前面介绍了自定义格式化输出列表函数printList(),下面再介绍下格式化列表项及列表项的排序。
这里有一组列表数据,记录运动员跑步时间的,要求按照时间大小进行排序。这里每项数据记录的时间格式不一样,无法统一排序。(对字符串排序时,短横线-排在点号前面,点号.在冒号:前面。)

直接排序:
def get_coach_data(filename): try: with open(filename) as fn: data=fn.readline() temp_data=data.strip().split(',') #方法串链 return (sorted(temp_data)) except IOError as ioe: print('File Error: '+str(ioe)) return (None) james=get_coach_data('./data/james.txt') print(james)
结果:

我们可以自定义一个函数sanitize()来处理列表项,统一下格式问题。
1,列表迭代
#列表迭代 def sanitize(time_string): if '-'in time_string: spliter='-' elif ':' in time_string: spliter=':' else: return (time_string) (mins,secs)=time_string.split(spliter) return (mins +'.'+secs) with open('./data/james.txt') as j: data=j.readline() temp_james=data.strip().split(',') james=[] for a in temp_james: james.append(sanitize(a)) print(james)
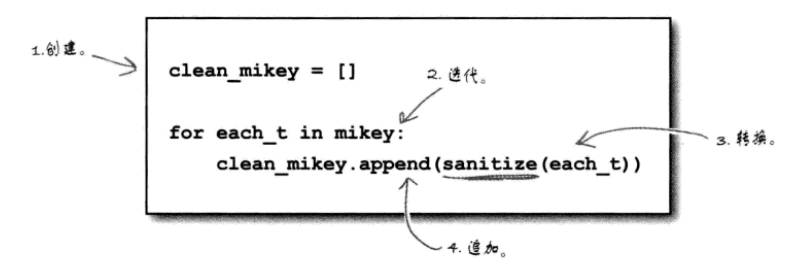
这里我们将一个列表转换为另一个列表要做4件事:
创建一个新列表来存放转换后的数据,迭代处理原列表中的各个数据项,每次迭代时完成转换,将转换后的数据追加到新列表。
2,列表推导
列表推导也可以完成上面的功能(排序)。
#列表推导 def sanitize(time_string): if '-'in time_string: spliter='-' elif ':' in time_string: spliter=':' else: return (time_string) (mins,secs)=time_string.split(spliter) return (mins +'.'+secs) with open('./data/james.txt') as j: data=j.readline() temp_james=data.strip().split(',') james=[sanitize(i) for i in temp_james] #列表推导 print(james)
这里不需要append()方法。
处理好数据后来进行排序,分析所给的数据发现里面有重复项,我们可以用set()来进行处理。
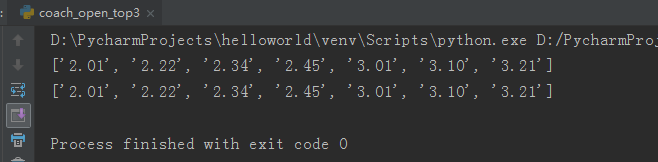
#列表去重 def sanitize(time_string): if '-'in time_string: spliter='-' elif ':' in time_string: spliter=':' else: return (time_string) (mins,secs)=time_string.split(spliter) return (mins +'.'+secs) with open('./data/james.txt') as j: data=j.readline() temp_james=data.strip().split(',') james=[sanitize(i) for i in temp_james] unique_james=[] for j in james:#使用迭代删除重复 if j not in unique_james: unique_james.append(j) print(unique_james[0:3]) #列表分片 print(sorted(set(james)))#使用集合删除重复
运行结果如下:
我们可以将打开文件部门放在一个自定义的函数里:
def get_coach_data(filename): try: with open(filename) as fn: data=fn.readline() temp_data=data.strip().split(',') f_data=[sanitize(d) for d in temp_data] return (f_data) except IOError as ioe: print('File Error: '+str(ioe)) return (None) james=get_coach_data('./data/james.txt')
附:列表数据。