一、简介
本文从链表的简介开始,介绍了链表的存储结构,并根据其存储结构分析了其存储结构所带来的优缺点,进一步我们通过代码实现了一个输入我们的单向链表。然后通过对递归过程和内存分配的详细讲解让大家对链表的引用和链表反转有一个深入的了解。单向链表实现了两个版本,分别使用循环和递归实现了两个版本的链表,相信大家仔细阅读本文后会对链表和递归有一个深刻的理解。再也不怕面试官让手写链表或者反转链表了。
后面会持续更新数据结构相关的博文。
数据结构专栏:https://www.cnblogs.com/hello-shf/category/1519192.html
git传送门:https://github.com/hello-shf/data-structure.git
二、链表
2.1、链表简介
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
前面文章我们介绍了数组这种数据结构,其最大的优点就是连续的存储空间所带来的随机访问的能力,最大的缺点同样是连续存储空间所造成的的容量的固定即不具备动态性。对于链表刚好相反,其是由物理存储单元上非连续的存储结构,这种结构能真正实现数据结构的动态性,但随之而来的就是丧失了随机访问的优点。正如一句古话-鱼和熊掌不可兼得。数组和链表正是这种互补的关系。
由上面可知,链表最大的优点就在于--动态。
2.2、链表的存储结构
如下图所示,单向链表正是以这种方式存储的。单向链表包含两个域,一个是信息域,一个是指针域。也就是单向链表的节点被分成两部分,一部分是保存或显示关于节点的信息,第二部分存储下一个节点的地址,而最后一个节点则指向一个空值。
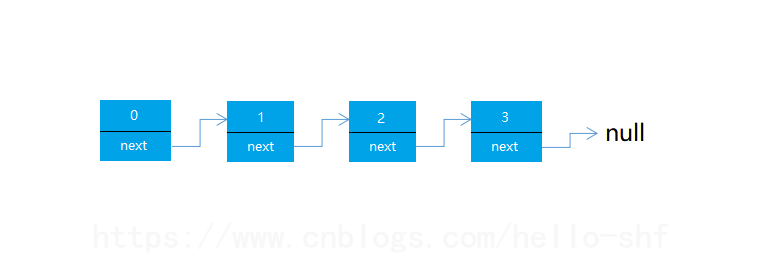
双向链表相对于单向链表,不过就是在指针域中除了指向下一个元素的指针,还存在一个指向上一个元素的指针。
循坏链表相对于单向链表,在最后一个元素的指针域存在一个指向头节点的指针。使之形成一个环。
三、实现一个单向链表
首先,为什么我们要自己实现一个链表?大家在找工作面试的时候,一旦被问到数据结构,手写链表应该都是必备的问题。其次,因为链表具有天然的递归性,链表的学习,有助于我们更深层次的理解递归。同样链表的学习对于我们理解Java中的“引用”有很好的帮助。
对于我们要实现的链表,我们作如下设计
1 以Node作为链表的基础存储结构 2 单向链表 3 使用泛型-增加灵活性 4 基本操作:增删改查等
3.1、链表的底层存储结构
对于链表我们将数据存储在一个node节点中,所以我们要设计一个node。
1 /** 2 * 描述:单向链表实现 3 * 对应 java 集合类 linkedList 4 * 5 * @Author shf 6 * @Date 2019/7/18 16:45 7 * @Version V1.0 8 **/ 9 public class MyLinkedList<E> { 10 /** 11 * 私有的 Node 12 */ 13 private class Node{ 14 public E e; 15 public Node next; 16 17 public Node(E e, Node next){ 18 this.e = e; 19 this.next = next; 20 } 21 public Node(E e){ 22 this(e, null); 23 } 24 public Node(){ 25 this(null, null); 26 } 27 } 28 private Node head; 29 private int size; 30 31 public MyLinkedList(){ 32 head = null; 33 size = 0; 34 } 35 public int getSize(){ 36 return this.size; 37 } 38 public boolean isEmpty(){ 39 return size == 0; 40 } 41 }
