一、hive入门手册
1.1数据仓库概念
 对历史数据变化的统计,从而支撑企业的决策。比如:某个商品最近一个月的销量,预判下个月应该销售多少,从而补充多少货源。 1.2传统数据仓库面临的挑战 (1)无法满足快速增长的海量数据存储需求 (2)无法有效处理不同类型的数据 (3)计算和处理能力不足 1.3 Hive介绍
对历史数据变化的统计,从而支撑企业的决策。比如:某个商品最近一个月的销量,预判下个月应该销售多少,从而补充多少货源。 1.2传统数据仓库面临的挑战 (1)无法满足快速增长的海量数据存储需求 (2)无法有效处理不同类型的数据 (3)计算和处理能力不足 1.3 Hive介绍 

 Hbase支持快速的交互式的大数据应用 pig,Hive支持批量式的数据分析业务 1.4 Hive与传统数据库的对比
Hbase支持快速的交互式的大数据应用 pig,Hive支持批量式的数据分析业务 1.4 Hive与传统数据库的对比  1.5 Hive在企业中的部署与应用
1.5 Hive在企业中的部署与应用 
2.Hive系统架构
 Microsoft推出的ODBC(Open Database Connectivity)技术 [1] 为异质数据库的访问提供了统一的接口 JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。 CIL (Common Intermediate Language) 公共中间语言
Microsoft推出的ODBC(Open Database Connectivity)技术 [1] 为异质数据库的访问提供了统一的接口 JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。 CIL (Common Intermediate Language) 公共中间语言
3.Hive工作原理
3.1 SQL转换为MapReduce作业的基本原理

 3.2 Hive中SQL查询转换MapReduce作业的过程
3.2 Hive中SQL查询转换MapReduce作业的过程 


4.Hive HA基本原理

5.Impala
5.1 Impala介绍  5.2 Impala系统架构
5.2 Impala系统架构 
 5.3 Impala查询执行过程
5.3 Impala查询执行过程 
 5.4 Impala和Hive的区别
5.4 Impala和Hive的区别 

6.Hive编程实践
6.1 Hive的安装和配置

6.2 Hive的基本数据类型


6.3 Hive的基本操作
1.create:创建数据库、表、视图
创建数据库 (1)创建数据库hive hive>create database hive; (2)创建数据库hive,因为hive已经存在,所以会抛出异常,加上if not exits 关键字,则不会抛出异常 hive>create database if not exits hive;
创建表 (1)在hive数据库中创建表usr,含三个属性id,name,age hive>use hive; hive>create table if not exists usr(id bigint,name string,age int); (2)在hive数据库中创建表usr,含三个属性id,name,age,存储路径为“/usr/local/hive/warehouse/hive/usr” hive>create table if not exits hive.usr(id bigint,name string,age int) >location '/usr/local/hive/warehouse/hive/usr';
创建视图 (1)创建视图little_usr,只包含usr表中id,age属性 hive>create view little_usr as select id,age from usr;
2.show:查看数据库、表、视图 查看数据库 (1)查看hive中包含的所有数据库
hive>show databases;
(2)查看hive中以h开头的所有数据库
hive>show databases like 'h.*';
查看表和视图 (1)查看数据库hive中所有的表和视图
hive>use hive;
hive>show tables;
(2)查看数据库hive中以u开头的所有表和视图
hive>show tables in hive like 'u.*';
3.load:向表中装在数据 (1)把目录‘/usr/local/data’下的数据文件中的数据装载进usr表并覆盖原有数据
hive>load data local inpath '/usr/local/data' overwrite into table usr;
(2)把目录‘/usr/local/data’下的数据文件中的数据装载进usr表不覆盖原有数据
hive>load data local inpath '/usr/local/data' into table usr;
(3)把分布式系统文件目录‘hdfs://master_server/usr/local/data’下的数据文件数据装载进usr表并覆盖原有数据
hive>load data local inpath ‘hdfs://master_server/usr/local/data’
>overwrite into table usr;
4.insert:向表中插入数据或从表中导出数据 (1)向表中usr1中插入来自usr表中的数据并覆盖原有数据
hive>insert overwrite table usr1
>select * from usr where age=10;
(2)向表中usr1中插入来自usr表中的数据并追加在原有数据后
hive>insert into table usr1 >select*from usr >where age=10;
6.4 Hive的应用实例(wordCount)


6.5 Hive的优势
WordCount算法在MapReduce中的编程实现和Hive中编程实现的主要不同点:
1.采用hive实现WordCount算法需要编写较少的代码量 在MapReduce中,WordCount类由63行Java代码编写而成 在hive中只需要编写7行代码
2.在MapReduce的实现中,需要进行编译生成jar文件来执行算法,而在hive中不需要 hiveQL语句的最终实现需要转换为MapReduce任务来执行,这都是由hive框架自动完成的,用户不需要了解具体实现细节。
7.Hive的几种数据模型
内部表 (Table 将数据保存到Hive 自己的数据仓库目录中:/usr/hive/warehouse) 外部表 (External Table 相对于内部表,数据不在自己的数据仓库中,只保存数据的元信息) 分区表 (Partition Table将数据按照设定的条件分开存储,提高查询效率,分区-----> 目录) 桶表 (Bucket Table本质上也是一种分区表,类似 hash 分区 桶 ----> 文件) 视图表 (视图表是一个虚表,不存储数据,用来简化复杂的查询) 注意:内部表删除表后数据也会删除,外部表数据删除后不会从hdfs中删除
1. 内部表/管理表
每一个Table在Hive中都有一个相应的目录存储数据 所有的Table数据都存储在该目录
create table if not exists aiops.appinfo (
appname string,
level string,
leader string,
appline string,
dep string,
ips array<string>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
COLLECTION ITEMS TERMINATED BY ',';
# 自定义文件和记录格式
## 使用create table创建表,最后使用stored as sequencefile保存成sequence格式[默认是text格式]
# 数据库授权
hive> grant create on database dbname to user hadoop;
# 导入数据(本地导入和hdfs导入)
hive> load data inpath 'hdfs://hdfs-name/sure.csv' overwrite into table aiops.appinfo;
load data local inpath '/home/hdfs/online_state1' overwrite into table online_state PARTITION (end_dt='99991231');
# 查看表结构
hive> describe extended bgops;
hive> describe bgops;
# 修改列名
## 这个命令可以修改表的列名,数据类型,列注释和列所在的位置顺序,FIRST将列放在第一列,AFTER col_name将列放在col_name后面一列
hive> ALTER TABLE aiops.appinfo CHANGE hostnum ipnum int comment 'some 注释' AFTER col3;
# 修改表结构
ALTER TABLE aiops.appinfo replace columns (appname string,level string,leader string,appline string,dep string,ips array<string>);
ALTER TABLE appinfo replace columns (appname string,appline string,level string,leader string,dep string,idcnum int,idcs array<string>,hostnum int,ips array<string>);
## 增加表的列字段(默认增加到最后一列,可以使用change column 来调整位置)
hive> alter table appinfo add columns (appclass string comment 'app_perf_class');
# 导出表查询结果(会将结果导出到testoutput目录下)
hive> insert overwrite local directory './testoutput'
> row format delimited fields terminated by " "
> select ip,appname,leader from appinfo LATERAL VIEW explode(ips) tmpappinfo AS ip;
2.外部表的使用场景
原始日志文件或同时被多个部门同时操作的数据集,需要使用外部表 如果不小心将meta data删除了,HDFS上的数据还在,可以恢复,增加了数据的安全性 注意:使用insert插入数据时会产生临时表,重新连接后会表会小时,因此大批量插入数据时不建议用insert tips1:在hdfs的hive路径下以.db结尾的其实都是实际的数据库 tips2:默认的default数据库就在hive的家目录
3. 分区表
注意:分区表通常分为静态分区表和动态分区表,前者需要导入数据时静态指定分区,后者可以直接根据导入数据进行分区。分区的好处是可以让数据按照区域进行分类,避免了查询时的全表扫描。
