Mysql失效总结
准备
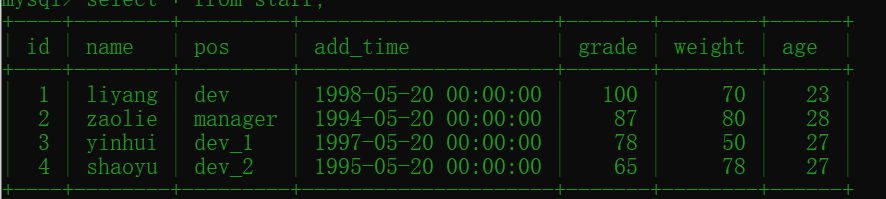
为了进行Mysql失效的实践,我们首先创建一个表,执行以下 sql 语句:
mysql> create table staff(
-> id int(11) not null auto_increment,
-> name varchar(20) not null,
-> pos varchar(20),
-> add_time datetime,
-> grade int(10),
-> weight int(10),
-> age int(10),
-> UNIQUE INDEX name_idx (name),
-> primary key (id))engine = innodb default charset = utf8;
执行插入语句,
insert into staff(name,pos,add_time,grade,weight,age) values("liyang", "dev","1998-5-20", 100, 23);
insert into staff(name,pos,add_time,grade,weight,age) values("zaolie", "manager","1994-5-20", 87,80, 28);
insert into staff(name,pos,add_time,grade,weight,age) values("yinhui", "dev_1","1997-5-20", 78,50, 27);
insert into staff(name,pos,add_time,grade,weight,age) values("shaoyu", "dev_2","1995-5-20", 65,78, 27);
执行 select * from staff:
Explain关键字
mysql为我们提供了很有用的辅助武器 explain,它向我们展示了 mysql 接收到一条sql语句的执行计划。根据explain 返回的结果我们便可以知道我们的 sql 写的怎么样,是否会造成查询瓶颈,同时根据结果不断的修改调整查询语句,从而完成 sql 优化的过程。
虽然 explain返回的结果项很多,这里我们只关注三种,分别是type,key,rows。
其中 key 表示用到了什么索引,为NULL表示未用到索引;rows 表示查找数据扫描的行数, type 表示连接类型;
type 字段出现不同的值表示的含义:
- all, 全表扫描;
- index,这种连接类型只是另外一种形式的全表扫描,只不过它的扫描顺序是按照索引的顺序。这种扫描根据索引然后回表取数据,和all相比,他们都是取得了全表的数据,而且index要先读索引而且要回表随机取数据,因此index不可能会比all快(取同一个表数据),但为什么官方的手册将它的效率说的比all好,唯一可能的原因在于,按照索引扫描全表的数据是有序的。
- range, 有范围的索引扫描,使用了范围索引,比如between, and 以及 ‘<', '>', in 和 or 也是索引范围优扫描。
- ref, 查找条件列使用了索引而且不为主键和unique。其实,意思就是虽然使用了索引,但该索引列的值并不唯一,有重复。
- ref_eq, 使用了主键或者唯一性索引;
- const, 如果将一个主键放置到where后面作为条件查询,mysql优化器就能把这次查询优化转化为一个常量。
索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
拿汉语字典的目录页(索引)打比方,我们可以按拼音、笔画、偏旁部首等排序的目录(索引)快速查找到需要的字。
索引分单列索引和组合索引。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
上面都在说使用索引的好处,但过多的使用索引将会造成滥用。因此索引也会有它的缺点:虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
建立索引会占用磁盘空间的索引文件。
普通索引
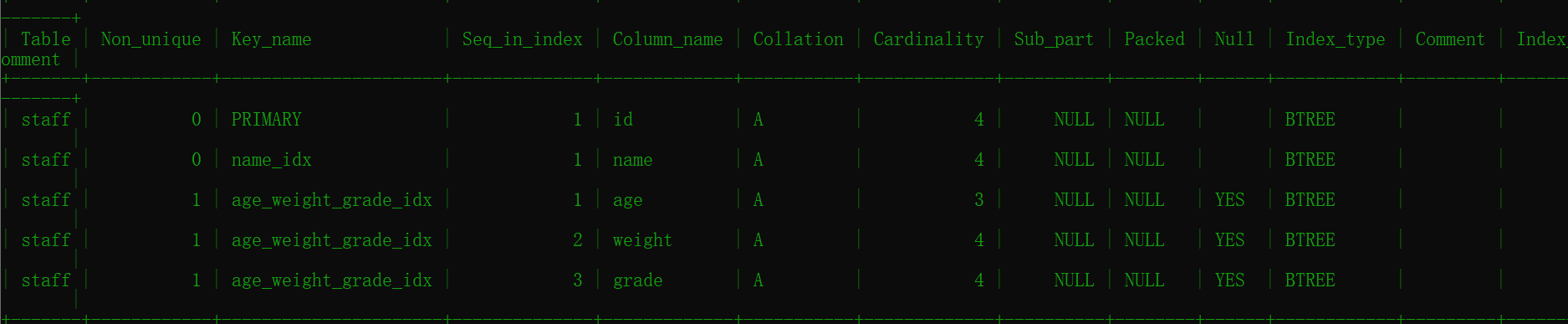
查看索引
show index from staff: 查看表的索引

