闲得无聊,到处找推荐歌曲都没有满意的,想了想不是有爬虫吗,反手就把酷狗排行榜的歌都给它爬下来了,不说了,我听歌去了~

文末的话,我也放了相关视频教程,比文章详细多了

开始今天的正文吧
这是今天的知识点
1、动态数据抓包演示
2、json数据解析
3、requests模块的使用
4、正则表达式的简单使用
5、css选择器数据解析方法
用到的环境和模块


python 3.6 pycharm (安装包/安装教程/激活码/使用教程/翻译插件) requests >>> pip install requests parsel >>> pip install parsel re 正则表达式
爬虫可见即可爬,你要想爬所有的也可以。
思路流程:
一. 数据来源分析
1. 确定需求 爬取音乐数据 音频
2. 通过开发者工具(浏览器都自带 F12 或者 鼠标右键点击检查)进行抓包分析
I. 找我们音乐播放地址 play_url
II. 找播放地址来源 对比参数变化 [hash ID]1629808844252 时间戳(表示你请求的时间点)
time 时间模块 可以获取当前时间戳
III. 找 hash ID 参数的来源
IV. 获取所有榜单的url地址
二. 代码实现过程
1. 发送请求 对于榜单url地址发送请求
2. 获取数据 获取网页源代码数据
3. 解析数据 提取所有榜单相对应的url地址
4. 发送请求 对于 榜单的url地址发送请求
5. 获取数据 获取网页源代码数据
6. 解析数据 提取音乐 hash 和 id 值
7. 发送请求 把 hash 和 id 值 参数相对url里面 发送请求
8. 获取数据 获取json字典数据
9. 解析数据 提取 歌名 音乐播放地址
10. 保存数据
数据来源分析 >>> 发送请求 >>> 获取数据 >>> 解析数据 >>> 保存数据
首先把要用的模块都安排上
import requests # 数据请求模块 pip install requests import parsel # 数据解析模块 pip install parsel import re # 正则表达式 内置模块 不需要安装 import pprint # 格式化输出 import os
设置一手文件夹,我们爬下来的音乐就放到这里
filename = 'music\' if not os.path.exists(filename): os.mkdir(filename)
然后有些歌曲下载下来可能有特殊字符,我们得把它替换掉
def change_title(title): pattern = re.compile(r"[/\:*?"<>|]") # '/ : * ? " < > |' new_title = re.sub(pattern, "_", title) # 替换为下划线 return new_title
1、发送请求 对于榜单url地址发送请求
url = 'https://www.kugou.com/yy/html/rank.html'
请求头 作用: 伪装 把python代码伪装成浏览器发送请求
任意一个数据包的 user-agent 都是一样的
user-agent 表示的就是浏览器的基本信息
headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } response = requests.get(url=url, headers=headers)
2、获取数据 获取网页源代码数据
print(response.text)
html 字符串数据(想直接解析字符串数据 只能用re) 转成 selector 对象
3、解析数据 提取所有榜单相对应的url地址
selector = parsel.Selector(response.text) print(selector)
css选择器 根据标签的内容 提取想要的数据
第一次提取 获取li 标签
lis = selector.css('.pc_rank_sidebar li') lis = lis[13:]
返回的是列表, 所以可以遍历 把里面每一个元素提取出来 Selector 对象
for li in lis: title = li.css('a::attr(title)').get() link_url = li.css('a::attr(href)').get() print(f'=====================正在爬取{title}=====================') print(title, link_url)
4、发送请求 对于 榜单的url地址发送请求
response_1 = requests.get(url=link_url, headers=headers) re.findall('')
5、获取数据 获取网页源代码数据 response_1.text
print(response_1.text)
6、解析数据 提取音乐 hash 和 id 值
hash_list = re.findall('"Hash":"(.*?)"', response_1.text)
d 匹配一个数字 d+ 匹配多个数字 .*? 可以匹配任意字符 (除了
)
正则表达式匹配的数据 返回的是列表
album_id = re.findall('"album_id":(d+),', response_1.text) for index in zip(hash_list, album_id): hash = index[0] music_id = index[1]
7、 发送请求 把 hash 和 id 值 参数相对url里面 发送请求
index_url = 'https://wwwapi.kugou.com/yy/index.php' params = { 'r': 'play/getdata', # 'callback': 'jQuery19106964302346548317_1629810585326', 'hash': hash, 'dfid': '1JdWoI2IQjNS2aq9KB1Ylhf3', 'mid': 'fe0e97001229790f9065ef29dec3bdcd', 'platid': '4', 'album_id': music_id, '_': '1629810585327', } response_2 = requests.get(url=index_url, params=params, headers=headers) # json_data = response_2.json()['data'] music_name = response_2.json()['data']['audio_name'] new_name = change_title(music_name) music_url = response_2.json()['data']['play_url'] if music_url: music_content = requests.get(url=music_url, headers=headers).content with open(filename + new_name + '.mp3', mode='wb') as f: f.write(music_content) print(music_name)