CREATE EXTERNAL TABLE if not exists aiops.tmpOnline(ip string, status string, .... ) PARTITIONED BY ( dt string); # 导入数据到静态分区表中(需要注意的是数据中没有dt字段) load data local inpath '/home/hdfs/tmpOnline' overwrite into table aiops.tmpOnline PARTITION (dt='99991231'); # 动态分区表的使用(动态分区和静态分区表的创建时没有区别的) # 注意:hive默认没有开启动态分区,需要进行参数修改 # 使用动态分区的记录中,必须在指定位置包含动态分区的字段才能被动态分区表识别 hive>set hive.exec.dynamic.partition.mode=nonstrict; hive> insert overwrite table aiops.tmpOnline partition(dt) select ip,appname,....,from_unixtime(unix_timestamp(),'yyyyMMdd') as dt from table; # 手动添加分区 alter table tablename add partition (dt='20181009'); # 删除分区,数据也会删除(所以一般会使用外部分区表?) ## 注意:如果数据有变动,是无法将数据load到同一个时间分区的记录的 alter table tablename drop partition (dt='20181009'); # 查询分区表没有加分区过滤,会禁止提交这个任务(strict方式每次查询必须制定分区) set hive.mapred.mode = strict|nostrict;
注意:在外部分区表中,如果将表删除了,重建表后只需要将分区加载进来即可恢复历史相关分区的数据。 多重分区的使用
# 创建多重分区表
create table log_m (
id int,
name string,
age int
)
partitioned by (year string,month string,day string)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '
';
# 插入数据
insert into table log_m partition (year='2018',month='10',day='10') values(1,'biaoge',24);
insert into table log_m partition (year='2018',month='10',day='09') values(2,'bgbiao',25);
hive> show partitions log_m;
OK
year=2018/month=10/day=09
year=2018/month=10/day=10
Time taken: 0.055 seconds, Fetched: 2 row(s)
hive>
# 多重动态分区
# 好像动态分区表不能直接load data
hive> insert into table log_m partition(year,month,day) values(3,'xuxuebiao',28,'2016','09','10');
hive> show partitions log_m;
OK
year=2016/month=09/day=10
year=2018/month=10/day=09
year=2018/month=10/day=10
# 查询分区数据
hive> select * from log_m where year = '2018';
OK
2 bgbiao 25 2018 10 09
1 biaoge 24 2018 10 10
2 bgbiao 25 2018 10 10
4、Hive的复杂数据类型的使用
注意:Hive之所以能在大数据领域比较受欢迎,很大一部分原因在于相比其他SQL类存储系统支持更加复杂的数据类型
map: (key1, value1, key2, value2, ...) 一些列的k/v对 map<int,string...> struct: (var1,var2,var3...) 不同类型的值的组合 structabc:string,def:int... array: (var1,var2,var3...) 一种类型的值的组合 array<string...> uniontype: (string,map<>,struct<>,array<>)
注意:在创建hive表时可根据需要导入的数据进行类型识别并创建适合的数据类型 hive数据类型数据识别标识:
字段分割标识含义FIELDS TERMINATED BY表示字段与字段之间的分隔符COLLECTION ITEMS TERMINATED BY表示一个字段中各个item之间的分隔符[可用于array和struct类型]MAP KEYS TERMINATED BY表示map类型中的key/value的分隔符[可用于map类型]
# 创建表
create table union_testnew(
foo uniontype<int, double, string, array<string>, map<string, string>>
)
row format delimited
collection items terminated by ','
map keys terminated by ':'
lines terminated by '
'
stored as textfile;
# 数据准备
[root@master wadeyu]# vim union_test.log
1 0,1
2 1,3.0
3 2,world
4 3,wade:tom:polly
5 4,k1^Dv1:k2^Dv2
# 导入数据
hive (badou)> load data local inpath './union_test.log' overwrite into table union_testnew;
# 查询数据
hive (badou)> select * from union_testnew;
OK
union_testnew.foo
{0:1}
{1:3.0}
{2:"world"}
{3:["wade","tom","polly"]}
{4:{"k1":"v1","k2":"v2"}}
Time taken: 0.225 seconds, Fetched: 5 row(s)
(1)array类型的使用 1.1 array类型的基本使用 类型结构: array<struct> 例如:array<string>,array<int> 数据表示: 例如:[string1,string2],[int1,int2]
# 原始文件
bmpjob P2 bgops 服务研发组 10.0.0.212,10.0.0.225,10.0.0.243,10.0.55.31
# 创建数据库
hive> create table appinfo
> (
> appname string,
> level string,
> leader string,
> dep string,
> ips array<string>)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ' '
> COLLECTION ITEMS TERMINATED BY ',';
# 加载数据到hive
hive> load data inpath 'hdfs://hdfs-name/aiops/wander/appinfo.txt' overwrite into table appinfo;
Loading data to table test.appinfo
Table test.appinfo stats: [numFiles=1, numRows=0, totalSize=32568, rawDataSize=0]
OK
# 查询相关数据
hive> select * from appinfo limit 1;
OK
bmpjob P2 bgops 服务研发组 ["10.0.0.212","10.0.0.225","10.0.0.243","10.0.55.31"]
hive> select appname,leader,ips[0] from appinfo limit 1;
OK
bmpjob bgops 10.0.0.212
1.2array与struct类型数据转换处理 背景
使用array结构时,一个字段中通常会有多个值,这个时候通常情况下是需要对某个值进行过滤的,一般情况下会使用lateral view结合UDTF(User-Defined Table-Generating Functions)进行过滤。而UDTF为了解决一行输出多行的需求,典型的就是explode()函数。 lateral view语法结构
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)
array和struct转字符串
# 借用split函数将array<string>结构内容转换为以","分割的字符串 select split(array<string>,',') from tablename
hive使用explode()函数进行行转列 语法:lateral view explode(col3) col3 as name explode(ARRAY): 列表中的每个元素生成一行 explode(MAP): map中每个key-value对,生成一行,key为一列,value为一列
hive> select ip,appname from appinfo LATERAL VIEW explode(ips) tmpappinfo AS ip limit 2; 10.0.0.212 bmpjob 10.0.0.225 bmpjob
hive使用concat_ws()函数进行列转行
# 借用concat_ws()和collect_set()函数进行相同列的重复数据转换
# collect_set()函数可以将相关列合并成array<>类型;concat_ws()函数会将array<>类型根据指定的分隔符进行合并
## 示例数据
hive> select * from tmp_jiangzl_test;
tmp_jiangzl_test.col1 tmp_jiangzl_test.col2 tmp_jiangzl_test.col3
a b 1
a b 2
a b 3
c d 4
c d 5
c d 6
## 对于以上数据,我们可以将col3列根据列col1和col2进行合并
hive> select col1,col2,concat_ws(',',collect_set(col3)) from tmp_jiangzl_test group by col1,col2;
col1 col2 _c2
a b 1,2,3
c d 4,5,6
(2)struct<>类型的使用 数据定义: struct<name:STRING, age:INT> 数据表示: biaoge:18
# 元数据格式
1,zhou:30
2,yan:30
3,chen:20
# 相关数据库结构
hive> create table test-struct(id INT, info struct<name:STRING, age:INT>)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY ':';
# 加载数据
hive> LOAD DATA LOCAL INPATH '/home/work/data/test5.txt' INTO TABLE test-struct;
# 查询相关数据
hive> select info.age from test-struct;
Total MapReduce jobs = 1
......