如上代码所示,我们通过定义一个私有的Node类,作为我们链表的基础存储结构。并在MyLinkedList中维护一个 head 属性,作为整个链表的头结点。
3.2、添加元素
我们设计这么一个方法,就是在链表的 index 位置 添加元素,我们只需要找到index的前一个元素prev,然后让其next指向我们要添加的节点newNode,然后让newNode的next指向prev的next节点即可。可能看着这段话有点绕。比如在 索引为2的位置添加一个新元素,看下图:
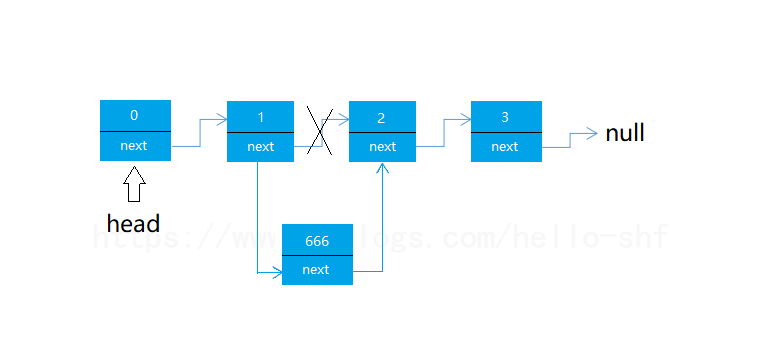
这样我们就将我们的666元素添加到了索引为2的位置。具体代码实现如下所示:
1 /** 2 * 在 index 位置 添加元素 3 * 时间复杂度:O(n) 4 * @param index 5 * @param e 6 */ 7 public void add(int index, E e){ 8 9 if(index < 0 || index > size) 10 throw new IllegalArgumentException("Add failed. Illegal index."); 11 12 if(index == 0) 13 addFirst(e); 14 else{ 15 Node prev = head; 16 for(int i = 0 ; i < index - 1 ; i ++) 17 prev = prev.next; 18 19 // Node node = new Node(e); 20 // node.next = prev.next; 21 // prev.next = node; 22 // 以上三行代码等价于下面这行代码 23 24 prev.next = new Node(e, prev.next); 25 size ++; 26 } 27 } 28 /** 29 * 在链表头 添加元素 30 * 时间复杂度:O(1) 31 * @param e 32 */ 33 public void addFirst(E e){ 34 // Node node = new Node(e); 35 // node.next = head; 36 // head = node; 37 // 以上三行代码等价于下面这行代码 38 39 head = new Node(e, head); 40 size ++; 41 } 42 43 /** 44 * 在链表尾 添加元素 45 * 时间复杂度:O(n) 46 * @param e 47 */ 48 public void addLast(E e){ 49 add(size, e); 50 }
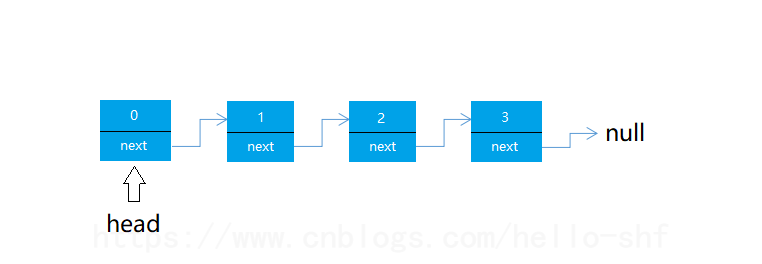
在上面add方法中我们需要判断 index == 0 这种特殊情况。我们可以通过将维护的head改为一个虚假的头节点 dummyHead,来改善我们的代码。这也是构造链表的一般手段。
