缓冲区
传统的流和通道的对比
|
流 |
通道 |
|
慢 |
快 |
|
处理简单 |
处理复杂 |
|
单字节的传输 |
一块数据的传输 |
|
- |
Java.io.*已经重新写过 |
|
- |
是对流的模拟 |
|
单向的 |
双向的 |
|
可直接访问 |
必须通过Buffer和通道打交道 |
流与块的比较
原来的 I/O 库(在 java.io.*中) 与 NIO 最重要的区别是数据打包和传输的方式。正如前面提到的,原来的 I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流 的 I/O 系统一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。为流式数据创建过滤器非常容易。链接几个过滤器,以便每个过滤器只负责单个复杂处理机制的一部分,这样也是相对简单的。不利的一面是,面向流的 I/O 通常相当慢。
一个 面向块 的 I/O 系统以块的形式处理数据。每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
1.1只读缓冲区
只读缓冲区非常简单 — 您可以读取它们,但是不能向它们写入。可以通过调用缓冲区的 asReadOnlyBuffer() 方法,将任何常规缓冲区转换为只读缓冲区,这个方法返回一个与原缓冲区完全相同的缓冲区(并与其共享数据),只不过它是只读的。
只读缓冲区对于保护数据很有用。在将缓冲区传递给某个对象的方法时,您无法知道这个方法是否会修改缓冲区中的数据。创建一个只读的缓冲区可以 保证 该缓冲区不会被修改。
不能将只读的缓冲区转换为可写的缓冲区。
1.2直接和间接缓冲区
ByteBuffer allocate()与ByteBuffer allocateDirect() 方法的区别:
在Java中当我们要对数据进行更底层的操作时,一般是操作数据的字节(byte)形式,这时经常会用到ByteBuffer这样一个类。ByteBuffer提供了两种静态实例方式:
public static ByteBuffer allocate(int capacity) public static ByteBuffer allocateDirect(int capacity)
为什么要提供两种方式呢?这与Java的内存使用机制有关。第一种分配方式产生的内存开销是在JVM中的,而另外一种的分配方式产生的开销在JVM之外,以就是系统级的内存分配。当Java程序接收到外部传来的数据时,首先是被系统内存所获取,然后在由系统内存复制复制到JVM内存中供Java程序使用。所以在另外一种分配方式中,能够省去复制这一步操作,效率上会有所提高。可是系统级内存的分配比起JVM内存的分配要耗时得多,所以并非不论什么时候allocateDirect的操作效率都是最高的。以下是一个不同容量情况下两种分配方式的操作时间对照:
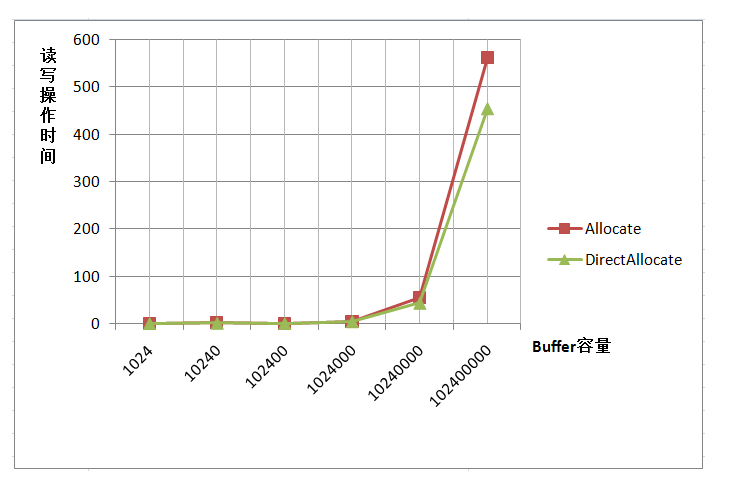
由图能够看出,当操作数据量非常小时,两种分配方式操作使用时间基本是同样的,第一种方式有时可能会更快,可是当数据量非常大时,另外一种方式会远远大于第一种的分配方式。
另一种有用的 ByteBuffer 是直接缓冲区。 直接缓冲区 是为加快 I/O 速度,而以一种特殊的方式分配其内存的缓冲区。
实际上,直接缓冲区的准确定义是与实现相关的。Sun 的文档是这样描述直接缓冲区的:
给定一个直接字节缓冲区,Java 虚拟机将尽最大努力直接对它执行本机 I/O 操作。也就是说,它会在每一次调用底层操作系统的本机 I/O 操作之前(或之后),尝试避免将缓冲区的内容拷贝到一个中间缓冲区中(或者从一个中间缓冲区中拷贝数据)。
您可以在例子程序 FastCopyFile.java 中看到直接缓冲区的实际应用,这个程序是 CopyFile.java 的另一个版本,它使用了直接缓冲区以提高速度。
还可以用内存映射文件创建直接缓冲区.
