Spark - Parquet
概述
Apache Parquet属于Hadoop生态圈的一种新型列式存储格式,既然属于Hadoop生态圈,因此也兼容大多圈内计算框架(Hadoop、Spark),另外Parquet是平台、语言无关的,这使得它的适用性很广,只要相关语言有对应支持的类库就可以用;
Parquet的优劣对比:
- 支持嵌套结构,这点对比同样是列式存储的OCR具备一定优势;
- 适用于OLAP场景,对比CSV等行式存储结构,列示存储支持映射下推和谓词下推,减少磁盘IO;
- 同样的压缩方式下,列式存储因为每一列都是同构的,因此可以使用更高效的压缩方法;
下面主要介绍Parquet如何实现自身的相关优势,绝不仅仅是使用了列式存储就完了,而是在数据模型、存储格式、架构设计等方面都有突破;
列式存储 vs 行式存储
区别在于数据在内存中是以行为顺序存储还是列为顺序,首先没有哪种方式更优,主要考虑实际业务场景下的数据量、常用操作等;
数据压缩
例如两个学生对象分别在行式和列式下的存储情况,假设学生对象具备姓名-string、年龄-int、平均分-double等信息:
行式存储:
| 姓名 | 年龄 | 平均分 | 姓名 | 年龄 | 平均分 |
|---|---|---|---|---|---|
| 张三 | 15 | 82.5 | 李四 | 16 | 77.0 |
列式存储:
| 姓名 | 姓名 | 年龄 | 年龄 | 平均分 | 平均分 |
|---|---|---|---|---|---|
| 张三 | 李四 | 15 | 16 | 82.5 | 77.0 |
乍一看似乎没有什么区别,事实上如何不进行压缩的化,两种存储方式实际存储的数据量都是一致的,那么确实没有区别,但是实际上现在常用的数据存储方式都有进行不同程度的压缩,下面我们考虑灵活进行压缩的情况下二者的差异:
行式存储是按照行来划分最小单元,也就是说压缩对象是某一行的数据,此处就是针对(张三、15、82.5)这个数据组进行压缩,问题是该组中数据格式并不一致且占用内存空间大小不同,也就没法进行特定的压缩手段;
列式存储则不同,它的存储单元是某一列数据,比如(张三、李四)或者(15,16),那么就可以针对某一列进行特定的压缩,比如对于姓名列,假设我们值到最长的姓名长度那么就可以针对性进行压缩,同样对于年龄列,一般最大不超过120,那么就可以使用tiny int来进行压缩等等,此处利用的就是列式存储的同构性;
注意:此处的压缩指的不是类似gzip这种通用的压缩手段,事实上任何一种格式都可以进行gzip压缩,这里讨论的压缩是在此之外能够进一步针对存储数据应用更加高效的压缩算法以减少IO操作;
谓词下推
与上述数据压缩类似,谓词下推也是列式存储特有的优势之一,继续使用上面的例子:
行式存储:
| 姓名 | 年龄 | 平均分 | 姓名 | 年龄 | 平均分 |
|---|---|---|---|---|---|
| 张三 | 15 | 82.5 | 李四 | 16 | 77.0 |
列式存储:
| 姓名 | 姓名 | 年龄 | 年龄 | 平均分 | 平均分 |
|---|---|---|---|---|---|
| 张三 | 李四 | 15 | 16 | 82.5 | 77.0 |
假设上述数据中每个数据值占用空间大小都是1,因此二者在未压缩下占用都是6;
我们有在大规模数据进行如下的查询语句:
SELECT 姓名,年龄 FROM info WHERE 年龄>=16;
这是一个很常见的根据某个过滤条件查询某个表中的某些列,下面我们考虑该查询分别在行式和列式存储下的执行过程:
- 行式存储:
- 查询结果和过滤中使用到了姓名、年龄,针对全部数据;
- 由于行式是按行存储,而此处是针对全部数据行的查询,因此需要遍历所有数据并对比其年龄数据,确定是否返回姓名、年龄;
- 列式存储:
- 过滤中使用了年龄,因此把年龄列取出来进行判断,判断结果是李四满足要求;
- 按照上述判断结果把姓名列取出来,取出其中对应位置的姓名数据,与上述年龄数据一起返回;
- 可以看到此时由于未涉及平均分,因此平均分列没有被操作过;
事实上谓词下推的使用主要依赖于在大规模数据处理分析的场景中,针对数据中某些列做过滤、计算、查询的情况确实更多,这一点有相关经验的同学应该感触很多,因此这里只能说列式存储更加适用于该场景;
统计信息
这部分直接用例子来理解,还是上面的例子都是有一点点改动,为了支持一些频繁的统计信息查询,针对年龄列增加了最大和最小两个统计信息,这样如果用户查询年龄列的最大最小值就不需要计算,直接返回即可,存储格式如下:
行式存储:
| 姓名 | 年龄 | 平均分 | 姓名 | 年龄 | 平均分 | 年龄最大 | 年龄最小 |
|---|---|---|---|---|---|---|---|
