基本数据类型补充
set
set集合,是一个无序且不重复的元素集合
#创建
s = {11,22,33,44}#类似字典
s = set()
#转换
l = (11,22,33,44)
s1 = set(l) #iterable
print(s1)
l = [11,22,33,44]
s1 = set(l) #iterable
print(s1)
l = "1234"
s1 = set(l) #iterable
print(s1)
{33, 11, 44, 22}
{33, 11, 44, 22}
{'3', '2', '1', '4'}
set的功能:
"""add"""
#add--添加一个元素
set = {11,22,33}
se = set
print(se)
se.add(44)
print(se)
输出结果:
{33, 11, 22}
{33, 11, 44, 22}
"""different"""
#different--(a.different(b) => a中存在,b中不存在的)
se = {11,22,33}
be = {22,55}
#找se中存在,be中不存在的集合,并将其赋值给新变量
temp = se.difference(be)
print(temp)
temp = be.difference(se) #be中存在,se中不存在的
print(temp)
输出结果:
{33, 11}
{55}
#difference_update
#找se中存在,be中不存在的集合,更新自己
ret = se.difference_update(be)
print(se)
print(ret)
输出结果:
{33, 11}
None
"""intersection"""
#取交集,并赋值给新值
se = {11,22,33}
be = {22,33,44}
ret = se.intersection(be)
print(ret)
#取交集,并更新自己
se.intersection_update(be)
print(se)
输出结果:
{33, 22}
{33, 22}
"""discard,remove"""
se = {11,22,33}
#discard--移除指定的元素
se.discard(11)
print(se)
se.discard(44)#不会宝座
print(se)
#se.remove(44)会报错
"""is..."""
#isdisjoint--判断是否有交集
#有交集是Flase,没有交集是True
ret = se.isdisjoint(be)
print(ret)
#issubset--a.issubset(b),b是不是a子序列
#issuperset--a.issuperset(b),b是不是a的父序列
se = {11,22,33,44}
be = {11,22}
ret = se.issubset(be)
print(ret)
ret = se.issuperset(be)
print(ret)
"""pop"""
#pop--移除元素
print(se)
ret = se.pop()
print(ret)
print(se)
#因为序列内部是无序排列的,所以pop移除了33
输出结果
{33, 11, 44, 22}
33
{11, 44, 22}
"""symmetric"""
#对称差集,a.symmetric_difference.b,把a,b各自存在的取出来,赋值给新变量
se = {11,22,33,44}
be = {11,22,77,55}
ret = se.symmetric_difference(be)
print(ret)
se.symmetric_difference_update(be)
print(se)
输出结果
{33, 44, 77, 55}
{33, 44, 77, 55}
"""union"""
#union--并集
se = {11,22,33,44}
be = {11,22,77,55}
ret = se.union(be)
print(ret)
"""update"""
update--更新
se = {11,22,33,44}
be = {11,22,77,55}
se.update("ciri")
print(se)
se.update(be)
print(se)
输出结果
{33, 'r', 'c', 11, 44, 'i', 22}
{33, 'r', 'c', 11, 44, 77, 'i', 22, 55}
练习
old_dict = {
"#1":11,
"#2":22,
"#3":100,
}
new_dict = {
"#1":33,
"#4":22,
"#7":100,
}
# 1,new和old里面,key相同的,就把new对应的值更新到old里面
# 2,若果new的keys存在,old中不存在,就在old中添加
# 3,若果old的keys存在,new中不存在,就在old中删除
# 最后只输出old就行,new不用管
提示:所有的判断都是根据keys来判断的
