https://arxiv.org/pdf/2003.00392.pdf
https://blog.csdn.net/qq_43310834/article/details/108384293
https://github.com/cshizhe/hgr_v2t
工作领域
视频与文本的跨模式检索。
传统的检索方法主要是基于关键字搜索,其中关键字预先定义并自动或手动分配给视频。然而,由于关键词是有限的和非结构化的,检索各种不同的内容是困难的,例如,在基于关键词的视频检索系统中,准确检索主题为“白狗”追逐对象为“黑猫”的视频几乎是不可能的。为了解决基于关键词的视频检索方法的局限性,越来越多的研究者开始关注使用自然语言文本进行视频检索,这种文本比关键词(也称为跨模式视频文本检索)包含更丰富、更结构化的细节。
已有工作
目前解决这个问题的主要方法是学习一个联合嵌入空间来测量跨模态相似性。
The current dominant approach for this problem is to learn a joint embedding space to measure cross-modal similarities.
然而,简单的联合嵌入不足以表示复杂的视觉和文本细节。
However, simple joint embeddings are insufficient to represent complicated visual and textual details, such as scenes, objects, actions and their compositions.
本文工作
- 本文提出了一个层次图推理(HGR)模型,将视频文本匹配分解为全局到局部的层次。它通过详细的语义改进了全局匹配,通过全局事件结构改进了局部匹配,从而实现了细粒度的视频文本检索。
- 文本中的三个分离层次,如事件、动作和实体,通过基于注意力的图形推理相互作用,并与相应的视频层次对齐。所有级别都有助于视频文本匹配,以实现更好的语义覆盖。
- HGR模型在不同的视频文本数据集上实现了更好的性能,在不可见数据集上实现了更好的泛化能力。本文还提出了一种新的二进制选择任务,用以证明区分细粒度语义差异的能力。
为了改进细粒度视频文本检索,提出了一种层次图推理(HGR)模型,将视频文本匹配分解为全局到局部的层次。具体来说,该模型将文本分解为层次语义图,包括事件、动作、实体和跨层次关系的三个层次。利用基于注意的图形推理生成层次化的文本嵌入,可以指导不同层次视频表示的学习。HGR模型聚合来自不同视频文本级别的匹配,以捕获全局和本地详细信息。
本文将视频文本匹配分解为三个层次语义层,分别负责捕获全局事件、局部动作和实体。在文本方面:全局事件由整个句子表示,动作用动词表示,实体指名词短语。不同的层次不是独立的,它们之间的相互作用解释了它们在事件中扮演的语义角色。下图展示了这种匹配的机制:
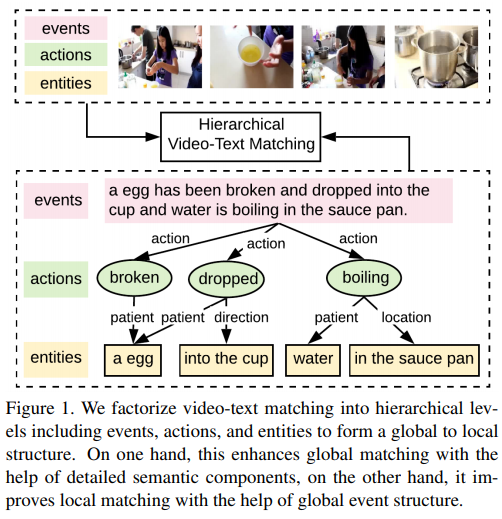
拟议的HGR模型的概述,该模型由三个模块组成:
1) 分层文本编码(第3.1节),从文本中构造语义角色图,并应用图形推理获得分层文本表示;
2) 分层视频编码(第3.2节)将视频映射到相应的多级表示;
3)视频文本匹配(第3.3节),该视频文本匹配在不同的级别上聚合全局和局部匹配,以计算整体的跨模态相似性。
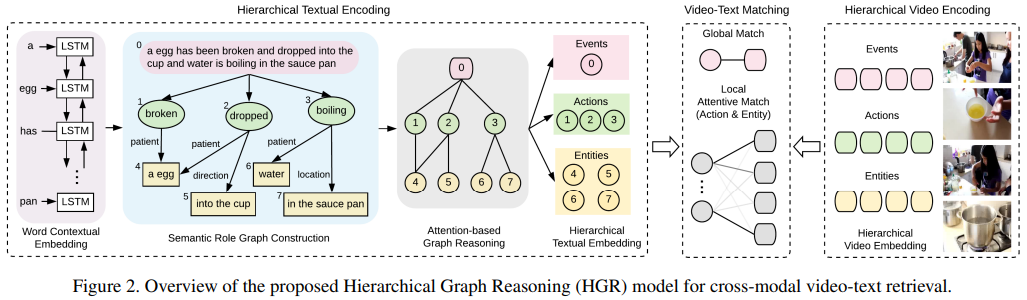
1、Hierarchical Textual Encoding(分层文本编码)
视频描述自然包含层次结构(Video descriptions naturally contain hierarchical structures),整句做事件节点(global event node),动词做动作节点(action node),名词组做实体节点(entity node)。动作和事件节点直接相连,隐含了动作的时序信息(The verbs are considered as action nodes and connected to event node with direct edges, so that temporal relations of different actions can be implicitly learned from event node in following graph reasoning.)。动作和实体之间的边蕴含了实体是施加还是承受动作的实体(The edge type between action and entity nodes is decided by the semantic role of the entity in reference to the action. If an entity node servers multiple semantic roles to different action nodes, we duplicate the entity node for each semantic role.)