Total MapReduce CPU Time Spent: 490 msec
OK
30
30
map<>类型的使用 数据定义: map<string,int> 数据表示: key:value,key:value...
# 原始数据格式
1 job:80,team:60,person:70
2 job:60,team:80
3 job:90,team:70,person:100
# map结构的表结构创建
hive> create table employee(id string, perf map<string, int>)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ' '
> COLLECTION ITEMS TERMINATED BY ','
> MAP KEYS TERMINATED BY ':';
# 数据导入
hive> LOAD DATA LOCAL INPATH '/home/work/data/test7.txt' INTO TABLE employee;
# 数据查询
hive> select perf['person'] from employee;
Total MapReduce jobs = 1
......
Total MapReduce CPU Time Spent: 460 msec
OK
70
NULL
# 使用explode()函数查询
hive> select explode(perf) as (p_name,p_score) from employee limit 4;
OK
job 80
team 60
person 70
# 使用explode()和lateral view结合查询
hive> select id,p_name,p_score from employee lateral view explode(perf) perf as p_name,p_score limit 3;
OK
1 job 80
1 team 60
1 person 70
# 使用size()函数查看map结构中的键值对个数[也可查看array中的元素个数]
hive> select size(perf) from employee
3
2
3
8.总结
本章详细介绍了hive的基本知识。hive是一个构建与Hadoop顶层的数据仓库工具,主要用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。hive在某种程度上可以看做是用户编程接口,本身不存储和处理数据,依赖HDFS存储数据,依赖MapReduce处理数据。 hive支持使用自身提供的命令行CLI、简单网页HWI访问方式,及通过Karmasphere、Hue、Qubole等工具的外部访问 hive在数据仓库中的具体应用中,主要用于报表中心的报表分析统计上。在Hadoop集群上构建的数据仓库由多个hive进行管理,具体实现采用hive HA原理的方式,实现一台超强“hive”。 Impala作为新一代开源大数据分析引擎,支持实时计算,并在性能上比hive高出3~30倍,甚至在将来的某一天可能会超过hive的使用率而成为Hadoop上最流行的实时计算平台。
本章最后以单词统计为例,详细介绍了如何使用hive进行简单编程。
二、hive高级手册
1、Hive的常用函数
注意:使用show functions可以查看hive支持的相关函数
(1). hive常用函数列表
 注意:聚合方法通常需要和group by语句组合使用
注意:聚合方法通常需要和group by语句组合使用
(2)、表生成函数:
表生成函数接收零个或者多个输入,然后产生多列或多行输出.  注意:当split被包含在""之中的时候需要使用四个进行转义[比如在hive -e ""中执行split函数]
注意:当split被包含在""之中的时候需要使用四个进行转义[比如在hive -e ""中执行split函数]
## array()函数可以将一列输入转换成一个数组输出 hive> select array(1,2,3) from xuxuebiao; OK [1,2,3] [1,2,3] ## explode()函数以array数据类型作为输入,对数组中数据进行迭代,返回多行结果 hive> select explode(array(1,2,3)) from xuxuebiao; OK 1 2 3 ## 使用explode()函数查看array中的某个元素 hive> select * from appinfo LATERAL VIEW explode(ips) tmpappinfo AS realid where realid ='10.0.0.125' ; ## collect_set函数 ### 该函数的作用是将某字段的值进行去重汇总,产生Array类型字段 hive> select * from test; OK 1 A 1 C 1 B hive> select id,collect_set(name) from test group by id; OK 1 ["A","C","B"]
(3)、常用的条件判断以及数据清洗函数
在使用hive处理数据过程中,通常我们需要对相关数据进行清洗转换,此时我们可能会使用一些条件判断以及默认值处理函数。 
# if条件判断常用于不同规格数据的清洗操作
hive> select ip,if(assign != '分配状态未知',0,assign) as fenpei from asset ;
OK
10.0.0.1 分配状态未知
# case多条件判断
hive> select ip,
case
when assign = '已分配' then 1
when assign = '未分配' then 2
else 0
end
as fenpei
from asset
hive (ods)> select name,salary,
> case when salary < 800 then 'low'
> when salary >= 800 and salary <=5000 then 'middle'
> when salary >5000 and salary <10000 then 'high'
> else 'very high'
> end as bracket
> from emp1;
# parser_url()函数
hive> select parse_url('https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E8%BF%AA%E5%A3%AB%E5%B0%BC%E6%94%B6%E8%B4%AD%E7%A6%8F%E5%85%8B%E6%96%AF&rsv_idx=2','HOST') ;
[url=http://www.baidu.com]www.baidu.com[/url]
# 正则表达式
hive> select regexp_replace('foobar', 'oo|ar', '');
select regexp_replace('foobar', 'oo|ar', '-');
## 输出第一个回溯引用(.*?)匹配到的内容即the
select regexp_extract('foothebar', 'foo(.*?)(bar)', 1);
## 输出第而个回溯引用(bar)匹配到的内容即bar
select regexp_extract('foothebar', 'foo(.*?)(bar)', 2);
## 输出全部内容
select regexp_extract('foothebar', 'foo(.*?)(bar)', 0);
# 清洗组合
select if(4>5,5000,1000),coalesce(null,1,3,5),coalesce(null,null,null,null), case 3 when 1 then 'lala' when 2 then 'chye' else 'abc' end;
(4)hive高级函数
row_number() over()
(5)、hive常用的环境变量

2、hive优化
2、1性能优化
在工作中使用hive比较多,也写了很多HiveQL。这里从三个方面对 Hive 常用的一些性能优化进行了总结。
 (1)表设计层面优化 利用分区表优化 分区表 是在某一个或者几个维度上对数据进行分类存储,一个分区对应一个目录。如果筛选条件里有分区字段,那么 Hive 只需要遍历对应分区目录下的文件即可,不需要遍历全局数据,使得处理的数据量大大减少,从而提高查询效率。 当一个 Hive 表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建为分区表。 利用桶表优化 指定桶的个数后,存储数据时,根据某一个字段进行哈希后,确定存储在哪个桶里,这样做的目的和分区表类似,也是使得筛选时不用全局遍历所有的数据,只需要遍历所在桶就可以了。 选择合适的文件存储格式 Apache Hive 支持 Apache Hadoop 中使用的几种熟悉的文件格式。 TextFile 默认格式,如果建表时不指定默认为此格式。 存储方式:行存储。 每一行都是一条记录,每行都以换行符