对于 head 这种情况,链表的存储结构如下图所示:
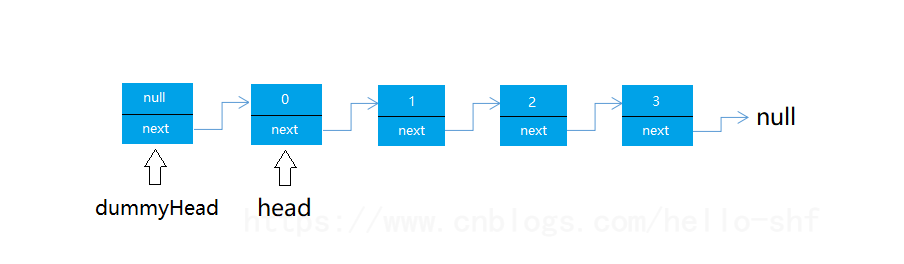
如果我们将 MyLinkedList中维护的 head 变成dummyHead,存储结构如下:
相应的我们的代码将进行简化:
1 private Node dummyHead; 2 private int size; 3 4 public MyLinkedList(){ 5 dummyHead = new Node(); 6 size = 0; 7 } 8 public int getSize(){ 9 return this.size; 10 } 11 public boolean isEmpty(){ 12 return size == 0; 13 } 14 15 /** 16 * 在 index 位置 添加元素 17 * @param index 18 * @param e 19 */ 20 public void add(int index, E e){ 21 if(index < 0 || index > size){ 22 throw new IllegalArgumentException("添加失败,Index 参数不合法"); 23 } 24 Node prev = dummyHead;// TODO 不理解这一行就是没有理解java中引用的含义 25 for(int i=0; i< index; i++){ 26 prev = prev.next; 27 } 28 prev.next = new Node(e, prev.next); 29 size ++; 30 } 31 32 /** 33 * 在链表头 添加元素 34 * 时间复杂度:O(1) 35 * @param e 36 */ 37 public void addFirst(E e){ 38 this.add(0, e); 39 } 40 41 /** 42 * 在链表尾 添加元素 43 * 时间复杂度:O(n) 44 * @param e 45 */ 46 public void addLast(E e){ 47 this.add(size, e); 48 }
我们可以看到,当我们引入了dummyHead,我们的代码更加精练了。后面所有的操作,我们都依据有dummyHead的代码来实现。
3.3、删除
删除和添加其实就差不多了,我们设计一个方法,删除指定索引位置的元素的方法。如下图,我们删除索引为2位置的元素666。

如图所示,我们只需要找到 所以为2的前一个元素prev,然后让其next指向666元素的下一个元素即可。但是别忘了,将666和链表断开连接。
1 /** 2 * 删除链表 index 位置的元素 3 * @param index 4 * @return 5 */ 6 public E remove(int index){ 7 if(index < 0 || index >= size){ 8 throw new IllegalArgumentException("操作失败,Index 参数不合法"); 9 } 10 Node prev = dummyHead; 11 for(int i=0; i< index; i++){ 12 prev = prev.next; 13 } 14 Node rem = prev.next; 15 prev.next = rem.next; 16 rem.next = null;// 看不懂这行就是还没理解链表。