Deep Learning
一、Framework
1. MobileNet
将标准卷积拆分成两部,第一次卷积不进行channel间卷积(逐层卷积:depthwise convolution),即一个输入channel对应一个卷积滤波器;第二次只进行channel间卷积,即使用1x1卷积核。如图,原来的参数个数为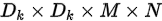 ,现在变为
,现在变为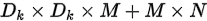 ,参数个数整体减少N倍。
,参数个数整体减少N倍。

2. ShuffleNet
以前Inception网络group时,各个通道之间都是独立的,现在将各个通道打乱,增强通道间的交互信息。

ShuffleNet使用类似MobileNet的网络,就是增加了通道间的shuffle,去掉了ReLU。先1x1 pointwise conv, 然后shuffle, 再进行3x3 Detpthwise conv,作者说1x1, 3x3的顺序不重要。

实验结果:

相对于MobileNet,ShuffleNet的前向计算量不仅有效地得到了减少,而且分类错误率也有明显提升,验证了网络的可行性。
3. Network in Network
利用 Mlpconv 和 全局平均 pooling 建立了 Network in Network 网络结构。
Mlpconv: mlpcon 指的是: multilayer perceptron + convolution;

过程如下:
假设上面的第三个图中的输入为2*(4 4), 输出为2 * (33)时:
- 第一层的卷积核大小为2*2, 步长为1, 输入为2*(4 *4), 输出为 4*(3*3);
- 第二层的卷积核大小为1*1, 步长为1, 输入为4*(3 *3), 输出为 3*(3*3);
- 第三层的卷积核大小为1*1, 步长为1, 输入为3*(3 *3), 输出为 2*(3*3);
后面两层的卷积核大小为1x1,意味着每个卷积核只进行不同通道间的累加,而不进行同一个Feature Map上的卷积,保证Feature Map大小不变。整个mlpconv的效果就相当于使用了第一层的卷积核大小,第三层的通道数的一层卷积。但好处是复杂的结构增加了网络的非线性,使网络表征非线性能力增强。文中也说明了 NIN比 maxout networks 更 non-linearity;

全局平均池化:即每个feature map平均池化成一个值,如果有m个通道,就会生成一个m维的向量(传统方法使用全连接层生成固定维度向量,但全连接层需要参数多,容易过拟合,dropout可以缓解这个问题),然后使用softmax分类:

http://blog.csdn.net/diamonjoy_zone/article/details/70229148
https://www.cnblogs.com/yinheyi/p/6978223.html
4. Mask RCNN(ICCV 2017 Best paper)

原来的分割都是对整张图片的所有目标进行多分类,输入一张图片,会输出一张整体的mask,如下图左边。
作者现在用分类框来辅导分割,那么现在在分类框内做分割只需要做二分类,减少其它的干扰。同时,作者将分类工作与分割工作进行解耦,分类和分割是两个过程,先分类,在对每个分类框进行分割。如下图左边所示。

http://blog.csdn.net/linolzhang/article/details/71774168
5. GoogleNet Inception
使用了1×1,3×3,5×5的卷积核,又因为pooling也是CNN成功的原因之一,所以把pooling也算到了里面,然后将结果在拼起来。

发展:
Inception V1, V2, V3, V4
Inception-Resnet V1, V2
Inception V1——构建了1x1、3x3、5x5的 conv 和3x3的 pooling 的分支网络,同时使用 MLPConv 和全局平均池化,扩宽卷积层网络宽度,增加了网络对尺度的适应性;
Inception V2——提出了 Batch Normalization,代替 Dropout 和 LRN,其正则化的效果让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高,同时学习 VGG 使用两个3´3的卷积核代替5´5的卷积核,在降低参数量同时提高网络学习能力;
Inception V3——引入了 Factorization,将一个较大的二维卷积拆成两个较小的一维卷积,比如将3x3卷积拆成1x3卷积和3x1卷积,一方面节约了大量参数,加速运算并减轻了过拟合,同时增加了一层非线性扩展模型表达能力,除了在 Inception Module 中使用分支,还在分支中使用了分支(Network In Network In Network);
Inception V4——设计了一个更深更优化的 Inception v4 模型。另外研究了 Inception Module 结合 ResNet,inception-resnet-v1, inception-resnet-v2 可以极大地加速训练,同时极大提升性能。而Inception v4可以达到和inception-resnet-v2 相媲美的性能。
http://blog.csdn.net/stdcoutzyx/article/details/51052847
http://blog.csdn.net/yuanchheneducn/article/details/53045551
6. SqueezeNet
作者提出了一个类似inception的网络单元结构,取名为fire module。使用这个模块代替原始的3x3卷积,一个fire module 包含一个squeeze 卷积层(只包含1x1卷积核)和一个expand卷积层(包含1x1和3x3卷积核)。其中,squeeze层借鉴了inception的思想,利用1x1卷积核来降低输入到expand层中3x3卷积核的输入通道数。

