参考自: https://www.cnblogs.com/chengxuyuanaa/p/12849919.html
#_*_ encoding: utf-8 _*_ @author: ty hery 2020/6/4
from collections import OrderedDict
# collections.OrderedDict类:
def __setitem__(self, key, value, dict_setitem=dict.__setitem__):
if key not in self:
root = self.__root
last = root[0]
last[1] = root[0] = self.__map[key] = [last, root, key]
return dict_setitem(self, key, value)
# 注意最后一个参数:dict_setitem=dict.setitem。如果你仔细想就会感觉有道理。将值关联到键上,
# 你只需要给setitem传递三个参数:要设置的键,与键关联的值,传递给内建dict类的setitem类方法。等会,好吧,
# 也许最后一个参数没什么意义。 最后一个参数其实是将一个函数绑定到局部作用域中的一个函数上。
# 具体是通过将dict.setitem赋值为参数的默认值。这里还有另一个例子:
def not_list_or_dict(value):
return not (isinstance(value, dict) or isinstance(value, list))
# 这里我们做同样的事情,把本来将会在内建命名空间中的对象绑定到局部作用域中去。因此,python将会使用LOCAL_FAST而不是
# LOAD_GLOBAL(全局查找)。那么这到底有多快呢?我们做个简单的测试:
# $ python -m timeit -s 'def not_list_or_dict(value): return not (isinstance(value, dict) or isinstance(value, list))'
# 'not_list_or_dict(50)'1000000 loops, best of 3: 0.48 usec per loop
#
# $ python -m timeit 'def not_list_or_dict(value, _isinstance=isinstance, _dict=dict, _list=list):return not (_isinstance(value, _dict) or _isinstance(value, _list))'
# 'not_list_or_dict(50)'1000000 loops, best of 3: 0.423 usec per loop
# 换句话说,大概有11.9%的提升 [2]。比我在文章开始处承诺的5%还多!
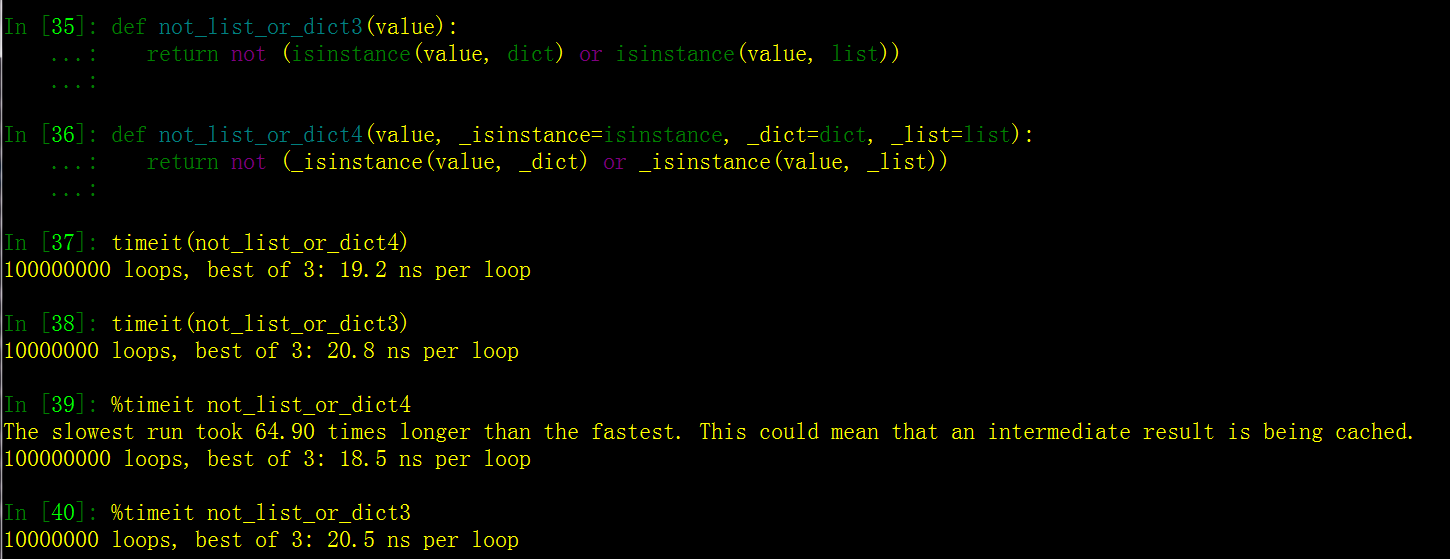
测试结果:
In [35]: def not_list_or_dict3(value):
...: return not (isinstance(value, dict) or isinstance(value, list))
...:
In [36]: def not_list_or_dict4(value, _isinstance=isinstance, _dict=dict, _list=list):
...: return not (_isinstance(value, _dict) or _isinstance(value, _list))
...:
In [37]: timeit(not_list_or_dict4)
100000000 loops, best of 3: 19.2 ns per loop
In [38]: timeit(not_list_or_dict3)
10000000 loops, best of 3: 20.8 ns per loop
In [39]: %timeit not_list_or_dict4
The slowest run took 64.90 times longer than the fastest. This could mean that an intermediate result is being cached.
100000000 loops, best of 3: 18.5 ns per loop
In [40]: %timeit not_list_or_dict3
10000000 loops, best of 3: 20.5 ns per loop
In [41]: 18
试了下,确实有小额度提升,但是不到,%7到%9之间