我们前面已经讲了如何训练稀疏自编码神经网络,当我们训练好这个神经网络后,当有新的样本![]() 输入到这个训练好的稀疏自编码器中后,那么隐藏层各单元的激活值组成的向量
输入到这个训练好的稀疏自编码器中后,那么隐藏层各单元的激活值组成的向量![]() 就可以代表
就可以代表![]() (因为根据稀疏自编码,我们可以用
(因为根据稀疏自编码,我们可以用![]() 来恢复
来恢复![]() ),也就是说
),也就是说![]() 就是
就是![]() 在新的特征下的特征值。每一个特征是使某一个
在新的特征下的特征值。每一个特征是使某一个![]() 取最大值的输入。假设隐藏层单元有200个,那么就一共有200个特征,所以
取最大值的输入。假设隐藏层单元有200个,那么就一共有200个特征,所以![]() 新的特征向量
新的特征向量![]() 有200维。特征显示情况在前面博客中已经给出,我们把这时候的特征称为一阶特征。
有200维。特征显示情况在前面博客中已经给出,我们把这时候的特征称为一阶特征。
![072226361877983[5]](https://images0.cnblogs.com/blog/703272/201502/031451453435485.png "072226361877983[5]")
我们知道脑神经在处理问题,比如看一个图片的时候,也不只使用了一层的神经,而是使用了多层的神经元不断的将看到的图片内容抽象,(更详细的可以看这里) 。因为每一层都是一层非线性的叠加,所以每增加一层隐藏层,那么神经网络的表达能力就增强一步,所以我们将要做的是提取二阶特征。
注意我们这里要得到二阶特征并不是使用像如下图所示的“增加版”稀疏自编码神经网络(在原基础增加一个隐藏层):

我们为什么不适用这样的一个网络呢?原因是这样的(引自这里):
‘’
虽然几十年前人们就发现了深度网络在理论上的简洁性和较强的表达能力,但是直到最近,研究者们也没有在训练深度网络方面取得多少进步。 问题原因在于研究者们主要使用的学习算法是:首先随机初始化深度网络的权重,然后使用有监督的目标函数在有标签的训练集 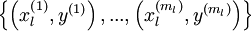 上进行训练。例如通过使用梯度下降法来降低训练误差。然而,这种方法通常不是十分奏效。这其中有如下几方面原因:
上进行训练。例如通过使用梯度下降法来降低训练误差。然而,这种方法通常不是十分奏效。这其中有如下几方面原因:
数据获取问题
使用上面提到的方法,我们需要依赖于有标签的数据才能进行训练。然而有标签的数据通常是稀缺的,因此对于许多问题,我们很难获得足够多的样本来拟合一个复杂模型的参数。例如,考虑到深度网络具有强大的表达能力,在不充足的数据上进行训练将会导致过拟合。
局部极值问题
使用监督学习方法来对浅层网络(只有一个隐藏层)进行训练通常能够使参数收敛到合理的范围内。但是当用这种方法来训练深度网络的时候,并不能取得很好的效果。特别的,使用监督学习方法训练神经网络时,通常会涉及到求解一个高度非凸的优化问题(例如最小化训练误差 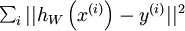 ,其中参数
,其中参数 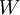 是要优化的参数。对深度网络而言,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。
是要优化的参数。对深度网络而言,这种非凸优化问题的搜索区域中充斥着大量“坏”的局部极值,因而使用梯度下降法(或者像共轭梯度下降法,L-BFGS等方法)效果并不好。
梯度弥散问题
梯度下降法(以及相关的L-BFGS算法等)在使用随机初始化权重的深度网络上效果不好的技术原因是:梯度会变得非常小。具体而言,当使用反向传播方法计算导数的时候,随着网络的深度的增加,反向传播的梯度(从输出层到网络的最初几层)的幅度值会急剧地减小。结果就造成了整体的损失函数相对于最初几层的权重的导数非常小。这样,当使用梯度下降法的时候,最初几层的权重变化非常缓慢,以至于它们不能够从样本中进行有效的学习。这种问题通常被称为“梯度的弥散”.
与梯度弥散问题紧密相关的问题是:当神经网络中的最后几层含有足够数量神经元的时候,可能单独这几层就足以对有标签数据进行建模,而不用最初几层的帮助。因此,对所有层都使用随机初始化的方法训练得到的整个网络的性能将会与训练得到的浅层网络(仅由深度网络的最后几层组成的浅层网络)的性能相似。
‘’
上面这个解释不光单指稀疏自编码神经网络(输出等于![]() )的各种困难,所有的如上图那样直接增加隐藏层,然后利用
)的各种困难,所有的如上图那样直接增加隐藏层,然后利用![]()
样本训练都会出现上面的困难。那么应该怎么办呢?
