match查询会将查询词分词,然后对分词的结果进行term查询。
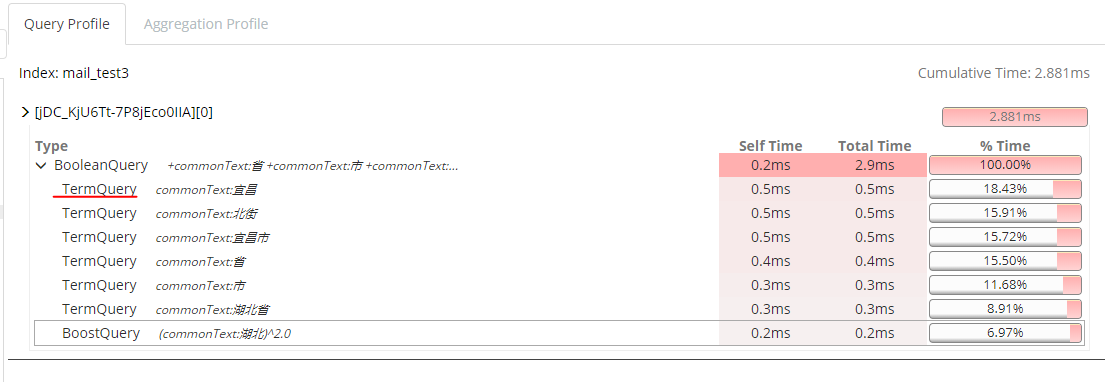
然后默认是将每个分词term查询之后的结果求交集,所以只要分词的结果能够命中,某条数据就可以被查询出来,而分词是在新建索引时指定的,只有text类型的数据才能设置分词策略。
新建索引,并指定分词策略:
PUT mail_test3
{
"settings": {
"index": {
"refresh_interval": "30s",
"number_of_shards": "1",
"number_of_replicas": "0"
}
},
"mappings": {
"default": {
"_all": {
"enabled": false
},
"_source": {
"enabled": true
},
"properties": {
"addressTude": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"copy_to": [
"commonText"
],
"fielddata": true
},
"captureTime": {
"type": "long"
},
"commonText": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fielddata": true
},
"commonNum":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"fielddata": true
},
"imsi": {
"type": "keyword",
"copy_to": ["commonNum"]
},
"uuid": {
"type": "keyword"
}
}
}
}
}
analyzer 指的是在建索引时的分词策略,search_analyzer 指的是在查询时的分词策略。ik分词器还有一种ik_smart 的分词策略,可以比较两种分词策略的差别:
ik_smart分词策略:
GET mail_test3/_analyze
{
"analyzer": "ik_smart",
"text": "湖南省湘潭市江山路96号-11-8"
}
结果:
{
"tokens": [
{
"token": "湖南省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "湘潭市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 1
},
{
"token": "江",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 2
},
{
"token": "山路",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 3
},
{
"token": "96号",
"start_offset": 9,
"end_offset": 12,
"type": "TYPE_CQUAN",
"position": 4
},
{
"token": "11-8",
"start_offset": 13,
"end_offset": 17,
"type": "LETTER",
"position": 5
}
]
}
ik_max_word分词策略:
GET mail_test1/_analyze
{
"analyzer": "ik_max_word",
"text": "湖南省湘潭市江山路96号-11-8"
}
分词结果:
{
"tokens": [
{
"token": "湖南省",
"start_offset": 0,
"end_offset": 3,
"type": "CN_WORD",
"position": 0
},
{
"token": "湖南",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
},
{
"token": "省",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "湘潭市",
"start_offset": 3,
"end_offset": 6,
"type": "CN_WORD",
"position": 3
},
{
"token": "湘潭",
"start_offset": 3,
"end_offset": 5,
"type": "CN_WORD",
"position": 4
},
{
"token": "市",
"start_offset": 5,
"end_offset": 6,
"type": "CN_CHAR",
"position": 5
},
{
"token": "江山",
"start_offset": 6,
"end_offset": 8,
"type": "CN_WORD",
"position": 6
},
{
"token": "山路",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 7
},
{
"token": "96",
"start_offset": 9,
"end_offset": 11,
"type": "ARABIC",
"position": 8
},
{
"token": "号",
"start_offset": 11,
"end_offset": 12,
"type": "COUNT",
"position": 9
},
{
"token": "11-8",
"start_offset": 13,
"end_offset": 17,
"type": "LETTER",
"position": 10
},
{
"token": "11",
"start_offset": 13,
"end_offset": 15,
"type": "ARABIC",
"position": 11
},
{
"token": "8",
"start_offset": 16,
"end_offset": 17,
"type": "ARABIC",
"position": 12
}
]
}
ik_max_word分词器的分词结果更多,分词的粒度更细,而ik_smart的分词结果粒度更粗,但较为智能。一般的策略是建立索引使用ik_max_word,查询时使用ik_smart,这样就能尽可能多的查到结果,而且上文提到,match查询最终是转化为term查询,因此只要某个分词结果命中,结果中就会有该条数据。
如果对搜索结果的精度较高,可以在查询中加入operator参数,然后让分词结果的每个term查询结果之间求交集,这样能尽可能地提高精度。
这里的operator设置为or和and的差别较大,可以测试进行比较:
GET mail_test3/_search
{
"query": {
"match": {
"commonText": {
"query": "湖北省宜昌市天台东二街",
"operator": "and"
}
}
}
}