抽象/接口
抽象和接口的区别 1.抽象方法不能有方法体 因为抽象类中可以包含非抽象方法 所以抽象类中的方法可以有方法体 因为接口类的方法完全是抽象方法 所以不能有方法体 2.实现方式: 子类用extends继承抽象类 并要实现抽象类的所有抽象方法(子类非抽象类的话就不用实现方法) 子类用implements实现接口类 并要实现所有方法 3.构造函数 抽象类可以有构造函数 接口类不能 4.访问修饰符 抽象类方法不能用private修饰 因为抽象方法就是要让别人实现 5.多继承 一个子类只能继承一个抽象类 子类可以实现多个接口 6.添加新方法 抽象类可以不修改子类的情况下添加新方法(添加非抽象方法) 接口类不行 接口类新增方法后也要在实现类中重写 抽象类和接口类适用场景 1.让方法中有默认的实现 用抽象类(抽象类可以有构造函数) 2.要实现多继承 用接口类(接口用实现 抽象类用继承 java不能多继承) 注:java实现类不能多继承 接口是可以多继承的
基本的js选择器
基本的js选择器 1.原生js选择器 getElementById() id选择 getElementsByName() name选择 getElementsByTagName() 标签选择 getElementsByClassName() class名称选择 2.jquery选择器 $("#id") $("div") $(".class")
HashMap原理
hashmap底层是数组+链表
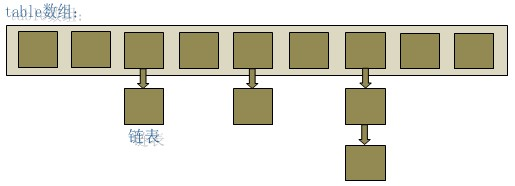
HashMap.put时先利用key的hashcode计算出存放数组的下标
数组该hashcode下标位置空的就插入kv
数组该hashcode下标位置非空的就equal判断key值 key相同覆盖 key不同把kv放入链表中 HashMap.get时先算出key的hashcode 再从数组中找到kv hashmap扩容 数组+链表的形式 但是数组的长度是固定的 存放到hashmap的数据太多的话底层会扩容 扩容得重新计算数组位置很影响性能 hashmap什么时候会扩容? 元素个数超过(数组大小*0.75)时会扩容 例子:new HashMap(1024); 需要存放元素的个数为1000 1024*0.75=768 即数组大小为1024 元素个数超过768时会自动扩容 因此元素个数1000时为了不扩容new HashMap(2048)更合适
IOC AOP?
什么是IOC? 具体的讲:当某个角色需要另外一个角色协助的时候,在传统的程序设计过程中,通常由调用者来创建被调用者的实例。但在spring中创建被调用者的工作不再由调用者来完成,因此称为控制反转。创建被调用者的工作由spring来完成,然后注入调用者 因此也称为依赖注入。 spring以动态灵活的方式来管理对象 , 注入的两种方式,设置注入和构造注入。 设置注入的优点:直观,自然 构造注入的优点:可以在构造器中决定依赖关系的顺序。 什么是AOP? 面向切面编程在spring中主要表现为两个方面 1.面向切面编程提供声明式事务管理 2.spring支持用户自定义的切面 Spring的事务管理机制实现的原理,就是通过这样一个动态代理对所有需要事务管理的Bean进行加载,并根据配置在invoke方法中对当前调用的 方法名进行判定,并在method.invoke方法前后为其加上合适的事务管理代码,这样就实现了Spring式的事务管理。Spring中的AOP实 现更为复杂和灵活,不过基本原理是一致的。
如何保证接口保证幂等性
幂等意味着,对于同一个交易的多次处理/重复提交,结果不变 1.每个交易都一个唯一的交易号 操作成功的id存到bitmap中 若这个id号出现重复 就不再继续操作 2.表中定义格主键或唯一索引id对应每次的交易 就只能插入一次 3.把同一交易需操作的放在一个事务中,相当于加悲观锁 4.前端控制插入的交易只允许点一次
事务不生效的原因
1.异常被try catch捕获 事务默认捕获异常是RuntimeException
想其它异常捕获可以加@Transactional(rollbackFor = Exception.class)
2.同类中普通方法调用了@Transactional注解方法
因为不是直接调@Transactional方法也不会生效
3.@Transactional注解方法的类没有被加载bean(即没有被@componse等注解)
4.@Transactional注解的方法不是public
5.数据源没配置事务管理
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);}
6.方法上事务这样的@Transactional(propagation = Propagation.NOT_SUPPORTED)
表示不以事务运行
2不生效的根本原因: spring扫描bean时会扫描方法上是否有@Transactional注解