我们这里使用了一种逐层贪婪训练的策略。简单来说,逐层贪婪算法的主要思路是每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,跟前面方法一样,我们根据输出层与样本标记的误差平方作为cost function,然后使用梯度下降法或L-BFGS等方法(求梯度时结合前向后向传播算法)最小化cost function得到第一隐藏层这一层的参数(第一隐藏层这一层指的是![]() 和
和![]() 的参数(书写方便,这里和下面都只用
的参数(书写方便,这里和下面都只用![]() 代替,但是记得是包括
代替,但是记得是包括![]() 的),注意训练好以后我们只需要如下图
的),注意训练好以后我们只需要如下图![]() 的参数,
的参数,![]() 的参数在之后训练新增加的隐藏层或最后的微调中是不需要的)。如图所示(样本的label是一个二维的向量,隐藏层用了三个神经元):
的参数在之后训练新增加的隐藏层或最后的微调中是不需要的)。如图所示(样本的label是一个二维的向量,隐藏层用了三个神经元):

如果是稀疏自编码,其他都一样,只是把前面提到的label,即样本的标记换成了样本本身,那么网络输出的就是原样本,如图所示(隐藏层用了四个神经元):

然后当这层网络训练结束之后才开始训练第二个隐藏层的网络,训练是这样的:训练的第二个隐藏层神经网络的输入是第一个隐藏层神经网络隐藏层的激活值,输出还是原样本的label,然后跟上面一样训练第二个隐藏层的网络,同样地,对于这个神经网络,我们需要的也是![]() 的参数(包括b(1))(为了与上面的
的参数(包括b(1))(为了与上面的![]() 区分,这里写成
区分,这里写成![]() ),
),![]() 的参数在之后训练新增加的隐藏层或最后的微调中是不需要的,如图所示(隐藏层用了三个神经元):
的参数在之后训练新增加的隐藏层或最后的微调中是不需要的,如图所示(隐藏层用了三个神经元):

如果是稀疏自编码,其他都一样,只是把前面提到的样本标记label换成了这一层神经网络的输入:![]() ,你可能发现不同了,如果是监督学习的时候,我们进行每一层贪婪训练时,每一个网络的输出都是一样的,都是原样本的label。而如果每一层都是稀疏自编码时,我们每一个网络的输出是相互不一样的,都等于本层训练网络的输入。如图所示(隐藏层用了三个神经元):
,你可能发现不同了,如果是监督学习的时候,我们进行每一层贪婪训练时,每一个网络的输出都是一样的,都是原样本的label。而如果每一层都是稀疏自编码时,我们每一个网络的输出是相互不一样的,都等于本层训练网络的输入。如图所示(隐藏层用了三个神经元):

之后如果还需要增加层次,跟前面一样,只是如果是稀疏自编码的话,那么最终得到的是![]() 在新特征下的特征值,所以跟监督学习不一样,整个过程并没有分类,所以我们还需要增加一个分类器,比如softmax回归,来对非监督学习到的新特征值进行分类,具体地:
在新特征下的特征值,所以跟监督学习不一样,整个过程并没有分类,所以我们还需要增加一个分类器,比如softmax回归,来对非监督学习到的新特征值进行分类,具体地:
当我们用一些不含label的样本完成了稀疏自编码逐层贪婪训练后,也就是我们找到了如果用新的特征去表示原数据![]() ,这时候我们把另外一些含label的样本,通过下图所示的神经网络,那么得到的就是这些样本在之前学习到的特征下的特征值。注意这个网络的参数就是前面逐层训练时得到的
,这时候我们把另外一些含label的样本,通过下图所示的神经网络,那么得到的就是这些样本在之前学习到的特征下的特征值。注意这个网络的参数就是前面逐层训练时得到的![]() 和
和![]() 。那么在之后softmax训练时,我们的训练样本和测试样本就是这些新的特征值(即用这些新得特征值来表示样本):
。那么在之后softmax训练时,我们的训练样本和测试样本就是这些新的特征值(即用这些新得特征值来表示样本):
 ……………………………………………………………………………………………………………………..图1
……………………………………………………………………………………………………………………..图1
得到新特征下的训练样本和测试样本后,我们接下来要做的跟以前softmax训练就一样了,训练得到softmax参数θ。
可能读者觉得这样基本就可以说ok了,其实这还远远不够,我们现在得到的参数,只是逐层贪婪训练得到的稀疏自编码参数和最后一层监督训练的softmax参数,但是我们真正想要的是那种纯监督学习对整个神经网络一块训练后的参数(虽然根据前面提到的缺陷,我们很难得到,但是我们还是想得到的这样的参数),所以我们刚才做的工作其实相当于把整个神经网络的参数由随机的参数初始化变成了由‘逐层贪婪训练得到稀疏自编码参数和监督训练softmax回归得到最后一层参数’这种方法的参数初始化,我们这样做的目的就是期待这样的参数初始化方法可以(比参数随机初始化)使 cost function最小化时更容易收敛。所以我们的任务还没有结束,并且接下来的过程能使网络性能大大提高,这一步我们俗称微调(fine-tuning)。
上述如果想做微调,首先需要注意的一点是,我们训练softmax回归模型的样本要和逐层训练稀疏编码的样本都是来着同一组样本,也就是说图1输入的还是原来训练稀疏编码的那些样本(如果你用新的样本的话,就代表之前训练的参数已经训练好了,所以还是要用原来的样本,这才能进行微调),最后得到的![]() 去训练和测试softmax回归模型得到图2最后的输出p(y=1|x)、p(y=2|x)、p(y=3|x),即我们把这整个过程看成一个整体,如下图2所示;我们利用一组样本训练出上面所说的W(1)、WW(1)和θ后,然后我们把原样本一个个通过下面这个神经网络中,在n-1层的神经元的激活值是各个样本对应的
去训练和测试softmax回归模型得到图2最后的输出p(y=1|x)、p(y=2|x)、p(y=3|x),即我们把这整个过程看成一个整体,如下图2所示;我们利用一组样本训练出上面所说的W(1)、WW(1)和θ后,然后我们把原样本一个个通过下面这个神经网络中,在n-1层的神经元的激活值是各个样本对应的![]() ,然后通过最后一层softmax模型得到最后的输出。然后根据样本的label y(i)和这个神经网络的输出p(y=1|x)、p(y=2|x)、p(y=3|x),形成cost function,整个模型的cost function为:
,然后通过最后一层softmax模型得到最后的输出。然后根据样本的label y(i)和这个神经网络的输出p(y=1|x)、p(y=2|x)、p(y=3|x),形成cost function,整个模型的cost function为: ,
,
