JSON、闭包和原型
----透视Javascript语言核心
接触过Javascript的朋友都知道,虽然Javascript看起来很像Java,但实际上它的编程思想与Java等主流语言有很大的不同。它既有LISP语言的影子,也可以用主流面向对象语言的方法来组织程序。本文尝试从Javascript特有的JSON结构、闭包和原型三方面入手,探索Javascript独特的运行机制和实现面向对象的模式。最后以Javascript为中介,探讨LISP语言与OO语言的关系。
一、JSON结构与Javascript对象
JSON与XML同类,是一种数据字典表单格式。它很简单:用逗号分隔开一系列属性,属性的形式是“属性名:属性值”,其中属性值可以是变量,也可以是另一个表单。如下例所示:
{ name : { firstname : "Tommy", lastname: "Chen"}, age : 25, sex : "male", married : false }
上面name属性是一个子表单,因此JSON是树结构的。在Javascript里,函数也可以作为JSON属性:
{ name : “Tommy”, speak : function(word){alert(word)} }
这里体现了LISP语言的思想:函数也是变量。(准确讲应该是自变量:能自行改变状态的变量。而数据变量不能自行改变状态,只能被动接受状态赋值)
Javascript规定Javascript对象有且只有JSON一种形式(JSON全称是“Javascript Object Notation”,即“Javascript对象标记”的意思)。可以用3种不同的方式构建对象,分别是直接描述、动态添加和new操作符构建,这3种方法构建的对象都是JSON格式的。
上面2个例子构建的对象只有数据内容,可以给它们设立一个名字:
var obj = { name : “Tommy”, Speak : function(word){alert(word)} }
这里obj是一个引用,它指向等号右边的对象。事实上,Javascript定义的变量,无论是对象、基本数据类型还是函数,都是引用:
a = 99; b = function(){alter(“hello”)};
引用a指向数据块“99”,引用b指向数据块“function(){alter(“hello”)}”。变量间赋值是引用的重定向操作:
var a = 0; var b = a; a = 1; console.log(b == 0); //true
这里b的行为不像引用,按通常对引用的理解,a改变后应该会影响到b,但这里b并没有改变。事实上,b也是引用没错。在执行var b = a;后,b与a引用同向,如下图所示:

当变量a重新被赋值1时,它是先抛弃原来指向的数据0,再指向新的数据1:
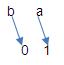
因为a改变了其引用定向,这时b与a所引用的值就不一样了。Javascript里赋值操作都是这种“弃旧用新”模式,再举一例:
var a = { n:0 }; var b = a; a.n = 1; console.log(b.n == 1); //true
这次a并没有断开对原对象的引用,只是对其进行了修改,因此b的属性也一并修改了。另外,Javascript数组实质上是封装了的对象变量,数组赋值也只是引用赋值,不发生内容克隆,有兴趣的朋友可以自己试一试。这就是Javascript是弱类型语言的原因:都是引用,怎样互相重定向都没问题。
全局命名空间本身也是一个JSON表单,Javascript定义全局JSON表单为window,在全局定义的变量、函数和对象都是window对象的下级节点:
console.log(this); //输出window var v = "I am a global var"; function f(){ console.log("I am a global funciton") }; var obj = { v : "I am a property of obj", f : function(){ console.log("I am a funciton property of obj") } }; console.log(window.v); //输出 I am a global var window.f(); //输出 I am a global function console.log(window.obj.v); //输出I am a property of obj window.obj.f(); //输出I am a funciton property of obj
这样Javascript变量的数据结构就比较清晰了:它变量存储结构为JSON树,树根为window。首层子节点为全局变量(或对象、函数),再往下的子节点是全局对象的子节点,如果这些子节点也是对象还可以继续往下再延伸。这些节点(变量)都是引用,它们是JSON树的分支节点,分支节点负责定向,终端节点存储实际数据内容。举例说明:
var person = { name : { firstname : “Tommy”, lastname: “Chen”}, age : 25, actions : { speak : function(word){alert(word)} };
person对象结构模型如下图JSON树所示:

Javascript用这种方式实现了LISP语言的数据管理模式。LISP是表处理器(List processor)的简称,它定义了一个数据树的结构,分支节点(在LISP里分支节点是匿名的)负责定向,终端节点为原子(即自变量,可自我改变状态,也可以被赋值改变状态,即Javascript的函数和基本数据类型变量)。因此,Javascript是LISP语言,只不过它的Java口音太重而已。
Javascript对象都是这种“门户大开”型的JSON模式,在对象外部可以直接访问它的内部数据,这与主流OO语言完全不同。要实现数据封装,必须使用闭包。
二、闭包与封装
Javascript函数在运行时生成闭包。闭包是Javascript里一个很重要的概念,它行为怪异,显得神秘莫测。但如果用JSON树的角度去看它,还是可以把它看透的。
1、顾名思义,闭包是一个封闭的数据包。外部程序不能直接访问闭包内部数据,但闭包内部程序可以访问闭包外部的数据,通过闭包内部程序的授权,外部程序才可以进入闭包内部访问。闭包内可继续包含闭包,遵循同样的数据访问规则。
2、闭包也是JSON树的节点。这意味着除非节点被系统垃圾回收,否则它是一直存在的,节点数据也会一直保留。因此,在函数执行完成后其它代码还可以进入它的闭包,访问其内部变量:
var watch; function f(){ var n=0; watch = function(){console.log(n)}; n=1; } f(); watch(); //1
函数f授权外部变量watch可以访问其内部变量n。f()执行完成后并没有释放内存,因此watch可以进入其闭包内部,输出其内部变量n的值。而n的最终值为1,因此watch输出1。
闭包内部的数据结构也可以用JSON图来表示,实线框确定闭包范围,NNF代表匿名函数。以上程序JSON模型如下:

3、函数永远在其定义的上下文中运行,而不是在其被调用的上下文中运行。这是因为函数赋值是引用重定向,而不是内容拷贝。以下代码尝试把一个函数作为另一个函数的参数传递,结果发生错误:
var a = function(){console.log(n)}; function f(a){ var n=1; var b = a; b(); } f(a); //ReferenceError: n is not defined
如果b = a是克隆操作,这段代码可以成功输出n的值。但实际上这不是克隆,而是把b的引用重定向至全局函数a,因此b()将在全局上下文执行。而全局并没有定义n,因此发生未定义错误。这意味着不能通过传递函数变量的方式动态修改已定义好的函数。
4、this指针指向本次调用执行它的对象:
var a = { n: 0, f: function(){this.n=9} }; var b = { n: 1, f: a.f}; b.f(); console.log(a.n == 0); //true console.log(b.n == 9); //true
b.f指向a.f,f()在a的上下文运行。但因为是b调用f,因此this指针指向b。使用this指针需要注意的是,用setTimeout或setInterval调用函数时,函数里头的this指针指向全局命名空间对象window:
var a = { n: 0, f: function(){this.n=9} }; var b = { n: 1, f: function(){setTimeout(a.f,1000)} }; b.f(); console.log(a.n == 0); //true console.log(b.n == 1); //true
b.f()修改的既不是a.n,也不是b.n,而是window.n。
5、闭包可理解为函数的运行实例,函数每次运行都会在函数定义的上下文(不是运行的上下文)里创建一个新的闭包(运行实例),在其执行完成后系统视其外联情况选择是否回收内存空间。这有点像OO语言类与对象实例的模式,而在Javascript里无论是否用new操作符,函数都以这种模式运行。以下例子说明,对于同一个函数,不同的引用在运行时是对应不同闭包的,里面的数据各自独立:
function f(){ var n=0; return function(){console.log(++n)}; } var a = f(); //f生成了一个闭包,a可以进入这个闭包 var b = f(); //f生成了另一个闭包,b进入的这个闭包与a进入的不同 a(); //1 a(); //2 a(); //3 b(); //1 f(); //f又生成了一个闭包,它与刚才2个闭包独立,不会重置内部数据n a(); //4 b(); //2
JSON模型如下:
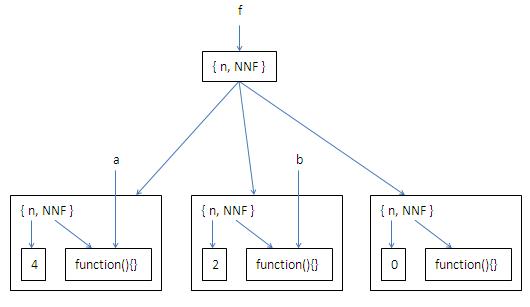
如图,f运行了3次,生成了3个闭包。最右边的是f第三次运行生成的闭包,由于它没有外部连接,生成后马上被系统垃圾回收了。f里面的匿名函数NNF也被多次执行,它也生成了多个闭包,但在运行完毕就被系统垃圾回收了。由于闭包内存空间独立于函数定义,即使函数被删除了,还是可以继续访问它的闭包的:
var watch; var obj = {f : function(){ var n=0; watch = function(){console.log(n)}; n=1; } }; obj.f(); delete obj.f; watch(); //1
