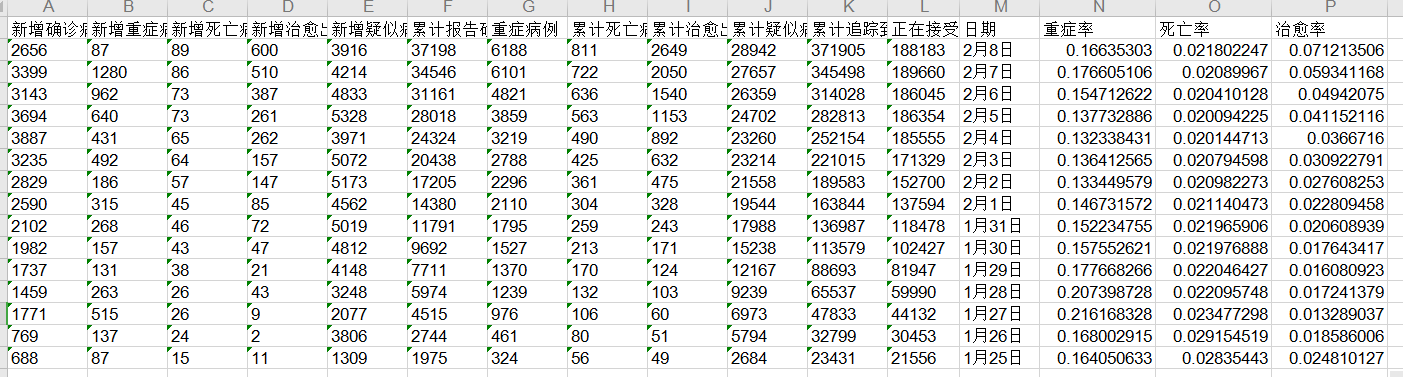
今天爬取全国新型冠状病毒感染的肺炎疫情数据
设计思路
1,获取网页数据
2,提取想要的内容
3,储存到excel表格中
代码设计
1 #_*_coding:utf-8_*_ 2 # 爬取新型冠状病毒肺炎疫情 3 import requests 4 import re 5 import xlw 6 7 8 def get_info(txt2_3): 9 Newly_confirmed_cases = re.findall('.*?新增确诊病例(.*?)例', txt2_3, re.S) 10 print("新增确诊病例", Newly_confirmed_cases[0]) 11 12 New_severe_cases = re.findall('.*?新增重症病例(.*?)例', txt2_3, re.S) 13 print("新增重症病例", New_severe_cases[0]) 14 15 New_deaths = re.findall('.*?新增死亡病例(.*?)例', txt2_3, re.S) 16 print("新增死亡病例", New_deaths[0]) 17 18 New_cured_discharge_cases = re.findall('.*?新增治愈出院病例(.*?)例', txt2_3, re.S) 19 if New_cured_discharge_cases: 20 print("新增治愈出院病例", New_cured_discharge_cases[0]) 21 else: 22 New_cured_discharge_cases = re.findall('.*?新增治愈出院(.*?)例', txt2_3, re.S) 23 print("新增治愈出院病例", New_cured_discharge_cases[0]) 24 25 New_suspected_cases = re.findall('.*?新增疑似病例(.*?)例', txt2_3, re.S) 26 print("新增疑似病例", New_suspected_cases[0]) 27 28 Cumulative_reported_confirmed_cases = re.findall('.*?累计报告确诊病例(.*?)例', txt2_3, re.S) 29 print("累计报告确诊病例", Cumulative_reported_confirmed_cases[0]) 30 31 Severe_cases = re.findall('.*?重症病例(.*?)例', txt2_3, re.S) 32 print("重症病例", Severe_cases[1]) 33 34 Cumulative_deaths = re.findall('.*?累计死亡病例(.*?)例', txt2_3, re.S) 35 if Cumulative_deaths: 36 print("累计死亡病例", Cumulative_deaths[0]) 37 else : 38 Cumulative_deaths = re.findall('.*?累计死亡(.*?)例', txt2_3, re.S) 39 print("累计死亡病例", Cumulative_deaths[0]) 40 41 Accumulative_cured_discharged_cases = re.findall('.*?累计治愈出院病例(.*?)例', txt2_3, re.S) 42 if Accumulative_cured_discharged_cases: 43 print("累计治愈出院病例", Accumulative_cured_discharged_cases[0]) 44 else: 45 Accumulative_cured_discharged_cases = re.findall('.*?累计治愈出院(.*?)例', txt2_3, re.S) 46 print("累计治愈出院病例", Accumulative_cured_discharged_cases[0]) 47 48 Cumulative_suspected_cases = re.findall('.*?有疑似病例(.*?)例', txt2_3, re.S) 49 print("累计疑似病例", Cumulative_suspected_cases[0]) 50 51 Close_contacts = re.findall('.*?追踪到密切接触者(.*?)人', txt2_3, re.S) 52 print("累计追踪到密切接触者", Close_contacts[0]) 53 54 Under_medical_observation = re.findall('.*?人,现有(.*?)人正在接受医学观察', txt2_3, re.S) 55 if Under_medical_observation: 56 print("正在接受医学观察人数", Under_medical_observation[0]) 57 else: 58 Under_medical_observation = re.findall('.*?人,共有(.*?)人正在接受医学观察', txt2_3, re.S) 59 if Under_medical_observation: 60 print("正在接受医学观察人数", Under_medical_observation[0]) 61 else: 62 Under_medical_observation = re.findall('.*?尚在医学观察的密切接触者(.*?)人', txt2_3, re.S) 63 print("正在接受医学观察人数", Under_medical_observation[0]) 64 day = re.findall('(.*?)0—24时',txt2_3,re.S) 65 if day: 66 print("日期", day[0]) 67 else : 68 day = re.findall('(.