多线程/并发面试题
现在有线程T1、T2和T3。你如何确保T2线程在T1之后执行,并且T3线程在T2之后执行。
https://www.cnblogs.com/helios-fz/p/11216925.html
Java 中新的Lock接口相对于同步代码块(synchronized block)有什么优势?如果让你实现一个高性能缓存,支持并发读取和单一写入,你如何保证数据完整性。
Lock接口的最大优势是它为读和写提供两个单独的锁(ReentrantReadWriteLock),ReentrantReadWriteLock的特点是:“读读共享”,“读写互斥”,“写写互斥”。(附:Lock取款机示例)
高性能缓存简易示例:
public class ReadWriteMap { private final Map<Object, Object> map; private final ReadWriteLock lock = new ReentrantReadWriteLock(); private final Lock readLock = lock.readLock(); private final Lock writeLock = lock.writeLock(); public ReadWriteMap(Map<Object, Object> map) { this.map = map; } public Object put(Object key, Object value) { try { writeLock.lock(); return map.put(key, value); } finally { writeLock.unlock(); } } public Object get(Object key) { try { readLock.lock(); return map.get(key); } finally { writeLock.unlock(); } } }
Java中wait和sleep方法有什么区别。
sleep() 是Thread类的静态方法,调用此方法会让当前线程暂停执行指定的时间,将执行机会(CPU)让给其他线程,但是对象的锁(或监视器)依然保持。休眠时间结束后线程自动回到就绪状态。
wait() 是Object类的方法,调用此方法会让当前线程暂停执行指定的时间,并放弃对象锁进入等待池(wait pool)。只有调用对象的notify()或notifyAll()方法才能唤醒等待池中的线程进入等锁池(lockpool)。如果线程重新获得对象的锁就可以进入就绪状态。
wait()方法多用于线程间通信,而sleep()只是在执行时暂停。
如何在Java中实现一个阻塞队列。
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作支持阻塞的插入和移除方法。
1)阻塞的插入:当队列满时,队列会阻塞插入元素的线程,直到队列不满。
2)阻塞的移除:当队列空时,队列会阻塞移除元素的线程,直到队列不空。
public class BlockingQueue { private final List<Object> queue = new LinkedList<>(); private int capacity = 10; public BlockingQueue() { } public BlockingQueue(int capacity) { this.capacity = capacity; } public synchronized Object put(Object item) throws InterruptedException { while (queue.size() >= capacity) { wait(); } queue.add(item); notifyAll(); return item; } public synchronized void remove() throws InterruptedException { while (0 == queue.size()) { wait(); } queue.remove(0); notifyAll(); } public synchronized int getSize() { return queue.size(); } }
附:我在实现阻塞队列时遇到的一个问题 https://www.cnblogs.com/helios-fz/p/11721583.html
写一段死锁代码。说说你在Java中如何解决死锁。
https://www.cnblogs.com/helios-fz/p/11663518.html
Java中volatile关键字是什么。你如何使用它。它和Java中的同步方法有什么区别。
https://www.cnblogs.com/helios-fz/p/10935129.html
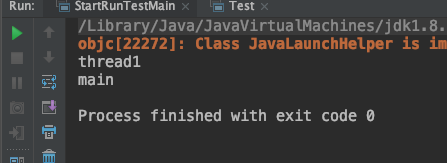
既然start()方法会调用run()方法,为什么我们调用 start() 方法,而不直接调用 run() 方法。
调用start()方法时,它会新建一个线程然后执行run()方法中的代码。
直接调用run()方法,则不会创建新线程,方法中的代码会在当前调用者的线程中执行。验证如下:
public static void main(String[] args) throws InterruptedException { Thread thread1 = new Thread(() -> System.out.println(Thread.currentThread().getName())); Thread thread2 = new Thread(() -> System.out.println(Thread.currentThread().getName())); thread1.setName("thread1"); thread1.start(); Thread.sleep(1000); thread2.setName("thread2"); thread2.run(); }
什么是线程调度,Java中使用了什么线程调度方法。
线程调度是指系统为线程分配处理器使用权的过程,主要调度方式分两种,分别是协同式线程调度和抢占式线程调度。
- 协同式调度。线程执行时间由线程本身来控制,线程把自己的工作执行完之后,要主动通知系统切换到另外一个线程上。最大好处是实现简单,且切换操作对线程自己是可知的,没啥线程同步问题。坏处是线程执行时间不可控制,如果一个线程有问题,可能一直阻塞在那里。