将rem断开与链表的联系。 17 size--; 18 return rem.e; 19 } 20 21 /** 22 * 删除 头元素 23 * @return 24 */ 25 public E removeFirst(){ 26 return remove(0); 27 } 28 29 /** 30 * 删除 尾元素 31 * @return 32 */ 33 public E removeLast(){ 34 return remove(size - 1); 35 }
3.4、链表反转
首先,我们在宏观角度分析,链表是有天然递归性的,这个大家都明白,我们想要实现链表反转,无非就是让每个元素的next指向前一个元素即可。看图(加了水印,大家凑活着看吧,作图很辛苦):
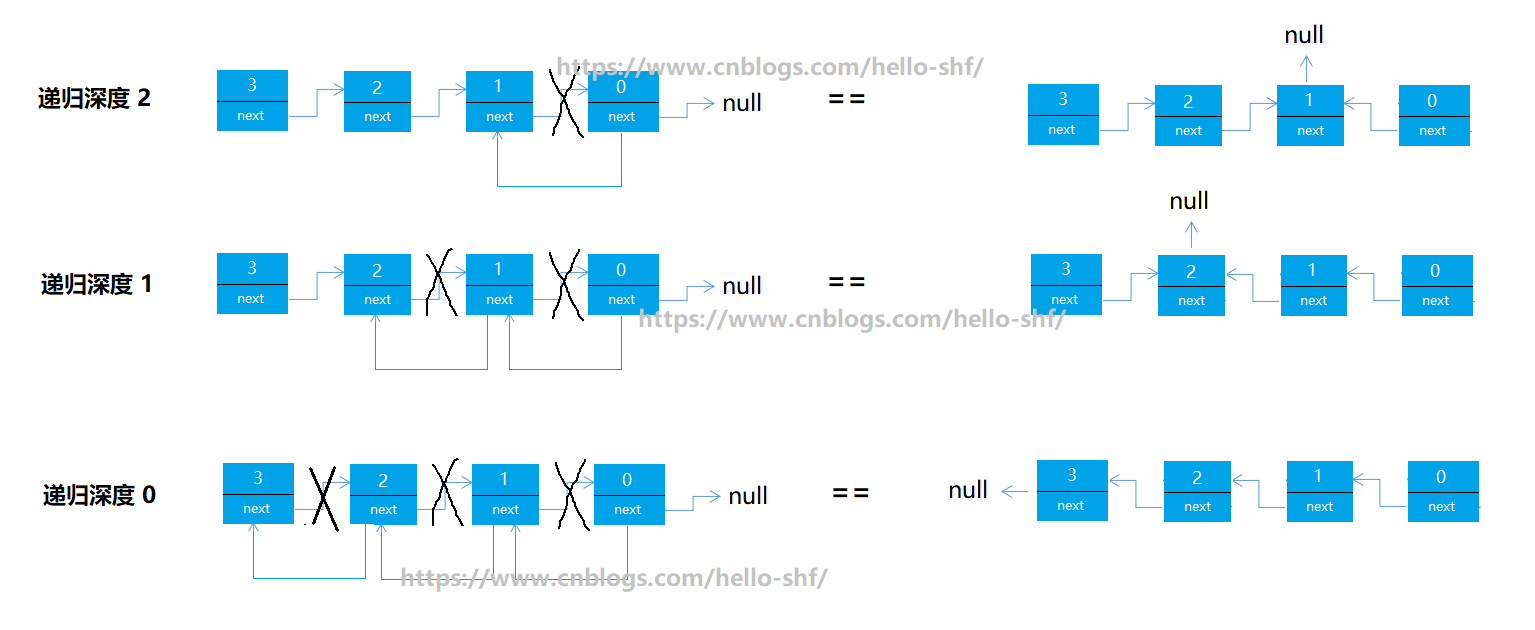
代码先放到这
1 /** 2 * 链表反转 3 */ 4 public void reverseList(){ 5 dummyHead.next = reverseList(dummyHead.next); 6 } 7 8 /** 9 * 链表反转 - 递归实现 10 * @param root 11 * @return 12 */ 13 private Node reverseList(Node root){ 14 if(root.next == null){ 15 return root; 16 } 17 // 先记住 root 的next节点 18 Node temp = root.next; 19 // 递归 root 的next节点,并返回root的节点 20 Node node = reverseList(root.next); 21 // 将 root 节点与链表断开连接 22 root.next = null; 23 // 让我们之前缓存的 root的下一个节点 指向 root节点,这样就实现了链表的反转 24 temp.next = root; 25 return node; 26 }
看到上面代码,估计大家会有点头蒙,并且不知所措,没问题,继续往下看,为了方便描述,我们加一个参数,递归深度。
1 /** 2 * 链表反转 3 */ 4 public void reverseList(){ 5 dummyHead.next = reverseList(dummyHead.next, 0); 6 } 7 /** 8 * 链表反转 - 递归实现 9 * @param root 10 * @return 11 */ 12 private Node reverseList(Node root, int deap){ 13 System.out.println("递归深度==>" + deap); 14 if(root.next == null){ 15 return root; 16 } 17 // 先记住 root 的next节点 18 Node temp = root.next; 19 // 递归 root 的next节点,并返回root的节点 20 Node node = reverseList(root.next, (deap + 1)); 21 // 将 root 节点与链表断开连接 22 root.next = null; 23 // 让我们之前缓存的 root的下一个节点 指向 root节点,这样就实现了链表的反转 24 temp.next = root; 25 return node; 26 }
