一、 while循环
1、基本形式
1 while 条件: 2 循环体 3 # 判断条件是否为真,如果真,执行代码块.然后再次判断条件是否为真.如果真继续执行代码块...直到条件变成了假.循环退出
4 ps:死循环 5 while True: 6 print('hello world')
2、while中的计数
1 count = 0
2 while count < 100: # count作用计数,控制循环范围
3 count = count + 1
4 print(count)
3、while 累加操作
1 # 计算 1+...100的和
2
3 count = 1
4 sum = 0
5 while count <= 100:
6 sum += count
7 count += 1
8 print(sum)
4、while...else
1 while 条件:
2 循环体
3 else: #只有执行条件为假的时候才会执行else后语句
4 循环体
5
6 index = 1
7 while index < 11:
8 if index == 8:
9 break #如果循环通过break退出那么while后面的else将不会执行
10 else:
11 print(index)
12 index += 1
13 else:
14 print('hello')
5、break 和 continue/exit(0)
<1>break
结束当前的本层循环
<2>continue
结束当前本次循环,继续下一次循环
<3>exit(0)
结束整个程序
二、 格式化输出
print("我叫%s, 我喜欢干%s, 我今年%d岁了" % (name, hobby, age)) # %d 必须占位数字
%s,字符串占位符可以接收所有数据类型, 输出%则需 %%
s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
o,将整数转换成 八 进制表示,并将其格式化到指定位置
x,将整数转换成十六进制表示,并将其格式化到指定位置
d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
F,同上
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
%,当字符串中存在格式化标志时,需要用 %%表示一个百分号 注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式
1 >>> print('%f' % 1.11) # 默认保留6位小数
2 1.110000
3 >>> print('%.1f' % 1.11) # 取1位小数
4 1.1
5 >>> print('%e' % 1.11) # 默认6位小数,用科学计数法
6 1.110000e+00
7 >>> print('%.3e' % 1.11) # 取3位小数,用科学计数法
8 1.110e+00
9 >>> print('%g' % 1111.1111) # 默认6位有效数字
10 1111.11
11 >>> print('%.7g' % 1111.1111) # 取7位有效数字
12 1111.111
13 >>> print('%.2g' % 1111.1111) # 取2位有效数字,自动转换为科学计数法
14 1.1e+03
三、基本运算符
1、算术运算符
2、比较运算符
3、逻辑运算符
( ) > not > and > or
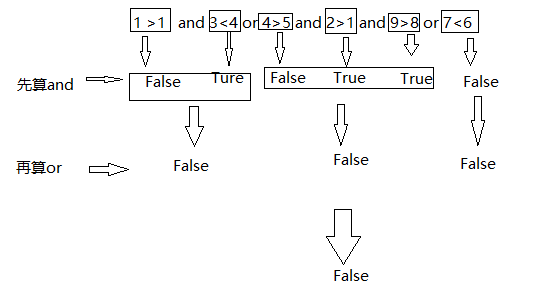
1 1 or 2 and 3 # 先计算and再or
2 结果:1
3
4 0 or 1 # 1
5 0 or 2 # 2
6 1 or 2 # 1
7 1 or 2 # 1
8
9 如果x 为 0,则返回y 否则返回x
10 and 和 or 相反
4、赋值运算符
5、成员运算符
6、身份运算符
7、位运算符
四、 编码
1、ASCII码
最多只能用 8 位(1byte)来表示 2^8 = 256 但ASCII只能表示英文.ASCII只用了其中的7位, 则ASCII的二进制表示最前面的数位是 0
2、GBK码
对ASCII的扩充,16位(2byte)主要包含中日韩文,英文(对ASCII的兼容)
3、Unicode(万国码)
用32位(4byte)兼容各个国家的编码,浪费空间
4、UTF-8(最小单位8bit) UTF-16 UTF-32
可变长度的Unicode,本质是Unicode. 英文 8位(1byte) 欧洲 16位(2byte) 中文 24位(3byte)
五、 in not in
判断XXX字符串是否在XXXXXX字符串中
1 content = input('请输入评论:')
2 if '金三胖' in content:
3 print('含有非法字符!')
4 else:
5 print('ok')