结尾。数据不做压缩时,磁盘会开销比较大,数据解析开销也比较大。 可结合 Gzip、Bzip2 等压缩方式一起使用(系统会自动检查,查询时会自动解压),但对于某些压缩算法 hive 不会对数据进行切分,从而无法对数据进行并行操作。 SequenceFile 一种Hadoop API 提供的二进制文件,使用方便、可分割、个压缩的特点。 支持三种压缩选择:NONE、RECORD、BLOCK。RECORD压缩率低,一般建议使用BLOCK压缩。 RCFile 存储方式:数据按行分块,每块按照列存储 。 首先,将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。 其次,块数据列式存储,有利于数据压缩和快速的列存取。 ORC 存储方式:数据按行分块,每块按照列存储 Hive 提供的新格式,属于 RCFile 的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快,快速列存取。 Parquet 存储方式:列式存储 Parquet 对于大型查询的类型是高效的。对于扫描特定表格中的特定列查询,Parquet特别有用。Parquet一般使用 Snappy、Gzip 压缩。默认 Snappy。 Parquet 支持 Impala 查询引擎。 表的文件存储格式尽量采用 Parquet 或 ORC,不仅降低存储量,还优化了查询,压缩,表关联等性能; 选择合适的压缩方式 Hive 语句最终是转化为 MapReduce 程序来执行的,而 MapReduce 的性能瓶颈在与 网络IO 和 磁盘IO,要解决性能瓶颈,最主要的是 减少数据量,对数据进行压缩是个好方式。压缩虽然是减少了数据量,但是压缩过程要消耗CPU,但是在Hadoop中,往往性能瓶颈不在于CPU,CPU压力并不大,所以压缩充分利用了比较空闲的CPU。
(1)表设计层面优化 利用分区表优化 分区表 是在某一个或者几个维度上对数据进行分类存储,一个分区对应一个目录。如果筛选条件里有分区字段,那么 Hive 只需要遍历对应分区目录下的文件即可,不需要遍历全局数据,使得处理的数据量大大减少,从而提高查询效率。 当一个 Hive 表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建为分区表。 利用桶表优化 指定桶的个数后,存储数据时,根据某一个字段进行哈希后,确定存储在哪个桶里,这样做的目的和分区表类似,也是使得筛选时不用全局遍历所有的数据,只需要遍历所在桶就可以了。 选择合适的文件存储格式 Apache Hive 支持 Apache Hadoop 中使用的几种熟悉的文件格式。 TextFile 默认格式,如果建表时不指定默认为此格式。 存储方式:行存储。 每一行都是一条记录,每行都以换行符
结尾。数据不做压缩时,磁盘会开销比较大,数据解析开销也比较大。 可结合 Gzip、Bzip2 等压缩方式一起使用(系统会自动检查,查询时会自动解压),但对于某些压缩算法 hive 不会对数据进行切分,从而无法对数据进行并行操作。 SequenceFile 一种Hadoop API 提供的二进制文件,使用方便、可分割、个压缩的特点。 支持三种压缩选择:NONE、RECORD、BLOCK。RECORD压缩率低,一般建议使用BLOCK压缩。 RCFile 存储方式:数据按行分块,每块按照列存储 。 首先,将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。 其次,块数据列式存储,有利于数据压缩和快速的列存取。 ORC 存储方式:数据按行分块,每块按照列存储 Hive 提供的新格式,属于 RCFile 的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快,快速列存取。 Parquet 存储方式:列式存储 Parquet 对于大型查询的类型是高效的。对于扫描特定表格中的特定列查询,Parquet特别有用。Parquet一般使用 Snappy、Gzip 压缩。默认 Snappy。 Parquet 支持 Impala 查询引擎。 表的文件存储格式尽量采用 Parquet 或 ORC,不仅降低存储量,还优化了查询,压缩,表关联等性能; 选择合适的压缩方式 Hive 语句最终是转化为 MapReduce 程序来执行的,而 MapReduce 的性能瓶颈在与 网络IO 和 磁盘IO,要解决性能瓶颈,最主要的是 减少数据量,对数据进行压缩是个好方式。压缩虽然是减少了数据量,但是压缩过程要消耗CPU,但是在Hadoop中,往往性能瓶颈不在于CPU,CPU压力并不大,所以压缩充分利用了比较空闲的CPU。  如何选择压缩方式 压缩比率 压缩解压速度 是否支持split 支持分割的文件可以并行的有多个 mapper 程序处理大数据文件,大多数文件不支持可分割是因为这些文件只能从头开始读。
如何选择压缩方式 压缩比率 压缩解压速度 是否支持split 支持分割的文件可以并行的有多个 mapper 程序处理大数据文件,大多数文件不支持可分割是因为这些文件只能从头开始读。
2.2 语法和参数层面优化
列裁剪 Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其他的列。这样做可以节省读取开销,中间表存储开销和数据整合开销。
set hive.optimize.cp = true; -- 列裁剪,取数只取查询中需要用到的列,默认为真
分区裁剪 在查询的过程中只选择需要的分区,可以减少读入的分区数目,减少读入的数据量。
set hive.optimize.pruner=true; // 默认为true
合并小文件 Map 输入合并 在执行 MapReduce 程序的时候,一般情况是一个文件需要一个 mapper 来处理。但是如果数据源是大量的小文件,这样岂不是会启动大量的 mapper 任务,这样会浪费大量资源。可以将输入的小文件进行合并,从而减少mapper任务数量。详细分析
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- Map端输入、合并文件之后按照block的大小分割(默认) set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat; -- Map端输入,不合并
Map/Reduce输出合并 大量的小文件会给 HDFS 带来压力,影响处理效率。可以通过合并 Map 和 Reduce 的结果文件来消除影响。
set hive.merge.mapfiles=true; -- 是否合并Map输出文件, 默认值为真 set hive.merge.mapredfiles=true; -- 是否合并Reduce 端输出文件,默认值为假 set hive.merge.size.per.task=25610001000; -- 合并文件的大小,默认值为 256000000
合理控制 map/reduce 任务数量 合理控制 mapper 数量 减少 mapper 数可以通过合并小文件来实现,增加 mapper 数可以通过控制上一个 reduce 默认的 mapper 个数计算方式
输入文件总大小:total_size hdfs 设置的数据块大小:dfs_block_size default_mapper_num = total_size/dfs_block_size
MapReduce 中提供了如下参数来控制 map 任务个数:
set mapred.map.tasks=10;
从字面上看,貌似是可以直接设置 mapper 个数的样子,但是很遗憾不行,这个参数设置只有在大于default_mapper_num的时候,才会生效。
那如果我们需要减少 mapper 数量,但是文件大小是固定的,那该怎么办呢? 可以通过mapred.min.split.size设置每个任务处理的文件的大小,这个大小只有在大于dfs_block_size的时候才会生效
split_size=max(mapred.min.split.size, dfs_block_size) split_num=total_size/split_size compute_map_num = min(split_num, max(default_mapper_num, mapred.map.tasks))
这样就可以减少mapper数量了。
总结一下控制 mapper 个数的方法: 如果想增加 mapper 个数,可以设置mapred.map.tasks为一个较大的值 如果想减少 mapper 个数,可以设置maperd.min.split.size为一个较大的值 如果输入是大量小文件,想减少 mapper 个数,可以通过设置hive.input.format合并小文件
