**数据质量检查是在完成宽表数据开发后进行的,主要包括四个方面:重复值检查、缺失值检查、数据倾斜检查、异常值检查。**数据行业有一句很经典的话——“垃圾进,垃圾出”(Garbage in, Garbage out, GIGO),意思就是,如果使用的基础数据有问题,那基于这些数据得到的任何产出都是没有价值的。而对于数据分析挖掘而言,只有一份高质量的基础数据,才可能得到正确、有用的结论。本文主要介绍数据质量检查的基本思路和方法,具体包括:从哪些角度检查数据质量问题、发现数据质量问题后又如何处理两方面,并提供基于Python的实现方法。
另外,数据质量检查是数据治理中的一个重要课题,涉及内容广,由于笔者经验水平有限,本文不做涉及,只从分析挖掘中的数据质量检查工作说起。
0. 示例数据集说明
数据集:/labcenter/python/dataset.xlsx
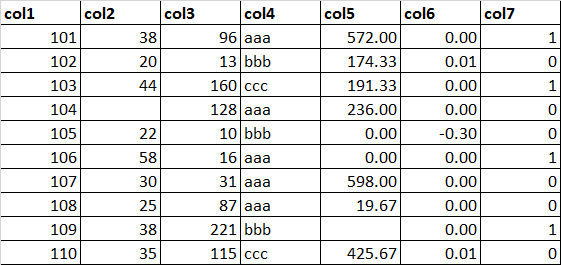
#读取数据集
import pandas as pd
dataset = pd.read_excel("/labcenter/python/dataset.xlsx")
#打印数据集
dataset
Out[6]:
col1 col2 col3 col4 col5 col6 col7
0 101 38.0 96 aaa 572.0000 0.0017 1
1 102 20.0 13 bbb 174.3333 0.0115 0
2 103 44.0 160 ccc 191.3333 0.0000 1
3 104 NaN 128 aaa 236.0000 0.0000 0
4 105 22.0 10 bbb 0.0000 -0.3000 0
5 106 58.0 16 aaa 0.0000 0.0000 1
6 107 30.0 31 aaa 598.0000 0.0000 0
7 108 25.0 87 aaa 19.6667 0.0000 0
8 109 38.0 221 bbb NaN 0.0000 1
9 110 35.0 115 ccc 425.6667 0.0094 0
##1. 重复值检查 ###1.1 什么是重复值 重复值的检查首先要明确一点,即重复值的定义。对于一份二维表形式的数据集来说,什么是重复值?可以从**两个层次**进行理解: ① 关键字段出现相同的记录,比如主索引字段出现重复; ② 所有字段出现相同的记录。 第一个层次是否是重复,必须从这份数据的业务含义进行确定,比如在一张表中,从业务上讲,一个用户应该只会有一条记录,那么如果某个用户出现了超过一条的记录,那么这就是重复值。第二个层次,就一定是重复值了。 ###1.2 重复值产生的原因 重复值的产生主要有**两种原因**,一是上游源数据造成的,二是数据准备脚本中的数据关联造成的。从数据准备角度来看,首先要检查数据准备的脚本,判断使用的源表是否有重复记录,同时检查关联语句的正确性和严谨性,比如关联条件是否合理、是否有限定数据周期等等。 比如:检查源表数据是否有重复的SQL:
SELECT MON_ID,COUNT(*),COUNT(DISTINCT USER_ID)
FROM TABLE_NAME
GROUP BY MON_ID;
如果是上游源数据出现重复,那么应该及时反映给上游进行修正;如果是脚本关联造成的,修改脚本,重新生成数据即可。
但在很多时候,用来分析的这份数据集是一份单独的数据集,并不是在数据仓库中开发得到的数据,既没有上游源数据,也不存在生成数据的脚本,比如公开数据集,那么如何处理其中的重复值?一般的处理方式就是直接删除重复值。
#判断重复数据
dataset.duplicated() #全部字段重复是重复数据
Out[3]:
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
dtype: bool
dataset.duplicated(['col2']) #col2字段重复是重复数据
Out[4]:
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 True
9 False
dtype: bool
#删除重复数据
dataset.drop_duplicates() #全部字段重复是重复数据
Out[5]:
col1 col2 col3 col4 col5 col6 col7
0 101 38.0 96 aaa 572.0000 0.0017 1
1 102 20.0 13 bbb 174.3333 0.0115 0
2 103 44.0 160 ccc 191.3333 0.0000 1
3 104 NaN 128 aaa 236.0000 0.0000 0
4 105 22.0 10 bbb 0.0000 -0.3000 0
5 106 58.0 16 aaa 0.0000 0.0000 1
6 107 30.0 31 aaa 598.0000 0.0000 0
7 108 25.0 87 aaa 19.6667 0.0000 0
8 109 38.0 221 bbb NaN 0.0000 1
9 110 35.0 115 ccc 425.6667 0.0094 0
dataset.drop_duplicates(['col2']) #col2字段重复是重复数据
Out[7]:
col1 col2 col3 col4 col5 col6 col7