递归深度==>0
递归深度==>1
递归深度==>2
递归深度==>3
对于上面这几行代码,我们发现,我们对 node 什么都没做,为什么要返回 node 呢?其实呢,node只是一个引用,node始终指向递归深度为 3的时候,返回的root,也就是 0 这个节点。明确这一点我们继续分析。
结合递归深度,先分析一下递归树,如下表所示:
| 递归深度 | 递归树(root的指向) | 递归树(temp的指向) | 递归树(node指向) |
| 0 | 3 | 2 | 0 |
| 1 | 2 | 1 | 0 |
| 2 | 1 | 0 | 0 |
| 3 | 0 |
如果你看上面的递归树对root,temp,node的指向感觉还有点懵,没关系,继续往下看,我们从堆栈的内存分布来说一下各个引用随递归深度的变化。从下图我们不难发现,其实在堆里面始终都是3210四个节点,也就是说,root,temp,node仅仅是堆内存里面这四个节点的引用而已。到这里想必大家应该对引用有了一个直观的理解。
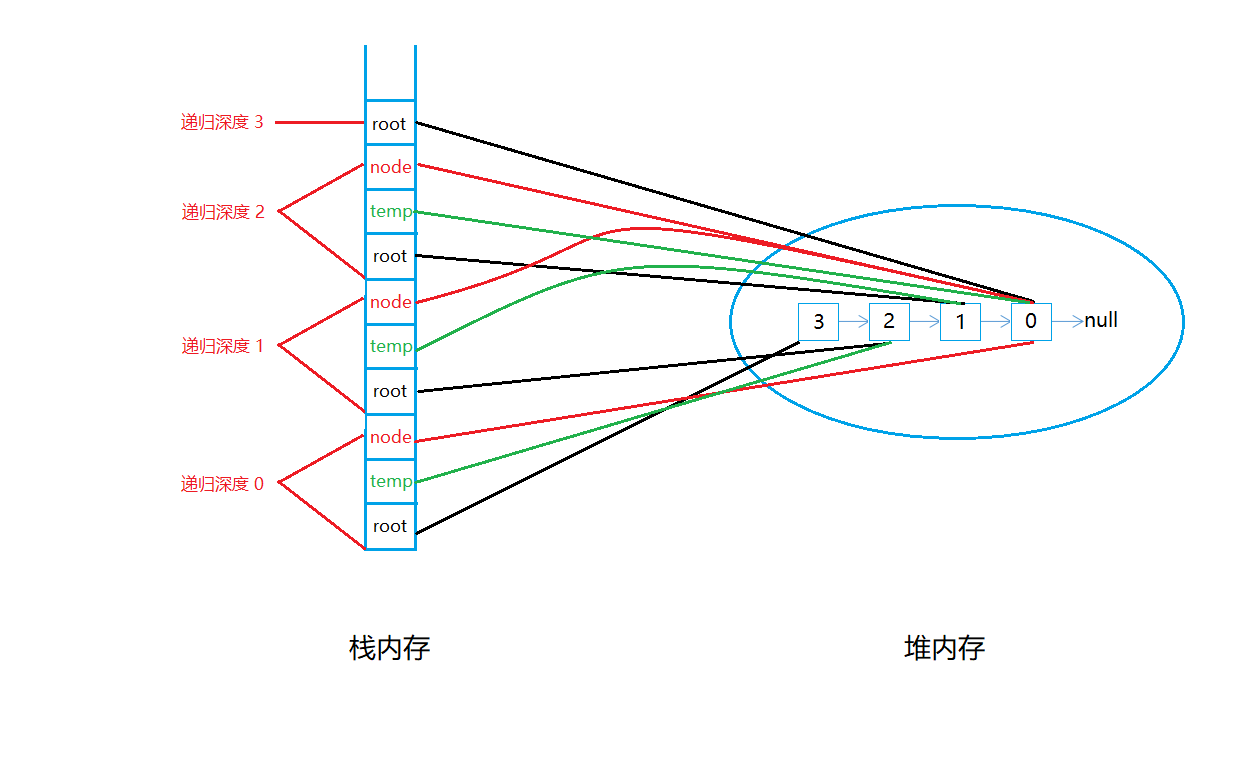
接下来,我们结合上图和压栈出栈的角度对该递归代码的执行顺序和堆内存的变化进行一个详细的分析。
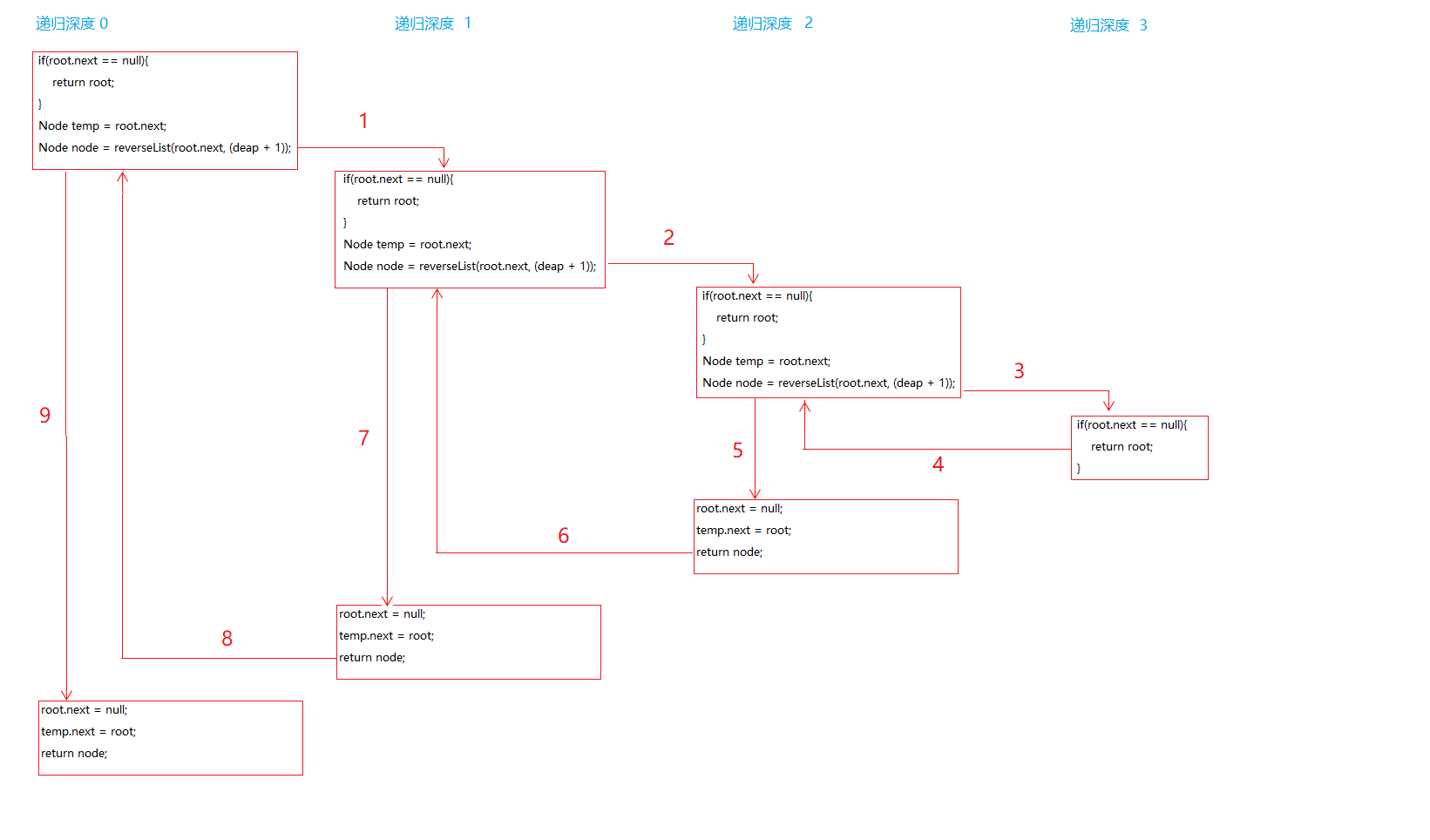
结合上面的递归树和堆栈的内存分布图进行一下分析:
第1步:递归深度0,temp变量指向递归深度为0的root.next及节点2(2 ==> 1 ==> 0 ==> null)。并将temp变量压入栈顶。执行递归,也就是步骤1。
第2步:递归深度1,temp变量指向递归深度为1的root.next及节点1(1 ==> 0 ==> null)。并将temp变量压入栈顶。执行递归,也就是步骤2。
第3步:递归深度2,temp变量指向递归深度为1的root.next及节点0( 0 ==> null)。并将temp变量压入栈顶。执行递归,也就是步骤3。
第4步:递归深度3,直接返回root == 0(0 == > null)也就是出栈。
第5步:递归深度2,当前栈顶元素为第3步的temp(指向0 == null),node指向 0节点(0 ==> null)(我们就不提node压栈出栈的事情了,因为我们上面分析过node始终是指向0节点的)。
首先看上面的递归树,当前node = 0;root = 1;temp=0;
执行代码:
root.next = null;这行代码改变了堆内存中的1节点的指向,将1节点和0几点断开了连接。及1 ==> null。当前堆内存如下图1。
temp.next = root;这行代码将0节点的下一个节点指向root所指向的堆内存也就是1节点。及 0 ==> 1 ==> null。当前堆内存如下图2。
第6步:return node;node,temp变量出栈。
第7步:递归深度1,当前栈顶元素为第2步的temp(指向节点1 == null)。
首先看上面的递归树,当前node = 0; root = 2;temp = 1;别忘了当前节点1 ==> null,0 == 1 ==> null。
执行代码:
root.next = null;这行代码同样改变了堆内存中2节点的指向,将2节点的和1节点断开了连接。及2 ==> null。当前堆内存如下图3。
temp.next = root;这行代码将1节点指向root所指向的堆内存也就是2节点。及1 ==> 2 ==> null。当前堆内存如下图4所示。
