之前记录过利用knn实现手写体识别。现在记录一下利用贝叶斯算法实现,训练数据和测试数据和knn的一样。
首先了解贝叶斯理论知识。
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
那么既然是朴素贝叶斯分类算法,它的核心算法又是什么呢?
是下面这个贝叶斯公式:
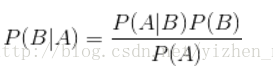
换个表达形式就会明朗很多,如下:

我们最终求的p(类别|特征)即可!就相当于完成了我们的任务。
- 训练数据(求P(类别))
class Bayes:
def __init__(self):
self.length=-1
self.labelrate=dict()
self.vectorrate=dict()
def fit(self,dataset:list,labels:list):
if len(dataset)!=len(labels):
raise ValueError("输入测试数组和类别数组长度不一致")
self.length=len(dataset[0])#训练数据特征值的长度
labelsnum=len(labels) #类别的数量
norlabels=set(labels) #不重复类别的数量
for item in norlabels:
self.labelrate[item]=labels.count(item)/labelsnum #求当前类别占总类别的比例
for vector,label in zip(dataset,labels):
if label not in self.vectorrate:
self.vectorrate[label]=[]
self.vectorrate[label].append(vector)
print("训练结束")
return self- 测试数据(求P(特征|类别)/P(特征))
def btest(self,testdata,labelset):
if self.length==-1:
raise ValueError("未开始训练,先训练")
#计算testdata分别为各个类别的概率
lbDict=dict()
for thislb in labelset:
p = 1
alllabel = self.labelrate[thislb]
allvector = self.vectorrate[thislb]
vnum=len(allvector)
allvector=npy.array(allvector).T
for index in range(0,len(testdata)):
vector=list(allvector[index])
p*=vector.count(testdata[index])/vnum
lbDict[thislb]=p * alllabel
thislbabel=sorted(lbDict,key=lambda x:lbDict[x],reverse=True)[0]
return thislbabel将测试数据计算的P(类别|特征)进行排序,(每一个lbDict字典内容是测试数据0~9标签与训练数据标签0~9所对应的概率)
{0: 3.1868338646386474e-110, 1: 0.0, 2: 0.0, 3: 0.0, 4: 1.6477211419058441e-296, 5: 2.955403551519686e-240, 6: 0.0, 7: 0.0, 8: 6.040460506986624e-226, 9: 6.948609891826844e-210}比如标签0,结果贝叶斯公式得到满足0的特征值且类别为0的概率为3.1868338646386474e-110,依此论推。
- 加载数据和取label值在之前knn中写到过,因为训练数据和测试数据一样,所以可以直接使用之前的方法。
- 实现识别及大概计算出错率:
labelsall=[0,1,2,3,4,5,6,7,8,9]
#识别多个手写体数字(批量处理)
testfile=os.listdir("............/testdata")
num=len(testfile)
x=0
for i in range(num):
thisfilename=testfile[i]
thislabel=seplabel(thisfilename)
thisdataarr=datatoarray(".....testdata/"+thisfilename)
label=bys.btest(thisdataarr,labelsall)
print("测试数字是:"+str(thislabel)+"识别出来的数字是:"+str(label))
if label!=thislabel:
x+=1
print("识别出错")
print(x)
print("出错率:"+str(x/num))效果图:


最后附上手写体训练测试数据及贝叶斯py代码下载地址https://download.csdn.net/download/nonoroya_zoro/10463524,可用于学习实践。
github免费下载:https://github.com/HeCCXX/CSDNDownloading/raw/main/%E6%89%8B%E5%86%99%E4%BD%93%E6%95%B0%E5%AD%97%E8%AF%86%E5%88%AB%E6%95%B0%E6%8D%AE%E5%92%8C%E8%B4%9D%E5%8F%B6%E6%96%AF%E4%BB%A3%E7%A0%81%E5%AE%9E%E7%8E%B0.zip