在对cost function求最小值的过程中,我们将cost function对各个参数求偏导,然后利用如梯度下降法迭代得到每一次迭代后的参数,最后迭代到cost function收敛后最终参数。在这里我们要注意一个地方:我们每一次迭代中求cost function 对前n-1层的网络参数的导数是根据前向后向传播算法计算的,而cost function 对最后的softmax层参数的导数我们是对上面的J(θ)直接求的,像以前博客中求softmax模型参数导数一样。对于求前面几层参数的导数,因为前面n-1行的网络就是前面《神经网络中的参数的求解:前向和反向传播算法》博客中的网络,前面后向传播算法等大体也是上面的步骤。但是因为有最后softmax层,我们模型的cost function形式不一样,所以还是多少有些出入,这里我们把不同的地方重新求解一下:
我们进行后向算法的时候,只对图2中前n-1层进行后向传播,求前n-1层神经元的残差。
现在我们先对图2中![]() 神经元求残差
神经元求残差 ,从上面提到的博客中我们知道是
,从上面提到的博客中我们知道是![]() ,f为sigmoid函数。
,f为sigmoid函数。
我们在利用前向后向算法时,是一个样本一个样本进行的,所以每一个样本下模型的’小cost function‘是 ,i指的是第i个样本下的各个值。下面我们’小cost function’对
,i指的是第i个样本下的各个值。下面我们’小cost function’对![]() 求导,因为
求导,因为![]() 是一样向量,对它求导就是对向量里面的所以元素分别求导,我们现在由
是一样向量,对它求导就是对向量里面的所以元素分别求导,我们现在由![]() 形成的’小 cost function’对
形成的’小 cost function’对![]() 的第m个元素
的第m个元素![]() 求导:
求导:

这里的θ1m指的是前面博客定义的θ1(博客中定义的θ矩阵每一行分别为θ1转置,θ2转置,,,θk转置)向量的第m个元素。
然后小 cost function’对![]() 所有的元素求导的向量形式就可以表示为:
所有的元素求导的向量形式就可以表示为:![]() 。I,P都是当前
。I,P都是当前![]() 下的列向量(也就是在一个样本下)。
下的列向量(也就是在一个样本下)。![]() 这是一个列向量,里面的每一个元素就是小 cost function’对
这是一个列向量,里面的每一个元素就是小 cost function’对![]() 的某个元素求导的值。以上这些是某一个
的某个元素求导的值。以上这些是某一个![]() 下的计算,我们要对所有的
下的计算,我们要对所有的![]() 分别进行如上操作(在matlab中采用矩阵(矢量)运算中I,P是一个矩阵,每一列是对应的样本下的情况,那么
分别进行如上操作(在matlab中采用矩阵(矢量)运算中I,P是一个矩阵,每一列是对应的样本下的情况,那么![]() 也是一个矩阵,每一列对应一个样本的情况)。
也是一个矩阵,每一列对应一个样本的情况)。
之后的步骤跟《神经网络中的参数的求解:前向和反向传播算法》博客中步骤是一样的了,这里就不再重复了(还是有一点不同之处,这里我们说的cost function都是在没有稀疏项和L2正则项的,我们要加入这些正则项。而在以前的稀疏编码中只有一层隐藏层,而这里是有两层,所以在代码中还是有些不同的,具体的看代码注释)。
 ………………………………………………………………………………………………………………….图2
………………………………………………………………………………………………………………….图2
上述这种方法称为逐层贪婪训练的半监督的机器学习方法(又叫自学习方法):原始样本提取新特征阶段利用稀疏自编码进行无监督学习,但学习到一定程度的特征后,然后利用监督学习方法(如softmax回归)进行训练分类等。如果是上面提到的第一类直接进行有监督的学习,即每层进行贪婪训练时使用样本的label作为每一层训练网络的输出,那么就不需要最后的softmax等的分类学习了,因为它一开始就进行了监督学习,(这可能也是上面黄色字体所表达的不同的原因吧)所以它称为逐层贪婪训练的监督学习。现在比较常用的是前者:逐层贪婪训练的半监督学习。
那么这里的逐层贪婪训练的半监督学习跟最前面提到的“增加版”稀疏自编码神经网络(也就是在单隐藏层增加n个隐藏层后整体直接进行监督学习,也叫纯监督学习、朴素监督学习或直接叫监督学习)相比,有哪些优点呢(引自这里):
‘’
数据获取
虽然获取有标签数据的代价是昂贵的,但获取大量的无标签数据是容易的。自学习方法(self-taught learning)的潜力在于它能通过使用大量的无标签数据来学习到更好的模型。具体而言,该方法使用无标签数据来学习得到所有层(不包括用于预测标签的最终分类层)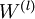 的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
的最佳初始权重。相比纯监督学习方法,这种自学习方法能够利用多得多的数据,并且能够学习和发现数据中存在的模式。因此该方法通常能够提高分类器的性能。
更好的局部极值
当用无标签数据训练完网络后,相比于随机初始化而言,各层初始权重会位于参数空间中较好的位置上。然后我们可以从这些位置出发进一步微调权重。从经验上来说,以这些位置为起点开始梯度下降更有可能收敛到比较好的局部极值点,这是因为无标签数据已经提供了大量输入数据中包含的模式的先验信息。
现在看一下程序:
我们还是去识别字体,数据库都和以前的一样。
首先我们先给出微调的这整个网络参数:
1: %% Here we provide the relevant parameters values that will
2: % allow your sparse autoencoder to get good filters;
3: clear all ; clc
4: inputSize = 28 * 28;%输入层的神经元个数(不包括+1的截距神经元,下面的hiddenSizeL1,2也不包括,因为在进行稀疏自编码的时候,以前我们写的函数
5: %使我们只需要输入不包括+1截距神经元信息的神经元个数和样本即可。但是下面的softmax层,我们在输入的时候我们就要添加+1层截距神经元信息,这点要
6: %注意,不然很容易出bug)
7: numClasses = 10; %类别有10个,label分别为1,2....10
8: hiddenSizeL1 = 200; % Layer 1 Hidden Size 如果你想展示你的二阶特征,这个值必须是一个数平方的值
9: hiddenSizeL2 = 200; % Layer 2 Hidden Size
10: sparsityParam = 0.1; % desired average activation of the hidden units.