描述一下这个过程,输入即为整个网络的初始输入一段text(当然这里是word embedding),将这一段text作为图event,然后再用一个语义角色分析工具提取这段text里的动词和名词,将动词分别作为event节点的子节点,将有关联性的名词节点作为关联的动词的子节点。
Initial Graph Node Representation
将每个节点的语义嵌入到稠密向量中作为初始化。
对于整句:
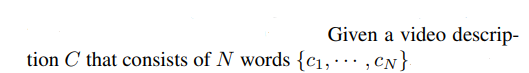


这里的ge就是每个语义节点的embedding,对于动作和实体节点,直接在整句的某些t(动作、实体)上做了最大池化:

Attention-based Graph Reasoning
在构造的图中,不同层次的连接不仅解释了局部节点如何构成全局事件,而且能够减少每个节点的模糊性。作者的例子说破的egg和完好的egg视觉上是不同的,而break和egg的连接对应了视觉上的破蛋。对图中的交互进行推理,以获得分层的文本表示。由于每条边所代表的语义信息不同,会极大程度地影响权重,
这一部分依赖GCN进行。
2、Hierarchical Video Encoding

直接将视频分解成层次结构是一个挑战,因为文本需要时间分割、目标检测、跟踪等(which requires temporal segmentation, object detection, tracking and so on.)。因此,我们构建了三个独立的视频嵌入来关注视频中不同层次的方面(We thus instead build three independent video embeddings to focus on different level of aspects in the video.)。
逐帧抽取向量表示:


3 Video-Text Matching

全局匹配:跨模型余弦相似度
局部匹配:先对齐,再计算
弱监督学习局部注意力匹配,这里v指的是视频得到的序列结果,c是文本得到的序列结果,这里可以理解成为计算每个文本的语义节点和视频的每一帧之间的关系(看这个正则化公式应该是每一文本节点去匹配全部帧),然后norm归一化它一下然后norm归一化它一下

损失函数:

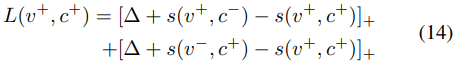
实验对比
表1将提出的HGR模型与MSR-VTT测试集上的SOTA方法进行了比较。为了公平比较,所有的模型都使用相同的视频特性。在MSR-VTT数据集上,我们的模型在不同的评估指标上实现了最佳性能。

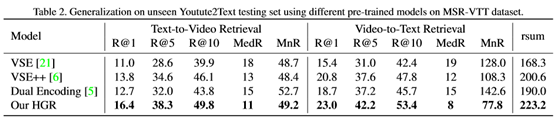
表2显示了Youtube2Text数据集的检索结果。VSE++[6]提出的hard负性训练策略使模型能够更有效地学习视觉语义匹配,提高了模型对未知数据的泛化能力。
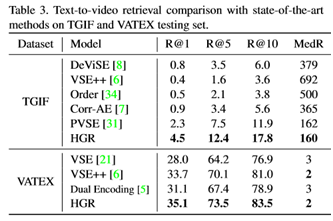
为了证明我们的方法对不同数据集和特性的健壮性,我们在表3中进一步提供了TGIF和VATEX数据集的定量结果。这些模型在TGIF数据集上使用Resnet152图像特征,在VATEX数据集上使用I3D视频特征。
为了研究我们提出的模型中不同成分的贡献,我们对表4中的MSR-VTT数据集进行了消融研究。表4中的第1行取代了图推理中的图注意机制,简单地利用了邻域节点上的平均池,在R@10度量上的检索性能分别比第4行的完整模型在文本到视频和视频到文本检索上降低了0.9和1.7。

在图3中,我们展示了一个学习的模式,在不同层次的图推理中,动作节点如何与邻居节点交互,这与语义角色密切相关。

由于我们的视频文本相似性是从不同的级别聚合的,在表5中,我们对视频文本检索的每个级别的性能进行了分解。我们可以看到,全局事件级别单独在rsum度量上表现最好,因为局部级别本身可能不包含整个事件结构。
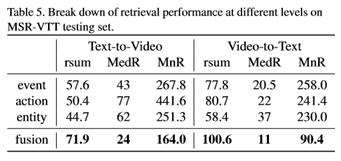
表6显示了不同二进制选择任务的结果。在角色转换任务中,我们的模型优于VSE++模型,绝对值为4.87%,但略低于双编码模型。

大多数成功的跨模式视频文本检索系统都是基于联合嵌入的方法。然而,简单的嵌入不足以捕获复杂视频和文本中的细粒度语义。因此,本文提出了一个层次图推理(HGR)模型,将视频和文本分解为事件、动作和实体等层次语义层。然后通过基于注意力的图形推理生成层次化的文本嵌入,并将文本与不同层次的视频对齐。总体的跨模态匹配是通过聚合来自不同层次的匹配来生成的。在三个视频文本数据集上的实验结果证明了该模型的优越性。提出的HGR模型在不可见数据集上也能获得更好的泛化性能,并且能够区分细粒度的语义差异。

在图5中,我们还提供了视频到文本检索的定性结果,这证明了我们的HGR模型在双向跨模式检索中的有效性。