0 101 38.0 96 aaa 572.0000 0.0017 1
1 102 20.0 13 bbb 174.3333 0.0115 0
2 103 44.0 160 ccc 191.3333 0.0000 1
3 104 NaN 128 aaa 236.0000 0.0000 0
4 105 22.0 10 bbb 0.0000 -0.3000 0
5 106 58.0 16 aaa 0.0000 0.0000 1
6 107 30.0 31 aaa 598.0000 0.0000 0
7 108 25.0 87 aaa 19.6667 0.0000 0
9 110 35.0 115 ccc 425.6667 0.0094 0
##2. 缺失值检查 **缺失值主要是指数据集中部分记录存在部分字段的信息缺失。** ###2.1 缺失值出现的原因 出现缺失值主要有**三种原因**: ① 上游源系统因为技术或者成本原因无法完全获取到这一信息,比如对用户手机APP上网记录的解析,一般来说,解析率相对较低; ② 从业务上讲,这一信息本来就不存在,比如一个学生的收入,一个未婚者的配偶姓名; ③ 数据准备脚本开发中出现的错误造成的。 第一种原因,短期内无法解决;第二种原因,数据的缺失并不是错误,而是一种不能避免的客观事实;第三种原因,则只需通过查证修改脚本即可。 缺失值的存在代表了某一部分信息的丢失,直接影响了挖掘分析结论的可靠性与稳定性,因此,必须对缺失值进行处理。 **一般来说:** **如果某字段的缺失值记录数超过了全部记录数的50%,则应该从数据集中直接剔除掉该字段,同时尝试从业务上寻找替代字段;** **如果某字段的缺失值记录数超过了全部记录数的20%,但没有超过50%,则应该首先看这个字段在业务上是否有替代字段,如果有,则直接剔除掉该字段,如果没有,则必须对其进行处理;** **如果某字段的缺失值记录数没有超过全部记录数的20%,不需要剔除该字段,但必须对其进行处理。**
#查看哪些字段有缺失值
dataset.isnull().any() #获取含有NaN的字段
Out[13]:
col1 False
col2 True
col3 False
col4 False
col5 True
col6 False
col7 False
dtype: bool
#统计各字段的缺失值个数
dataset.isnull().apply(pd.value_counts)
Out[14]:
col1 col2 col3 col4 col5 col6 col7
False 10.0 9 10.0 10.0 9 10.0 10.0
True NaN 1 NaN NaN 1 NaN NaN
#删除含有缺失值的字段
nan_col = dataset.isnull().any()
dataset.drop(nan_col[nan_col].index,axis=1)
Out[15]:
col1 col3 col4 col6 col7
0 101 96 aaa 0.0017 1
1 102 13 bbb 0.0115 0
2 103 160 ccc 0.0000 1
3 104 128 aaa 0.0000 0
4 105 10 bbb -0.3000 0
5 106 16 aaa 0.0000 1
6 107 31 aaa 0.0000 0
7 108 87 aaa 0.0000 0
8 109 221 bbb 0.0000 1
9 110 115 ccc 0.0094 0
2.2 缺失值的处理
缺失值的处理主要有两种方式:过滤和填充。
(1)缺失值的过滤
直接删除含有缺失值的记录,总体上会影响样本个数,如果要删除的样本过多或者数据集本来就很小时,这种方式并不建议采用。
#删除含有缺失值的记录
dataset.dropna()
Out[20]:
col1 col2 col3 col4 col5 col6 col7
0 101 38.0 96 aaa 572.0000 0.0017 1
1 102 20.0 13 bbb 174.3333 0.0115 0
2 103 44.0 160 ccc 191.3333 0.0000 1
4 105 22.0 10 bbb 0.0000 -0.3000 0
5 106 58.0 16 aaa 0.0000 0.0000 1
6 107 30.0 31 aaa 598.0000 0.0000 0
7 108 25.0 87 aaa 19.6667 0.0000 0
9 110 35.0 115 ccc 425.6667 0.0094 0
(2)缺失值的填充
缺失值的填充主要三种方法:
① 方法一:使用特定值填充
使用缺失值字段的平均值、中位数、众数等统计量填充。
优点:简单、快速
缺点:容易产生数据倾斜
② 方法二:使用算法预测填充
将缺失值字段作为因变量,将没有缺失值字段作为自变量,使用决策树、随机森林、KNN、回归等预测算法进行缺失值的预测,用预测结果进行填充。
优点:相对精确
缺点:效率低,如果缺失值字段与其他字段相关性不大,预测效果差
③ 方法三:将缺失值单独作为一个分组,指定值进行填充
从业务上选择一个单独的值进行填充,使缺失值区别于其他值而作为一个分组,从而不影响后续的分析计算。
优点:简单,实用
缺点:效率低,需要逐一进行填充
##使用Pandas进行特定值填充
#不同字段的缺失值都用0填充
dataset.fillna(0)
Out[16]:
col1 col2 col3 col4 col5 col6 col7
0 101 38.0 96 aaa 572.0000 0.0017 1
1 102 20.0 13 bbb 174.3333 0.0115 0
2 103 44.0 160 ccc 191.3333 0.0000 1
3 104 0.0 128 aaa 236.0000 0.0000 0
4 105 22.0 10 bbb 0.0000 -0.3000 0
5 106 58.0 16 aaa 0.0000 0.0000 1
6 107 30.0 31 aaa 598.0000 0.0000 0
7 108 25.0 87 aaa 19.6667 0.0000 0
8 109 38.0 221 bbb 0.0000 0.0000 1
9 110 35.0 115 ccc 425.6667 0.0094 0
#不同字段使用不同的填充值
dataset.fillna({'col2':20,'col5':0})
Out[17]:
col1 col2 col3 col4 col5 col6 col7
0 101 38.0 96 aaa 572.0000 0.0017 1
1 102 20.0 13 bbb 174.3333 0.0115 0
2 103 44.0 160 ccc 191.3333 0.0000 1
3 104 20.0 128 aaa 236.0000 0.0000 0
4 105 22.0 10 bbb 0.0000 -0.3000 0
5 106 58.0 16 aaa 0.0000 0.0000 1
6 107 30.0 31 aaa 598.0000 0.0000 0
7 108 25.0 87 aaa 19.6667 0.0000 0
8 109 38.0 221 bbb 0.0000 0.0000 1
9 110 35.0 115 ccc 425.6667 0.0094 0
#分别使用各字段的平均值填充
dataset.fillna(dataset.mean())
Out[18]:
col1 col2 col3 col4 col5 col6 col7
0 101 38.000000 96 aaa 572.000000 0.0017 1
1 102 20.000000 13 bbb 174.333300 0.0115 0
2 103 44.000000 160 ccc 191.333300 0.0000 1
3 104 34.444444 128 aaa 236.000000 0.0000 0
4 105 22.000000 10 bbb 0.000000 -0.3000 0
5 106 58.000000 16 aaa 0.000000 0.0000 1
6 107 30.000000 31 aaa 598.000000 0.0000 0
7 108 25.000000 87 aaa 19.666700 0.0000 0
8 109 38.000000 221 bbb 246.333333 0.0000 1
9 110 35.000000 115 ccc 425.666700 0.0094 0
#分别使用各字段的中位数填充
dataset.fillna(dataset.median())
Out[19]:
col1 col2 col3 col4 col5 col6 col7
0 101 38.0 96 aaa 572.0000 0.0017 1
1 102 20.0 13 bbb 174.3333 0.0115 0
2 103 44.0 160 ccc 191.3333 0.0000 1
3 104 35.0 128 aaa 236.0000 0.0000 0
4 105 22.0 10 bbb 0.0000 -0.3000 0
5 106 58.0 16 aaa 0.0000 0.0000 1
6 107 30.0 31 aaa 598.0000 0.0000 0
7 108 25.0 87 aaa 19.6667 0.0000 0
8 109 38.0 221 bbb 191.3333 0.0000 1
9 110 35.0 115 ccc 425.6667 0.0094 0
##使用sklearn中的预处理方法进行缺失值填充(只适用于连续型字段)
from sklearn.preprocessing import Imputer
#删除非数值型字段
dataset2 = dataset.drop(['col4'],axis=1)
#打印新数据集
dataset2
Out[35]:
col1 col2 col3 col5 col6 col7
0 101 38.0 96 572.0000 0.0017 1
1 102 20.0 13 174.3333 0.0115 0
2 103 44.0 160 191.3333 0.0000 1
3 104 NaN 128 236.0000 0.0000 0
4 105 22.0 10 0.0000 -0.3000 0
5 106 58.0 16 0.0000 0.0000 1
6 107 30.0 31 598.0000 0.0000 0
7 108 25.0 87 19.6667 0.0000 0
8 109 38.0 221 NaN 0.0000 1
9 110 35.0 115 425.6667 0.0094 0
#创建填充规则(平均值填充)