public class FastCopyFile { static public void main( String args[] ) throws Exception { if (args.length<2) { System.err.println( "Usage: java FastCopyFile infile outfile" ); System.exit( 1 ); } String infile = args[0]; String outfile = args[1]; //第一步是获取通道。我们从 FileInputStream 获取通道: FileInputStream fin = new FileInputStream( infile ); FileOutputStream fout = new FileOutputStream( outfile ); FileChannel fcin = fin.getChannel(); FileChannel fcout = fout.getChannel(); //下一步是创建缓冲区: ByteBuffer buffer = ByteBuffer.allocateDirect( 1024 );//直接缓冲区 //检查状态 //下一步是检查拷贝何时完成。当没有更多的数据时,拷贝就算完成, // 并且可以在 read() 方法返回 -1 是判断这一点,如下所示: while (true) { buffer.clear(); int r = fcin.read( buffer ); if (r==-1) { break; } buffer.flip(); //最后一步是写入缓冲区中: fcout.write( buffer ); } } }
1.3NIO 中两个重要的缓冲区组件:状态变量和访问方法 (accessor)
状态变量
可以用三个值指定缓冲区在任意时刻的状态:
positionlimitcapacity
Position
您可以回想一下,缓冲区实际上就是美化了的数组。在从通道读取时,您将所读取的数据放到底层的数组中。 position 变量跟踪已经写了多少数据。更准确地说,它指定了下一个字节将放到数组的哪一个元素中。因此,如果您从通道中读三个字节到缓冲区中,那么缓冲区的 position 将会设置为3,指向数组中第四个元素。
同样,在写入通道时,您是从缓冲区中获取数据。 position 值跟踪从缓冲区中获取了多少数据。更准确地说,它指定下一个字节来自数组的哪一个元素。因此如果从缓冲区写了5个字节到通道中,那么缓冲区的 position 将被设置为5,指向数组的第六个元素。
Limit
limit 变量表明还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。
position 总是小于或者等于 limit。
Capacity
缓冲区的 capacity 表明可以储存在缓冲区中的最大数据容量。实际上,它指定了底层数组的大小 ― 或者至少是指定了准许我们使用的底层数组的容量。
limit 决不能大于 capacity。



访问方法
到目前为止,我们只是使用缓冲区将数据从一个通道转移到另一个通道。然而,程序经常需要直接处理数据。例如,您可能需要将用户数据保存到磁盘。在这种情况下,您必须将这些数据直接放入缓冲区,然后用通道将缓冲区写入磁盘。
或者,您可能想要从磁盘读取用户数据。在这种情况下,您要将数据从通道读到缓冲区中,然后检查缓冲区中的数据。
在本节的最后,我们将详细分析如何使用 ByteBuffer 类的 get() 和 put() 方法直接访问缓冲区中的数据。
get() 方法
ByteBuffer 类中有四个 get() 方法:
byte get();ByteBuffer get( byte dst[] );ByteBuffer get( byte dst[], int offset, int length );byte get( int index );
第一个方法获取单个字节。第二和第三个方法将一组字节读到一个数组中。第四个方法从缓冲区中的特定位置获取字节。那些返回 ByteBuffer 的方法只是返回调用它们的缓冲区的 this 值。
此外,我们认为前三个 get() 方法是相对的,而最后一个方法是绝对的。 相对 意味着 get() 操作服从 limit 和 position 值 ― 更明确地说,字节是从当前 position 读取的,而 position 在 get 之后会增加。另一方面,一个 绝对 方法会忽略 limit 和 position 值,也不会影响它们。事实上,它完全绕过了缓冲区的统计方法。
上面列出的方法对应于 ByteBuffer 类。其他类有等价的 get() 方法,这些方法除了不是处理字节外,其它方面是是完全一样的,它们处理的是与该缓冲区类相适应的类型。
put()方法
ByteBuffer 类中有五个 put() 方法:
ByteBuffer put( byte b );ByteBuffer put( byte src[] );ByteBuffer put( byte src[], int offset, int length );ByteBuffer put( ByteBuffer src );ByteBuffer put( int index, byte b );
第一个方法 写入(put) 单个字节。第二和第三个方法写入来自一个数组的一组字节。第四个方法将数据从一个给定的源 ByteBuffer 写入这个 ByteBuffer。第五个方法将字节写入缓冲区中特定的 位置 。那些返回 ByteBuffer 的方法只是返回调用它们的缓冲区的 this 值。
与 get() 方法一样,我们将把 put() 方法划分为 相对 或者 绝对 的。前四个方法是相对的,而第五个方法是绝对的。
上面显示的方法对应于 ByteBuffer 类。其他类有等价的 put() 方法,这些方法除了不是处理字节之外,其它方面是完全一样的。它们处理的是与该缓冲区类相适应的类型。
1.4缓冲区分配和包装
在能够读和写之前,必须有一个缓冲区。要创建缓冲区,您必须 分配 它。我们使用静态方法 allocate() 来分配缓冲区:
ByteBuffer buffer = ByteBuffer.allocate( 1024 );
allocate() 方法分配一个具有指定大小的底层数组,并将它包装到一个缓冲区对象中 ― 在本例中是一个 ByteBuffer。
您还可以将一个现有的数组转换为缓冲区,如下所示:
byte array[] = new byte[1024]; ByteBuffer buffer = ByteBuffer.wrap( array );
创建缓冲区的两种方法:
方法一:使用静态方法 allocate() 来分配缓冲区
public class CreateBuffer { static public void main( String args[] ) throws Exception { //要创建缓冲区,您必须 分配 它。我们使用静态方法 allocate() 来分配缓冲区: ByteBuffer buffer = ByteBuffer.allocate( 1024 ); buffer.put( (byte)'a' ); buffer.put( (byte)'b' ); buffer.put( (byte)'c' ); //buffer.flip(); System.out.println( (char)buffer.get() ); System.out.println( (char)buffer.get() ); System.out.println( (char)buffer.get() ); } } 运行结果: a b c
方法二:通过对数组的包装来实现,使用了 wrap() 方法将一个数组包装为缓冲区,本例使用了 wrap() 方法将一个数组包装为缓冲区。必须非常小心地进行这类操作。一旦完成包装,底层数据就可以通过缓冲区或者直接访问。
public class CreateArrayBuffer { static public void main( String args[] ) throws Exception { //allocate() 方法分配一个具有指定大小的底层数组,并将它包装到一个缓冲区对象中 byte array[] = new byte[1024]; //本例使用了 wrap() 方法将一个数组包装为缓冲区。必须非常小心地进行这类操作。 //一旦完成包装,底层数据就可以通过缓冲区或者直接访问。 //可以分配来创建,也可以通过对数组的包装来实现 ByteBuffer buffer = ByteBuffer.wrap( array ); buffer.put( (byte)'a' ); buffer.put( (byte)'b' ); buffer.put( (byte)'c' ); buffer.flip(); System.out.println( (char)buffer.get() ); System.out.println( (char)buffer.get() ); System.out.println( (char)buffer.get() ); } } 运行结果: a b c
1.5缓冲区份片和数据共享
slice() 方法根据现有的缓冲区创建一种 子缓冲区 。也就是说,它创建一个新的缓冲区,新缓冲区与原来的缓冲区的一部分共享数据。
使用例子可以最好地说明这点。让我们首先创建一个长度为 10 的 ByteBuffer:
ByteBuffer buffer = ByteBuffer.allocate( 10 );
然后使用数据来填充这个缓冲区,在第 n 个槽中放入数字 n:
for (int i=0; i<buffer.capacity(); ++i) {
buffer.put( (byte)i );