11: % (This was denoted by the Greek alphabet rho, which looks like a lower-case "p",
12: % in the lecture notes). 两层隐藏层的各神经元的平均激活度都是这个值
13: lambda = 3e-3; % 稀疏自编码各层的L2范数权重 这个 3e-3参数值如果效果不好,可以自己再调一调
14: lambda2 = 1e-4; %softmax层L2范数权重 这个1e-4 参数值如果效果不好,可以自己再调一调
15: beta = 3; % weight of sparsity penalty term 稀疏自编码稀疏项的权重
16:
17: %%======================================================================
18: %% Load data from the MNIST database
19: % This loads our training data from the MNIST database files.
20: % Load MNIST database files
21: mnistData = loadMNISTImages('train-images.idx3-ubyte');
22: mnistLabels = loadMNISTLabels('train-labels.idx1-ubyte');
23: mnistLabels(mnistLabels == 0) = 10; % Remap 0 to 10 since our labels need to start from 1
24: trainData = mnistData;%训练样本
25: trainLabel= mnistLabels;
接下来我们先训练第一个稀疏自编码(这块跟以前代码一样,就不注释了,可以看以前博客的代码,有注释):
1: %% Train the first sparse autoencoder
2: % Randomly initialize the parameters
3: sae1Theta = initializeParameters(hiddenSizeL1, inputSize);
4: addpath minFunc/
5: options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
6: % function. Generally, for minFunc to work, you
7: % need a function pointer with two outputs: the
8: % function value and the gradient. In our problem,
9: % sparseAutoencoderCost.m satisfies this.
10: options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
11: options.display = 'on';
12: [sae1OptTheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
13: inputSize, hiddenSizeL1, ...
14: lambda, sparsityParam, ...
15: beta, trainData), ...
16: sae1Theta, options);
17: %现在训练好了第一个的稀疏编码神经网络
我们从下图可以看到最后cost function 收敛到 12.22附近

训练好以后我们想直观看看我们训练出来的那200个特征(代码为什么这么写原因在以前博客中已经说明了):
1: W1 = reshape(sae1OptTheta(1:hiddenSizeL1 * inputSize), hiddenSizeL1, inputSize);
2: display_network(W1');
稀疏自编码学习的200个特征如下:

训练第二个的稀疏编码神经网络:
1: %% Train the second sparse autoencoder
2: %开始训练第二个的稀疏编码神经网络,注意输入到第二个稀疏编码神经网络的训练样本应该是第一个稀疏编码的激活值。
3: %所以要把第一个的训练样本unlabeledData输入到feedForwardAutoencoder()得到激活值,做为第二个稀疏编码神经网络的训练样本。
4: [sae1Features] = feedForwardAutoencoder(sae1OptTheta, hiddenSizeL1, ...
5: inputSize, trainData);%sae1Features就是第二个稀疏编码神经网络的训练样本
6:
7: %进行第二个的稀疏编码神经网络训练,和第一个的方法一样
8: sae2Theta = initializeParameters(hiddenSizeL2, hiddenSizeL1);%这时候训练样本是第一层隐藏层的激活值,所以
9: %这时候的'inputSize'是hiddenSizeL1。
10: addpath minFunc/
11: options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
12: % function. Generally, for minFunc to work, you
13: % need a function pointer with two outputs: the
14: % function value and the gradient. In our problem,
15: % sparseAutoencoderCost.m satisfies this.
16: options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
17: options.display = 'on';
18: [sae2OptTheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
19: hiddenSizeL1, hiddenSizeL2, ...
20: lambda, sparsityParam, ...
21: beta, sae1Features), ...
22: sae2Theta, options);
23: %现在训练好了第二个的稀疏编码神经网络
我们从下图可以看到最后cost function 收敛到 3.589附近

训练好第二个的稀疏编码神经网络以后,我们想看下trainData的二阶特征是什么样的?为了说了更详细一点,这个放到下一个博客当中。
接下来我们就要训练整个模型的最后一层softmax 层了(这里再啰嗦几句,虽然softmax和前面稀疏自编码都需要+1的截距神经元,但是因为以前写的函数里面后者包括了+1的稀疏自编码,所以样本有多少维、有多少神经元有多少参数,你就不用管+1截距神经元了。而softmax你需要管这些):
1: %% Train the softmax classifier
2: % This trains the sparse autoencoder on the second autoencoder features.
3: [sae2Features] = feedForwardAutoencoder(sae2OptTheta, hiddenSizeL2, ...
4: hiddenSizeL1, sae1Features);%把sae1Features输入到训练好的第2个稀疏编码
5: %神经网络中即使用feedForwardAutoencoder,得到sae2Features,也就是用来训练
6: %softmax模型的训练样本,sae2Features大小和以前的data数据格式一样,每一列是一 %个样本。每一个样本有hiddenSizeL2维。
8: sae2Features=[ones(1,size(sae2Features,2));sae2Features];%增加一维截距+1
9: %在这里你不需要初始化softmax模型参数,因为下面softmaxTrain函数里面会自动初始化,还有输入softmaxTrain的‘putinsize’和样本应该包括
10: %+1的截距神经元,所以这里是‘putinsize’是hiddenSizeL2+1
11: options.maxIter = 100;
12: softmaxModel = softmaxTrain(hiddenSizeL2+1, numClasses, lambda2, ...