| 张三 | 15 | 82.5 | 李四 | 16 | 77.0 | 16 | 15 |
列式存储:
| 姓名 | 姓名 | 年龄 | 年龄 | 年龄最大 | 年龄最小 | 平均分 | 平均分 |
|---|---|---|---|---|---|---|---|
| 张三 | 李四 | 15 | 16 | 16 | 15 | 82.5 | 77.0 |
在统计信息存放位置上,由于统计信息通常是针对某一列的,因此列式存储直接放到对应列的最后方或者最前方即可,行式存储需要单独存放;
针对统计信息的耗时主要体现在数据插入删除时的维护更新上:
- 行式存储:插入删除每条数据都需要将年龄与最大最小值进行比较并判断是否需要更新,如果是插入数据,那么更新只需要分别于最大最小进行对比即可,如果是删除数据,那么如果删除的恰恰是最大最小值,就还需要从现有数据中遍历查找最大最小值来,这就需要遍历所有数据;
- 列式存储:插入有统计信息的对应列时才需要进行比较,此处如果是插入姓名列,那就没有比较的必要,只有年龄列会进行此操作,同样对于年龄列进行删除操作后的更新时,只需要针对该列进行遍历即可,这在数据维度很大的情况下可以缩小N(N为数据列数)倍的查询范围;
数据架构
这部分主要分析Parquet使用的数据模型,以及其如何对嵌套类型的支持(需要分析repetition level和definition level);
数据模型这部分主要分析的是列式存储如何处理不同行不同列之间存储上的歧义问题,假设上述例子中增加一个兴趣列,该列对应行可以没有数据,也可以有多个数据(也就是说对于张三和李四,可以没有任何兴趣,也可以有多个,这种情况对于行式存储不是问题,但是对于列式存储存在一个数据对应关系的歧义问题),假设兴趣列存储如下:
| 兴趣 | 兴趣 |
|---|---|
| 羽毛球 | 篮球 |
事实上我们并不确定羽毛球和篮球到底都是张三的、都是李四的、还是二人一人一个,这是由兴趣列的特殊性决定的,这在Parquet数据模型中称这一列为repeated的;
数据模型
上述例子的数据格式用parquet来描述如下:
message Student{
required string name;
optinal int age;
required double score;
repeated group hobbies{
required string hobby_name;
repeated string home_page;
}
}
这里将兴趣列复杂了一些以展示parquet对嵌套的支持:
- Student作为整个schema的顶点,也是结构树的根节点,由message关键字标识;
- name作为必须有一个值的列,用required标识,类型为string;
- age作为可选项,可以有一个值也可以没有,用optinal标识,类型为string;
- score作为必须有一个值的列,用required标识,类型为double;
- hobbies作为可以没有也可以有多个的列,用repeated标识,类型为group,也就是嵌套类型;
- hobby_name属于hobbies中元素的属性,必须有一个,类型为string;
- home_page属于hobbies中元素的属性,可以有一个也可以没有,类型为string;
可以看到Parquet的schema结构中没有对于List、Map等类型的支持,事实上List通过repeated支持,而Map则是通过group类型支持,举例说明:
通过repeated支持List:
[15,16,18,14]
==>
repeated int ages;
通过repeated+group支持List[Map]:
{'name':'李四','age':15}
==>
repeated group Peoples{
required string name;
optinal int age;
}
存储格式
从schema树结构到列存储;
还是上述例子,看下schema的树形结构:
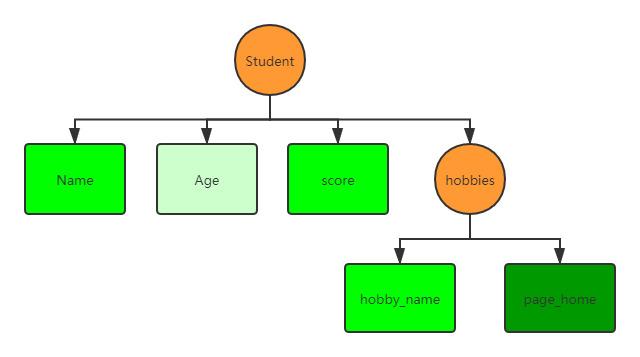
矩形表示是一个叶子节点,叶子节点都是基本类型,Group不是叶子,叶子节点中颜色最浅的是optinal,中间的是required,最深的是repeated;
首先上述结构对应的列式存储总共有5列(等于叶子节点的数量):
| Column | Type |
|---|---|
| Name | string |
| Age | int |
| Score | double |
| hobbies.hobby_name | string |
| hobbies.page_home | string |
Definition level & Repeatition level
