Wireshark提供了两种过滤器:
捕获过滤器:在抓包之前就设定好过滤条件,然后只抓取符合条件的数据包。
显示过滤器:在已捕获的数据包集合中设置过滤条件,隐藏不想显示的数据包,只显示符合条件的数据包。
需要注意的是,这两种过滤器所使用的语法是完全不同的,想想也知道,捕捉网卡数据的其实并不是Wireshark,而是WinPcap,当然要按WinPcap的规则来,显示过滤器就是Wireshark对已捕捉的数据进行筛选。
使用捕获过滤器的主要原因就是性能。如果你知道并不需要分析某个类型的流量,那么可以简单地使用捕获过滤器过滤掉它,从而节省那些会被用来捕获这些数据包的处理器资源。当处理大量数据的时候,使用捕获过滤器是相当好用的。
新版Wireshark的初始界面非常简洁,主要就提供了两项功能:先设置捕获过滤器,然后再选择负责抓包的网卡。由此可见捕获过滤器的重要性。
Wireshark拦截通过网卡访问的所有数据,没有设置任何代理
Wireshark不能拦截本地回环访问的请求,即127.0.0.1或者localhost
显示过滤器:
下面是Wireshark中对http请求的拦截,注意不包含https
http.request.uri contains "product"
链接地址中包含product的请求,不算域名
http.host==shanghai.rongzi.com
过滤域名
http.host contains rongzi.com
更模糊的过滤,可以有多个二级域名
http.content_type =="text/html"
content_type类型过滤
http.request.uri=="/product/"
完整地址过滤,有参数的话就不合适这样过滤
http.request.method=="GET"
tcp.port==80
http && tcp.port==8613 or tcp.port==8090 or tcp.port==8091
ip.dst==42.159.245.203
搜集:
http.host==magentonotes.com http.host contains magentonotes.com //过滤经过指定域名的http数据包,这里的host值不一定是请求中的域名 http.response.code==302 //过滤http响应状态码为302的数据包 http.response==1 //过滤所有的http响应包 http.request==1 //过滤所有的http请求,貌似也可以使用http.request http.request.method==POST //wireshark过滤所有请求方式为POST的http请求包,注意POST为大写 http.cookie