- 抢占式调度。每个线程将由系统来分配执行时间,线程的切换不由线程本身来决定(Java中,Thread.yield()可以让出执行时间,但无法获取执行时间)。线程执行时间系统可控,也不会有一个线程导致整个进程阻塞。
Java线程调度就是抢占式调度。
Java实现多线程的方式。
1)继承Thread类:看jdk源码可以发现,Thread类其实是实现了Runnable接口的一个实例,继承Thread类后需要重写run方法并通过start方法启动线程。继承Thread类耦合性太强了,因为Java只能单继承,所以不利于扩展。
2)实现Runnable接口:通过实现Runnable接口并重写run方法,并把Runnable实例传给Thread对象,Thread的start方法调用run方法再通过调用Runnable实例的run方法启动线程。所以如果一个类继承了另外一个父类,此时要实现多线程就不能通过继承Thread的类实现。
3)实现Callable接口:通过实现Callable接口并重写call方法,并把Callable实例传给FutureTask对象,再把FutureTask对象传给Thread对象。它与Thread、Runnable最大的不同是Callable能返回一个异步处理的结果Future对象并能抛出异常,而其他两种不能。
Runnable接口和Callable接口的区别。
Runnable接口中的run()方法的返回值是void,它只是纯粹地去执行run()方法中的代码而已。
Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。
多线程有什么作用。
1)发挥多核CPU的优势
如果是单线程的程序,那么在双核CPU上就浪费了50%,在4核CPU上就浪费了75%。单核CPU上的"多线程"是假的多线程,同一时间处理器只会处理一段逻辑,只不过线程之间切换得比较快,看着像多个线程"同时"运行罢了。多核CPU上的多线程才是真正的多线程,它能让你的多段逻辑同时工作,多线程,可以真正发挥出多核CPU的优势来,达到充分利用CPU的目的。
2)防止阻塞
从程序运行效率的角度来看,单核CPU不但不会发挥出多线程的优势,反而会因为在单核CPU上运行多线程导致线程上下文的切换,而降低程序整体的效率。但是单核CPU我们还是要应用多线程,就是为了防止阻塞。试想,如果单核CPU使用单线程,那么只要这个线程阻塞了,比方说远程读取某个数据,对端迟迟未返回又没有设置超时时间,那么整个程序在数据返回来之前就停止运行了。多线程可以防止这个问题,多条线程同时运行,哪怕一条线程的代码执行读取数据阻塞,也不会影响其它任务的执行。
3)便于建模
这是另外一个没有这么明显的优点了。假设有一个大的任务A,单线程编程,那么就要考虑很多,建立整个程序模型比较麻烦。但是如果把这个大的任务A分解成几个小任务,任务B、任务C、任务D,分别建立程序模型,并通过多线程分别运行这几个任务,那就简单很多了。
CyclicBarrier和CountDownLatch的区别
两个看上去有点像的类,都在java.util.concurrent下,都可以用来表示代码运行到某个点上,二者的区别在于:
1)CyclicBarrier的某个线程运行到某个点上之后,该线程即停止运行,直到所有的线程都到达了这个点,所有线程才重新运行;CountDownLatch则不是,某线程运行到某个点上之后,只是给某个数值-1而已,该线程继续运行。
2)CyclicBarrier只能唤起一个任务,CountDownLatch可以唤起多个任务。
3) CyclicBarrier可重用,CountDownLatch不可重用,计数值为0该CountDownLatch就不可再用了。
什么是线程安全。
如果你的代码在多线程下执行和在单线程下执行永远都能获得一样的结果,那么你的代码就是线程安全的。
这个问题有值得一提的地方,就是线程安全也是有几个级别的:
1)不可变
像String、Integer、Long这些,都是final类型的类,任何一个线程都改变不了它们的值,要改变除非新创建一个,因此这些不可变对象不需要任何同步手段就可以直接在多线程环境下使用。
2)绝对线程安全
不管运行时环境如何,调用者都不需要额外的同步措施。要做到这一点通常需要付出许多额外的代价,Java中标注自己是线程安全的类,实际上绝大多数都不是线程安全的,不过绝对线程安全的类,Java中也有,比方说CopyOnWriteArrayList、CopyOnWriteArraySet。
3)相对线程安全
相对线程安全也就是我们通常意义上所说的线程安全,像Vector这种,add、remove方法都是原子操作,不会被打断,但也仅限于此,如果有个线程在遍历某个Vector、有个线程同时在add这个Vector,99%的情况下都会出现ConcurrentModificationException,也就是fail-fast机制。
4)线程非安全
这个就没什么好说的了,ArrayList、LinkedList、HashMap等都是线程非安全的类。
Java如何获取线程的dump文件。
死循环、死锁、阻塞、页面打开慢等问题,打线程dump是最好的解决问题的途径。所谓线程dump也就是线程堆栈,获取到线程堆栈有两步:
1)获取到线程的pid,可以通过使用jps命令,在Linux环境下还可以使用ps -ef | grep java
2)打印线程堆栈,可以通过使用jstack pid命令,在Linux环境下还可以使用kill -3 pid
另外提一点,Thread类提供了一个getStackTrace()方法也可以用于获取线程堆栈。这是一个实例方法,因此此方法是和具体线程实例绑定的,每次获取获取到的是具体某个线程当前运行的堆栈。
一个线程如果出现了运行时异常会怎么样。
如果这个异常没有被捕获的话,这个线程就停止执行了。另外重要的一点是:如果这个线程持有某个对象的监视器,那么这个对象监视器会被立即释放。
如何在两个线程之间共享数据。
通过在线程之间共享对象就可以了,然后通过wait/notify/notifyAll、await/signal/signalAll进行唤起和等待,比方说阻塞队列BlockingQueue就是为线程之间共享数据而设计的。
生产者消费者模型的作用是什么。
1)通过平衡生产者的生产能力和消费者的消费能力来提升整个系统的运行效率,这是生产者消费者模型最重要的作用。
2)解耦,这是生产者消费者模型附带的作用,解耦意味着生产者和消费者之间的联系少,联系越少越可以独自发展而不需要收到相互的制约。