第8步:return node;node, temp变量出栈。
第9步:递归深度0,当前栈顶元素为0步的temp(指向节点2 == null)
首先看上面的递归树,当前node = 0; root = 3;temp = 2;别忘了当前节点2 ==> null,0 == 1 ==> 2 ==> null。
执行代码:
root.next = null;这行代码同样改变了堆内存中3节点的指向,将3节点的和2节点断开了连接。及3 ==> null。当前堆内存如下图5。
temp.next = root;这行代码将2节点指向root所指向的堆内存也就是3节点。及2 ==> 3 ==> null。当前堆内存如下图6所示。
return node;node, temp变量出栈。

OK,终于分析完了,大家应该对递归有了一个深刻的理解。
其实递归反转链表的代码还可以更简练一点:
1 private Node reverseList1(Node node){ 2 if(node.next == null){ 3 return node; 4 } 5 Node cur = reverseList1(node.next); 6 node.next.next = node; 7 node.next = null; 8 return cur; 9 }
3.5、查,改等操作
关于这些操作,如果前面的增和删操作看明白了,这些操作就很简单了。直接上代码吧。
1 /** 2 * 获取链表的第index个位置的元素 3 * 时间复杂度:O(n) 4 * @param index 5 * @return 6 */ 7 public E get(int index){ 8 if(index < 0 || index >= size){ 9 throw new IllegalArgumentException("获取失败,Index 参数非法"); 10 } 11 Node cur = dummyHead.next; 12 for(int i=0; i< index; i++){ 13 cur = cur.next; 14 } 15 return cur.e; 16 } 17 18 /** 19 * 获取头元素 20 * 时间复杂度:O(1) 21 * @return 22 */ 23 public E getFirst(){ 24 return get(0); 25 } 26 27 /** 28 * 获取尾元素 29 * 时间复杂度:O(n) 30 * @return 31 */ 32 public E getLast(){ 33 return get(size - 1); 34 } 35 36 /** 37 * 修改 index 位置的元素 e 38 * 时间复杂度:O(n) 39 * @param index 40 * @param e 41 */ 42 public void set(int index, E e){ 43 if(index < 0 || index >= size){ 44 throw new IllegalArgumentException("操作失败,Index 参数不合法"); 45 } 46 Node cur = this.dummyHead.next; 47 for(int i=0; i< index; i++){ 48 cur = cur.next; 49 } 50 cur.e = e; 