相比传统的压缩方法,SqueezeNet能在保证精度不损(甚至略有提升)的情况下,达到最大的压缩率,将原始AlexNet从240MB压缩至4.8MB,而结合Deep Compression后更能达到0.47MB,完全满足了移动端的部署和低带宽网络的传输。

7. Deep Compression
《Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding》
进行权重文件压缩:

1、Pruning(权值剪枝)
2、Quantization (权值量化) codebook
3、Huffman encoding(霍夫曼编码)
http://blog.csdn.net/QcloudCommunity/article/details/77719498
8. MoblieNet-SSD
SSD的MobileNet实现,caffemodel大小只有22.1M左右。
9. RetinaNet, Focol Loss (ICCV 2017 Best Student paper)
深度学习目标检测主要有两种方法:
- 两步检测,如RCNN、Faster RCNN,这样的检测效果好,但速度慢
- 一步检测,如YOLO、SSD,这样的检测速度快,但效果稍差。
作者改进了损失函数,使得在效果、速度上都取得了较好的效果。
二分类问题的原始交叉熵损失函数:

作者做了两方面改进,一个是针对样本不均衡的问题,如果一个类别样本少,它的权重就要大一些。作者用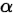 来调节样本少的类,用一类的调节参数即为
来调节样本少的类,用一类的调节参数即为 。
。

作者另一方面在分类错误度上进行惩罚,分类偏离越大,惩罚的权重也应该越大。

虽然cross_entroy在设计上对分类偏离越大的样本给予越大的损失,但作者想加入一个调节因子可以加大调节力度。如果分类概率为0.2, 那么结果为 ,可以看见当分类正确概率越低,前面的调节因子可以起到加大这种loss的作用;当分类正确概率接近1的时候,前面的调节因子就会很小,导致最后的损失函数变小,这正是想要的结果:惩罚大的分类误差。
,可以看见当分类正确概率越低,前面的调节因子可以起到加大这种loss的作用;当分类正确概率接近1的时候,前面的调节因子就会很小,导致最后的损失函数变小,这正是想要的结果:惩罚大的分类误差。
最后,作者结合两者,给出了最后的损失函数形式:

tensorflow实现:
- import tensorflow as tf
- from tensorflow.python.ops import array_ops
- def focal_loss(prediction_tensor, target_tensor, weights=None, alpha=0.25, gamma=2):
- r"""Compute focal loss for predictions.
- Multi-labels Focal loss formula:
- FL = -alpha * (z-p)^gamma * log(p) -(1-alpha) * p^gamma * log(1-p)
- ,which alpha = 0.25, gamma = 2, p = sigmoid(x), z = target_tensor.
- Args:
- prediction_tensor: A float tensor of shape [batch_size, num_anchors,
- num_classes] representing the predicted logits for each class
- target_tensor: A float tensor of shape [batch_size, num_anchors,
- num_classes] representing one-hot encoded classification targets
- weights: A float tensor of shape [batch_size, num_anchors]
- alpha: A scalar tensor for focal loss alpha hyper-parameter
- gamma: A scalar tensor for focal loss gamma hyper-parameter
- Returns:
- loss: A (scalar) tensor representing the value of the loss function
- """
- sigmoid_p = tf.nn.sigmoid(prediction_tensor)
- zeros = array_ops.zeros_like(sigmoid_p, dtype=sigmoid_p.dtype)
-
- # For poitive prediction, only need consider front part loss, back part is 0;
- # target_tensor > zeros <=> z=1, so poitive coefficient = z - p.
- pos_p_sub = array_ops.where(target_tensor > zeros, target_tensor - sigmoid_p, zeros)
-
- # For negative prediction, only need consider back part loss, front part is 0;
- # target_tensor > zeros <=> z=1, so negative coefficient = 0.
- neg_p_sub = array_ops.where(target_tensor > zeros, zeros, sigmoid_p)
- per_entry_cross_ent = - alpha * (pos_p_sub ** gamma) * tf.log(tf.clip_by_value(sigmoid_p, 1e-8, 1.0))
- - (1 - alpha) * (neg_p_sub ** gamma) * tf.log(tf.clip_by_value(1.0 - sigmoid_p, 1e-8, 1.0))
- return tf.reduce_sum(per_entry_cross_ent)
这个代码是用来做目标检测,主要计算了两部分loss。
回顾:
进行多目标分类的loss是softmax cross entropy,公式如下:
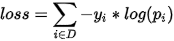
其中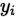 是one_hot形式。
是one_hot形式。
sigmoid二分类损失函数如下:
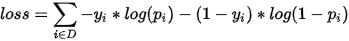
这里面的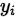 是标量,0或者1,实际上如果表示成one_hot格式,也可以使用softmax cross entropy 表示损失函数。
是标量,0或者1,实际上如果表示成one_hot格式,也可以使用softmax cross entropy 表示损失函数。
obj_loss:
既然包含目标,进行多目标分类,惩罚概率不为1的如下:
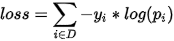
再乘上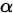 ,得:
,得:
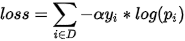
再乘上误分较大的惩罚:
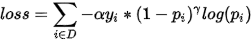
noobj_loss:
不包含目标,需要惩罚概率不为0的:

再乘上 ,得:
,得:
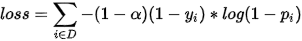
再乘上误分较大的惩罚:

最终loss:
结合obj_loss和noobj_loss,可以得到最后的loss如下:
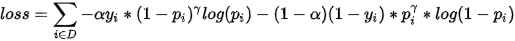
代码中将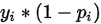 和
和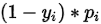 分别将标签乘进去变成了
分别将标签乘进去变成了pos_p_sub和neg_p_sub,也就以后最后的代码:
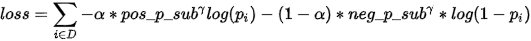
- per_entry_cross_ent = - alpha * (pos_p_sub ** gamma) * tf.log(tf.clip_by_value(sigmoid_p, 1e-8, 1.0))
- - (1 - alpha) * (neg_p_sub ** gamma) * tf.log(tf.clip_by_value(1.0 - sigmoid_p, 1e-8, 1.0))
若平时只是多分类任务,则没有第二项的,则损失函数是简单的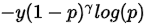 。现在因为是目标检测,所以包含了没有目标的样本,需要惩罚这部分样本,需要加入第二项。
。现在因为是目标检测,所以包含了没有目标的样本,需要惩罚这部分样本,需要加入第二项。
10. FCN(Fully Convolutional Networks)全卷积网络
全部使用卷积层,不使用全连接层。这样可以降低全连接层的参数,并且可以接受不同大小的图片做为输入。
并且经过一个反卷积,可以进行像素级的分割。

deconv,上采样方法:

http://blog.csdn.net/u010678153/article/details/48676195
https://www.cnblogs.com/gujianhan/p/6030639.html
11. FPN
SSD采取类似(c)的做法,作者利用从底层Feature Map进行上采样,然后再和对应层的特征进行融合再进行预测。