13: sae2Features, trainLabel, options);
14: %注意softmaxTrain里面有softmax_regression_vec函数,softmax_regression_vec函数输入的y需要是一个列向量(因为有sub2ind函数,具体看函 %数内部注释),所以这里的trainlabel
15: %需要是列向量。
16: saeSoftmaxOptTheta = softmaxModel.optTheta(:);
17: %softmax模型的参数已经训练好了。saeSoftmaxOptTheta是一个列向量。
我们从下图可以看到最后cost function 收敛到 0.368附近

接下来就是重头戏了,我们要微调整个网络了:
我们先初始化微调这一步整个网络的参数,注意这里不是随机的给出参数了,因为是微调,所以初始化的值是之前训练好的2个稀疏自编码模型的参数和
softmax层的参数。
1: %% Finetune softmax model
2: % Initialize the stackedAETheta using the parameters learned
3: %我们从前面的博客中已经说了,我们训练好每一个稀疏自编码,我们需要的是每个神经网络的第一层的参数,即w(1)和b(1),
4: %stack{1}是第一个稀疏自编码里面的w(1)和b(1)参数,stack{2}标记的是第二个稀疏自编码w(1)和b(1)参数
5: stack = cell(2,1);
6: stack{1}.w = reshape(sae1OptTheta(1:hiddenSizeL1*inputSize), ...
7: hiddenSizeL1, inputSize);
8: stack{1}.b = sae1OptTheta(2*hiddenSizeL1*inputSize+1:2*hiddenSizeL1*inputSize+hiddenSizeL1);
9: stack{2}.w = reshape(sae2OptTheta(1:hiddenSizeL2*hiddenSizeL1), ...
10: hiddenSizeL2, hiddenSizeL1);
11: stack{2}.b = sae2OptTheta(2*hiddenSizeL2*hiddenSizeL1+1:2*hiddenSizeL2*hiddenSizeL1+hiddenSizeL2);
12:
13: % Initialize the parameters for the deep model
14: [stackparams, netconfig] = stack2params(stack);%把原胞stack变成一个向量,注意这个向量里面元素代表的是什么,顺序不要混。
15: stackedAETheta = [ saeSoftmaxOptTheta ; stackparams ];%这个就是整个模型进行微调时参数的初始化
16: %stackedAETheta向量的头(hiddenSizeL2 +1)* numClasses个参数 是softmax 模型的参数。
17: save('debug2') %把前面运行完的得到的所有变量save 一下,因为接下来我们要看看写得wholeNetCost_and_grad函数 是否正确,
18: %又因为原模型太复杂,运行起来浪费时间,所以我们简化了一下模型,因此模型的结构和参数值都变了。我们再检测完正确以后,我们想训练这个微调这一步。
19: %我们还是需要原来整个模型的值,所以我们在检测这个函数正确以后,再load 一下debug2.
上面程序有一个stack2params函数:
1: function [params, netconfig] = stack2params(stack)
2:
3: % Converts a "stack" structure into a flattened parameter vector and also
4: % stores the network configuration. This is useful when working with
5: % optimization toolboxes such as minFunc.
6: %
7: % [params, netconfig] = stack2params(stack)
8: %
9: % stack - the stack structure, where stack{1}.w = weights of first layer
10: % stack{1}.b = weights of first layer
11: % stack{2}.w = weights of second layer
12: % stack{2}.b = weights of second layer
13: % ... etc.
14:
15:
16: % Setup the compressed param vector
17: params = [];
18: for d = 1:numel(stack)
19:
20: % This can be optimized. But since our stacks are relatively short, it
21: % is okay
22: params = [params ; stack{d}.w(:) ; stack{d}.b(:) ];
23:
24: % Check that stack is of the correct form
25: assert(size(stack{d}.w, 1) == size(stack{d}.b, 1), ... %assert(expression,'string')若expression是false的,那么就
26: ['The bias should be a *column* vector of ' ... 报错string那段话
27: int2str(size(stack{d}.w, 1)) 'x1']);
28: if d < numel(stack)
29: assert(size(stack{d}.w, 1) == size(stack{d+1}.w, 2), ...
30: ['The adjacent layers L' int2str(d) ' and L' int2str(d+1) ...
31: ' should have matching sizes.']);
32: end
33:
34: end
35: %params最后得到的是一个列向量,列向量的前hiddenSizeL1*inputSize个是以前训练的第一个稀疏自编码的w(1)(这里不包括b(1)),
36: %也是新的'大神经网络'(上面的图2)的第一层的参数(不包括+1的截距参数),列向量的第hiddenSizeL1*inputSize+1到
37: %hiddenSizeL1*inputSize+hiddenSizeL1是以前训练的第一个稀疏自编码的b(1)。列向量的第
38: %hiddenSizeL1*inputSize+hiddenSizeL1+1到hiddenSizeL1*inputSize+hiddenSizeL1+hiddenSizeL2*hiddenSizeL1
39: %以前训练的第二个稀疏自编码的w(1)(这里不包括b(1)),也是新的'大神经网络'(上面的图2)的第二层的参数(不包括+1的截距参数)
40: %第hiddenSizeL1*inputSize+hiddenSizeL1+hiddenSizeL2*hiddenSizeL1+1
41: %到hiddenSizeL1*inputSize+hiddenSizeL1+hiddenSizeL2*hiddenSizeL1+hiddenSizeL2是以前训练的第二个稀疏自编码的b(1)。
42: %但是我们发现这个‘大神经网络’第一、二层参数w和截距参数b在params的排列跟以前的神经网络的参数向量排列不怎么一样。(以前的把所有
43: %层的+1的截止参数都放最后)这个注意一下。
44: if nargout > 1
45: % Setup netconfig
46: if numel(stack) == 0
47: netconfig.inputsize = 0;
48: netconfig.layersizes = {};
49: else
50: netconfig.inputsize = size(stack{1}.w, 2);
51: netconfig.layersizes = {};
52: for d = 1:numel(stack)
53: netconfig.layersizes = [netconfig.layersizes ; size(stack{d}.w,1)];
54: end
55: end
56: end
57:
58: end
下面看看写得wholeNetCost_and_grad函数,这个函数的作用就是给定模型的参数θ,把样本都通过这个总的模型得到相应的模型输出,根据样本的label这个函数就给出了当前模型参数下的 cost function 和各模型参数的导数grad。
1: function [cost,grad] = wholeNetCost_and_grad(theta, visibleSize,hiddenSizeL1,hiddenSizeL2,numClasses ,...