如果想要调整 mapper 个数,在调整之前,需要确定处理的文件大概大小以及文件的存在形式(是大量小文件,还是单个大文件),然后再设置合适的参数。 合理控制reducer数量 如果 reducer 数量过多,一个 reducer 会产生一个结数量果文件,这样就会生成很多小文件,那么如果这些结果文件会作为下一个 job 的输入,则会出现小文件需要进行合并的问题,而且启动和初始化 reducer 需要耗费和资源。 如果 reducer 数量过少,这样一个 reducer 就需要处理大量的数据,并且还有可能会出现数据倾斜的问题,使得整个查询耗时长。 默认情况下,hive 分配的 reducer 个数由下列参数决定:
参数1:hive.exec.reducers.bytes.per.reducer(默认1G) 参数2:hive.exec.reducers.max(默认为999)
reducer的计算公式为:N = min(参数2, 总输入数据量/参数1) 可以通过改变上述两个参数的值来控制reducer的数量。 也可以通过set mapred.map.tasks=10;直接控制reducer个数,如果设置了该参数,上面两个参数就会忽略。
2、3 join优化
优先过滤数据 尽量减少每个阶段的数据量,对于分区表能用上分区字段的尽量使用,同时只选择后面需要使用到的列,最大限度的减少参与 join 的数据量。
小表 join 大表原则 小表 join 大表的时应遵守小表 join 大表原则,原因是 join 操作的 reduce 阶段,位于 join 左边的表内容会被加载进内存,将条目少的表放在左边,可以有效减少发生内存溢出的几率。join 中执行顺序是从左到右生成 Job,应该保证连续查询中的表的大小从左到右是依次增加的。
使用相同的连接键 在 hive 中,当对 3 个或更多张表进行 join 时,如果 on 条件使用相同字段,那么它们会合并为一个 MapReduce Job,利用这种特性,可以将相同的 join on 的放入一个 job 来节省执行时间。 启用 mapjoin mapjoin 是将 join 双方比较小的表直接分发到各个 map 进程的内存中,在 map 进程中进行 join 操作,这样就不用进行 reduce 步骤,从而提高了速度。只有 join 操作才能启用 mapjoin。
set hive.auto.convert.join = true; -- 是否根据输入小表的大小,自动将reduce端的common join 转化为map join,将小表刷入内存中。 set hive.mapjoin.smalltable.filesize = 2500000; -- 刷入内存表的大小(字节) set hive.mapjoin.maxsize=1000000; -- Map Join所处理的最大的行数。超过此行数,Map Join进程会异常退出
尽量原子操作 尽量避免一个SQL包含复杂的逻辑,可以使用中间表来完成复杂的逻辑。 桶表 mapjoin 当两个分桶表 join 时,如果 join on的是分桶字段,小表的分桶数是大表的倍数时,可以启用 mapjoin 来提高效率。
set hive.optimize.bucketmapjoin = true; -- 启用桶表 map join
2.4、Group By 优化
默认情况下,Map阶段同一个Key的数据会分发到一个Reduce上,当一个Key的数据过大时会产生 数据倾斜。进行group by操作时可以从以下两个方面进行优化:
-
Map端部分聚合 事实上并不是所有的聚合操作都需要在 Reduce 部分进行,很多聚合操作都可以先在 Map 端进行部分聚合,然后在 Reduce 端的得出最终结果。
set hive.map.aggr=true; -- 开启Map端聚合参数设置 set hive.grouby.mapaggr.checkinterval=100000; -- 在Map端进行聚合操作的条目数目
-
有数据倾斜时进行负载均衡
set hive.groupby.skewindata = true; -- 有数据倾斜的时候进行负载均衡(默认是false)
当选项设定为 true 时,生成的查询计划有两个 MapReduce 任务。在第一个 MapReduce 任务中,map 的输出结果会随机分布到 reduce 中,每个 reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的group by key有可能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处理的数据结果按照group by key分布到各个 reduce 中,最后完成最终的聚合操作。
2.5 Order By 优化
order by只能是在一个reduce进程中进行,所以如果对一个大数据集进行order by,会导致一个reduce进程中处理的数据相当大,造成查询执行缓慢。 在最终结果上进行order by,不要在中间的大数据集上进行排序。如果最终结果较少,可以在一个reduce上进行排序时,那么就在最后的结果集上进行order by。 如果是去排序后的前N条数据,可以使用distribute by和sort by在各个reduce上进行排序后前N条,然后再对各个reduce的结果集合合并后在一个reduce中全局排序,再取前N条,因为参与全局排序的order by的数据量最多是reduce个数 * N,所以执行效率很高。
2.6 COUNT DISTINCT优化
-- 优化前(只有一个reduce,先去重再count负担比较大):
select count(distinct id) from tablename;
-- 优化后(启动两个job,一个job负责子查询(可以有多个reduce),另一个job负责count(1)):
select count(1) from (select distinct id from tablename) tmp;
一次读取多次插入 有些场景是从一张表读取数据后,要多次利用,这时可以使用multi insert语法:
from sale_detail insert overwrite table sale_detail_multi partition (sale_date='2010', region='china' ) select shop_name, customer_id, total_price where ..... insert overwrite table sale_detail_multi partition (sale_date='2011', region='china' ) select shop_name, customer_id, total_price where .....;
说明: 一般情况下,单个SQL中最多可以写128路输出,超过128路,则报语法错误。 在一个multi insert中: 对于分区表,同一个目标分区不允许出现多次。 对于未分区表,该表不能出现多次。 对于同一张分区表的不同分区,不能同时有insert overwrite和insert into操作,否则报错返回。
2.7、启用压缩
map 输出压缩
set mapreduce.map.output.compress=true; set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
中间数据压缩 中间数据压缩就是对 hive 查询的多个 job 之间的数据进行压缩。最好是选择一个节省CPU耗时的压缩方式。可以采用snappy压缩算法,该算法的压缩和解压效率都非常高。
set hive.exec.compress.intermediate=true; set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec; set hive.intermediate.compression.type=BLOCK;
结果数据压缩 最终的结果数据(Reducer输出数据)也是可以进行压缩的,可以选择一个压缩效果比较好的,可以减少数据的大小和数据的磁盘读写时间; 注:常用的gzip,snappy压缩算法是不支持并行处理的,如果数据源是gzip/snappy压缩文件大文件,这样只会有有个mapper来处理这个文件,会严重影响查询效率。 所以如果结果数据需要作为其他查询任务的数据源,可以选择支持splitable的LZO算法,这样既能对结果文件进行压缩,还可以并行的处理,这样就可以大大的提高job执行的速度了。关于如何给Hadoop集群安装LZO压缩库可以查看这篇文章。
set hive.exec.compress.output=true; set mapreduce.output.fileoutputformat.compress=true; set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec; set mapreduce.output.fileoutputformat.compress.type=BLOCK;