即使obj删除了f属性,watch还可以继续进入f的闭包访问其内部数据。这就是Javascript垃圾回收原则:只要还有外部链接,就不会回收。再举一个经典例子,以下程序尝试为保存在函数形参里的数据动态建立一个对外的访问连接,结果失败了:
function User(properties){ for(var i in properties){ this["get" + i] = function(){return properties[i]}; this["set" + i] = function(val){properties[i] = val}; } } var user = new User({name: "Bob", age: 44}); console.log(user.getname() === "Bob"); //false
因为执行user.getname()要重新进入User函数内部上下文,而它的i已经定在最后一个元素,因此return properties[i]永远返回最后一个元素的值。这种情况应该使用闭包:
function User(properties){ for(var i in properties){ (function(_this){ var p = i; _this["get" + p] = function(){return properties[p]}; _this["set" + p] = function(val){properties[p] = val}; })(this); } } var user = new User({name: "Bob", age: 44}); console.log(user.getname() === "Bob"); //ture user.setage(22); console.log(user.getage() === 22); //true
每执行一次循环都执行一个函数,建立了新的闭包,使p保存在不同的闭包空间里,再分别授权user.getname()进入。
以上几点是闭包最突出的特点,它们都是共通且可以相互解释的。试着把它们在JSON图框架模型里联系起来,可更形象立体地理解闭包。
利用函数闭包这些性质,可以实现OO语言的对象封装模式。以上代码是其中的一个例子,它的私有数据甚至不是函数的内部变量,它被保存在函数的参数里。这个方式隐密性很好,但程序逻辑太复杂,我更喜欢直接简洁直观的代码:
function F(){ var inner_data = 0; return { setData : function(x){inner_data = x}, getData : function(){console.log(inner_data)} }; } var a = F(); var b = F(); a.setData(1); b.setData(2); a.getData(); //1 b.getData(); //2
这种模式是用函数的内部变量保存私有数据,返回操作接口。因为每次执行均生成不同的闭包,a和b各自独立,互相不影响。这种方法不用new操作符号,内部逻辑清晰,安全又潇洒。
用闭包封装对象的缺点是不能继承,因为函数一旦定义好外部程序就无法修改其内容。闭包形式的对象把自己封装了,同时也就放弃了继承。Javascript里能继承的对象都是不完全封闭的,标准方式是原型继承。
三、原型与继承
Javascript所有变量都是对象,每个对象都有原型,原型顾名思义是对象原来的型态,而对象现在的型态是从它原型进化发展过来的。比如钢铁侠的原型是Tony,Tony穿上装置服后,就成为了钢铁侠。一个原型可以派生出很多新对象(多态、继承),如Tony穿上蝙蝠衣就会变成蝙蝠侠,穿上蜘蛛衣就会变成蜘蛛侠。对象会继承它原型(父对象)的数据,Firfox浏览器显式提供“__proto__”指针指向对象的原型:
var a = {x:0}, b = {y:1}; b.__proto__ = a; console.log(b); //Object { y=1, x=0}
将b的原型设置为a,b则继承了a的属性x。a也有原型,a的原型是Object对象的prototype属性:
console.log(b.__proto__.__proto__); //Object{}
而Object.prototype的原型是null:
console.log(b.__proto__.__proto__.__proto__); //null
这就是“原型链”,每个对象的原型都指向它的父对象,直至null。原型指针赋值操作与其它变量赋值操作一样,是引用不是克隆。这意味着用这种方法设置原型各子对象会共享着同一个父对象的数据,它们是强耦合关系,如果父对象数据有修改,将影响所有子对象:
var a = {x:0}, b = {y:1}, c = {z:2}; b.__proto__ = a; c.__proto__ = a; a.x = 99; console.log(b.x == 99); //true console.log(c.x == 99); //true
编译器在查找一个对象的属性时,先查找本对象是否有这个属性,如果没有就查找它的原型对象,再没有再继续沿原型链查找后面的原型对象直至找到,至null则返回Undefined。以上显式设置对象原型的方法只对Firefox浏览器有效,通用的方法是利用函数的专属属性prototype隐式设置:
function f0(y){ this.y = y; } function f1(x,y){ f0.call(this,y); this.x = x; } f1.prototype = new f0(); //每次都新建一个f0对象 var a = new f1(1,2); var b = new f1(3,4); console.log(a); //f0 { y=2, x=1} console.log(b); //f0 { y=4, x=3}
构造器隐式设置了对象__proto__指针指向构造器函数的prototype属性。而f1构造器的prototype属性指向一个新的f0对象,因此f1生成的对象是不共享原型的。但有些情况共享原型可能更好,比如把公有的或不变的属性(静态变量)放在原型对象里,可有效节约内存。另外,可以把原型定义为只有接口的“虚类”,实现类似Java语言定义接口的功能:
var Interface = { setX : function(x){this._x=x}, getX : function(){return this._x} }; function f(){ this._x = 0; //.... } f.prototype = Interface;
但原型继承还是不能打破闭包,也就是说Javascript里要么用闭包模式实现封装,要么打开门户实现继承。只能二选一,视情况取舍吧。
四、深入再浅出,无招胜有招
以上只涉及了Javascript很基础的一些皮毛,如有兴趣可继续深入阅读《精通Javascript》、《Javascript权威指南》、《Javascript精粹》和《Javascript设计模式》等大师佳作。Javascript是很灵活的语言,解决一个问题可以有多种方法,知道某个特性并不意味着必须使用。如果对某个概念或它的运行机制似懂非懂,最聪明的办法是在实际应用时尽量不要使用它们,这样可以减少编程难度,提高可读性,同时规避不可预测的风险。比如不用new和this也可以构建对象:
function F(x,y){ return{x:x, y:y}; } var a = F(1,2); var b = F(3,4); console.log(a); // Object { x=1, y=2} console.log(b); // Object { x=3, y=4}
不用prototype也可以实现继承:
function F0(y){ return{y : y}; } function F1(x,y){ var t = F0(y); t.x = x; return t; } var a = new F1(1,2); var b = new F1(3,4); console.log(a); // Object { y=2, x=1} console.log(b); // Object { y=4, x=3}
你甚至可以完全不用原型,自己编写一个extend函数,实现类式继承。Javascript好玩之处就在于此,每个人都可以用各自的喜欢方法实现面向对象。正因为这种随意性它被称为“玩具语言”:它既是行外人写小程序的玩具,更是高手玩家任意发挥的玩具。写Javascript程序就像写散文,而写OO程序像写有严格格式要求的八股文。它们孰优孰劣一直都有争论,但它们真的水火不容吗?
五、LISP与OO共融
Javascript本质是LISP语言,这就不得不提"格林斯潘第十定律":任何C或Fortran程序复杂到一定程度之后,都会包含一个临时开发的、只有一半功能的、不完全符合规格的、到处都是bug的、运行速度很慢的Common Lisp实现。我们再看看以Java为代表的主流面向对象语言,复杂到一定程度后,父类生成一系列子类,子类又生成子类,这不正是构造出LISP语言里的树结构吗?类与类之间的交互关系就相当于LISP的树节点处理,看来也符合"格林斯潘第十定律"的Common Lisp实现。但面向对象方法有模块化、可复用、易维护等工程学上的优点,当Javascript语言复杂到一定程序后,或多或少都会包含这些面向对象的方法理念。通过前文对Javascript实现面向对象的分析,说实在话,它并没有像Java语言那么简洁清晰,充其量只是功能模拟,是一个“临时开发的、只有一半功能的、不完全符合规格的、到处都是bug的、运行速度很慢的”面向对象实现。其实LISP和OO都能很好地表达编程思想,只是它们各有专长和应用领域,相煎何太急?LISP接近纯粹的数学,假设有无限内存,不需要寄存器,更不用考虑软件工程流程、分工协作等工程学、管理学上的问题,因此它可以用最少代码表达最多意思,且逻辑优雅符合自然之美。而以Java为代表的主流面向对象语言更多是面向软件工程的综合解决方案,它在解决了工程上的问题,建立了设计模式后,就会如"格林斯潘第十定律"所言,重新回归到LISP语言。LISP属于“非工业用”,它在解决数学、人工智能和简易小程序等特定问题很实用,而OO的专长当然是工业化生产大型软件了。如果把程序设计比作出版书籍,那么LISP是手写版,OO是印刷版。手写版当然价值更高,但它不易维护,更难以传播。最好还是采用印刷版,用电脑起草文稿,再在印刷厂排版印刷发行。所以LISP与OO不是对立关系,而是共融关系。LISP程序员要学些OO语言设计模式,OO程序员也要学些LISP语言编程思想,这样才能真正把握全局,成为高手。