来看看效果
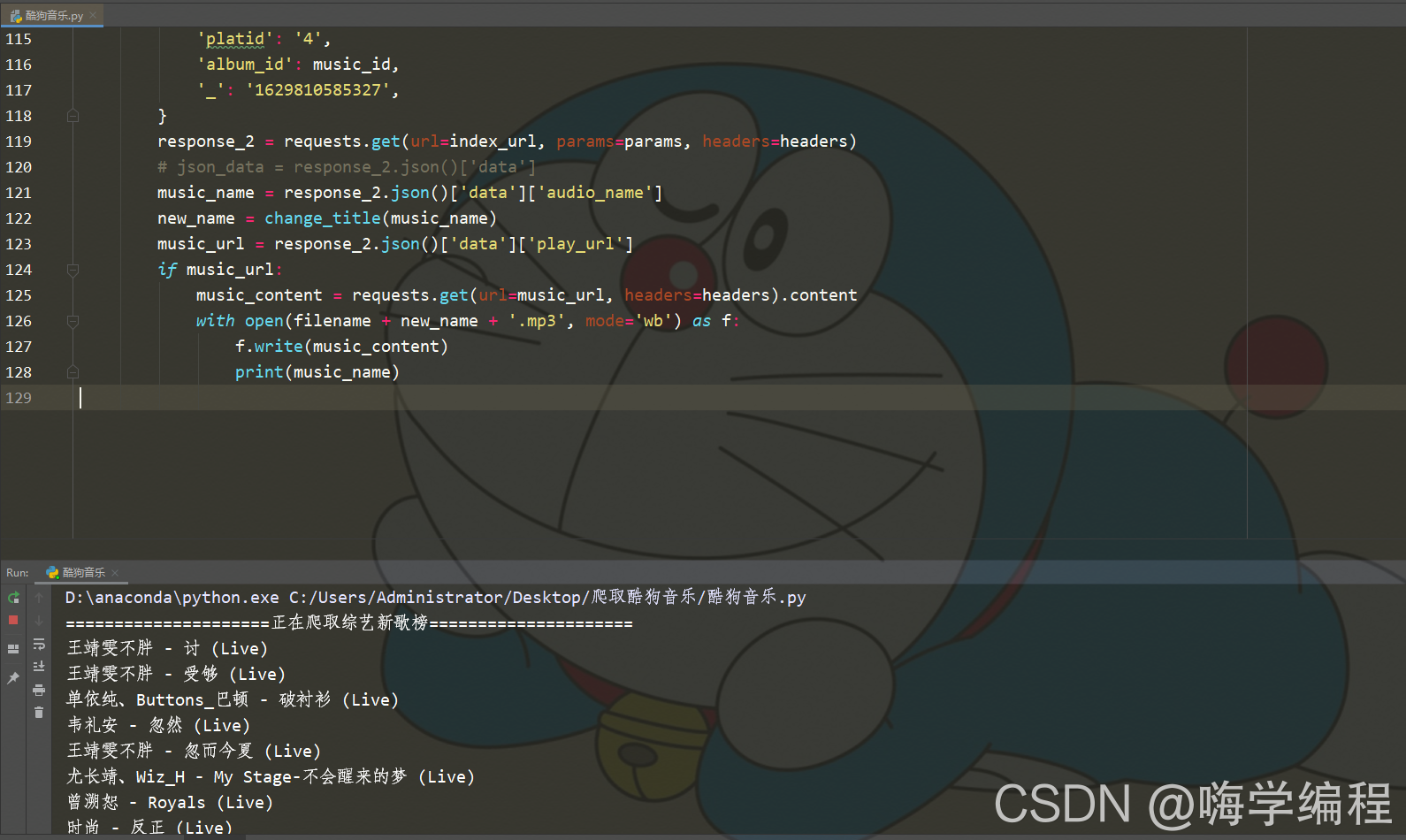
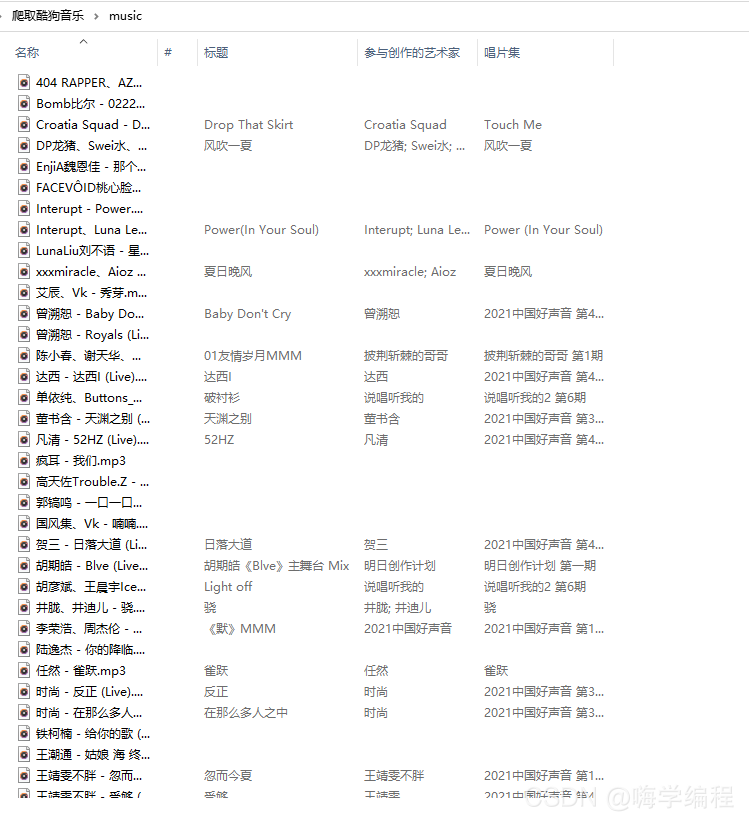
这下子我又能消停几天了
视频教程我也放在这给大家了,视频会讲的详细一些 点我看视频 密码:qwer