第一章:oracle的优化器
一、什么是oracle里的优化器?
1.优化器:优化器时Oracle数据库中内置的一个核心子系统。
2.分类:oracle数据库中优化器分为RBO和CBO,(Rule-Based-Optimizer)基于规则的优化器,(Cost-Based-Optimizer)基于成本的优化器
3.RBO等级从低到高分为1~15等级,1的执行效率最高,15等级最低,RBO内置的等级1所对应的执行路径为single row by rowid ,等级15则对应的执行路径为full table scan(全表扫描)。
4.CBO与RBO相比,有明显缺陷,在使用RBO情况下,执行计划一旦出现问题,很难对其做调整,还有就是,SQL的写法,甚至时目标SQL中涉及的各个对象在该SQL文本中的先后顺序,都可能会影响RBO对于该SQL执行计划的选择,还有,oracle数据库中有好多很好的特性,都不被RBO支持。

5.调整RBO,改变执行计划,比如where条件中,对NUMBER或者DATE类型的列加0,varchar2或者char类型加一个空格符,例如'||',如果遇到同等级的SQL时,RBO会根据目标SQL中所涉及的相关对象在数据字典缓存中的缓存顺序和目标SQL中涉及的各个对象在目标SQL文本中出现的先后顺序来综合判断,意味着我们可以通过调整相关对象在数据字典缓存中缓存顺序,改变SQL中涉及的各个对象在SQL文本中出现的先后顺序来调整其执行计划。
6.执行sql
create index idx_mgr_temp on emp_temp(mgr);
create index idx_deptno_temp on emp_temp(deptno);
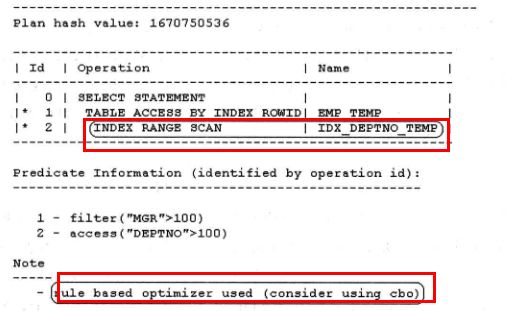
select * from emp_temp where mgr > 100 and deptno > 100 ;
从下图可以看出走的索引是idx_deptno_temp,走的规则是RBO。
如果我们发现走idx_deptno_temp索引效率没有idx_mgr_temp高,我们可以改变执行SQL语句
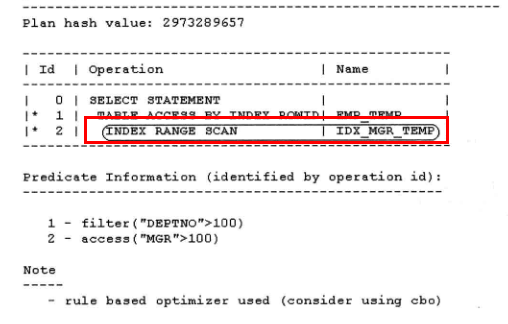
select * from emp_temp where mgr > 100 and deptno+0 > 100 ;
由下图可知,索引已经走的是idx_mgr_temp。