为了保证和上采样的通道数一样,使用一个1x1卷积对之前的特征图进行卷积。

12. Relation Networks for Object Detection
原来的目标检测都是针对单个目标的特征进行bbox, class score,没有考虑目标之前的关系。作者提出一种关系网络,可以在深度网络里加入关系。

对原来的外观特征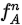 加入了与其它proposal的realtion,把这些realtion拼接在原始外观特征的后面,形成最后的特征。
加入了与其它proposal的realtion,把这些realtion拼接在原始外观特征的后面,形成最后的特征。
整体的架构如下图(a)所示,在特征拼接之后加一个全连接层。图(b)在最后添加了一个duplicate removal 网络以代替NMS。

作者把duplicate removal归结成一个二分类问题,即对于每一个gt box,只有一个detected box是被分成correct,其他的都是分成duplicate。作者的duplicate removal network是接在classifier的输出后面。该模块的输入包括object proposal的score vector(属于各个类别的概率), bbox,以及proposal的特征(典型的1024维)。
对于某一个object proposal的某一个类别,假设属于这个类别的概率为scorenscoren,首先经过一个rank embed模块,即拿出其他object proposal属于该类别的score,进行排序,得到第n个object proposal在排序中的下标(rank),作者特别说明了,使用rank值而不是直接score的值非常重要。然后将rank值映射到128维向量,同时将该proposal的特征也映射到128维,将两种128维的特征相加之后作为新的appearance feature,然后和bbox作为relation module的输入,得到新的128维的输出,和W_s做内积之后通过sigmoid得到s_1,最终的correct的概率s=s_0 * s_1。整体流程如上图(b)所示。
思考:
不管多少维的特征,都可以与一个W权重相乘,映射到任何维度,做embeding。反正W可以通过网络学习到,但映射维度要如何选择呢。
http://blog.csdn.net/yaoqi_isee/article/details/78696954
13. MobileNet V2
MobileNet V1将一个normal 卷积分解成两个部分:Depthwise convolution + Pixelwise Convolution,从而极大的降低了参数数量。
MobileNet V2提出两个方面的改进:
- revert residuals,加入了改进的residuals, 之前的residual block都是先用1x1降维,再做3x3,再用1x1恢复原来的维度。现在是先扩张,再压缩回去。
- Linear bottlenecks,为了避免Relu对低维特征的破坏,在residual block的Eltwise sum之前的压缩 1*1 Conv 不再采用Relu。
与MobileNetV1比较,多了一个3x3之前的扩张层:

与Resnet比较:

stride=1时才进行short_cut连接:

linear bottleneck和revert residuals的性能表现:

14. Resnet
神经网络的深度是影响性能的一个重要原因,越深的网络带来更好的性能。但另一方面随着网络深度的加深,梯度消失、爆炸问题随之而来,网络出现了退化,一个56层网络的性能远不如20层的网络。
残差的思想:
如果一个卷积的作用就是从输入x映射到输出y,那么卷积的作用就相当于一个映射函数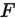 ,使得
,使得 ,那么这些F函数中的w与x逐层作用,就可能使梯度越来越小。现在,改变一个思路,如果不是直接来求这个映射,而是求这个映射的差
,那么这些F函数中的w与x逐层作用,就可能使梯度越来越小。现在,改变一个思路,如果不是直接来求这个映射,而是求这个映射的差 ,那么卷积的作用就相当于
,那么卷积的作用就相当于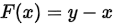 ,卷积的工作就变成了去拟合这个残差,一样可以达到从输入x到输出y的变化,但是,由于采用了short_cut,在训练时可以直接将梯度传给下一层,这样就不会出现梯度弥散的问题了。
,卷积的工作就变成了去拟合这个残差,一样可以达到从输入x到输出y的变化,但是,由于采用了short_cut,在训练时可以直接将梯度传给下一层,这样就不会出现梯度弥散的问题了。
resnet的结构如下,起初是左边的形式,input通过两个3x3 conv和short_cut相加。后来,为了提高训练速度,提出右边的bottle-neck结构,就是先进行1x1的降维,再进行3x3的卷积,再通过1x1提升到原来的维度,这样可以使3x3具有较小的计算量(bootle-neck)。

