前面讲到如何搭建solr运行环境以及对中文查询语句进行分词处理,这篇文章主要讲解对schema.xml的相关配置和如何使用solrj
对于搜索程序来说,最重要的是理解他的总体架构.solr也是基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面.但是他的执行过程却无异于lucene
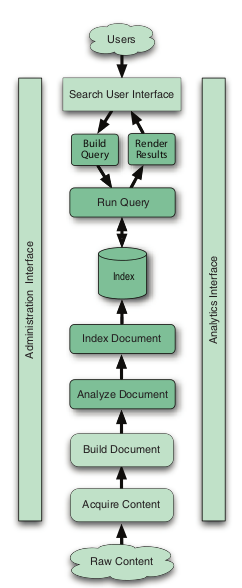
搜索程序的典型组件,其中阴影部分由lucene完成
我们首先来说说这个schema.xml。
schema.xml,这个相当于数据表配置文件,它定义了加入索引的数据的数据类型。主要包括types、fields和其他的一些缺省设置。
1)首先需要在types结点内定义一个FieldType子结点,包括name,class,positionIncrementGap等等一些参数,name就是这个FieldType的名称,class指向org.apache.solr.analysis包里面对应的class名称,用来定义这个类型的行为。在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤。在第二篇文章中详细讲了怎样添加中文分词器,详情请参见http://3961409.blog.51cto.com/3951409/833417
2)接下来的工作就是在fields结点内定义具体的字段(类似数据库中的字段),就是filed,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否有多个值)等等。
例:
- <field name="id" type="string" indexed="true" stored="true" required="true" />
- <field name="ant_title" type="textComplex" indexed="true" stored="true" />
- <field name="ant_content" type="textComplex" indexed="true" stored="true" />
- <field name="all" type="textComplex" indexed="true" stored="false" multiValued="true"/>
field的定义相当重要,有几个技巧需注意一下,对可能存在多值得字段尽量设置multiValued属性为true,避免建索引抛出错误;如果不需要存储相应字段值,尽量将stored属性设为false。
3)建议建立了一个拷贝字段,将所有的全文字段复制到一个字段中,以便进行统一的检索: (此时进行查询使用all:jason就相当于使用ant_title:jason or ant_content:jason)
- <field name="all" type="textComplex" indexed="true" stored="false" multiValued="true"/>
并在拷贝字段结点处完成拷贝设置:
- <copyField source="ant_title" dest="all"/>
- <copyField source="ant_content" dest="all"/>
4)除此之外,还可以定义动态字段,所谓动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
schema.xml配置文件大体上就是这样,更多细节请参见solr wiki http://wiki.apache.org/solr/SchemaXml。
下面将使用solrj对索引进行操作
1)新建工程,并加入以下jar包(参考http://wiki.apache.org/solr/Solrj)
From /dist:
- apache-solr-solrj-*.jar
From /dist/solrj-lib
- commons-codec-1.3.jar
- commons-httpclient-3.1.jar
- commons-io-1.4.jar
- jcl-over-slf4j-1.5.5.jar
- slf4j-api-1.5.5.jar