nan_rule1 = Imputer(missing_values='NaN',strategy='mean',axis=0)
#应用规则
pd.DataFrame(nan_rule1.fit_transform(dataset2),columns=dataset2.columns)
Out[36]:
col1 col2 col3 col5 col6 col7
0 101.0 38.000000 96.0 572.000000 0.0017 1.0
1 102.0 20.000000 13.0 174.333300 0.0115 0.0
2 103.0 44.000000 160.0 191.333300 0.0000 1.0
3 104.0 34.444444 128.0 236.000000 0.0000 0.0
4 105.0 22.000000 10.0 0.000000 -0.3000 0.0
5 106.0 58.000000 16.0 0.000000 0.0000 1.0
6 107.0 30.000000 31.0 598.000000 0.0000 0.0
7 108.0 25.000000 87.0 19.666700 0.0000 0.0
8 109.0 38.000000 221.0 246.333333 0.0000 1.0
9 110.0 35.000000 115.0 425.666700 0.0094 0.0
#创建填充规则(中位数填充)
nan_rule2 = Imputer(missing_values='NaN',strategy='median',axis=0)
#应用规则
pd.DataFrame(nan_rule2.fit_transform(dataset2),columns=dataset2.columns)
Out[37]:
col1 col2 col3 col5 col6 col7
0 101.0 38.0 96.0 572.0000 0.0017 1.0
1 102.0 20.0 13.0 174.3333 0.0115 0.0
2 103.0 44.0 160.0 191.3333 0.0000 1.0
3 104.0 35.0 128.0 236.0000 0.0000 0.0
4 105.0 22.0 10.0 0.0000 -0.3000 0.0
5 106.0 58.0 16.0 0.0000 0.0000 1.0
6 107.0 30.0 31.0 598.0000 0.0000 0.0
7 108.0 25.0 87.0 19.6667 0.0000 0.0
8 109.0 38.0 221.0 191.3333 0.0000 1.0
9 110.0 35.0 115.0 425.6667 0.0094 0.0
#创建填充规则(众数填充)
nan_rule3 = Imputer(missing_values='NaN',strategy='most_frequent',axis=0)
#应用规则
pd.DataFrame(nan_rule3.fit_transform(dataset2),columns=dataset2.columns)
Out[38]:
col1 col2 col3 col5 col6 col7
0 101.0 38.0 96.0 572.0000 0.0017 1.0
1 102.0 20.0 13.0 174.3333 0.0115 0.0
2 103.0 44.0 160.0 191.3333 0.0000 1.0
3 104.0 38.0 128.0 236.0000 0.0000 0.0
4 105.0 22.0 10.0 0.0000 -0.3000 0.0
5 106.0 58.0 16.0 0.0000 0.0000 1.0
6 107.0 30.0 31.0 598.0000 0.0000 0.0
7 108.0 25.0 87.0 19.6667 0.0000 0.0
8 109.0 38.0 221.0 0.0000 0.0000 1.0
9 110.0 35.0 115.0 425.6667 0.0094 0.0
##3. 数据倾斜检查 **数据倾斜是指字段的取值分布主要集中在某个特定类别或者特定区间。** ###3.1 数据倾斜问题的原因 出现这一问题主要有**三种原因**: ① 上游源数据存在问题; ② 数据准备脚本的问题; ③ 数据本身的分布就是如此。 如果某个字段出现数据倾斜问题,必须首先排查上述第一、二种原因,如果都没有问题或者无法检查(如:单独的数据集),那么就要考虑这个字段对后续的分析建模是否有价值。一般来说,有严重的数据倾斜的字段对目标变量的区分能力很弱,对分析建模的价值不大,应该直接剔除掉。 ###3.2 如何衡量数据的倾斜程度 衡量数据的倾斜程度,主要采用频数分析方法,但因数据类别的不同而有所差异: ① 针对连续型字段,需要首先采用等宽分箱方式进行离散化,然后计算各分箱的记录数分布; ② 针对离散型字段,直接计算各类别的记录数分布。 一般来说,如果某个字段90%以上的记录数,主要集中在某个特定类别或者特定区间,那么这个字段就存在严重的数据倾斜问题。
#对于连续型变量进行等宽分箱
pd.value_counts(pd.cut(dataset['col3'],5)) #分成5箱
Out[39]:
(9.789, 52.2] 4
(94.4, 136.6] 3
(178.8, 221] 1