其中,
-
Table: 表名, -
Non_unique: 表示如果索引不能包含重复项,则返回 0 ;如果可以,则返回 1. -
Key_name: 索引名称,或者键名; -
Seq_in_index: 索引中的序列号,从1开始。 -
Column_name:列名; -
Collation: 列在索引中的排序方式。升序值 A 或者 NULL 未排序; -
Cardinality: 索引中唯一值数量的估计。Cardinality是根据存储为整数的统计信息进行计数的. -
Sub_part: 索引前缀,如果仅对列进行部分索引,则为已索引字符的数目;如果对整个列索引则为null.Note
前缀限制以字节为单位。但是,对于CREATE TABLE,ALTER TABLE和CREATE INDEX语句中的索引规范,前缀 length 被解释为非二进制字符串类型(CHAR,VARCHAR,TEXT)的字符数和二进制字符串类型(BINARY,VARBINARY,BLOB)的字节数。
-
Packed: 指示密钥的包装方式。 -
NULL: 如果该列可能包含NULL个值,则包含YES;否则,则包含''。 -
Index_type: 使用的索引方法(BTREE,FULLTEXT,HASH,RTREE) -
Comment: 关于索引的信息未在其自己的列中描述,例如disabled(如果禁用了索引)。 -
Index_comment: 创建索引时,为索引提供的具有COMMENT属性的任何 Comments。
创建索引
-
创建索引
CREATE INDEX indexName ON table_name (column_name)如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
-
修改表结构添加
Alter table tableName ADD INDEX indexName(column) -
创建表时添加
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, INDEX [indexName] (username(length)) );
删除索引
DROP INDEX [indexName] ON mytable;
唯一索引
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建索引
-
创建索引
CREATE UNIQUE INDEX indexName ON mytable(username(length)) -
修改表结构
ALTER table mytable ADD UNIQUE [indexName] (username(length)) -
创建表时指定
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, UNIQUE [indexName] (username(length)) );
使用ALTER 命令添加和删除索引
添加主键
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list)
该语句添加一个主键,这意味着索引值必须是唯一的,且不能为NULL。
添加唯一索引
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list)
这条语句创建索引的值必须是唯一的(除了NULL外,NULL可能会出现多次)。
添加普通索引
ALTER TABLE tbl_name ADD INDEX index_name (column_list)
添加普通索引,索引值可出现多次。
添加全文索引
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list)
该语句指定了索引为 FULLTEXT ,用于全文索引。
删除表中的索引
ALTER 命令中使用 DROP 子句来删除索引:
ALTER table tableName DROP INDEX c;
使用ALTER 命令添加和删除主键
主键作用于列上(可以一个列或多个列联合主键),添加主键索引时,你需要确保该主键默认不为空(NOT NULL)。
添加主键:
ALTER TABLE testalter_tbl MODIFY c INT NOT NULL;
ALTER TABLE testalter_tbl ADD PRIMARY KEY (c)
使用 ALTER 命令删除主键:
ALTER TABLE testalter_tbl DROP PRIMARY KEY;
索引失效
索引失效主要原因有以下:
- 违反最佳最前缀法则
- 在索引列上做操作
- 索引范围条件右边的列
- 使用不等于
- like以通配符开头
- 字符串不加单引号
- or连接
- order by: 违反最左前缀法则,含非索引字段排序,导致文件排序;
- group by: 违反最左前缀法则,含非索引字段,会导致产生临时表;
违反最左前缀法则
在age, weight, grade列创建复合索引:
create index age_weight_grade_idx on staff (age,weight,grade);
如果索引有多列,要遵守最左前缀法则:即查询从索引的最左前列开始并且不跳过索引中的列。
正确姿势:
explain select * from staff where age = 23 and weight = 70 and grade = 100;

错误方式:

这也就是说,我们创建索引一定是基于某种原因或者基于特定的sql语句去做优化,而不是一上来就创建索引。
在索引列上操作
执行计算、函数、自动转换类型等,或导致索引失效。
比如我们执行以下语句,
explain select * from staff where id + 1 = 3;