也就是solr/dist/solrj-lib/中commons-codec-x.xjar , commons-httpclient-x.x.jar , commons-io-x.x.jar , jcl-over-slf4j-x.x.jar , slf4j-api-x.x.jar还有solr/dist/中apache-solr-solrj-x.x.x.jar , apache-solr-core-x.x.x.jar
2)新建一个测试类
- package cn.edu.ccut.blackant;
- import java.io.IOException;
- import java.net.MalformedURLException;
- import org.apache.solr.client.solrj.SolrServerException;
- import org.apache.solr.client.solrj.impl.CommonsHttpSolrServer;
- import org.apache.solr.common.SolrInputDocument;
- import org.junit.Test;
- public class SolrTest {
- @Test
- public void test(){
- final String URL="http://localhost:8080/solr";
- //创建solrserver对象(CommonsHttpSolrServer)
- try {
- CommonsHttpSolrServer server=new CommonsHttpSolrServer(URL);
- SolrInputDocument doc = new SolrInputDocument();
- doc.addField("id", "2");//id必须有,value的值类型要根据schema.xml中规定的id类型而定
- doc.addField("ant_title", "atitle");
- doc.addField("ant_content", "jason");
- server.add(doc);
- server.commit();
- } catch (MalformedURLException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } catch (SolrServerException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- } catch (IOException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
项目中添加junit,具体做法是右键项目-->add library-->选择junit-->junit4-->finish
3)运行测试类(运行相关信息需要查看控制台或者tomcat的日志文件)
运行结果可以使用luke来查看,使用前一定要根据solr的版本来选择luke,这里是用的是solr3.5,所以luke也要用3.5版本
下载地址http://code.google.com/p/luke/downloads/detail?name=lukeall-3.5.0.jar
使用方法:
3.1)进入文件所在路径
3.2)在命令行java -jar ./lukeall-3.5.0.jar打开软件
运行界面如图:
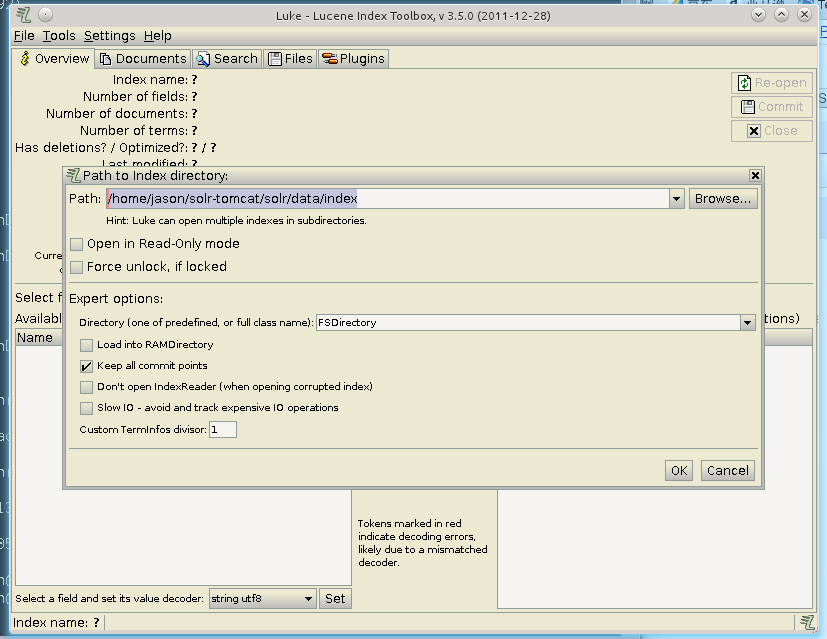
需要说明的是要指定solr的索引文件路径.此处为/home/jason/solr-tomcat/solr/data/index,指定好路径以后
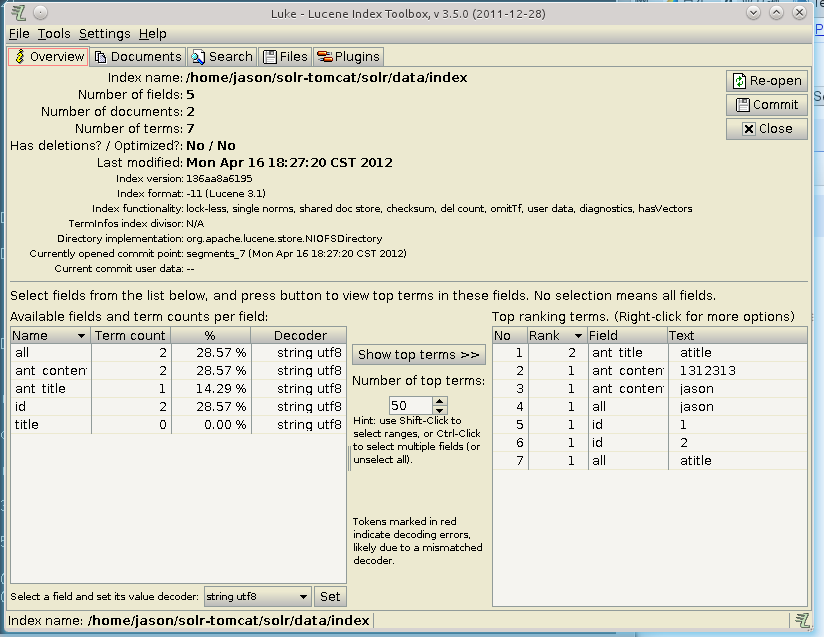
运行成功的话将会生成新的索引,如图右下角所示.如果程序中id值不变,那么每次将会覆盖id为2的索引值,这样可以完成更新索引的操作
4)访问http://127.0.0.1:8080/solr/admin/
查询*:*(查询全部),如果结果包含程序中的信息,那么恭喜配置成功!
本文出自 “李明泽” 博客,请务必保留此出处http://3961409.blog.51cto.com/3951409/836027