old_keys = old_dict.keys() new_keys = new_dict.keys() old_set = set(old_keys) new_set = set(new_keys) old_set里存在,new_keys里不存在的--删除的 del_set = old_set.different(new_set) new里存在,old里不存在--添加的 add_set = new_set.different(old_set) keys值相同更新--要更新的 update_set = old_set.intersection(new_set)
深浅拷贝
注:不同数据类型在内存中的存址方式
li = [11,22,33,44]
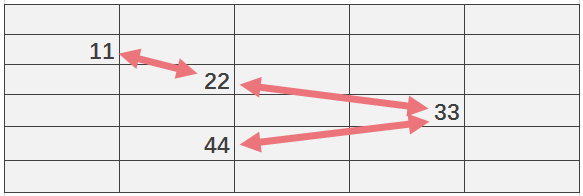
因为列表的数量无法确定所以说,在内存中的地址不可能是连续的,因为不知道要预留多大的空间
所以有了链表的概念:就是每一个元素的内存地址中,记录着上一个和下一个元素的内存地址的位置
如图所示:
在Java、C#里,有个数组的概念,数组的个数是不能改变的,所以在内存中的地址是连续的
因为python是C写的,所以python里的字符串也是用C写的,C当中的字符串就是字符数组
例如:ciri——在内存中的地址就是固定的,不能修改,若修改就是生成新的字符串

总结:
对于字符串(str)和整形(int)而言,一次性创建,不能被修改,只要修改就是在创建。
对于其他(如列表、字典):相当于C语言里的链表,记录着上一个和下一个元素的内存地址的位置
图示:
1、修改字符串时,内存中的操作
a = ciri a = deborah

注:此时“ciri”仍然在内存中
2、修改列表中的字符串时,内存中的操作
li = ["ciri","prime","deborah"] li[0] = "cirila"
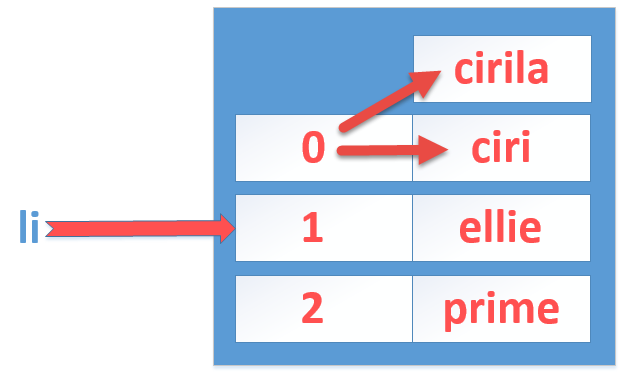
注:此时仅仅更改索引 [0] 对应的元素的内存地址,此时“ciri”仍然在内存中
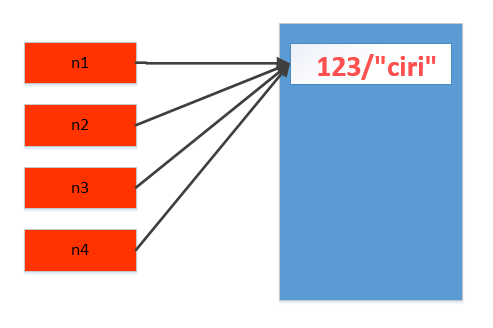
一、数字和字符串
对于 数字 和 字符串 而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
>>> import copy >>> n1 =123 >>> id(n1) 44592192L #赋值 >>> n2 = n1 >>> id(n2) 44592192L #浅拷贝 >>> n2 = copy.copy(n1) >>> id(n2) 44592192L #深拷贝 >>> n3 = copy.deepcopy(n1) >>> id(n3) 44592192L
二、其它基本数据类型
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
1、赋值
赋值,只是创建一个变量,该变量指向原来内存地址,如:
n1 = {"k1": "ciri", "k2": 123, "k3": ["prime", 456]}
n2 = n1

2、浅拷贝
浅拷贝,在内存中只额外创建第一层数据
>>> import copy
>>> n1 = {"k1": "ciri", "k2": 123, "k3": ["prime", 456]}
#浅拷贝
>>> n2 = copy.copy(n1)
#第一层
>>> id(n1),id(n2)
(48245208L, 48250120L) #内存地址不相同
#第二层
>>> id(n1["k3"]),id(n2["k3"])
(48216584L, 48216584L) #内存地址相同
#最后一层
#因为"k1""k2"后面是个字符,而不是字典,列表,元组之类的,所以也是最后一层
>>> id(n1['k2']),id(n2['k2'])
(46361664L, 46361664L) #内存地址相同
>>> id(n1['k3']),id(n2['k3'])
(48216584L, 48216584L) #内存地址相同
>>> id(n1['k3'][0]),id(n2['k3'][0])
(48457168L, 48457168L) #内存地址相同

3、深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
>>> import copy
>>> n1 = {"k1": "ciri", "k2": 123, "k3": ["prime", 456]}
#深拷贝
>>> n2 = copy.deepcopy(n1)
#第一层
>>> id(n1),id(n2)
(44659576L, 50021240L) #内存地址不相同
#第二层