解决上述歧义问题是通过定义等级和重复等级来完成的,下面依次介绍这两个比较难以直观理解的概念;
Definition level 定义等级
Definition level指的是截至当前位置为止,从根节点一路到此的路径上有多少可选的节点被定义了,因为是可选的,因此required类型不统计在内;
如果一个节点被定义了,那么说明到达它的路径上的所有节点都是被定义的,如果一个节点的定义等级等于这个节点处的最大定义等级,那么说明它是有数据的,否则它的定义等级应该更小才对;
一个简单例子讲解定义等级:
message ExampleDefinitionLevel{
optinal group a{
required group b{
optinal string c;
}
}
}
| Value | Definition level | 说明 |
|---|---|---|
| a:null | 0 | a往上只有根节点,因此它最大定义等级为1,但是它为null,所以它的定义等级为0; |
| a:{b:null} | 不可能 | b是required的,因此它不可能为null; |
| a:{b:{c:null}} | 1 | c处最大定义等级为2,因为b是required的不参与统计,但是c为null,所以它的定义等级为1; |
| a:{b:{c:"foo"}} | 2 | c有数据,因此它的定义等级就等于它的最大定义等级,即2; |
到此,定义等级的计算公式如下:当前树深度 - 路径上类型为required的个数 - 1(如果自身为null);
Repetition level 重复等级
针对repeated类型field,如果一个field重复了,那么它的重复等级等于根节点到达它的路径上的repeated节点的个数;
注意:这个重复指的是同一个父节点下的同一类field出现多个,如果是不同父节点,那也是不算重复的;
同样以简单例子进行分析:
message ExampleRepetitionLevel{
repeated group a{
required group b{
repeated group c{
required string d;
repeated string e;
}
}
}
}
| Value | Repetition level | 说明 |
|---|---|---|
| a:null | 0 | 根本没有重复这回事。。。。 |
| a:a1 | 0 | 对于a1,虽然不是null,但是field目前只有一个a1,也没有重复; |
| a:a1 a:a2 |
1 | 对于a2,前面有个a1此时节点a重复出现了,它的重复等级为1,因为它上面也没有其他repeated节点了; |
| a1:{b:null} | 0 | 对于b,a1看不到a2,因此没有重复; |
| a1:{b:null} a2:{b:null} |
1 | 对于a2的b,a2在a1后面,所以算出现重复,b自身不重复且为null; |
| a1:{b:{c:c1}} a2:{b:{c:c2}} |
1 | 对于c2,虽然看着好像之前有个c1,但是由于他们分属不同的父节点,因此c没有重复,但是对于a2与a1依然是重复的,所以重复等级为1; |
| a1:{b:{c:c1}} a1:{b:{c:c2}} |
2 | 对于c2,他们都是从a1到b,父节点都是b,那么此时field c重复了,c路径上还有一个a为repeated,因此重复等级为2; |
这里可能还是比较难以理解,下面通过之前的张三李四的例子,来更加真切的感受下在这个例子上的定义等级和重复等级;
张三李四的定义、重复等级
Schema以及数据内容如下:
message Student{
required string name;
optinal int age;
required double score;
repeated group hobbies{
required string hobby_name;
repeated string home_page;
}
}
Student 1:
Name 张三
Age 15
Score 70
hobbies
hobby_name 篮球
page_home nba.com
hobbies
hobby_name 足球
Student 2:
Name 李四
Score 75
name列最好理解,首先它是required的,所以既不符合定义等级,也不符合重复等级的要求,又是第一层的节点,因此全部都是0;
| name | 定义等级 | 重复等级 |
|---|---|---|
| 张三 | 0 | 0 |
| 李四 | 0 | 0 |
score列所处层级、类型与name列一致,也全部都是0,这里就不列出来了;
