前面的内容把雪花算法的时间部分和机器信息部分都生成了,下面来生成最后一部分,就是毫秒内的序列。什么意思呢?我们在生成时间部分获取时间戳的时候,使用 long now = System.currentTimeMillis(); 获取,是个毫秒级的时间戳,但是即使是这么短的时间,对于电脑来说也足够生成很多个id,所以很多id可能会在同一个毫秒内生成,也就是时间部分的数值一样。这个时候就要让同一个毫秒内生成的id加上数字序列标识,就是第三部分的序列。第三部分占的长度是12位,转成整数值就是4095,所以最后一部分的范围就是4095到0之间的数字。如果毫秒内访问的数量超过了这个限制怎么办?没法解决,只能强制等到下一毫秒再生产id。这就是第三部分的作用。
下面先定义一个序列初始值:

序列由于和时间戳有关系,所以要加载时间戳真正开始使用之前:
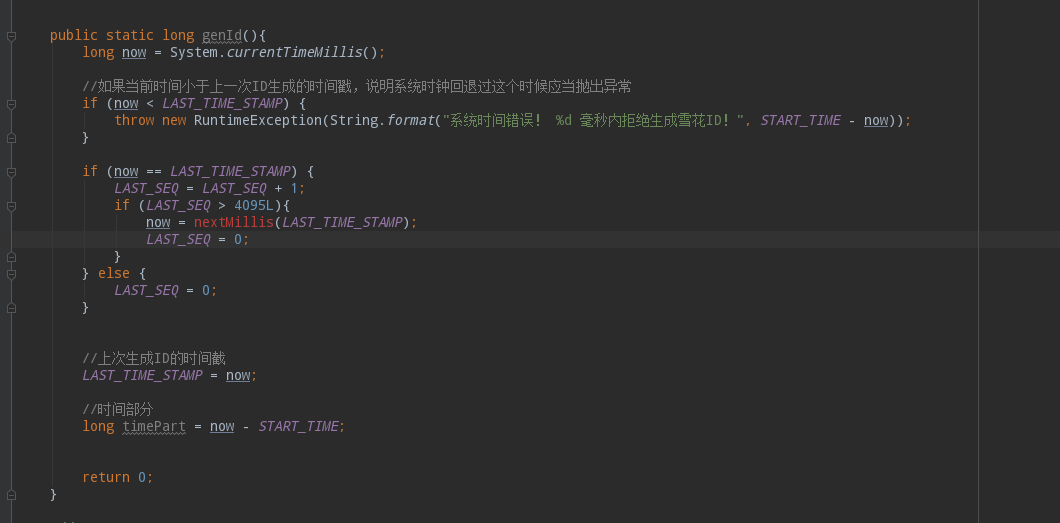
上面的逻辑做了判断,同一毫秒内就让序列加1,超过4095,就强制获取下一毫秒的值,等时间戳不是同一毫秒的时候,序列从新开始计算。看下如何强制获取下一毫秒:
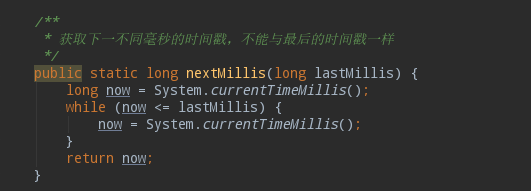
简单粗暴,就是while循环等下一毫秒就可以。这样毫秒内的序列数就算获取成功了。
我们三大部分的数字都获取成功了,最后直接位移加合并就行:

这样雪花算法就写完了,下面执行一下测试:
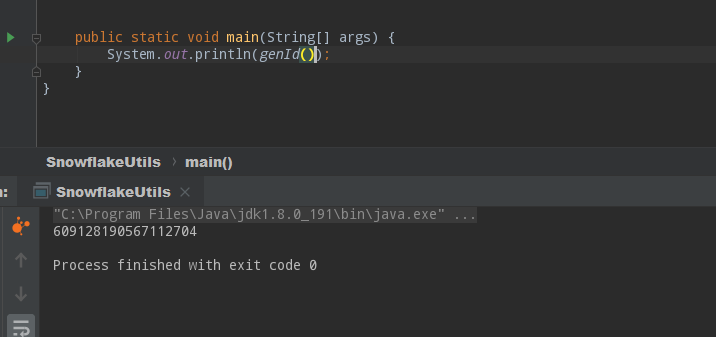
是一个18位的long类型数字,确实是我们要的结果。等等!是不是有问题?如果此时多个线程访问,会产生重复的id!现在的程序确实有多并发问题,需要加上锁:
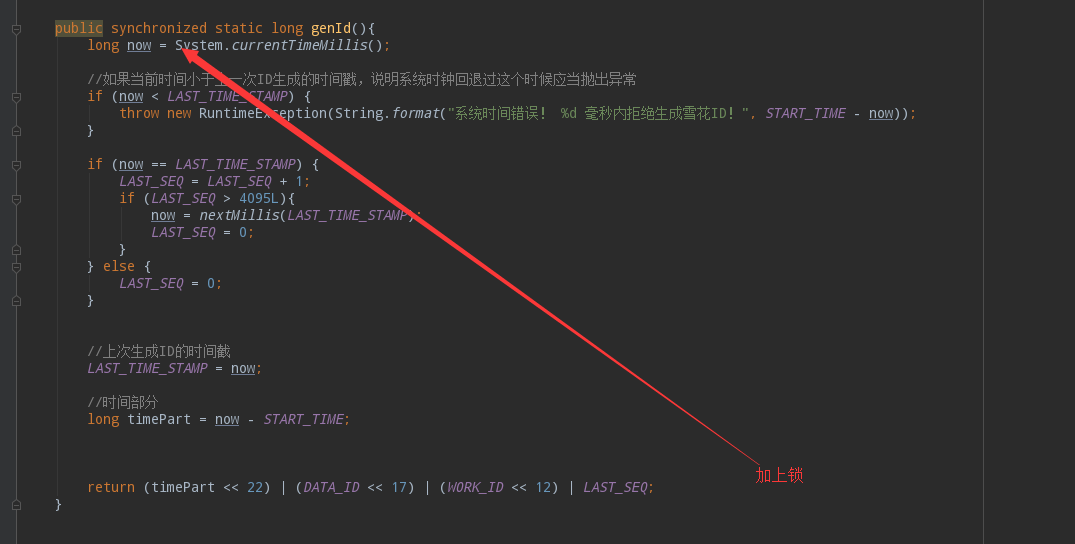
这样我们的雪花算法算是初步完成了。基本也符合项目对唯一id的要求!现在的写法和网上的例子还有些差别,下面我们讲讲差别相关的内容。