我们之前先创建的是idx_mgr_temp,然后创建的是idx_deptno_temp,则数据字典缓存的顺序是idx_mgr_temp,然后是idx_deptno_temp,这种情况下,RBO走的是idx_deptno_temp,删除索引idx_mgr_temp,重新在创建索引idx_mgr_temp,此时,数据缓存字典变成idx_deptno_temp,然后idx_mgr_temp,此时执行SQL,则可以发现走的索引变成了idx_mgr_temp,说明当两个同等级的执行选择,可以通过改变数据字典的缓存顺序来改变RBO对于其计划的选择。
select * from emp_temp where mgr > 100 and deptno > 100 ;
之前提到,我们还可以通过改变SQL中涉及的各个对象在该SQL文本中出现的顺序来调整目标SQL的执行计划,这通常适用于目标sql中出现多表关联的情形,在目标sql中出现执行路径相同的等级值时,RBO会按照从右到左的顺序决定谁是驱动表,谁是被驱动表,进而选择执行计划。
执行sql:
select t1.mgr ,t2.deptno from emp_temp t1, emp_temp1 t2 where t1.empno = t2.empno;
前提:表emp_temp和emp_temp1唯一的表连接条件为t1.empno = t2.empno,在表emp_temp和emp_temp1的字段empno上均没有任何索引
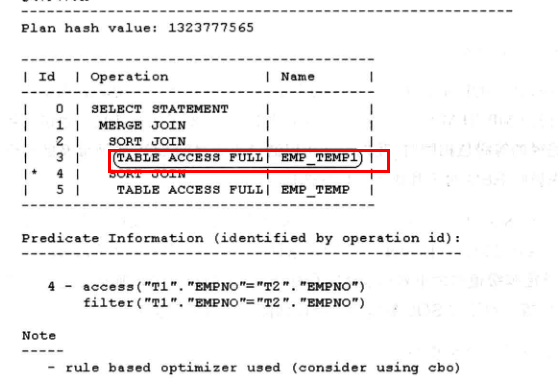
此时,RBO会选择emp_temp1为驱动表,更换位置,则驱动表变成了emp_temp
select t1.mgr,t2.deptno from emp_temp1 t2,emp_temp t1 where t1.empno = t2.empno;
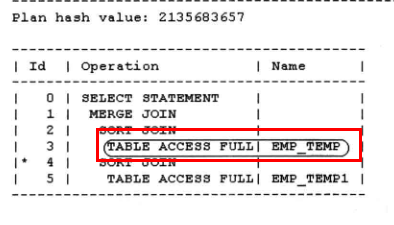
如果RBO仅凭各条执行路径等级值的大小选择目标SQL的执行计划,那么无论如何调整相关对象在该SQL的SQL文本中的位置,对于该SQL最终的执行计划都不会有影响。
执行sql:
前提:表emp与表emp_temp唯一的表连接条件为t1.empno=t2.empno,对于表emp而言,列empno中存在主键索引,对于表emp_temp而言,列empno不存在任何索引。
select * from emp t1, emp_temp t2 where t1.empno=t2.empno
此时驱动表是emp_temp

改变目标sql中对象的位置
select * from emp_temp t2, emp t1 where t1.empno=t2.empno
此时驱动表并不会改变。
7.基于成本的优化器
RBO是有明显区别的,RBO最大的问题在于它是靠硬编码在oracle数据库代码的一系列固定的规则来决定目标SQL的执行计划,而没有考虑目标SQL所涉及的对象的实际数据量,实际数据分布等情况,这样一旦固定的规则并不适用于该sql中所涉及的实际对象时,RBO选择的执行计划就不是最优的选择。
执行sql:
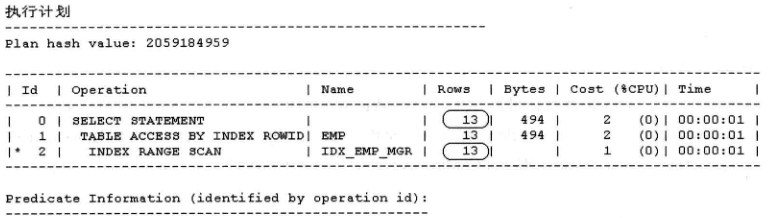
select * from emp where mgr = 7902;
假设在表emp的列mgr上事先存在一个名为idx_emp_mgr的单键值B树索引(BTREE),如果我们使用RBO,则不管表EMP的数据量有多大,也不管MGR的数据分布情况如何,它都会始终走索引,对于RBO而言,全表扫描的等级值要高于索引范围扫描的等级值。RBO这种选择在表EMP的数据量不大,或者虽然表emp的数据量很大,但满足mgr=7902的记录很小时是没有问题的,但是当emp表的数据量很大,有1000万条,且1000万条数据都满足mgr=7902,此时RBO还是会选择走索引扫描,因为这相当于单块读顺序扫描所有的1000万行索引,然后在回表1000万次,这显然没有使用多块读以全表扫描方式直接扫描emp的执行效率高。
为了解决RBO的一些缺陷,oracle7开始,引入了CBO,CBO在选择目标SQL的执行计算时,判断原则是成本,CBO会从目标SQL诸多可能的执行路径中选择一条成本最小的执行路径作为其执行计划,各条执行的成本值是根据目标SQL语句涉及的表,索引,列相关对象的统计信息计算出来的。统计信息是这样的一组数据,他们存储在oracle数据库的数据字典里,且从多个维度描述了oracle数据库相关对象的实际量,实际数据分布等详细信息。