age列同样处于第一层,但是它是optinal的,因此满足定义等级的要求,只有张三有age,定义等级为1,路径上只有它自己满足,重复等级为0;
| age | 定义等级 | 重复等级 |
|---|---|---|
| 15 | 1 | 0 |
hobby_name列处于hobbies group中,类型是required,篮球、足球定义等级都是1(自身为required不纳入统计),父节点hobbies为repeated,纳入统计,篮球重复等级为0,此时张三的数据中还没有出现过hobby_name或者hobbies,而足球的父节点hobbies重复了,而hobbies路径上重复节点数为1,因此它的重复等级为1;
| hobbies.hobby_name | 定义等级 | 重复等级 |
|---|---|---|
| 篮球 | 1 | 0 |
| 足球 | 1 | 1 |
home_page列只在张三的第一个hobbies中有,首先重复等级为0,这点与篮球是一个原因,而定义等级为2,因为它是repeated,路径上它的父节点也是repeated的;
| hobbies.home_page | 定义等级 | 重复等级 |
|---|---|---|
| nba.com | 2 | 0 |
到此对两个虽然简单,但是也包含了Parquet的三种类型、嵌套group等结构的例子进行了列式存储分析,对此有个基本概念就行,其实就是两个等级的定义问题;
文件格式
Parquet的文件格式主要由header、footer、Row group、Column、Page组成,这种形式也是为了支持在hadoop等分布式大数据框架下的数据存储,因此这部分看起来总让人想起hadoop的分区。。。。。。
结合下面的官方格式展示图:
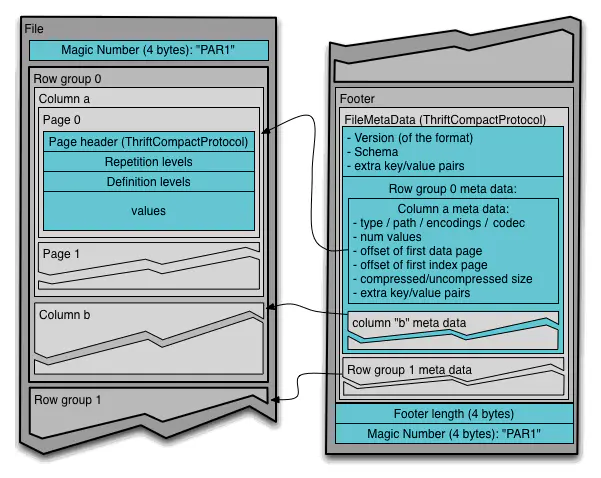
可以看到图中分为左右两部分:
- 左边:
- 最外层表示一个Parquet文件;
- 首先是Magic Number,用于校验Parquet文件,并且也可以用于表示文件开始和结束位;
- 一个File对应多个Row group;
- 一个Row group对应多个Column;
- 一个Column对应多个Page;
- Page是最小逻辑存储单元,其中包含头信息、重复等级和定义等级以及对应的数据值;
- 右边:
- Footer中包含重要的元数据;
- 文件元数据包含版本、架构、额外的k/v对等;
- Row group元数据包括其下属各个Column的元数据;
- Column的元数据包含数据类型、路径、编码、偏移量、压缩/未压缩大小、额外的k/v对等;
文件格式的设定一方面是针对Hadoop等分布式结构的适应,另一方面也是对其嵌套支持、高效压缩等特性的支持,所以觉得从这方面理解会更容易一些,比如:
- 嵌套支持:从上一章节知道列式存储支持嵌套中Repetition level和Definition level是很重要的,这二者都存放于Row group的元数据中;
- 高效压缩:注意到每个Column都有一个type元数据,那么压缩算法可以通过这个属性来进行对应压缩,另外元数据中的额外k/v对可以用于存放对应列的统计信息;
Python导入导出Parquet格式文件
最后给出Python使用Pandas和pyspark两种方式对Parquet文件的操作Demo吧,实际使用上由于相关库的封装,对于调用者来说除了导入导出的API略有不同,其他操作是完全一致的;
Pandas:
import pandas as pd
pd.read_parquet('parquet_file_path', engine='pyarrow')
上述代码需要注意的是要单独安装pyarrow库,否则会报错,pandas是基于pyarrow对parquet进行支持的;
PS:这里没有安装pyarrow,也没有指定engine的话,报错信息中说可以安装pyarrow或者fastparquet,但是我这里试过fastparquet加载我的parquet文件会失败,我的parquet是spark上直接导出的,不知道是不是两个库对parquet支持上有差异还是因为啥,pyarrow就可以。。。。
pyspark:
from pyspark import SparkContext
from pyspark.sql.session import SparkSession
ss = SparkSession(sc)
ss.read.parquet('parquet_file_path') # 默认读取的是hdfs的file
pyspark就直接读取就好,毕竟都是一家人。。。。
参考
文中的很多概念、例子等都来自于下面两篇分享,需要的同学可以移步那边;