(136.6, 178.8] 1
(52.2, 94.4] 1
Name: col3, dtype: int64
#对于离散型变量进行频数统计
pd.value_counts(dataset['col4'])
Out[40]:
aaa 5
bbb 3
ccc 2
Name: col4, dtype: int64
##4. 异常值检查 **异常值是指数据中出现了处于特定分布、范围或者趋势之外的数据,这些数据一般会被称为异常值、离群点、噪声数据等。** ###4.1 异常值产生的原因 异常值的产生主要有**两种原因**: ① 数据采集、生成或者传递过程中发生的错误; ② 业务运营过程出现的一些特殊情况。 将第一种原因产生的异常值称为**统计上的异常**,这是错误带来的数据问题,需要解决;将第二种原因产生的异常值称为**业务上的异常**,反映了业务运营过程的某种特殊结果,它不是错误,但需要深究,在数据挖掘中的一种典型应用就是异常检测模型,比如信用卡欺诈,网络入侵检测、客户异动行为识别等等。 ###4.2 异常值的识别方法 异常值的识别方法主要有以下几种: ####(1)极值检查 主要检查字段的取值是否超出了合理的值域范围。 **① 方法一:最大值最小值** 使用最大值、最小值进行判断。比如客户年龄的最大值为199岁,客户账单的最小费用为-20,这些都明显存在异常。 **② 方法二:3σ原则** 如果数据服从正态分布,在3σ原则下,异常值被定义为与平均值的偏差超过了3倍标准差的值。这是因为,在正态分布的假设下,具体平均值3倍标准差之外的值出现的概率低于0.003,属于极个别的小概率事件。 **③ 方法三:箱线图分析** 箱线图提供了识别异常的标准:异常值被定义为小于下四分位-1.5倍的四分位间距,或者大于上四分位+1.5倍的四分位间距的值。 箱线图分析不要求数据服从任何分布,因此对异常值的识别比较客观。
#获取描述性统计量
statDF = dataset2.describe()
#打印统计量
statDF
Out[45]:
col1 col2 col3 col5 col6 col7
count 10.00000 9.000000 10.000000 9.000000 10.000000 10.000000
mean 105.50000 34.444444 87.700000 246.333333 -0.027740 0.400000
std 3.02765 11.959422 71.030588 235.303647 0.095759 0.516398
min 101.00000 20.000000 10.000000 0.000000 -0.300000 0.000000
25% 103.25000 25.000000 19.750000 19.666700 0.000000 0.000000
50% 105.50000 35.000000 91.500000 191.333300 0.000000 0.000000
75% 107.75000 38.000000 124.750000 425.666700 0.001275 1.000000
max 110.00000 58.000000 221.000000 598.000000 0.011500 1.000000
#计算平均值+3倍标准差
statDF.loc['mean+3std'] = statDF.loc['mean'] + 3 * statDF.loc['std']
#计算平均值-3倍标准差
statDF.loc['mean-3std'] = statDF.loc['mean'] - 3 * statDF.loc['std']
#计算上四分位+1.5倍的四分位间距
statDF.loc['75%+1.5dist'] = statDF.loc['75%'] + 1.5 * (statDF.loc['75%'] - statDF.loc['25%'])
#计算下四分位-1.5倍的四分位间距
statDF.loc['25%-1.5dist'] = statDF.loc['25%'] - 1.5 * (statDF.loc['75%'] - statDF.loc['25%'])
#再次打印统计量
statDF
Out[50]:
col1 col2 col3 col5 col6 col7
count 10.000000 9.000000 10.000000 9.000000 10.000000 10.000000
mean 105.500000 34.444444 87.700000 246.333333 -0.027740 0.400000
std 3.027650 11.959422 71.030588 235.303647 0.095759 0.516398
min 101.000000 20.000000 10.000000 0.000000 -0.300000 0.000000
25% 103.250000 25.000000 19.750000 19.666700 0.000000 0.000000
50% 105.500000 35.000000 91.500000 191.333300 0.000000 0.000000
75% 107.750000 38.000000 124.750000 425.666700 0.001275 1.000000
max 110.000000 58.000000 221.000000 598.000000 0.011500 1.000000