2: lambda,lambda2, sparsityParam, beta, data,label)
3: %这个wholeNetCost_and_grad函数的作用是:你给定整个神经网络的结构,网络参数值,L2正则项、稀疏约束项的权重lambda,
4: %softmax的正则项lambda2,稀疏性参数。(在结构中注意一点,因为hiddenSizeL2即作为前面神经网络的输出,又作为最后
5: %一层softmax的输入,而做为前面神经网络的输出时,用的是以前写得稀疏自编码的程序(都是三层,只是第三层神经元个数不再是稀疏自编码
6: %输入神经元的个数,而是hiddenSizeL2),所以考虑每一层神经元个数或参数的时候,是不用考虑+1的截距神经元的,不是说稀疏自编码不需要,
7: %而是以前的函数内部已经有了,你只要输入除+1截距神经元的个数就可以了,而对于softmax层的输入,我们考虑ipuSixe的时候或有多少参数的
8: %时候,你要加上+1的截距神经元。所以下面对于softmax 的输入我们要hiddenSizeL2+1)
9: %那么这个函数就会给出这个神经网络的cost function的值(整个网络的cost function),和cost function对各个参数的偏导。
10: %注意label输入需要是一个列向量
11: %下面的W1,W2,b1,b2是总的模型第一层第二层参数,注意他在theta中的位置是什么,要细心。
12: W1 = reshape(theta((hiddenSizeL2 +1)* numClasses+1:(hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize),...
13: hiddenSizeL1, visibleSize);
14: W2 = reshape(theta((hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+hiddenSizeL1+1:...
15: (hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+hiddenSizeL1+ hiddenSizeL2*hiddenSizeL1),...
16: hiddenSizeL2, hiddenSizeL1);
17: b1 = theta((hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+1:...
18: (hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+hiddenSizeL1);
19: b2 = theta((hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+hiddenSizeL1+ hiddenSizeL2*hiddenSizeL1+1:end);
20: theta_softmax=reshape(theta(1:(hiddenSizeL2 +1)* numClasses),(hiddenSizeL2 +1),numClasses);
21: theta_softmax=theta_softmax(2:end,:);%求倒数第二层神经元残差时要用到最后一层的参数θ矩阵,但是这里面的θ矩阵要去掉截距参数
22: %应该倒数第二层+1的神经元不用求残差。
23: %% 初始化要求得的cost function 对各参数的偏导数
24: % Cost and gradient variables (your code needs to compute these values).
25: % Here, we initialize them to zeros.
26: cost = 0;
27: W1grad = zeros(size(W1)); %W1grad 也是一个矩阵,跟W1的行列数是一样的。里面的元素与神经网络里面的参数对应的情况和W1
28: %里元素与神经网络参数对应的情况是一样的。第一列各元素的含义是cost function 对输入层第一个神经元分别对应第二层隐藏层的
29: %各单元(不包括第二层偏置节点)的参数的偏导。
30: W2grad = zeros(size(W2));
31: b1grad = zeros(size(b1));
32: b2grad = zeros(size(b2));
33:
34: %% 求cost function 对各参数的偏导数
35: % Instructions: Compute the cost/optimization objective J_sparse(W,b) for the Sparse Autoencoder,
36: % and the corresponding gradients W1grad, W2grad, b1grad, b2grad.
37: %
38: % W1grad, W2grad, b1grad and b2grad should be computed using backpropagation.
39: % Note that W1grad has the same dimensions as W1, b1grad has the same dimensions
40: % as b1, etc. Your code should set W1grad to be the partial derivative of J_sparse(W,b) with
41: % respect to W1. I.e., W1grad(i,j) should be the partial derivative of J_sparse(W,b)
42: % with respect to the input parameter W1(i,j). Thus, W1grad should be equal to the term
43: % [(1/m) Delta W^{(1)} + lambda W^{(1)}] in the last block of pseudo-code in Section 2.2
44: % of the lecture notes (and similarly for W2grad, b1grad, b2grad).
45: %
46: % Stated differently, if we were using batch gradient descent to optimize the parameters,
47: % the gradient descent update to W1 would be W1 := W1 - alpha * W1grad, and similarly for W2, b1, b2.
48: %
49: %1.forward propagation
50: data_size=size(data);
51: biasPara_1=repmat(b1,1,data_size(2));
52: biasPara_2=repmat(b2,1,data_size(2));
53: active_value2=sigmoid(W1*data+biasPara_1);
54: active_value3=sigmoid(W2*active_value2+biasPara_2);
55: %active_value2这个矩阵每一列是每一个样本前向算法中第二层各单元的激活值(不包括偏置节点,因为偏置节点
56: %相当于激活值始终为1)。
57: %active_value3是第三层各单元的激活值。
58:
59: %最后一层的'传播':把active_value3增广数据输入softmax中得到这个模型最后的输出,使用的是softmax_regression_vec_addP函数
60: %softmax_regression_vec_addP是softmax_regression_vec在输出的时候增加了一个p,p矩阵每一列是每个样本对应的各个输出神经元的概率
61: softmax_input=[ones(1,size(active_value3,2));active_value3];%每个样本都加一个+1维
62: [p,cost,softmax_grad] = softmax_regression_vec_addP(theta(1:(hiddenSizeL2 +1)* numClasses),softmax_input ,...