为了加个short_cut就能解决梯度问题。
如下,一个网络的梯度前后、反向传播时会越来越小,导致前面几层不能得到有效的训练。


DenseNet更为极端,它的skip connection不仅仅只连接上下层,直接实现了跨层连接,每一层获得的梯度都是来自前面几层的梯度加成。

二、Face Recognition
face++: 使用从网络搜集的500万张人脸图片训练深度网络模型。在lfw数据集上有用,在现实生活中效果还是不行
baidu: 在人脸的各个区域分别利用神经网络提取特征,提取到的特征通过metric learning降维到128维。
pose+shape+expression augmentation: face++,DeepID,FaceNet等需要基于百万级人脸图像的训练才能达到高精度。而搜集百万级人脸数据所耗费的人力,物力,财力是很大的,所以商业公司使用的图像数据库是不公开的。采用了新的人脸数据扩增方法。对现有公共数据库人脸图像,从pose,shape和expression三个方面合成新的人脸图像,极大的扩增数据量。
CNN-3DMM estimation: 他们采用了卷积神经网络(CNN)来根据输入照片来调节三维人脸模型的脸型和纹理参数,利用3D重建模型扩充人脸。
FR+FCN: 与当前使用2d环境或者3d信息来进行人脸重建的方法不同,该方法直接从人脸图像之中学习到图像中的规则观察体(canonical view,标准正面人脸图像)。作者开发了一种从个体照片中自动选择/合成canonical-view的方法。
第一类:face++,DeepFace,DeepID,FaceNet和baidu。他们方法的核心是搜集大数据,通过更多更全的数据集让模型学会去识别人脸的多样性。这类方法适合百度/腾讯/谷歌等大企业,未来可以搜集更多更全的训练数据集。数据集包扩同一个体不同年龄段的照片,不同人种的照片,不同类型(美丑等)。通过更全面的数据,提高模型对现场应用中人脸差异的适应能力。
第二类:FR+FCN,pose+shape+expression augmentation和CNN-3DMM estimation。这类方法采用的是合成的思路,通过3D模型等合成不同类型的人脸,增加数据集。这类方法操作成本更低,更适合推广。其中,特别是CNN-3DMM estimation,作者做了非常出色的工作,同时提供了源码,可以进一步参考和深度研究。
https://zhuanlan.zhihu.com/p/24816781
1. FaceNet
Google提供FaceNet用于人脸识别,lfw准确率: 99.63%。
FaceNet主要工作是使用triplet loss,组成一个三元组 ,x表示一个样例,
,x表示一个样例,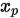 表示和x同一类的样例,
表示和x同一类的样例,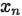 表示和x不是同一类的样例。
表示和x不是同一类的样例。
loss就是同类的距离(欧几里德距离)减去异类的距离:
- 如果<=0,则loss为0;
- 如果>0, 则表明同类距离要长,分类不正确,要计入loss中。
另外,加入一个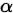 ,表示希望两个距离之间的最小边界,论文中设为0.2,如下公式:
,表示希望两个距离之间的最小边界,论文中设为0.2,如下公式:
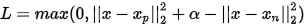

2. DeepFace
2014年,DeepFace是facebook提出的方法,这篇论文早于DeepID和FaceNet,但其所使用的方法在后面的论文中都有体现,可谓是早期的奠基之作。准确率:97.25%。
3D人脸矫正,过程如下:
a. 人脸检测,使用6个基点
b. 二维剪切,将人脸部分裁剪出来
c. 67个基点,然后Delaunay三角化,在轮廓处添加三角形来避免不连续
d. 将三角化后的人脸转换成3D形状
e. 三角化后的人脸变为有深度的3D三角网
f. 将三角网做偏转,使人脸的正面朝前。
g. 最后放正的人脸
h. 一个新角度的人脸(在论文中没有用到)