有的话会为bean生成一个代理类 这个方法实际上是由代理类来调用的
代理类在调用前会开启事务
如果这个@Transactional注解方法由同类的其它方法调用的话自然没通过代理类
所以事务无效
主要记住123
过滤器拦截器区别
①拦截器是基于java的反射机制的,而过滤器是基于函数回调。 ②拦截器不依赖与servlet容器,过滤器依赖与servlet容器。 ③拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。 ④拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。 ⑤在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次。 ⑥拦截器可以获取IOC容器中的各个bean,而过滤器就不行,这点很重要,在拦截器里注入一个service,可以调用业务逻辑。 1.过滤器和拦截器触发时机不一样: ⑦过滤器是在请求进入容器后,但请求进入servlet之前进行预处理的。请求结束返回也是,是在servlet处理完后,返回给前端之前。 拦截器实现HandlerInterceptor 过滤器实现Filter 主要记住⑥⑦
栈和队列
Stack 栈方法 (先进后出)(失败抛异常) push(e) //进队列,将元素加入队列头 pop() //获取队列头的元素并移除 peek() //获取队列头的元素(不抛异常) Queue 队列方法 (先进先出)(失败不抛异常) offer(e) //进队列,将元素加入队列末尾 poll() //获取队列头的元素并移除 peek() 下面的api若失败抛异常 尽量用上面的api add() remove() Linklist能支持队列和栈的api
sleep和wait区别
1.Thread.sleep(3000L); sleep让当前线程休眠 wait必须在synchronized中 wait唤醒可以用wait(1000);定义唤醒时间 也可以lock.notifyall();主动唤醒 2.sleep一般用于当前线程 wait用于多线程 比如生产者消费者模式中 notifyAll()唤醒其它线程 3.sleep属于Thread wait属于Object 4.wait休眠能释放当前线程的对象锁 其它线程能获取锁 sleep休眠还拿着锁 其它线程也进不来
cookie session
个人理解可能有误: 在传统单机项目中 用户登录后服务端将请求的用户信息放在session中 springmvc中的@sessionAttibute{}生成session
并将sessionid给客户端 客户端放在cookie中 客户端再次请求时会自动将cookie发送给服务端 服务端获取httpsession校验 符合校验规则通过 否则请求失败
过滤器 拦截器
1.触发时机不同 请求进入顺序:-tomcat-Filter-Servlet-Inteceptor-Controller 过滤器先触发 拦截器再触发 2.根据1的结论 拦截器可以获取IOC容器中的各个bean,而过滤器就不行,这点很重要,在拦截器里注入一个service,可以调用业务逻辑。 3.拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用 4.filter在servlet前后起作用 Inteceptor是spring组件 能对请求前后处理 spring项目用拦截器更有灵活性
hibernate mybatis
Hibernate 是一个全表映射的框架,只需提供 POJO 和映射关系即可
MyBatis 是一个半自动映射的框架,因为 MyBatis 需要手动匹配 POJO、SQL 和映射关系。
Hibernate 数据库移植性很好,
MyBatis 的数据库移植性不好,不同的数据库需要写不同 SQL
Hibernate 有更好的二级缓存机制,可以使用第三方缓存。
MyBatis 本身提供的缓存机制不佳。
MyBatis 可以进行更为细致的 SQL 优化,可以减少查询字段
MyBatis 容易掌握,而 Hibernate 门槛较高
mysql oracle
事务提交
MySQL默认是自动提交
Oracle默认不自动提交,需要用户手动提交,需要在写commit;指令或者点击commit按钮
分页
mysql limit oracle rownum
事务支持
MySQL在innodb存储引擎的行级锁的情况下才可支持事务,而Oracle则完全支持事务
MySQL以表级锁为主,对资源锁定的粒度很大,InnoDB引擎的表可以用行级锁,但这个行级锁的机制依赖于表的索引
Oracle使用行级锁,对资源锁定的粒度要小很多
MYSQL有自动增长的数据类型
ORACLE没有自动增长的数据类型,需要建立一个自动增长的序列号SEQUENCE
MYSQL里可以用双引号包起字符串,ORACLE里只可以用单引号包起字符串