8.Cardinality概念
它是指定集合所包含的记录数,其实就是数据查询出来的结果集的行数,他的值越大,对应的成本越高,这个执行路径的总成本值越大。
9.selectvity概念
它是指施加指定谓词条件后返回结果集的记录数占未施加任何谓词条件的原始结果级的记录数的比率。

例子:
执行sql
alter tabel emp_modify(mgr not null)
create index idx_emp_mgr on mgr(mgr)
A=select count(*) from emp ;

B=select count(distinct mgr) from emp ;

从上图可知,selectivity为1/B,则为1/13
computer Cardinality = original Cardinality * selectivity,即A*selectivity ,为13*1/13=1
执行sql语句:
update emp set mgr = 7902;
A=select count(*) from emp ;
B=select count(distinct mgr) from emp ;
由于将所有的mgr改成了7902,则统计起来会变成1,
此时,计算selectivity为1/B,则为1/1 ===》 1
computer Cardinality = original Cardinality * selectivity,即A*selectivity ,为13*1=13
假设现在有1000万条数据,那么计算的值则变成
computer Cardinality = original Cardinality * selectivity,即A*selectivity ,为1000万*1=1000万
由此可看成本非常大,如果CBO的话,此时就不会走索引,因为这条执行计划成本很大,如果是RBO,由于全表扫描等级会比索引扫描高,此时他还是会走索引扫描,成本大。
10.可传递性
它是指CBO可能对原目标SQL做简单的等价改写,即在原目标的SQL中根据该SQL现有的谓词条件推算出新的谓词条件,这样做的目的是提供更多的执行路径给CBO做选择,进而增加得到高效执行计算的可能性,利用可传递性对目标SQL做简单的等价改写仅仅适用于CBO,RBO不会做这样的事情。

执行sql语句
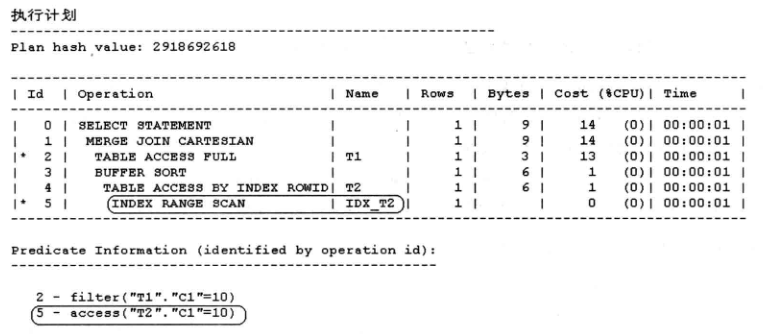
create index idx_t2 on t2(c1);
select * from t1.c1,t2.c2 from t1,t2 where t1.c1 = t2.c2 and t1.c1 = 10 ;
我们并未对表t2的列c1做简单的谓词条件,正常应该不能走t2的列c1上键的索引idx_t2,但是实际上已经走了t2表的索引。
11.CBO的局限性