将矫正后的人脸输入神经网络,网络参数如下:
Conv:32个11×11×3的卷积核
max-pooling: 3×3, stride=2
Conv: 16个9×9的卷积核
Local-Conv: 16个9×9的卷积核,Local的意思是卷积核的参数不共享
Local-Conv: 16个7×7的卷积核,参数不共享
Local-Conv: 16个5×5的卷积核,参数不共享
Fully-connected: 4096维
Softmax: 4030维
后面三层都是使用参数不共享的卷积核,之所以使用参数不共享,有如下原因:
- 对齐的人脸图片中,不同的区域会有不同的统计特征,卷积的局部稳定性假设并不存在,所以使用相同的卷积核会导致信息的丢失
- 不共享的卷积核并不增加抽取特征时的计算量,而会增加训练时的计算量
- 使用不共享的卷积核,需要训练的参数量大大增加,因而需要很大的数据量,然而这个条件本文刚好满足。

DeepFace与之后的方法的最大的不同点在于,DeepFace在训练神经网络前,使用了对齐方法。论文认为神经网络能够work的原因在于一旦人脸经过对齐后,人脸区域的特征就固定在某些像素上了,此时,可以用卷积神经网络来学习特征。
针对同样的问题,DeepID和FaceNet并没有对齐,DeepID的解决方案是将一个人脸切成很多部分,每个部分都训练一个模型,然后模型聚合。FaceNet则是没有考虑这一点,直接以数据量大和特殊的目标函数取胜。
在DeepFace论文中,只使用CNN提取到的特征,这点倒是开后面之先河,后面的DeepID、FaceNet全都是使用CNN提取特征了,再也不谈LBP了。
http://blog.csdn.net/stdcoutzyx/article/details/46776415
3. DeepID3
lfw准确率:99.53%。
借鉴了VGG net3和GoogLeNet4,使用了更深的网络,引入了inception layer。网络中还出现了连续两个conv layer直接相连的情况,这样使得网络具有更大的receptive fields和更复杂的nonlinearity。
http://blog.csdn.net/yiyouxian/article/details/52145727
三、Trick
1. 1x1卷积
1x1卷积,又叫elementwise conv,是在相同的一个位置点上进行不同通道间的权重累加。
CNN中,1X1卷积核到底有什么作用呢?
1.实现跨通道的交互和信息整合
2.进行卷积核通道数的降维和升维
https://www.jianshu.com/p/ba51f8c6e348
同时,还有一种叫depthwise conv,它是一个卷积核只在一个输入通道上进行卷积,不进行通道间的计算。
depthwise的tensorflow实现:
tf.nn.depthwise_conv2d(input,filter,strides,padding,rate=None,name=None,data_format=None)
input: [batch_size, h, w, in_channels]
output: [filter_width, filter_width, in_channels, channel_multiplier], channel_multiplier是输出卷积乘子,即输出的卷积通道数为in_channels * channel_multiplier。
strides: 卷积步长
padding: 包括SAME, VALID
rate: 实现空洞卷积,空洞卷积的洞个数,如果rate是大于1的正数,stride必须等于1
http://blog.csdn.net/mao_xiao_feng/article/details/78003476
组合这两种操作,可以得到一个完整的卷积操作,而参数的数量却大大缩小,这就是MoblieNet的原理了。
2. parameter
google net 中的solver文件参数:
net: "models/bvlc_googlenet/train_val.prototxt"
test_iter: 1000 # test_iter * batch_size = test_size
test_interval: 4000 #每训练多少次进行一次测试
test_initialization: false #取值为true或者false,默认为true,就是刚启动就进行测试,false的话不进行第一次的测试。
display: 40 #每40次显示一次loss
average_loss: 40 #取40次迭代平均loss显示出来
base_lr: 0.01
lr_policy: "step"
stepsize: 320000 # 每隔stepsize降低学习速率,每隔stepsize,基础学习速率*gamma
gamma: 0.96 #lr 更新参数,还有power
max_iter: 10000000
momentum: 0.9
weight_decay: 0.0002
snapshot: 40000
snapshot_prefix: "models/bvlc_googlenet/bvlc_googlenet"
solver_mode: GPU
Doing validation every 0.25 epoch may be OK. Just make sure that training loss and validation convergence at the same time.
每0.25个epoch进行一次验证,确保traning loss和validation loss都收敛。
solver参数的解析:
1. weight decay
为了避免overfitting,一般会加上参数(w)正则项用来约束模型复杂度。weight decay用以控制约束项的作用大小。这时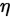 是学习率,
是学习率, 是正则项系数,也可能是这个所谓的weight decay。
是正则项系数,也可能是这个所谓的weight decay。