}
现在我们对这个缓冲区 分片 ,以创建一个包含槽 3 到槽 6 的子缓冲区。在某种意义上,子缓冲区就像原来的缓冲区中的一个 窗口 。
窗口的起始和结束位置通过设置 position 和 limit 值来指定,然后调用 Buffer 的 slice() 方法:
buffer.position( 3 ); buffer.limit( 7 ); ByteBuffer slice = buffer.slice();
片 是缓冲区的 子缓冲区 。不过, 片段 和 缓冲区 共享同一个底层数据数组,我们在下一节将会看到这一点。
缓冲区份片和数据共享
我们已经创建了原缓冲区的子缓冲区,并且我们知道缓冲区和子缓冲区共享同一个底层数据数组。让我们看看这意味着什么。
我们遍历子缓冲区,将每一个元素乘以 11 来改变它。例如,5 会变成 55。
for (int i=0; i<slice.capacity(); ++i) {
byte b = slice.get( i );
b *= 11;
slice.put( i, b );
}
最后,再看一下原缓冲区中的内容:
buffer.position( 0 );
buffer.limit( buffer.capacity() );
while (buffer.remaining()>0) {
System.out.println( buffer.get() );
}
结果表明只有在子缓冲区窗口中的元素被改变了:
$ java SliceBuffer 0 1 2 33 44 55 66 7 8 9
//slice() 方法根据现有的缓冲区创建一种 子缓冲区 。
//也就是说,它创建一个新的缓冲区,新缓冲区与原来的缓冲区的一部分共享数据。
public class SliceBuffer
{
static public void main( String args[] ) throws Exception {
//首先创建一个长度为 10 的 ByteBuffer:
ByteBuffer buffer = ByteBuffer.allocate( 10 );
//然后使用数据来填充这个缓冲区,在第 n 个槽中放入数字 n:
for (int i=0; i<buffer.capacity(); ++i) {
buffer.put( (byte)i );
}
//现在我们对这个缓冲区 分片 ,以创建一个包含槽 3 到槽 6 的子缓冲区。在某种意义上,子缓冲区就像原来的缓冲区中的一个 窗口 。
// 窗口的起始和结束位置通过设置 position 和 limit 值来指定,然后调用 Buffer 的 slice() 方法:
buffer.position( 3 );
buffer.limit( 7 );
ByteBuffer slice = buffer.slice();
//我们已经创建了原缓冲区的子缓冲区,并且我们知道缓冲区和子缓冲区共享同一个底层数据数组。
// 让我们看看这意味着什么。我们遍历子缓冲区,将每一个元素乘以 11 来改变它。例如,5 会变成 55。
for (int i=0; i<slice.capacity(); ++i) {
byte b = slice.get( i );
b *= 11;
slice.put( i, b );
}
//最后,再看一下原缓冲区中的内容:
buffer.position( 0 );
buffer.limit( buffer.capacity() );
while (buffer.remaining()>0) {
System.out.println( buffer.get() );
}
}
}
运行结果:
0
1
2
33
44
55
66
7
8
9
1.6NIO 中的读和写
读和写是 I/O 的基本过程。从一个通道中读取很简单:只需创建一个缓冲区,然后让通道将数据读到这个缓冲区中。写入也相当简单:创建一个缓冲区,用数据填充它,然后让通道用这些数据来执行写入操作。
在本节中,我们将学习有关在 Java 程序中读取和写入数据的一些知识。我们将回顾 NIO 的主要组件(缓冲区、通道和一些相关的方法),看看它们是如何交互以进行读写的。在接下来的几节中,我们将更详细地分析这其中的每个组件以及其交互。
从文件中读取
在我们第一个练习中,我们将从一个文件中读取一些数据。如果使用原来的 I/O,那么我们只需创建一个 FileInputStream 并从它那里读取。而在 NIO 中,情况稍有不同:我们首先从 FileInputStream 获取一个 Channel 对象,然后使用这个通道来读取数据。
在 NIO 系统中,任何时候执行一个读操作,您都是从通道中读取,但是您不是 直接 从通道读取。因为所有数据最终都驻留在缓冲区中,所以您是从通道读到缓冲区中。
因此读取文件涉及三个步骤:(1) 从 FileInputStream 获取 Channel,(2) 创建 Buffer,(3) 将数据从 Channel 读到 Buffer 中。