51 } 52 53 /** 54 * 查找链表中是否存在元素 e 55 * 时间复杂度:O(n) 56 * @param e 57 * @return 58 */ 59 public boolean contains(E e){ 60 Node cur = dummyHead.next; 61 for(int i=0; i<size; i++){ 62 if(cur.e == e){ 63 return true; 64 } 65 cur = cur.next; 66 } 67 return false; 68 }
关于各个操作的时间复杂度,在每个方法的注释中都写明了。链表的时间复杂度很稳定,没什么好分析的。
四、单向链表相应的递归实现
/** * 描述:递归实现版 * * @Author shf * @Date 2019/7/26 17:04 * @Version V1.0 **/ public class LinkedListR<E> { private class Node{ private Node next; private E e; public Node(E e, Node next){ this.e = e; this.next = next; } public Node(E e){ this(e, null); } public Node(){ this(null, null); } @Override public String toString(){ return e.toString(); } } private Node dummyHead; private int size; public LinkedListR(){ this.dummyHead = new Node(); this.size = 0; } public int size(){ return size; } public boolean isEmpty(){ return size == 0; } /** * 向 index 索引位置 添加元素 e * @param index * @param e */ public void add(int index, E e){ add(index, e, dummyHead, 0); } /** * 向 index 索引位置 添加元素 e 递归实现 * @param index 索引位置 * @param e 要添加的元素 e * @param prev index 索引位置的前一个元素 * @param n */ private void add(int index, E e, Node prev, int n){ if(index == n){ size ++; prev.next = new Node(e, prev.next); return; } add(index, e, prev.next, n+1); } /** * 向链表 头 添加元素 * @param e */ public void addFirst(E e){ this.add(0, e); } /** * 向链表 尾 添加元素 * @param e */ public void addLast(E e){ this.add(this.size, e); } /** * 获取索引位置为 index 处的元素 * @param index * @return */ public E get(int index){ if(index < 0 || index >= size){ throw new IllegalArgumentException("index 参数非法"); } return get(index, 0, dummyHead.next); } private E get(int index, int n, Node node){ if(index == n){ return node.e; } return get(index, (n + 1), node.next); } public E getFirst(){ return this.get(0); } public E getLast(){ return this.get(this.size - 1); } public boolean contains(E e){ return contains(e, dummyHead.next); } private boolean contains(E e, Node node){ if(node == null){ return false; } if(node.e.equals(e)){ return true; } return contains(e, node.next); } public E remove(int index){ if(index < 0 || index >= size){ throw new IllegalArgumentException("Index is illegal"); } return remove(dummyHead, index, 0); } private E remove(Node prev, int index, int n){ if(n == index){ Node cur = prev.next; prev.next = cur.next; cur.next = null; return cur.e; } return remove(prev.next, index, (n + 1)); } public E removeElement(E e){ return removeElement(e, dummyHead); } private E removeElement(E e, Node prev){ if(prev.next != null && e.equals(prev.next.e)){ Node cur = prev.next; prev.next = cur.next; cur.next = null; return cur.e; } return removeElement(e, prev.next); } @Override public String toString(){ StringBuilder res = new StringBuilder(); Node cur = dummyHead.next; while(cur != null){ res.append(cur + "->"); cur = cur.next; } res.append("NULL"); return res.toString(); } }
为了中华民族的伟大复兴,做一个爱国敬业的码农。
参考文献:
《玩转数据结构-从入门到进阶-刘宇波》
《数据结构与算法分析-Java语言描述》
如有错误还请留言指正。
原创不易,转载请注明原文地址:https://www.cnblogs.com/hello-shf/p/11304615.html