有人会问有价值的weight是不是也会decay。其实BP算法本质能对降低error function意义不大的weight变的越来越小,对于如此小的值,可以完全discard(是不是想起了dropout,呵)。而真正解决问题的weight不会随便被decay。
从原来的:
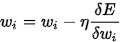
变为:
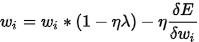
就相当于对于权重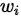 进行了一次decay,再进行后面的参数更新,它会始一些作用不大的参数越来越小,避免参数过于复杂,造成过拟合;而有用的参数可以通过权重更新较好的保留下来。
进行了一次decay,再进行后面的参数更新,它会始一些作用不大的参数越来越小,避免参数过于复杂,造成过拟合;而有用的参数可以通过权重更新较好的保留下来。
2. Learning Rate Decay:
计算学习率:

更直接的方法,每迭代1000次,学习率减少10倍
3. Momentum
动量(m),采用牛顿第二定律,惯性,在权重前面增加一个系数,可以更快地下降收敛:
原来相当于如下的式子:
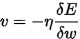
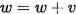
现在利用之前的保存的v来加速下降,对之前的v乘以一个m(动量,如0.9)。 现在算得的梯度为-3,如果不使用动量,那么最后更新值就是-3,如果使用动量并且之前的v假设是-9,那么最后需要更新的值为 -3 + 0.9 * (-9) = -11.1,这样在当前梯度方向和上一次方面一致的时候就起到了快速更新的作用:
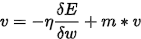

4. weigth_filler
xavier方式:
使用Uniform初始化,[-sqrt(3/n), sqrt(3/n)],n一般是number_in + number_out,保证参数初始化在一个尺度上,不要一个太大60,一个太小如0.2。
guassian:
标准分布
3. train_val.prototxt, deploy.prototxt
solver.prototxt、train_val.prototxt用于训练参数,deploy.prototxt用于前向传播。
- train_val里面详细的定义了train, test的数据地址,deploy里面则只简单提供了维度。
- train_val里面的权重初始化部分在deploy中可以去掉,如weight_filler
- train_val里面分train, test phase,train phase在输入数据部分有,test phase在输入数据、评估test准确率部分有,而在deploy不存在两个阶段。
- train_val里面最后使用的类型是SoftmaxWithLoss,输出的是loss,而deploy里面最后应该是Softmax,输出的是probs。
4. triplet loss
triplet loss是对于一个样例x,分别选取一个同类样例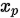 和异类样例
和异类样例 ,组成一个三元组
,组成一个三元组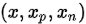 ,使得存在一个边界距离
,使得存在一个边界距离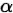 ,使 其满足
,使 其满足 ,最终的loss为:
,最终的loss为:
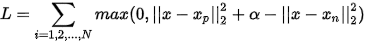
如果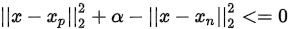 ,则loss为0,分类正确。
,则loss为0,分类正确。
如果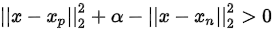 ,则存在loss,分类出错。
,则存在loss,分类出错。
http://blog.csdn.net/tangwei2014/article/details/46788025
用triplet loss替换softmax loss可以取得更好的效果:
https://www.zhihu.com/question/62486208/answer/199117070
5. embeding
使用one_hot来表示单词,如果一共有8000个单词,那就需要8000维。使用embeding方法可以降低维度,如使用100维表示。
Embedding在数学上表示一个maping, f: X -> Y, 也就是一个function,其中该函数是injective(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)。
那么对于word embedding,就是将单词word映射到另外一个空间,其中这个映射具有injective和structure-preserving的特点。
通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,那么该多维向量相当于嵌入到Y所属空间中,一个萝卜一个坑。word embedding,就是找到一个映射或者函数,生成在一个新的空间上的表达,该表达就是word representation。
推广开来,还有image embedding, video embedding, 都是一种将源数据映射到另外一个空间
6. 归一化(Normalization)、标准化(Standardization)、正则化(Regularization)
归一化:
缩放到(0, 1): 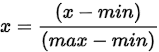
标准化:
用的最多的是 z-score标准化: 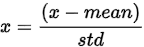
正则化:
可以用在目标函数后面约束模型复杂度,也可以进行数据处理, 能尽可能的削弱“强势”特征,将一些数值较小但是比较有特点的特征“凸显”出来。。
将每个样本缩放到单位范数(每个样本的范数为1),如果后面要使用如二次型(点积)或者其他核函数方法计算两个样本之间的相似性,这个方法会很有用。
对每个样本计算其p-范数, 每个元素再除以p范数。
l2 正则化: 
http://blog.csdn.net/power0405hf/article/details/53456162
7. 空洞卷积
又叫dilate_conv, atrous_conv。
卷积会使图片的尺寸变小,损失信息,但另一方面我们又希望可以获得更大的感受野,如何在图片减小较少的情况获取更多的感受野?
如图中所示,只计算红点的卷积,其余绿色区域权重都为0,(a)为传统的卷积,(b)(c)是空洞卷积,同样是3x3的卷积, (b)、(c)拥有更大的感受野。