contains guid //过滤含有指定cookie的http数据包 http.request.uri==”/online/setpoint” //过滤请求的uri,取值是域名后的部分 http.request.full_uri==” http://task.browser.360.cn/online/setpoint” //过滤含域名的整个url则需要使用http.request.full_uri http.server contains “nginx” //过滤http头中server字段含有nginx字符的数据包 http.content_type == “text/html” //过滤content_type是text/html的http响应、post包,即根据文件类型过滤http数据包 http.content_encoding == “gzip” //过滤content_encoding是gzip的http包 http.transfer_encoding == “chunked” //根据transfer_encoding过滤 http.content_length == 279 http.content_length_header == “279″ //根据content_length的数值过滤 http.server //过滤所有含有http头中含有server字段的数据包 http.request.version == “HTTP/1.1″ //过滤HTTP/1.1版本的http包,包括请求和响应 http.response.phrase == “OK” //过滤http响应中的phrase
捕捉过滤器:
捕捉--》捕捉过滤器
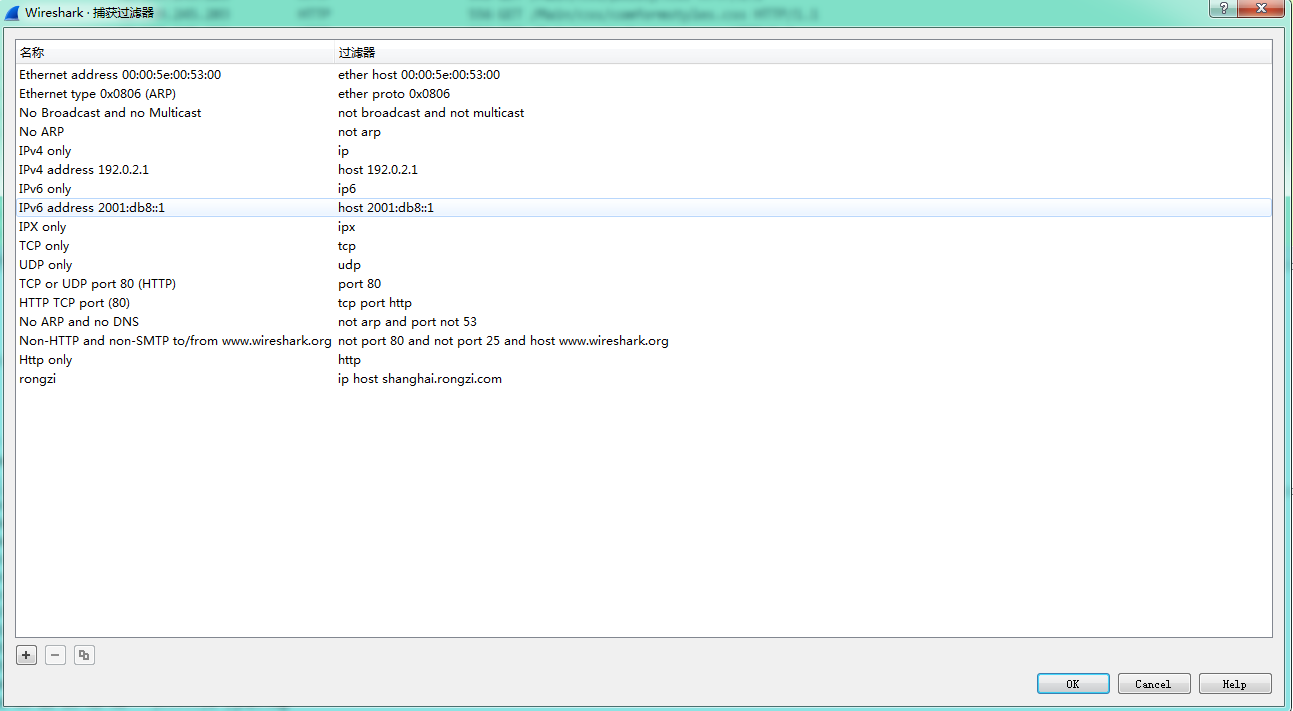
捕捉--》选项--》
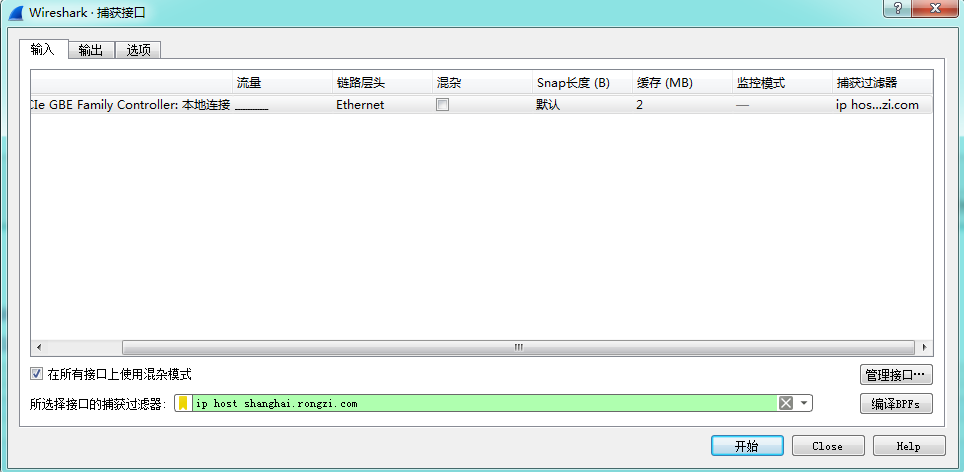
点击开始就开始捕捉数据。
通过测试发现,上面用例是用的域名,但是实际是用的ip,因为很多不同域名,但是相同ip的数据也可以被捕捉到!
具体的规则可以看下面的链接,里面有很多例子。
Wireshark捕捉mysql语句:
mysql.query contains "SELECT"
所有的mysql语句内容进行过滤:
mysql contains "FD171290339530899459"
http://www.cnblogs.com/wangkangluo1/archive/2011/12/19/2293750.html
http://yttitan.blog.51cto.com/70821/1737031
http://yttitan.blog.51cto.com/70821/1734425