>>> id(n1['k3']),id(n2['k3'])
(48216584L, 48215368L) #内存地址不相同
#最后一层
#因为"k1","k2"后面是个字符,而不是字典,列表,元组之类的,所以也是最后一层
>>> id(n1['k1']),id(n2['k1'])
(48457048L, 48457048L) #内存地址相同
>>> id(n1['k2']),id(n2['k2'])
(46361664L, 46361664L) #内存地址相同
>>> id(n1['k3'][0]),id(n2['k3'][0])
(50019824L, 50019824L) #内存地址相同

三元运算
三元运算(三目运算),是对简单的条件语句的缩写。
# 书写格式 result = 值1 if 条件 else 值2 # 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2”赋值给result变量 name = "ciri" if 1==1 else "prime" #这里的1==1是条件 print(name) #输出结果:ciri
函数
一、背景
在学习函数之前,一直遵循:面向过程编程,即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处,如下:
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
腚眼一看上述代码,if条件语句下的内容可以被提取出来公用,如下:
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
对于上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
函数式编程最重要的是增强代码的重用性和可读性
二、定义和使用
def 函数名(参数):
...
函数体
...
返回值
函数的定义主要有如下要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。
1、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
以上要点中,比较重要有参数和返回值:
def email():
print("我要发邮件了")
return"123"
ret = email()
print(ret)
#函数return后面是什么值,ret等于返回值
#如果没有return,则会返回None
2、参数
函数的有三中不同的参数:
- 普通参数
#定义函数 # name 叫做函数func的形式参数,简称:形参 def func(name): print name #执行函数 # 'ciri' 叫做函数func的实际参数,简称:实参 func('ciri') - 默认参数
def drive(p,name = "prime"): temp = name + "去英国" return temp,p ret = drive(666,"ciri") print(ret) #输出结果:('ciri去英国', 666) ret = drive(666) print(ret) #输出结果:('prime去英国', 666) 注:默认参数需要放在参数列表最后 - 动态参数
为什么需要动态参数?def f1(a): print(a,type(a)) f1(123) f1(123,456) #出错了,只能传一个参数 #所以需要一个动态参数,来动态调整大小,来接收参数动态参数的类型
#动态参数1——默元组类型 def f1(*a): print(a,type(a)) f1(123,456,[7,8,9],"alex") #输出结果:(123, 456, [7, 8, 9], 'alex') <class 'tuple'> #动态参数2——默认字典类型 def f1(**a): print(a,type(a)) f1(k1=123,k2=456,k3=[7,8,9]) #输出结果: {'k1': 123, 'k2': 456, 'k3': [7, 8, 9]} <class 'dict'> #动态参数3——1,2结合,万能参数 #*a,**aa = > 顺序不能变 def f1(*a,**aa): print(a,type(a)) print(aa,type(aa)) f1(k1=123,k2=456,k3=[7,8,9]) """ 输出结果: () <class 'tuple'> {'k1': 123, 'k2': 456, 'k3': [7, 8, 9]} <class 'dict'> """ f1(123,456,k1=789) """ 输出结果: (123, 456) <class 'tuple'> {'k1': 789} <class 'dict'> """如何使列表中的参数一个一个传入,而不是作为一个整体传入?