Hadoop集群支持一下算法: org.apache.hadoop.io.compress.DefaultCodec org.apache.hadoop.io.compress.GzipCodec org.apache.hadoop.io.compress.BZip2Codec org.apache.hadoop.io.compress.DeflateCodec org.apache.hadoop.io.compress.SnappyCodec org.apache.hadoop.io.compress.Lz4Codec com.hadoop.compression.lzo.LzoCodec com.hadoop.compression.lzo.LzopCodec (3)、Hive架构层面优化 启用直接抓取 Hive 从 HDFS 中读取数据,有两种方式:启用 MapReduce 读取、直接抓取。 直接抓取数据比 MapReduce 方式读取数据要快的多,但是只有少数操作可以使用直接抓取方式。 可以通过hive.fetch.task.conversion参数来配置在什么情况下采用直接抓取方式: minimal:只有 select * 、在分区字段上 where 过滤、有 limit 这三种场景下才启用直接抓取方式。 more:在 select、where 筛选、limit 时,都启用直接抓取方式。
set hive.fetch.task.conversion=more; -- 启用fetch more模式
本地化执行 Hive 在集群上查询时,默认是在集群上多台机器上运行,需要多个机器进行协调运行,这种方式很好的解决了大数据量的查询问题。但是在Hive查询处理的数据量比较小的时候,其实没有必要启动分布式模式去执行,因为以分布式方式执行设计到跨网络传输、多节点协调等,并且消耗资源。对于小数据集,可以通过本地模式,在单台机器上处理所有任务,执行时间明显被缩短。
set hive.exec.mode.local.auto=true; -- 打开hive自动判断是否启动本地模式的开关 set hive.exec.mode.local.auto.input.files.max=4; -- map任务数最大值 set hive.exec.mode.local.auto.inputbytes.max=134217728; -- map输入文件最大大小
JVM重用 Hive 语句最终会转换为一系列的 MapReduce 任务,每一个MapReduce 任务是由一系列的Map Task 和 Reduce Task 组成的,默认情况下,MapReduce 中一个 Map Task 或者 Reduce Task 就会启动一个 JVM 进程,一个 Task 执行完毕后,JVM进程就会退出。这样如果任务花费时间很短,又要多次启动 JVM 的情况下,JVM的启动时间会变成一个比较大的消耗,这时,可以通过重用 JVM 来解决。 set mapred.job.reuse.jvm.num.tasks=5;
JVM也是有缺点的,开启JVM重用会一直占用使用到的 task 的插槽,以便进行重用,直到任务完成后才会释放。如果某个不平衡的job中有几个 reduce task 执行的时间要比其他的 reduce task 消耗的时间要多得多的话,那么保留的插槽就会一直空闲却无法被其他的 job 使用,直到所有的 task 都结束了才会释放。
并行执行 有的查询语句,hive会将其转化为一个或多个阶段,包括:MapReduce 阶段、抽样阶段、合并阶段、limit 阶段等。默认情况下,一次只执行一个阶段。但是,如果某些阶段不是互相依赖,是可以并行执行的。多阶段并行是比较耗系统资源的。
set hive.exec.parallel=true; -- 可以开启并发执行。 set hive.exec.parallel.thread.number=16; -- 同一个sql允许最大并行度,默认为8。
推测执行 在分布式集群环境下,因为程序Bug(包括Hadoop本身的bug),负载不均衡或者资源分布不均等原因,会造成同一个作业的多个任务之间运行速度不一致,有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行进度。为了避免这种情况发生,Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
set mapreduce.map.speculative=true; set mapreduce.reduce.speculative=true;
谓词下推 在关系型数据库如MySQL中,也有谓词下推(Predicate Pushdown,PPD)的概念。它就是将SQL语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。 例如以下HiveQL语句:
select a.uid,a.event_type,b.topic_id,b.title from calendar_record_log a left outer join ( select uid,topic_id,title from forum_topic where pt_date = 20190224 and length(content) >= 100 ) b on a.uid = b.uid where a.pt_date = 20190224 and status = 0;
对forum_topic做过滤的where语句写在子查询内部,而不是外部。Hive中有谓词下推优化的配置项hive.optimize.ppd,默认值true,与它对应的逻辑优化器是PredicatePushDown。该优化器就是将OperatorTree中的FilterOperator向上提,见下图。  group by代替distinct 当要统计某一列的去重数时,如果数据量很大,count(distinct)就会非常慢,原因与order by类似,count(distinct)逻辑只会有很少的reducer来处理。这时可以用group by来改写:
group by代替distinct 当要统计某一列的去重数时,如果数据量很大,count(distinct)就会非常慢,原因与order by类似,count(distinct)逻辑只会有很少的reducer来处理。这时可以用group by来改写:
select t.a,sum(t.b),count(t.c),count(t.d) from ( select a,b,null c,null d from some_table union all select a,0 b,c,null d from some_table group by a,c union all select a,0 b,null c,d from some_table group by a,d ) t;
多表join时key相同 这种情况会将多个join合并为一个MR job来处理,例如:
select a.event_type,a.event_code,a.event_desc,b.upload_time from calendar_event_code a inner join ( select event_type,upload_time from calendar_record_log where pt_date = 20190225 ) b on a.event_type = b.event_type inner join ( select event_type,upload_time from calendar_record_log_2 where pt_date = 20190225 ) c on a.event_type = c.event_type;
利用map join特性 map join特别适合大小表join的情况。Hive会将build table和probe table在map端直接完成join过程,消灭了reduce,效率很高。
select /*+mapjoin(a)*/ a.event_type,b.upload_time from calendar_event_code a inner join ( select event_type,upload_time from calendar_record_log where pt_date = 20190225 ) b on a.event_type < b.event_type;
优化SQL处理join数据倾斜 2.2.1空值或无意义值 这种情况很常见,比如当事实表是日志类数据时,往往会有一些项没有记录到,我们视情况会将它置为null,或者空字符串、-1等。如果缺失的项很多,在做join时这些空值就会非常集中,拖累进度。 因此,若不需要空值数据,就提前写where语句过滤掉。需要保留的话,将空值key用随机方式打散,例如将用户ID为null的记录随机改为负值:
select a.uid,a.event_type,b.nickname,b.age from ( select (case when uid is null then cast(rand()*-10240 as int) else uid end) as uid, event_type from calendar_record_log where pt_date >= 20190201 ) a left outer join ( select uid,nickname,age from user_info where status = 4 ) b on a.uid = b.uid;