mean+3std 114.582951 70.322711 300.791764 952.244274 0.259538 1.949193
mean-3std 96.417049 -1.433822 -125.391764 -459.577607 -0.315018 -1.149193
75%+1.5dist 114.500000 57.500000 282.250000 1034.666700 0.003187 2.500000
25%-1.5dist 96.500000 5.500000 -137.750000 -589.333300 -0.001912 -1.500000
#获取各字段最大值、最小值
statDF.loc[['max','min']]
Out[51]:
col1 col2 col3 col5 col6 col7
max 110.0 58.0 221.0 598.0 0.0115 1.0
min 101.0 20.0 10.0 0.0 -0.3000 0.0
#判断取值是否大于平均值+3倍标准差
dataset3 = dataset2 - statDF.loc['mean+3std']
dataset3[dataset3>0]
Out[52]:
col1 col2 col3 col5 col6 col7
0 NaN NaN NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN NaN
5 NaN NaN NaN NaN NaN NaN
6 NaN NaN NaN NaN NaN NaN
7 NaN NaN NaN NaN NaN NaN
8 NaN NaN NaN NaN NaN NaN
9 NaN NaN NaN NaN NaN NaN
#判断取值是否小于平均值-3倍标准差
dataset4 = dataset2 - statDF.loc['mean-3std']
dataset4[dataset4<0]
Out[53]:
col1 col2 col3 col5 col6 col7
0 NaN NaN NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN NaN
5 NaN NaN NaN NaN NaN NaN
6 NaN NaN NaN NaN NaN NaN
7 NaN NaN NaN NaN NaN NaN
8 NaN NaN NaN NaN NaN NaN
9 NaN NaN NaN NaN NaN NaN
#判断取值是否大于上四分位+1.5倍的四分位间距
dataset5 = dataset2 - statDF.loc['75%+1.5dist']
dataset5[dataset5>0]
Out[54]:
col1 col2 col3 col5 col6 col7
0 NaN NaN NaN NaN NaN NaN
1 NaN NaN NaN NaN 0.008313 NaN
2 NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN NaN
5 NaN 0.5 NaN NaN NaN NaN
6 NaN NaN NaN NaN NaN NaN
7 NaN NaN NaN NaN NaN NaN
8 NaN NaN NaN NaN NaN NaN
9 NaN NaN NaN NaN 0.006213 NaN
#判断取值是否大于上四分位-1.5倍的四分位间距
dataset6 = dataset2 - statDF.loc['25%-1.5dist']
dataset6[dataset6<0]
Out[55]:
col1 col2 col3 col5 col6 col7
0 NaN NaN NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN -0.298088 NaN
5 NaN NaN NaN NaN NaN NaN
6 NaN NaN NaN NaN NaN NaN
7 NaN NaN NaN NaN NaN NaN
8 NaN NaN NaN NaN NaN NaN
9 NaN NaN NaN NaN NaN NaN
(2)记录数分布检查
主要检查字段的记录数分布是否超出合理的分布范围,包括三个指标:零值记录数、正值记录数、负值记录数。
(3)波动检查
波动检查主要适用于有监督的数据,用于检查随着自变量的变化,因变量是否发生明显的波动情况。
以上异常值的识别方法主要针对连续型字段,而对于离散型字段的异常识别主要通过检查类别出现是否出现了合理阈值外的数据,比如苹果终端型号字段,出现了“P20”的取值。
4.3 异常值的处理
对于统计上的异常值的处理,主要采取两种方式:剔除或者替换。剔除是指直接将被标记为异常值的记录从数据集中删除掉,而替换是指将异常值用一个非异常值进行替换,比如边界值,或者有监督情况下的目标变量表征相似的某个值。
对于业务上的异常值的处理,原则就是进行深入探索分析,查找出现这一特殊情况的根本原因。
##5.参考与感谢 [1] [Python数据分析与数据化运营](https://book.douban.com/subject/27608466/) [2] [Python数据分析与数据挖掘实战](https://book.douban.com/subject/26677686/)