#一般的写法一个*是*args.两个**是**kwargs def f1(*args): print(args,type(args)) li = [11,22,33,44] f1(li) #输出结果:([11, 22, 33, 44],) <class 'tuple'> #列表li是元组的第一个元素 f1(*li) #输出结果:(11, 22, 33, 44) <class 'tuple'> #想要输出元组,列表就需要在实参前面加个*如何使字典中的参数,自己进行导入?
def f1(**kwargs): print(kwargs,type(kwargs)) dic = {"k1":123,"k2":456} #f1(dic) 会报错因为需要两个参数 f1(k1=dic) #输出结果:{'k1': {'k1': 123, 'k2': 456}} <class 'dict'> #可以看出,字典dic中的内容,作为一个整体进行传入
f1(**dic) #输出结果:{'k1': 123, 'k2': 456} <class 'dict'>
#可以看出传对字典中的每一个键值对,分别进行了传入
全局变量和局部变量
不成文的规定,全局变量都大写,局部变量都小写
全局变量的特性
def func1():
a = 123
print(a)
#print(a) 输出不了的,会报错。因为a只存在与函数当中
p = 123
#全局变量,都可以使用,但是不能修改
p = "ciri"
def f1():
a = 123
p = 456 #这么写就相当于又创建了一个局部变量,和上面的全局变量没有关系
print(a,p)
f1()
print(p)
# 输出结果:
# 123 456
# ciri #值并没有被函数修改
修改全局变量的方法
p = "ciri"
def f1():
a = 123
global p #加上global就可以修改
p = 456
print(a,p)
f1()
print(p)
# 输出结果:
# 123 456
# 456
练习题
练习题
1、简述普通参数、指定参数、默认参数、动态参数的区别
1.普通参数--形参实参相同 2.指定参数--顺序可以打乱 3.默认参数--默认参数要放到最后面 4.动态参数--*args,转换成元组 **kwargs转换成字典
2、写函数,计算传入字符串中【数字】、【字母】、【空格] 以及 【其他】的个数
def func1(s):
al_num = 0
spance_num = 0
digit_num = 0
others_num = 0
for i in s:
if i.isalpha():
al_num += 1
elif i.isdigit():
digit_num += 1
elif i.isspace():
spance_num += 1
else:
others_num += 1
print("字母",al_num,"数字",digit_num,"空格",spance_num,"其它",others_num,)
return
s = "123asd asd asddqw3213;';'"
func1(s)
3、写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5。
def obj_len(arg):
#如何判断传入的参数是哪一类
if isinstance(arg,str) or isinstance(arg,list)or isinstance(arg,tuple):
if len(arg) > 5:
return True
else:
return False
return False
temp = "123456wqer"
ret = obj_len(temp)
print(ret)
4、写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空格。
def has_space(args):
for c in args:
ret = True #相当于设置了一个默认的返回值
for c in args:
if c.isspace():
ret = False
break #一旦有空格,就跳出循环
return ret
#Tips:设置一个默认的返回值,如果符合判断就修改返回值
result = has_space("asdflkj zsaf;';';")
print(result)
5、写函数,检查传入列表的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
def f2(args):
if len(args) > 2:
return args[0:2]
return args
#若果大于2把前两个元素拿出来
li = ["11","22","33","qwer"]
ret = f2(li)
print(ret)
6、写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。
def f4(args):
ret = []
for i in range(len(args)): #输出所有的索引
if i % 2 == 1:
ret.append(args[i])
else:
pass
return ret
li = [11,22,33,44,55,66,77]
r = f4(li)
print(li)
print(r)
7、写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
dic = {"k1": "v1v1", "k2": [11,22,33,44]}
PS:字典中的value只能是字符串或列表
#方法一:不修改dic的值
def f5(args):
ret = {}
for key,value in args.items():
if len(value) > 2:
ret[key] = value[0:2]
else:
ret[key] = value
return ret
dic = {"k1": "v1v1", "k2": [11,22,33,44]}
r = f5(dic)
print(r)
#方法二:修改dic的值
def f5(args):
for key,value in args.items():
if len(value) > 2:
args[key] = value[0:2]
else:
args[key] = value
return args
dic = {"k1": "v1v1", "k2": [11,22,33,44]}
f5(dic)
print(dic)
8、写函数,利用递归获取斐波那契数列中的第 10 个数,并将该值返回给调用者