2.2..2 单独处理倾斜key 这其实是上面处理空值方法的拓展,不过倾斜的key变成了有意义的。一般来讲倾斜的key都很少,我们可以将它们抽样出来,对应的行单独存入临时表中,然后打上一个较小的随机数前缀(比如0~9),最后再进行聚合。SQL语句与上面的相仿,不再赘述。 不同数据类型 这种情况不太常见,主要出现在相同业务含义的列发生过逻辑上的变化时。 举个例子,假如我们有一旧一新两张日历记录表,旧表的记录类型字段是(event_type int),新表的是(event_type string)。为了兼容旧版记录,新表的event_type也会以字符串形式存储旧版的值,比如'17'。当这两张表join时,经常要耗费很长时间。其原因就是如果不转换类型,计算key的hash值时默认是以int型做的,这就导致所有“真正的”string型key都分配到一个reducer上。所以要注意类型转换:
select a.uid,a.event_type,b.record_data from calendar_record_log a left outer join ( select uid,event_type from calendar_record_log_2 where pt_date = 20190228 ) b on a.uid = b.uid and b.event_type = cast(a.event_type as string) where a.pt_date = 20190228;
build table过大 有时,build table会大到无法直接使用map join的地步,比如全量用户维度表,而使用普通join又有数据分布不均的问题。这时就要充分利用probe table的限制条件,削减build table的数据量,再使用map join解决。代价就是需要进行两次join。举个例子:
select /*+mapjoin(b)*/ a.uid,a.event_type,b.status,b.extra_info from calendar_record_log a left outer join ( select /*+mapjoin(s)*/ t.uid,t.status,t.extra_info from (select distinct uid from calendar_record_log where pt_date = 20190228) s inner join user_info t on s.uid = t.uid ) b on a.uid = b.uid where a.pt_date = 20190228;
表的优化 3.1小表join大表 (小表需要在左边.) 注:(新版的 hive 已经对小表 JOIN 大表和大表 JOIN 小表进行了优化。小表 放在左边和右边已经没有明显区别。) 3.2大表join大表 当一个表内有许多空值时会导致MapReduce过程中,空成为一个key值,对应的会有大量的value值, 而一个key的value会一起到达reduce造成内存不足;所以要想办法过滤这些空值. 【这里你是否明白一起达到,因为空值太多导致都到了同一个reduce,然后造成内存暴增,所以需要过滤】 (1).通过查询所有不为空的结果
insert overwrite table jointable select n.* from (select * from nullidtable where id is not null ) n left join ori o on n.id = o.id;
查询出空值并给其赋上随机数,避免了key值为空
insert overwrite table jointable
select n.* from nullidtable n full join ori o on
case when n.id is null then concat('hive', rand()) else n.id end = o.id;
建议: 如果用户对于运行时的偏差非常敏感的话,那么可以将这些功能关闭掉。如果用户因为输入数据量很大而需要执行长时间的map或者Reduce task的话,那么启动推测执行造成的浪费是非常巨大大。
3、hive的钩子,数据湖
通常,Hook是一种在处理过程中拦截事件,消息或函数调用的机制。 Hive hooks是绑定到了Hive内部的工作机制,无需重新编译Hive。从这个意义上讲,提供了使用hive扩展和集成外部功能的能力。换句话说,Hive hadoop可用于在查询处理的各个步骤中运行/注入一些代码。根据钩子的类型,它可以在查询处理期间的不同点调用: Pre-execution hooks-在执行引擎执行查询之前,将调用Pre-execution hooks。请注意,这个目的是此时已经为Hive准备了一个优化的查询计划。 Post-execution hooks -在查询执行完成之后以及将结果返回给用户之前,将调用Post-execution hooks 。 Failure-execution hooks -当查询执行失败时,将调用Failure-execution hooks 。 Pre-driver-run 和post-driver-run hooks-在driver执行查询之前和之后调用Pre-driver-run 和post-driver-run hooks。 Pre-semantic-analyzer 和 Post-semantic-analyzer hooks-在Hive在查询字符串上运行语义分析器之前和之后调用Pre-semantic-analyzer 和Post-semantic-analyzer hooks。 什么是数据湖: 数据湖是一种在系统或存储库中以自然格式存储数据的方法,它有助于以各种模式和结构形式配置数据,通常是对象块或文件。数据湖的主要思想是对企业中的所有数据进行统一存储,从原始数据(这意味着源系统数据的精确副本)转换为用于报告、可视化、分析和机器学习等各种任务的转换数据。湖中的数据包括结构化数据从关系数据库(行和列),半结构化数据(CSV、XML、JSON的日志),非结构化数据(电子邮件,文档,PDF)和二进制数据(图像、音频、视频)从而形成一个集中式数据存储容纳所有形式的数据。 数据湖的核心思想是把不同结构的数据统一存储,使不同数据有一致的存储方式,在使用时方便连接,真正解决数据集成问题。 数据湖泊和数据仓库的区别,主要就是数据仓库的数据进入这个池之前是预先分类的,这可以指导其后面如何进行数据的分析。但在大数据时代,这些都是素材而已,你根本不知道以后如何用它。也就是数据湖泊给后面的数据分析带来了更大的弹性。因此,这个放大数据的仓库,专家建议叫数据湖泊,以区别于数据仓库。 关于数据的数据 数据湖泊(lakes )和数据沼泽(swamps )之间的重要区别在于,组织良好的数据可以形成高效的湖泊,而沼泽只是数据过度复制或被用户孤立的数据。获取有关如何跨组织使用生产数据的信息不仅有利于构建组织良好的数据湖,而且还有助于数据工程师微调数据管道或数据本身。
要了解数据的消耗方式,我们需要找出一些基本问题的答案,例如: 经常访问哪些数据集(表/视图/数据库)? 查询何时运行最频繁? 哪些用户或应用程序正在大量使用这些资源? 什么类型的查询经常运行? 访问最多的对象可以轻松地受益于压缩,列式文件格式或数据分解等优化。可以为利用资源的应用程序或用户分配单独的队列,以平衡群集上的负载。群集资源可以在时间范围内按比例放大,此时大多数查询主要用于满足SLA并在低使用率期间按比例缩小以节省成本。 钩子是一种允许修改程序行为的机制。 它是一种拦截应用程序中的函数调用,消息或事件的技术。 Hive提供了许多不同类型的钩子,上文补充内容已经列出来。 可以在特定事件中调用每种类型的挂钩,并且可以根据用例自定义以执行不同的操作。 例如,在执行物理查询计划之前调用预执行挂钩,并在向job.xml提交查询以编辑敏感信息之前调用redactor挂钩。 Apache Atlas拥有最流行的Hive钩子实现之一,它可以监听Hive中的创建/更新/删除操作,并通过Kafka通知更新Atlas中的元数据。
Implementation Pre-execution hooks可以由ExecuteWithHookContext接口创建实现。这是一个空的接口,简单地调用run方法和HookContext。HookContext 有很多关于查询、HIVE实例和用户的信息。可以很容易地利用信息来检测数据湖如何被其用户使用。
public HookContext(QueryPlan queryPlan, QueryState queryState,
Map<String, ContentSummary> inputPathToContentSummary, String userName, String ipAddress,