现在,让我们看一下这个过程。
三个容易的步骤
第一步是获取通道。我们从 FileInputStream 获取通道:
FileInputStream fin = new FileInputStream( "readandshow.txt" ); FileChannel fc = fin.getChannel();
下一步是创建缓冲区:
ByteBuffer buffer = ByteBuffer.allocate( 1024 );
最后,需要将数据从通道读到缓冲区中,如下所示:
fc.read( buffer );
您会注意到,我们不需要告诉通道要读 多少数据 到缓冲区中。每一个缓冲区都有复杂的内部统计机制,它会跟踪已经读了多少数据以及还有多少空间可以容纳更多的数据。我们将在 缓冲区内部细节 中介绍更多关于缓冲区统计机制的内容。
写入文件
在 NIO 中写入文件类似于从文件中读取。首先从 FileOutputStream 获取一个通道:
FileOutputStream fout = new FileOutputStream( "writesomebytes.txt" ); FileChannel fc = fout.getChannel();
下一步是创建一个缓冲区并在其中放入一些数据 - 在这里,数据将从一个名为 message 的数组中取出,这个数组包含字符串 "Some bytes" 的 ASCII 字节(本教程后面将会解释 buffer.flip() 和 buffer.put() 调用)。
ByteBuffer buffer = ByteBuffer.allocate( 1024 ); for (int i=0; i<message.length; ++i) { buffer.put( message[i] ); } buffer.flip();
最后一步是写入缓冲区中:
fc.write( buffer );
注意在这里同样不需要告诉通道要写入多数据。缓冲区的内部统计机制会跟踪它包含多少数据以及还有多少数据要写入。
读写结合
下面我们将看一下在结合读和写时会有什么情况。我们以一个名为 CopyFile.java 的简单程序作为这个练习的基础,它将一个文件的所有内容拷贝到另一个文件中。CopyFile.java 执行三个基本操作:首先创建一个 Buffer,然后从源文件中将数据读到这个缓冲区中,然后将缓冲区写入目标文件。这个程序不断重复 ― 读、写、读、写 ― 直到源文件结束。
CopyFile 程序让您看到我们如何检查操作的状态,以及如何使用 clear() 和 flip() 方法重设缓冲区,并准备缓冲区以便将新读取的数据写到另一个通道中。
运行 CopyFile 例子
因为缓冲区会跟踪它自己的数据,所以 CopyFile 程序的内部循环 (inner loop) 非常简单,如下所示:
fcin.read( buffer );
fcout.write( buffer );
第一行将数据从输入通道 fcin 中读入缓冲区,第二行将这些数据写到输出通道 fcout 。
检查状态
下一步是检查拷贝何时完成。当没有更多的数据时,拷贝就算完成,并且可以在 read() 方法返回 -1 是判断这一点,如下所示:
int r = fcin.read( buffer ); if (r==-1) { break; }
重设缓冲区
最后,在从输入通道读入缓冲区之前,我们调用 clear() 方法。同样,在将缓冲区写入输出通道之前,我们调用 flip() 方法,如下所示:
buffer.clear(); int r = fcin.read( buffer ); if (r==-1) { break; } buffer.flip(); fcout.write( buffer );
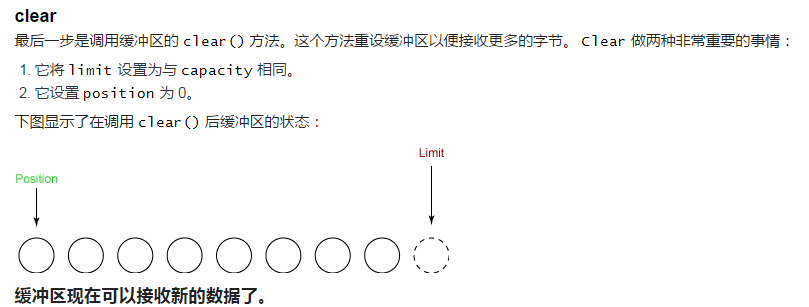
clear() 方法重设缓冲区,使它可以接受读入的数据。 flip() 方法让缓冲区可以将新读入的数据写入另一个通道。
public class ReadAndShow { static public void main(String args[]) throws Exception { FileInputStream fin = new FileInputStream("readandshow.txt"); FileChannel fc = fin.getChannel(); ByteBuffer buffer = ByteBuffer.allocate(1024); //通过通道读取数据到缓存区 fc.read(buffer); buffer.flip(); int i = 0; while (buffer.remaining() > 0) { byte b = buffer.get(); System.out.println("Character " + i + ": " + ((char) b)); i++; } fin.close(); } }