二叉查找树
(1)二叉查找树后续遍历的最后一个结点,必能把前面的部分分成两部分,左边比它小,右边比它大。
根据上面结论就可以判断。
二叉平衡树(AVL)
二叉平衡树(AVL)肯定是一个二叉排序树,任何节点的两个子树的高度最大差别为1。
在AVL树中进行插入或删除节点后,可能导致AVL树失去平衡。这种失去平衡的可以概括为4种姿态:LL(左左),LR(左右),RR(右右)和RL(右左)。

(1)LL旋转代码

private TreeNode leftLeftRotation(TreeNode k2){ TreeNode k1; k1 = k2.left; // 先得到k1根节点。 k2.left = k1.right; //先把k1的right给k2,因为下一步要给k1的right赋值。 k1.right = k2; return k1; }
(2)RR旋转代码
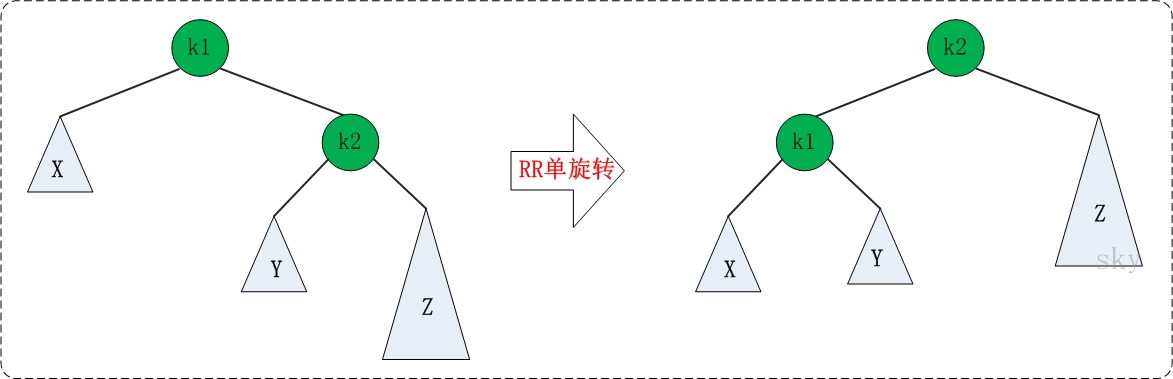
private TreeNode rightRightRotation(TreeNode k1){ TreeNode k2; k2 = k1.right; k1.right = k2.left; k2.left = k1; return k2; }
(3)LR旋转代码
先通过RR旋转为LL情况,再进行LL旋转。即对k3的左子树RR,再对k3 LL

private TreeNode leftRightRotation(TreeNode k3){ k3.left = rightRightRotation(k3.left); return leftLeftRotation(k3); }
(4)RL 旋转代码
先通过LL旋转为RR情况,再进行RR旋转。即对k1的右子树LL,再对k1 RR

private TreeNode rightLeftRotation(TreeNode k1){ k1.right = leftLeftRotation(k1.right); return rightRightRotation(k1); }
B 树
大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下,那么如何减少树的深度,一个基本的想法就是:采用多叉树结构。
由于大规模数据存储在外存磁盘中,而在外存磁盘中读取/写入块(block)中某数据时,首先需要定位到磁盘中的某块,如何有效地查找磁盘中的数据,需要一种合理高效的外存数据结构,就是下面所要重点阐述的B-tree结构,以及相关的变种结构:B+-tree结构和B*-tree结构。数据库系统都一般使用B树或者B树的各种变形结构,就是为了降低磁盘I/0操作。数据库索引采用B+树。
数据库索引采用B+树的主要原因是 B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
B*-tree是B+-tree的变体
Trie 树