一、索引的本质:
索引(Index) 是帮助MySQL高效获取数据的数据结构。索引可以包含一个或多个列的值。如果索引含多个列,那么列的顺序也十分重要,因为MySQL只能高效地使用索引的最左前缀列。
二、索引的数据结构:
1、B - Tree:
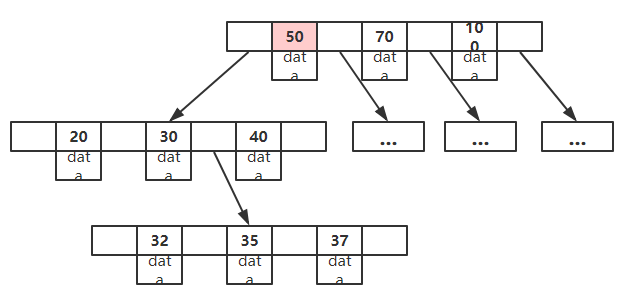
1.1、根节点至少包括两个孩子;
1.2、树中每个节点最多有m个孩子(m >= 2);
1.3、除根节点和叶子节点外,其他每个节点至少有ceil(m/2)个孩子;
1.4、所有叶子节点都位于同一层;
1.5、所有节点关键字按顺序排序,并遵循左小右大原则;关键字的个数n必须满足[ceil(m / 2) - 1] <= n <= m-1;
2、B+ - Tree:

B+ 树是B 树的变体,其定义基本与B 树相同。除了以下几点:
2.1、非叶子节点的子树指针与关键字个数相同;
2.2、非叶子节点的子树指针P[i],指向关键字值[K[i],K[i+1]]的子树;
2.3、非叶子节点仅用来索引,数据都保存在叶子节点中;
2.4、所有叶子节点均有一个链指针指向下一个叶子节点;
3、Hash:
3.1、Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B+ -Tree需要从根节点到叶子节点,最后才能获取数据,所以Hash 索引的查询效率要远高于B+ -Tree 索引。但是由于Hash 索引比较的的是进行Hash 运算之后的Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的Hash 算法处理之后的Hash 值的大小关系,并不能保证和Hash 运算前完全一样;
三、B+ -Tree 索引 和 Hash 索引使用场景的区别:
1、B+ -Tree 索引当使用>、<、>=、<=、between、!= 或者<>,或者like ;
2、Hash 索引只能使用=、in()、>=、<=,当使用Hash 索引时应考虑哈希冲突导致查询效率下降的问题;
3、Hash 索引无法被用来数据的排序操作。(Hash 索引无法加速 order by 操作)
4、Hash 索引不能利用部分索引键查询;
5、B+ -Tree 限制:
5.1、如果不是按照索引的最左列开始查找,则无法使用索引;
5.2、不能跳过索引中的列;
5.3、如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找;
四、聚簇索引和非聚簇索引:
1、基于InnoDB 引擎实现的聚簇索引,有且只有一个聚簇索引。若一个主键被定义,该主键则作为聚簇索引。若没有主键被定义,该表的第一个唯一非空索引则作为聚簇索引。若都没有,InnoDB 内部会生成一个隐藏主键(聚簇索引,6字节的列)。非主键索引叶子节点存储的是相关键位和其对应的主键值,使用二级索引要两次查找才能找到表数据;
2、基于MyISAM 引擎非聚簇索引,叶子节点存储的是表记录的地址,表数据与索引数据分开存储(分为两个文件存储);