*?)0-24时', txt2_3, re.S) 69 print("日期", day[0]) 70 71 data = {} 72 data['Newly_confirmed_cases'] = Newly_confirmed_cases[0] 73 data['New_severe_cases'] = New_severe_cases[0] 74 data['New_deaths'] = New_deaths[0] 75 data['New_cured_discharge_cases'] = New_cured_discharge_cases[0] 76 data['New_suspected_cases'] = New_suspected_cases[0] 77 data['Cumulative_reported_confirmed_cases'] = Cumulative_reported_confirmed_cases[0] 78 data['Severe_cases'] = Severe_cases[1] 79 data['Cumulative_deaths'] = Cumulative_deaths[0] 80 data['Accumulative_cured_discharged_cases'] = Accumulative_cured_discharged_cases[0] 81 data['Cumulative_suspected_cases'] = Cumulative_suspected_cases[0] 82 data['Close_contacts'] = Close_contacts[0] 83 data['Under_medical_observation'] = Under_medical_observation[0] 84 data['day'] = day[0] 85 return data 86 87 def write_TXT(): 88 DATA = [] 89 f = open('virus.txt', 'r', encoding='utf-8') 90 edges = [line.strip('————') for line in f] 91 for i in range(len(edges)): 92 edges[i] = edges[i].replace(' ', '') 93 contents = [] 94 content = '' 95 for item in edges: 96 if item: 97 content += item 98 else: 99 contents.append(content) 100 content = '' 101 continue 102 contents.append(content) 103 for item in contents: 104 datas = get_info(item) 105 DATA.append(datas) # 将所有的数据添加到DATA里 106 107 108 f = xlwt.Workbook(encoding='utf-8') 109 sheet01 = f.add_sheet(u'sheet1', cell_overwrite_ok=True) 110 sheet01.write(0, 0, '新增确诊病例') # 第一行第一列 111 sheet01.write(0, 1, '新增重症病例') 112 sheet01.write(0, 2, '新增死亡病例') 113 sheet01.write(0, 3, '新增治愈出院病例') 114 sheet01.write(0, 4, '新增疑似病例') 115 sheet01.write(0, 5, '累计报告确诊病例') 116 sheet01.write(0, 6, '重症病例') 117 sheet01.write(0, 7, '累计死亡病例') 118 sheet01.write(0, 8, '累计治愈出院病例') 119 sheet01.write(0, 9, '累计疑似病例') 120 sheet01.write(0, 10, '累计追踪到密切接触者') 121 sheet01.write(0, 11, '正在接受医学观察人数') 122 sheet01.write(0, 12, '日期') 123 # 写内容 124 for i in range(len(DATA)): 125 sheet01.write(i + 1, 0, DATA[i]['Newly_confirmed_cases']) 126 sheet01.write(i + 1, 1, DATA[i]['New_severe_cases']) 127 sheet01.write(i + 1, 2, DATA[i]['New_deaths']) 128 sheet01.write(i + 1, 3, DATA[i]['New_cured_discharge_cases']) 129 sheet01.write(i + 1, 4, DATA[i]['New_suspected_cases']) 130 sheet01.write(i + 1, 5, DATA[i]['Cumulative_reported_confirmed_cases']) 131 sheet01.write(i + 1, 6, DATA[i]['Severe_cases']) 132 sheet01.write(i + 1, 7, DATA[i]['Cumulative_deaths']) 133 sheet01.write(i + 1, 8, DATA[i]['Accumulative_cured_discharged_cases']) 134 sheet01.write(i + 1, 9, DATA[i]['Cumulative_suspected_cases']) 135 sheet01.write(i + 1, 10, DATA[i]['Close_contacts']) 136 sheet01.write(i + 1, 11, DATA[i]['Under_medical_observation']) 137 sheet01.write(i + 1, 12, DATA[i]['day']) 138 print('p', end='') 139 f.save('D:\爬虫数据\新型冠状病毒感染的肺炎疫情数据.xls') 140 141 if __name__ == '__main__': 142 write_TXT()
遇见的问题:
一,获取不了国家卫健委网页数据
解决办法:手动打开网页复制网页数据储存在文本中
二,由于提取数据的对象组不是完全固定的样式,它会有细微的变化,比如它要表示累计出院病例的数量会说“累计治愈出院病例xxx例”也可能会说“累计治愈出院xxx例”,除此之外,它表示相同的内容的顺序也会变化,比如把新增重症人数放在新增治愈人数前,也有可能把新增治愈人数放在新增重症病人人数前,所以传统的一次提取数据的方法就不可取了。
解决办法:把所要提取的信息单独出来,把有可能出现多种表达方式的信息多样化处理。