63: label,lambda2 );
64: %这里的softmax_grad是一个向量,是softmax这一层的参数的导数。
65: weight_decay=lambda/2*(sum(sum(W1.^2))+sum(sum(W2.^2)));
66: %这是const function 中前面几层网络的L2正则项,softmax
67: %的L2正则项在softmax_regression_vec_addP已经有了,所以上面的那个cost 包括了。
68: active_average=[sum(active_value2,2)./data_size(2);sum(active_value3,2)./data_size(2)];
69: %因为这里有两层隐藏层,并且active_average是一个列向量的形式,里面每一个元素是每一个隐藏层神经元在所有样本下的平均激活值
70: p_para=repmat(sparsityParam,hiddenSizeL1+hiddenSizeL2,1);
71: %因为下面那行代码中有p_para./active_average所以要弄成和active_average一样size的列向量,才能与active_average里的元素点除。
72: sparsity=beta.*sum(p_para.*log(p_para./active_average)+(1-p_para).*log((1-p_para)./(1-active_average)));
73: %这是稀疏项
74: cost=cost+weight_decay+sparsity;%cost function就完成了。
75: %现在我们有了整个模型在特定θ下的cost function,也得到了最后一层softmax参数的导数,只剩下前面几层神经网络的导数了,
76: %现在我们用后向传播算法和一些其他公式进行求出,这里跟以前稍有不同的是整个模型倒数第二层神经元的残差,不同的地方已经在上面博客中
77: %说明了。
78:
79: %求残差
80: %根据博客中公式(稍有不同的是,这里是所有样本一块操作,每一列是一个样本的信息)
81: I=full(sparse(label,1:data_size(2),1)); %I为一个稀疏矩阵,这个矩阵的(label(1),1)、(label(2),2)
82: %....(label(m),m)位置都是1。
83: active_average_repmat1=repmat(sum(active_value3,2)./data_size(2),1,data_size(2));
84: default_sparsity1=repmat(sparsityParam,hiddenSizeL2,data_size(2));
85: sparsity_penalty1=beta.*(-(default_sparsity1./active_average_repmat1)+((1-default_sparsity1)./...
86: (1-active_average_repmat1)));
87: delta3=(theta_softmax*(p-I)+sparsity_penalty1).*(active_value3).*(1-active_value3);
88: %因为这里delta3、theta_softmax*(p-I)、active_value3都是一个矩阵,每一列是一个样本输入神经网络后第三层各个神经元的残差、激活值、小cost
89: %function(单样本)对第三层各个神经元的导数,列数代表样本数。所以sparsity_penalty1、active_average_repmat1、sparsity_penalty1
90: %要和前面提的矩阵大小相等。所以default_sparsity1是平铺hiddenSizeL2行。下面的default_sparsity也是同样道理平铺hiddenSizeL1行
91: active_average_repmat=repmat(sum(active_value2,2)./data_size(2),1,data_size(2));
92: %sum(active_value2,2)./data_size(2)就是active_average,然后repmat,因为active_average是一个列向量,再平铺
93: %data_size(2)列,那么active_average_repmat就是一个矩阵,弄成矩阵的的形式是为了后面所有样本第二层所有神经元
94: %一起运算。
95: default_sparsity=repmat(sparsityParam,hiddenSizeL1,data_size(2));
96: %default_sparsity也是一个hiddenSize*data_size(2)矩阵,弄成这个形式也是为了下面所有样本第二层所有神经元一起的矩阵
97: %运算。
98: sparsity_penalty=beta.*(-(default_sparsity./active_average_repmat)+((1-default_sparsity)./(1-active_average_repmat)));
99: delta2=(W2'*delta3+sparsity_penalty).*((active_value2).*(1-active_value2));
100:
101: %求各参数偏导
102: W2grad=delta3*active_value2'./data_size(2)+lambda.*W2;
103: %delta3*active_value2'得到的是一个矩阵,矩阵的第一个元素是所有样本对应的 小cost function
104: %对第二层的W11的偏导 的累加形成的总cost function对第二层的W11的偏导。矩阵第一行第二个元素是
105: %总cost function对第二层的W21的偏导。所以你看这里的W下标的顺序和前面的W矩阵是一样的。然后这个矩阵的元素都除以样本
106: %个数,得到的就是cost function中只有均方误差项时,对第二层各个参数的偏导。然后这个矩阵每个元素加上lambda倍的W2这个
107: %矩阵对应的元素,得到的W2grad矩阵的元素是总cost function对第二层各参数的偏导。
108: W1grad=delta2*data'./data_size(2)+lambda.*W1;
109: b2grad=sum(delta3,2)./data_size(2);%b2grad向量是总cost function对第二层偏置节点各参数的偏导
110: b1grad=sum(delta2,2)./data_size(2);
111:
112: %-------------------------------------------------------------------
113: % After computing the cost and gradient, we will convert the gradients back
114: % to a vector format (suitable for minFunc). Specifically, we will unroll
115: % your gradient matrices into a vector.
116:
117: grad = [softmax_grad;W1grad(:) ;b1grad(:) ; W2grad(:) ; b2grad(:)];%注意里面元素的顺序和theta是一样的。
118:
119: end
120:
121: %-------------------------------------------------------------------
122: % Here's an implementation of the sigmoid function, which you may find useful
123: % in your computation of the costs and the gradients. This inputs a (row or
124: % column) vector (say (z1, z2, z3)) and returns (f(z1), f(z2), f(z3)).