https://www.zhihu.com/question/54149221/answer/192025860
Tensorflow中通过atrous_conv2d进行空洞卷积,原型如下:
tf.nn.atrous_conv2d(value,filters,rate,padding,name=None)
value: [batch_size, h, w, input_channel] 输入图片
filters: [filter_width, filter_width, input_channel, out_channel] 卷积核
rate: 控制空洞,如果=1, 正常卷积;如果=2,有1个空洞的卷积。
http://blog.csdn.net/mao_xiao_feng/article/details/78003730
10. 逆卷积(deconv)
Deconvolutional Network做图片的unsupervised feature learning,ZF-Net论文中的卷积网络可视化,FCN网络中的upsampling,GAN中的Generative图片生成。
实际上是寻找一个逆矩阵,使2x2的大小可以变换成4x4的大小,这个变换就像是4x4大小的图像用3x3卷积核卷积成2x2的逆变换,所以就叫deconv。
https://www.zhihu.com/question/43609045/answer/132235276
11. hard negative mining
在做目标检测时,会生成正负样本,由于负样本是在非ground truth ROI处随机crop得到的,所以生成的负样本很多,会造成样本不均衡。为了解决这个问题,把这些生成的负样本输入到网络中,把分类错的样本取出来做为最后的负样本。
12. 模型压缩
Network in Network
MobileNet
SqueezeNet
ShuffleNet
Network in Network:
https://arxiv.org/pdf/1312.4400.pdf
1x1 conv + avg pooling
SqueezeNet:
firemodule: 1x1 squeeze, 1x1 + 3x3 expand
paper: http://arxiv.org/abs/1602.07360
code: https://github.com/DeepScale/SqueezeNet
MobileNet:
https://arxiv.org/pdf/1704.04861.pdf
1x1 element-wise conv + 3x3 depth-wise conv
MobileNet: https://arxiv.org/pdf/1704.04861.pdf
原来的卷积权重参数个数为KxKxCxF,如图(a)。
现在将这个卷积解偶成两步:
第一步是只在一个通道上进行KxK卷积,然后逐层进行,如图(b)。
第二步是在通道间进行1x1卷积,如图(c)。
使用这种方法,参数个数变为KxKxC + CxF。
!MobileNet.png!
如果K=3, C=128, F=256, 则两种方法的参数个数分别为3x3x128x256, 3x3x128+128x256,可以减少9倍左右。
ShuffleNet:
shuffle channel
deep compresion:
https://arxiv.org/pdf/1510.00149v5.pdf
四、优秀网站
Ref
https://www.jianshu.com/p/96791a306ea5
http://blog.csdn.net/QcloudCommunity/article/details/77719498
https://www.jianshu.com/p/3d79e722ee56
https://blog.csdn.net/u011995719/article/details/79135818