CIFAR简介:
CIFAR是由Hinton的学生Alex Krizhevsky和Ilya Sutskever整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机(airplane)、汽车(automobile)、鸟类(bird)、猫(cat)、鹿(deer)、狗(dog)、蛙类(frog)、马(horse)、船(ship)和卡车(truck)。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练图片和 10000 张测试图片。既然用到了这个数据集,那么在编写的时候肯定要弄清楚里面到底是什么样子的,因此在实现CNN处理之前,先来可视化一下数据集吧!
先从keras数据库中下载数据集,用到的是下面的代码,下载出来的文件是《cifar-10-batches-py.tar.gz》,正常应该会下载到C:UsersAdministrator.kerasdatasets这里面,可以把下载的那个文件解压一下,就变成了cifar-10-batches-py。
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
而cifar-10-batches-py里面就是数据集了,打开文件夹是一些数据集了,训练集有5个,分别是data_batch_1、2、3、4、5,5个,每个里面有10000个数据,一共50000个,然后test_batch就是测试集了。如下图:
输出图片的时候选择了data_batch_5,选哪个都一样,能看到结果就行
def plt_fifar():
with open('data/cifar-10-batches-py/data_batch_5', 'rb')as f:
datadict = p.load(f, encoding='latin1') #获取一个data_batch
# print(datadict)
batch_label_ = datadict['batch_label']
#print(batch_label) #字典第一个key(batch_label),value为“training batch 5 of 5”
labels_ = datadict['labels'] #字典第二个key(labels),value为[0,1,2,3,...],里面有10000个数据
data_ = datadict['data'] #字典第三个key(data),value为列表,形状为10000*3072,3*32*32=3072
# print(len(data_))
filenames_ = datadict['filenames'] #字典最后一个key,value为每个图片的名字,也就是图片里面的内容,car,...
# print(len(filenames_))
#处理的时候需要把data中的形状转成3*32*32
imgX = data_.reshape(-1, 3, 32, 32)
imgY = np.array(labels_)
# print(imgY)
# print(len(imgY))
for i in range(100): # 值输出10张图片,用来做演示
imgs = imgX[i] #一张图片3*32*32
#print(len(imgs))
img0 = imgs[0] #三层通道的每一层
# print(imgs0.shape) #32*32
img1 = imgs[1] #32*32
img2 = imgs[2] #32*32
#fromarray实现array到image的转换,np.asarray将image 转为 array
i0 = Image.fromarray(img0) # 数据生成image对象
i1 = Image.fromarray(img1)
i2 = Image.fromarray(img2)
img = Image.merge("RGB", (i0, i1, i2))
plt.imshow(img)
plt.show()
#保存
# name = "img" + str(i) + ".png"
# img.save("cifar10_images/" + name, "png") # 文件夹下是RGB融合后的图像
# print("保存完毕.")
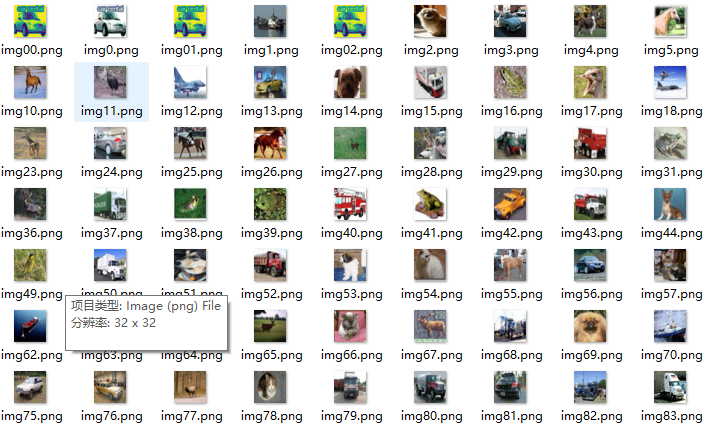
放一些输出的结果图片,只截取了一部分,要是想看其他的可以自己更改参数:
接下来就是搭建CNN实现分类了,开始肯定是要预处理数据集的,见下面的代码:
#x_train shape (50000, 32*32*3),x_test shape (10000, 32*32*3)
#y_train shape (50000,), y_test shape (10000, ) [0-9]
(x_train, y_train), (x_test, y_test) = cifar10.load_data() #如果有导入数据,没有就下载数据
x_train = x_train.astype('float32') / 255 #(50000, 32, 32, 3)
x_test = x_test.astype('float32') / 255 #(10000, 32, 32, 3)
y_train = np_utils.to_categorical(y_train, 10) #(10000, 1)
y_test = np_utils.to_categorical(y_test, 10) #(10000, 1)
搭建以及编译模型:
model = Sequential([ #第一层要写输入尺寸,最后一层要写输出尺寸
#输入(1,32,32,3)输出(32, 32, 32, 3)
Convolution2D(filters=32,
kernel_size=(3, 3),
padding='same',
input_shape=(32, 32, 3),),
Activation('relu'),
#输入(32,32,32,3)输出(64, 32, 32, 3)
Convolution2D(filters=32,
kernel_size=(3, 3),
padding='same',),
Activation('relu'),
#input (64,32,32,3) #output(64,16,16,3)
MaxPooling2D(pool_size=(2, 2)),
Dropout(0.25),
#input(32,16,16,3) output(64,16,16,3)
Convolution2D(filters=64,
kernel_size = (3, 3),
padding = 'same'),
Activation('relu'),
#input(32,16,16,3) output(64,16,16,3)
Convolution2D(filters=64,
kernel_size = (3, 3),
padding = 'same'),
Activation('relu'),
#input(64,16,16,3),output(128,8,8,3)
MaxPooling2D(pool_size = (2,2)),
Dropout(0.25),
Flatten(), #将数据展平 64*64*3 = 8452
Dense(512),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
print(model.summary()) #输出模型结构
#优化器
opti =keras.optimizers.rmsprop(lr=0.001, decay=1e-6)
model.compile(loss='categorical_crossentropy', optimizer=opti, metrics=['accuracy'])
训练以及测试,因为数据集比较大,因此训练轮数要比较多,这里设置成32了,有的是64,但是我看着后来结果差距不是很大,就减少了一半:
#训练
print("----------------train------")
hist = model.fit(x_train, y_train, batch_size=100, epochs=32, shuffle=True, validation_data=(x_test, y_test))
# plot_model(hist, to_file='model_CIFAR10_CNN.png', show_shapes=True) #这一步其实是将模型输出成一张包含有向图的图片,但是我这里没成功,就给注释了,改用model.summary方法(上面有)
#测试
print("----------------test------")
loss, accuracy = model.evaluate(x_test, y_test)
print(loss, accuracy)
然后绘制一下训练过程中训练集和测试集的准确率曲线以及损失值曲线:
# 绘制训练过程中训练集和测试集合的准确率值
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy') #设置y坐标名称
plt.xlabel('Epoch') #设置x坐标名称
plt.legend(['Train', 'Test'], loc = 'upper left') #这个是设置用于区别的小线段,位置是左上角
plt.show()
# 绘制训练过程中训练集和测试集合的损失值
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
下面这一张图是训练过程准确率的曲线图,由于损失值的曲线图片没保存,就没上传了。
