视频学习资料:
https://www.bilibili.com/video/BV12E411A7ZQ?p=22
常用正则表达式知识总结与应用:
原文地址:https://www.cnblogs.com/zxin/archive/2013/01/26/2877765.html
一、正则表达式简单解析
正则表达式:(判断字符串是否符合一定的标准)
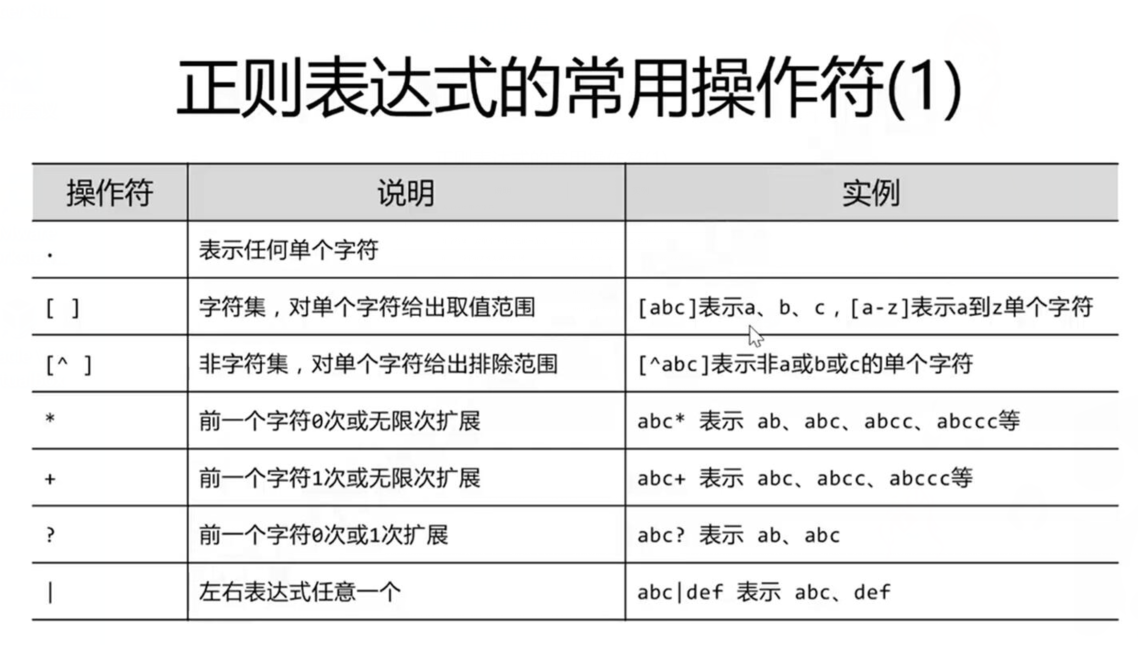

二、Re库主要功能函数

添加的模式限定:

注意*:建议在正则表达式中,被比较的字符串前面加上人,不用担心转义字符的问题
三、源码案例


import urllib.request,urllib.error #指定URL获取网页数据 import bs4 #网页解析数据获取 import re #正则表达式,进行文字匹配的 import xlwt #进行excel操作 import sqlite3 #进行SQLite数据库操作 from bs4 import BeautifulSoup #主函数 def main(): baseurl="https://movie.douban.com/top250?start=" #1.爬取网页 #2.逐一解析数据 dataList=getDate(baseurl) #3.保存数据 #savepath="" #saveData(savepath) #askURL("https://movie.douban.com/top250?start=") #影片详情链接的规则 findLink=re.compile(r'<a href="(.*?)">') #生成正则表达式对象,表示规则(字符串的模式) #-------------------------相关函数----------------------------- #1.爬取网页 def getDate(baseurl): dataList=[] for i in range(0,1): #循环爬取页面,调用活页页面信息的函数10次 url=baseurl+str(i*25) html= askURL(url) #保存获取到的网页源码 #2.逐一解析数据 soup=BeautifulSoup(html,"html.parser") for item in soup.find_all('div',class_="item"): #查找符合要求的字符串 #print(item) #测试:查看电影item全部信息 data=[] #保存一部电影的所有信息 item=str(item) #获取影片详情链接 link=re.findall(findLink,item)[0] #re库用来通过正则表达式查找指定的字符串 print(link) return dataList #得到指定一个URL的网页内容 def askURL(url): head={ #模拟浏览器头部消息,向豆瓣服务器发送消息 "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36" } #用户代理表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容) request=urllib.request.Request(url,headers=head) html="" try: response=urllib.request.urlopen(request) html=response.read().decode("utf-8") #print(html) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) return html #3.保存数据 def saveData(savepath): print("print...") if __name__=="__main__": #当程序执行时,更容易管理代码主流程(程序入口) #调用函数 main();
四、运行截图