论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
本文提出的模型叫MobileNet,主要用于移动和嵌入式视觉应用。该模型具有小巧、低延迟的特点。MobileNet在广泛的应用场景中具有有效性,包括物体检测,细粒度分类,人脸属性和大规模地理定位。

MobileNet架构
深度可分解卷积(Depthwise Separable Convolution)
MobileNet模型基于深度可分解卷积(depthwise separable convolutions),它由分解后的卷积组成,分解后的卷积就是将标准卷积分解成一个深度卷积(depthwise convolution)和一个1x1的点卷积(pointwise convolution)。深度卷积将每个卷积核应用于输入的每一个通道;然后,深度卷积的输出作为点卷积的输入,点卷积用1x1卷积来组合这些输入。下面两个图如下:

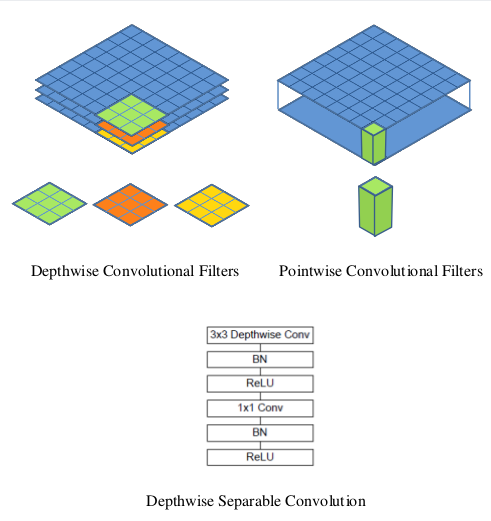
一个标准的卷积层以DF x DF x M大小的feature map F作为输入,然后输出一个DG x DG x N的feature G,其中DF输入feature map的宽度和高度,M是输入通道数目;DG是输出feature map的宽度和高度,N是输出通道的个数。卷积核K的参数量为DK x DK x M x N,其中,DK是卷积核的宽度和高度。标准的卷积的计算代价是(stride=1,padding=same):
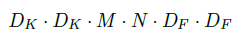
现在将卷积核进行分解,深度卷积的计算量为:
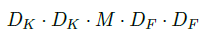
点卷积的计算量为(公式中省略了1 x 1,即完整的表达式为1 * 1 * M * N * DF * DF):
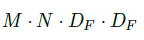
因此,深度可分解卷积的计算总量为:

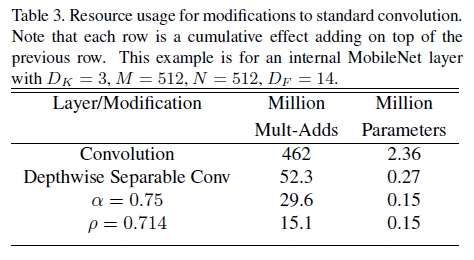
深度可分解卷积与标准卷积的计算量做比较,如下:
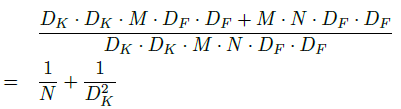
MobileNet使用了大量的3 × 3的深度可分解卷积核,极大地减少了计算量(1/8到1/9之间),同时准确率下降的很少,相比其他的方法确有优势。
Network Structure and Training
MobileNet结构如下图。其中,第一层采用标准卷积,其它层均采用本文提出的深度可分解卷积。每一层后面跟着一个batchnorm和ReLU,除了最后一层全连接层直接接softmax。下采样是采用带stride的卷积实现的。最后,MobileNet总共有28层(深度卷积和点卷积分开计算)。
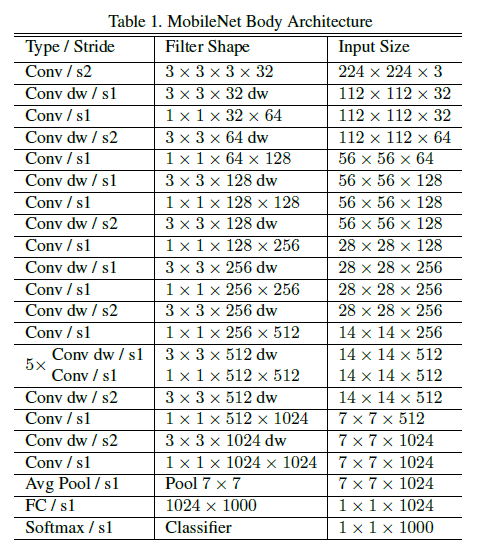
下图对比了标准卷积与深度可分解卷积的结构:

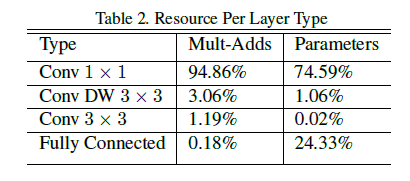
MobileNet将95%的计算时间用于有75%的参数的1×1卷积,作者采用tensorflow和RMSprop进行训练,因为模型比较小,过拟合不太容易,所以数据增强和规则化用的不多。
每一层的计算量如下:
Width Multiplier: Thinner Models
尽管模型已经很小,但是为了让模型更小和更快,本文又提出第一个超参数α,称为宽度乘数(Width Multiplier)。宽度乘数α的作用是使得网络的每一层都“变瘦”。对于一个给定的层和一个宽度乘数α,输入通道M变成αM,输出通道N变成αN。
加上宽度乘数α之后,深度可分解卷积的计算量变为:
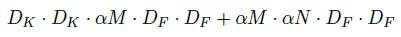
其中,α∈(0,1],典型值是1,0.75,0.5和0.25。α=1是MobileNet的baseline,α<1是reduced MobileNets。宽度乘数在计算量和参数量上大概可以减少α²。
Resolution Multiplier: Reduced Representation
第二个用于减少网络计算量的超参数是分辨率乘数(Resolution Multiplier)ρ。分辨率乘数用来改变输入数据层的分辨率。
在α和ρ共同作用下,我们的深度可分离卷积网络的计算量为:

其中,ρ∈(0,1],ρ 如果为{1,6/7,5/7,4/7},则对应输入分辨率为{224,192,160,128}。ρ 参数的优化空间同样是 ρ² 左右。
下图可以看出两个超参数在减少网络参数的上的作用。
Experiments
Model Choices
表4中,同样是MobileNet的架构,使用可分离卷积,精度值下降1%,而参数仅为1/7。

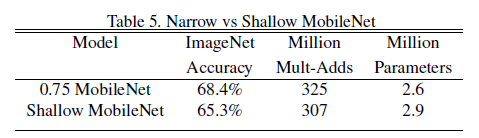
表5中,深且瘦的网络比浅且胖的网络准确率高3%。
Model Shrinking Hyperparameters
表6中,α 超参数减小的时候,模型准确率随着模型的变瘦而下降。
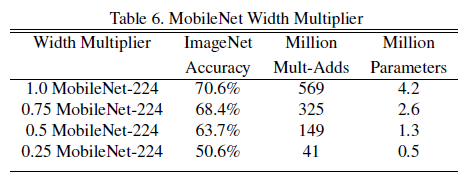
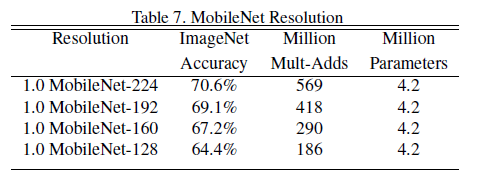
表7中,ρ 超参数减小的时候,模型准确率随着模型的分辨率下降而下降。
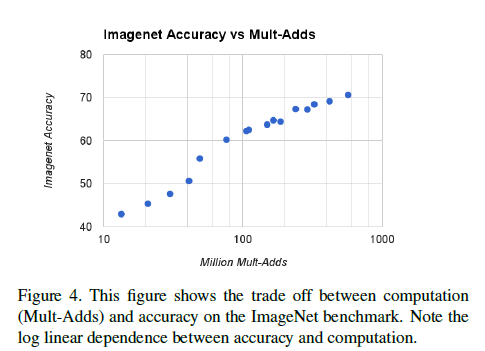
下图显示了准确率和计算量的权衡。总共16个模型,其中α∈{1,0.75,0.5,0.25},ρ∈{224,192,160,128}。
下图是MobileNet与GoogleNet、VGG16的比较。

还有其他很多比较数据,不再详述。
参考:
http://blog.csdn.net/wfei101/article/details/78310226