范围索引右边的列失效
复合索引中,如果有一列使用了范围控制符,则右边的索引会失效。
explain select * from staff where age = 23 and weight > 70 and grade = 100;

使用不等于
使用 ‘!=' 或者’<>' 导致索引失效,全表扫描;
explain select * from staff where age != 1;

like以通配符开头("%abc")
explain select * from staff where name like '%ang';

字符串不加单引号
explain select * from staff where name = 200;

使用or连接
// 少用or 连接
explain select * from staff where age = 23 or grade = 70;

order by
正常使用, 索引有两个作用:排序和查找
explain select * from staff where age = 23 order by age,weight;

违反最左前缀法则或者使用非索引字段会导致索引失效。
explain select * from staff where age = 23 order by age,grade;

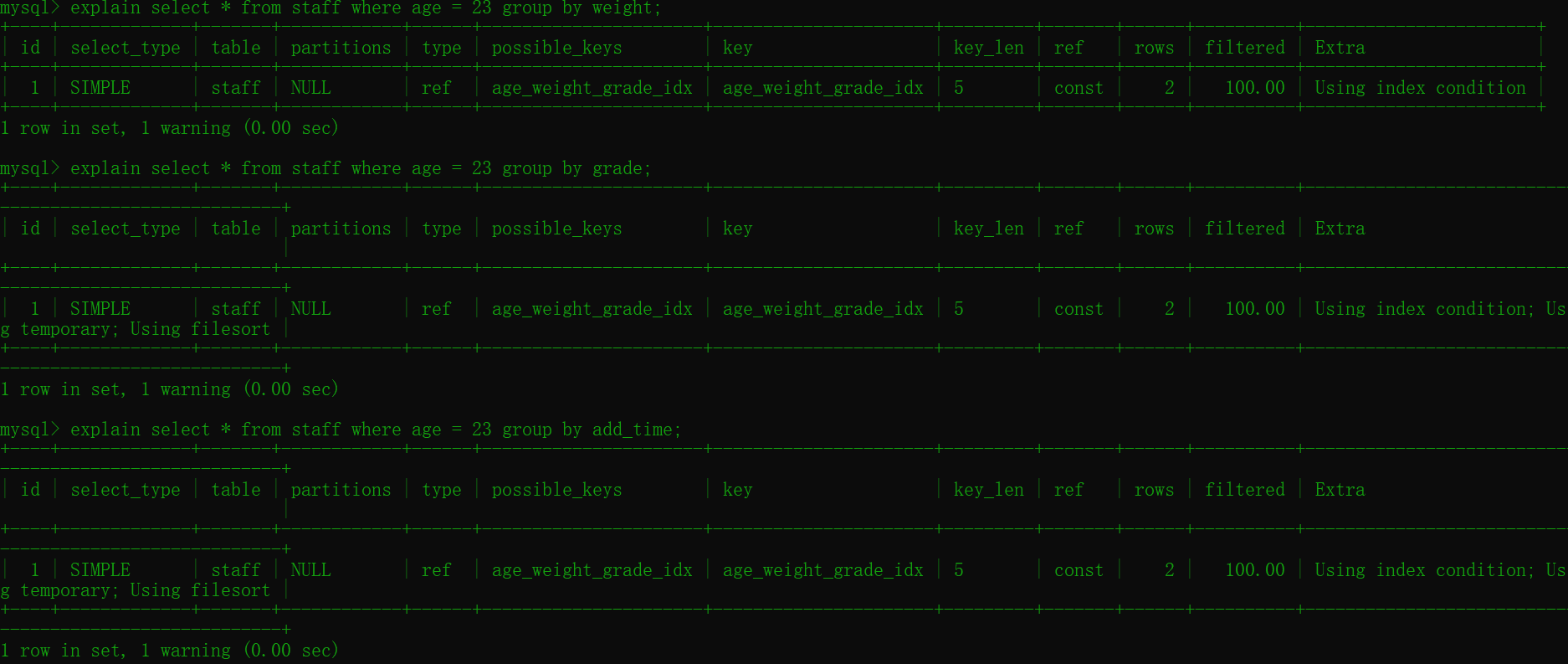
group by
正常使用(分组之前必须排序)
explain select * from staff where age = 23 group by age;

违反最左前缀法则或者使用非索引字段会导致索引失效。
explain select * from staff where age = 23 group by grade;
explain select * from staff where age = 23 group by add_time;
终!!!
参考
MySql 中文文档 - 13.7.5.22 SHOW INDEX 语句 | Docs4dev