // true
reg.test('http://wewe.mP4') // false
// 我们加上忽略大小写,就可以为 true 啦
let reg = /^(http).*(\.mp4)$/i
reg.test('http://wewe.mP4') // true
二、语法错误 Uncaught SyntaxError: Invalid regular expression - Nothing to repeat 的原因
还有一个运行时偶然发现的问题就是 匹配个数符号是不能仅仅作为分组里的唯一字符的,否则会报语法错误:Uncaught SyntaxError: Invalid regular expression - Nothing to repeat,很容易理解就是语法错误,没有东西去 repeat。
let reg = /(http)(*)(.mp4)/
reg.test('http://wewe.mP4')
// VM385:1 Uncaught SyntaxError: Invalid regular expression: /(http)(*)(.mp4)/: Nothing to repeat
三、为什么使用正则 RegExp.test() 方法时第一次是 true,第二次却是 false?
1、问题背景
也是我在测试运行时发现一个问题,然后网上查了下发现原来是个知识点:现在需要多次匹配同一个内容,但是为什么我第一次匹配,直接是 true,而第二次匹配确实 false 呢?
var s1 = "MRLP";
var s2 = "MRLP";
var reg = /mrlp/ig;
console.log(reg.test(s1));
console.log(reg.test(s2));
这时候你会发现,我们在连续使用一个正则匹配其他字符串的时候,第一次匹配是 true,而第二次匹配则是 false。
等等,WHY?我匹配的是 MRLP,而且我还特意加上i 用于不区分大小写,可以为什么第一次可以正常匹配,第二次就不行了呢?这也就是我今天要跟大家说的,关于 JS 中的 lastIndex。
2、lastIndex
首先先带大家简单回顾一下 JS中正则表达式的使用方式。JS 中正则表达式的使用方式有两种:
(1)第一种是正则表达式对象的方法,常用方法有两个。
exec(str) : 检索字符串中指定的值。返回找到的值,并确定其位置
test(str) : 检索字符串中指定的值。返回 true 或 false
(2)第二种是字符串对象的方法,常用方法有四个。
match(regexp) : 找到一个或多个正则表达式的匹配,返回一个配配的数组(该数组的内容依赖于 regexp 是否具有全局标志 g。)
replace(regexp/substr,replacement) : 替换与正则表达式匹配的子串,返回一个新的字符串(replacement可以是字符串或函数、lambda表达式)
search(regexp) : 检索与正则表达式相匹配的值,返回相匹配的子串的起始位置,否则返回 -1。(它将忽略标志g和 lastIndex属性,且总是从字符串的开始处进行检索)
split(search) : 把字符串根据正则匹配的字符,分割为字符串数组,返回数组
而这些方法和咱们今天所说的 lastIndex 有什么关系呢?重点来了,记笔记:
(1)lastIndex 属性用于规定下次匹配的起始位置。
(2)上次匹配的结果是由方法 RegExp.exec() 和 RegExp.test() 找到的,它们都以 lastIndex 属性所指的位置作为下次检索的起始点。
(3)这样,就可以通过反复调用这两个方法来遍历一个字符串中的所有匹配文本。
(4)而且需要注意,该属性只有设置标志 g才能使用。
既然已经知道这个东西的形成原因,那么解决起来就非常简单了。
3、解决方案
(1)第一种解决方案:不使用 全局模式
如上面所述,我们 lastIndex 属性必须要设置 g 标签才能使用。那么我们在匹配的时候,可以根据情况,直接去掉 g 标签就可以啦。
(2)第二种解决方案:重置 lastIndex 属性
很多时候,我们必须要执行 全局匹配(g),这时候就不能使用第一种方案了。
其实,我们的 lastIndex 属性是可读可写的。只要目标字符串的下一次搜索开始,就可以对它进行设置。当方法 exec() 或 test() 再也找不到可以匹配的文本时,它们会自动把 lastIndex 属性重置为 0。这样,我们再次执行全局匹配的时候,就不会出现 false 的情况了。
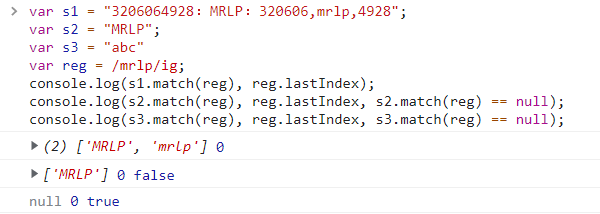
var s1 = "3206064928:MRLP:3206064928";
var s2 = "MRLP";
var reg = /mrlp/ig;
console.log(reg.test(s1)); //true
console.log(reg.lastIndex); //reg.lastIndex = 15
reg.lastIndex = 0; //这里我将 lastIndex 重置为 0
console.log(reg.test(s2)); //true
(3)第三种解决方式:改用 match() 来替换 test() 做判断
我们使用string.match()方法,判断返回值是否为Null对象:为 null - 不包含;不为 null - 包含。