125: %若果x是个矩阵,也是可以的,igmoid(x)也是一个矩阵,里面的每个元素就是对应x矩阵对应的元素进行sigmoid计算。
126:
127: function sigm = sigmoid(x)
128:
129: sigm = 1 ./ (1 + exp(-x));
130: end
131:
接下面我们要对写的这个函数检验一下,在给定模型参数下,模型的cost function 对各参数求导是不是正确,检验方法是利用求导的定义,在前面已经讲了,因为这个模型和参数比较多,我们简化一下模型,对检验这个函数正确性上没有影响。
1: %% 看看写得wholeNetCost_and_grad 是否正确
2: DEBUG = true;
3: if DEBUG
4: stackedAETheta=0.005 * randn(430, 1);
5: inputSize = 20;
6: trainData = randn(20, 100);
7: hiddenSizeL1=10;
8: hiddenSizeL2=10;
9: numClasses=10;
10: trainLabel= randi(10, 100, 1);%从[1,10]中随机生成一个100*1的列向量
11: [cost,grad] = wholeNetCost_and_grad(stackedAETheta, inputSize, hiddenSizeL1,hiddenSizeL2,numClasses, ...
12: lambda,lambda2, sparsityParam, beta,trainData,trainLabel);
13: %注意trainlabel输入需要是一个列向量
14:
15:
16: numGrad = computeNumericalGradient( @(x) wholeNetCost_and_grad(x, inputSize, hiddenSizeL1,...
17: hiddenSizeL2,numClasses, ...
18: lambda,lambda2, sparsityParam, beta,trainData,trainLabel),...
19: stackedAETheta );
20:
21: disp([numGrad grad]);
22: diff = norm(numGrad-grad)/norm(numGrad+grad);
23: disp(diff);
24: end
结果为:

所以我们知道我们写的函数是正确的。
那么接下来就是微调了:
1: %% 微调 训练 前面的stackedAETheta就是这里最小化过程中的初始化参数向量
2: load debug2 %把前面的变量值再加载一遍
3: addpath minFunc/
4: options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
5: % function. Generally, for minFunc to work, you
6: % need a function pointer with two outputs: the
7: % function value and the gradient. In our problem,
8: % sparseAutoencoderCost.m satisfies this.
9: options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
10: options.display = 'on';
11: [stackedAEOptTheta, cost] = minFunc( @(p) wholeNetCost_and_grad(p, ...
12: inputSize, hiddenSizeL1,hiddenSizeL2,numClasses, ...
13: lambda,lambda2, sparsityParam, beta,trainData,trainLabel), ...
14: stackedAETheta, options);
15: %stackedAEOptTheta就是最终整个模型的参数。
现在模型的参数都已经训练好了,接下来就是检验了(检验用的数据库前面博客中已经给出了,可以去那里下载):
1: %% 测试
2: testData = loadMNISTImages('t10k-images.idx3-ubyte');
3: testLabels = loadMNISTLabels('t10k-labels.idx1-ubyte');
4:
5: testLabels(testLabels == 0) = 10; % Remap 0 to 10
6:
7: [pred] = stackedAEPredict(stackedAETheta, inputSize, hiddenSizeL1,hiddenSizeL2, numClasses, testData);
8:
9: acc = mean(testLabels(:) == pred(:));
10: fprintf('Before Finetuning Test Accuracy: %0.3f%% ', acc * 100);
11:
12: [pred] = stackedAEPredict(stackedAEOptTheta, inputSize, hiddenSizeL1,hiddenSizeL2, numClasses, testData);
13:
14: acc = mean(testLabels(:) == pred(:));
15: fprintf('After Finetuning Test Accuracy: %0.3f%% ', acc * 100);
代码中的stackedAEPredict函数:
1: function [pred] = stackedAEPredict(theta, visibleSize, hiddenSizeL1,hiddenSizeL2, numClasses, data)
2:
3: % stackedAEPredict: Takes a trained theta and a test data set,
4: % and returns the predicted labels for each example.
5:
6: % theta: trained weights from the autoencoder
7: % visibleSize: the number of input units
8: % hiddenSize: the number of hidden units *at the 2nd layer*
9: % numClasses: the number of categories
10: % data: Our matrix containing the training data as columns. So, data(:,i) is the i-th training example.
11:
12: % Your code should produce the prediction matrix
13: % pred, where pred(i) is argmax_c P(y(c) | x(i)).
14:
15: %% 下面的代码都是利用上面函数的部分代码,道理都是一样的,不懂的可以往前看看
16: W1 = reshape(theta((hiddenSizeL2 +1)* numClasses+1:(hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize),...
17: hiddenSizeL1, visibleSize);
18: W2 = reshape(theta((hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+hiddenSizeL1+1:...
19: (hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+hiddenSizeL1+ hiddenSizeL2*hiddenSizeL1),...
20: hiddenSizeL2, hiddenSizeL1);
21: b1 = theta((hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+1:...
22: (hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+hiddenSizeL1);
23: b2 = theta((hiddenSizeL2 +1)* numClasses+hiddenSizeL1*visibleSize+hiddenSizeL1+ hiddenSizeL2*hiddenSizeL1+1:end);
24: data_size=size(data);
25: biasPara_1=repmat(b1,1,data_size(2));
26: biasPara_2=repmat(b2,1,data_size(2));
27: active_value2=sigmoid(W1*data+biasPara_1);
28: active_value3=sigmoid(W2*active_value2+biasPara_2);
29: softmax_input=[ones(1,size(active_value3,2));active_value3];%每个样本都加一个+1维
30: p= softmax_regression_vec_justP(theta(1:(hiddenSizeL2 +1)* numClasses),softmax_input );%其实用的还是softmax_regression_vec
31: %函数,只是这里让它仅输出p
32: [q,pred]=max(p);%这里认为最大概率的类别就是样本类别
36: end
37:
39: % You might find this useful
40: function sigm = sigmoid(x)
41: sigm = 1 ./ (1 + exp(-x));
42: end
我们从下图可以看到最后cost function 收敛到 0.655附近
![PF]CRKIJO)$$2%BW0$N{FGI](https://images0.cnblogs.com/blog/703272/201502/031454455934019.png "PF]CRKIJO)$$2%BW0$N{FGI")
全部就完成了,看下我们最终的结果吧:
![]()
我们发现微调以后我们的正确率提高了3%多一点,我们可以通过调参数进一步的提高正确率。