String hiveInstanceAddress, String operationId, String sessionId, String threadId,
boolean isHiveServerQuery, PerfLogger perfLogger, QueryInfo queryInfo) throws Exception {
实现HookContext的任何钩子得到查询计划(QueIGrPy)。在QueryPlan的hood下面,有许多getters 被用来收集关于查询的信息。举几个例子:
getQueryProperties - 获取有关查询的详细信息,包括查询是否具有joins,分组,分析函数或任何排序/排序操作。 getQueryStartTime - 返回查询的开始时间。 getOperationName - 返回查询执行的操作类型,例如CREATETABLE,DROPTABLE,ALTERDATABASE等, getQueryStr - 以字符串形式返回查询。
要创建我们自己的Hive钩子,我们只需要一个实现ExecuteWithHookContext的类,并使用我们的自定义逻辑覆盖其run方法来捕获数据。
public class CustomHook implements ExecuteWithHookContext {
private static final Logger logger = Logger.getLogger(CustomHook.class.getName());
public void run(HookContext hookContext) throws Exception {
assert (hookContext.getHookType() == HookType.PRE_EXEC_HOOK);
SessionState ss = SessionState.get();
UserGroupInformation ugi = hookContext.getUgi();
Set<ReadEntity> inputs = hookContext.getInputs();
QueryPlan plan = hookContext.getQueryPlan();
this.run(ss, ugi, plan, inputs);
}
需要SessionState和UserGroupInformation来收集有关Hive session 及其users的信息。
public void run(SessionState sess, UserGroupInformation ugi, QueryPlan qpln, Set<ReadEntity> inputs)
throws Exception {
if (sess != null) {
String qid = sess.getQueryId() == null ? qpln.getQueryId() : sess.getQueryId();
String QueryID = qid;
String Query = sess.getCmd().trim();
String QueryType = sess.getCommandType();
// get all information about query
if (qpln != null) {
Long Query_Start_Time = qpln.getQueryStartTime();
QueryProperties queryProps = qpln.getQueryProperties();
if (queryProps != null) {
boolean Has_Join = queryProps.hasJoin();
boolean Has_Group_By = queryProps.hasGroupBy();
boolean Has_Sort_By = queryProps.hasSortBy();
boolean Has_Order_By = queryProps.hasOrderBy();
boolean Has_Distribute_By = queryProps.hasDistributeBy();
boolean Has_Cluster_By = queryProps.hasClusterBy();
boolean Has_Windowing = queryProps.hasWindowing();
}
}
// get user id
String username = sess.getUserName() == null ? ugi.getUserName() : sess.getUserName();
// get list of database@table names
List<String> tables = new ArrayList<String>();
for (Object o : inputs) {
tables.add(o.toString());
}
// Add logic here to format logging msg
// logger.info(msg)
}
}
在分配挂钩之前,应将已编译的jar添加到Hive类路径中。 可以在hive-site.xml属性hive.aux.jars.path定义的位置添加jar。 可以使用属性hive.exec.pre.hooks将预执行挂钩设置为自定义挂钩的类。 使用Hive CLI,我们可以执行以下操作:
set hive.exec.pre.hooks=com.myApp.CustomHook;
一旦设置了pre-execution挂钩,就应该为每个用户的每个查询执行CustomHook的代码。 CustomHook收集的信息可以在通用日志记录存储库中记录为逗号分隔值,稍后可以在任何BI工具或Excel文件中提取,以找出有关数据湖使用模式的各种统计信息。
注意事项 虽然挂钩是捕获信息的好方法,但它们可能会增加查询执行的延迟。 钩子中的处理可以保持最小以避免这种开销。 通过Hive钩子无法捕获有关通过Spark的HiveContext在Hive表上完成的处理的信息。 Spark提供了自己的钩子机制。
三、hive的分析函数总结
一、关系运算:
-
等值比较: =. 4
-
不等值比较: <>. 4
-
小于比较: <. 4
-
小于等于比较: <=. 4
-
大于比较: >. 5
-
大于等于比较: >=. 5
-
空值判断: IS NULL. 5
-
非空判断: IS NOT NULL. 6
-
LIKE比较: LIKE. 6
-
JAVA的LIKE操作: RLIKE. 6
-
REGEXP操作: REGEXP. 7
二、数学运算:
-
加法操作: +. 7
-
减法操作: - 7
-
乘法操作: *. 8
-
除法操作: /. 8
-
取余操作: %.. 8
-
位与操作: &.. 9
-
位或操作: |. 9
-
位异或操作: ^. 9
-
位取反操作: ~. 10
三、逻辑运算
-
逻辑与操作: AND.. 10
-
逻辑或操作: OR. 10
-
逻辑非操作: NOT. 10
四、数值计算
-
取整函数: round. 11
-
指定精度取整函数: round. 11
-
向下取整函数: floor. 11
-
向上取整函数: ceil 12
-
向上取整函数: ceiling. 12
-
取随机数函数: rand. 12
-
自然指数函数: exp. 13
-
以10为底对数函数: log10. 13
-
以2为底对数函数: log2. 13
-
对数函数: log. 13
-
幂运算函数: pow.. 14
-
幂运算函数: power. 14
-
开平方函数: sqrt. 14
-
二进制函数: bin. 14
-
十六进制函数: hex. 15
-
反转十六进制函数: unhex. 15
-
进制转换函数: conv. 15
-
绝对值函数: abs. 16
-
正取余函数: pmod. 16
-
正弦函数: sin. 16
-
反正弦函数: asin. 16
-
余弦函数: cos. 17
-
反余弦函数: acos. 17
-
positive函数: positive. 17
-
negative函数: negative. 17
五、日期函数
-
UNIX时间戳转日期函数: from_unixtime. 18
-
获取当前UNIX时间戳函数: unix_timestamp. 18
-
日期转UNIX时间戳函数: unix_timestamp. 18
-
指定格式日期转UNIX时间戳函数: unix_timestamp. 18
-
日期时间转日期函数: to_date. 19
-
日期转年函数: year. 19
-
日期转月函数: month. 19
-
日期转天函数: day. 19
-
日期转小时函数: hour. 20
-
日期转分钟函数: minute. 20
-
日期转秒函数: second. 20
-
日期转周函数: weekofyear. 20
-
日期比较函数: datediff 21
-
日期增加函数: date_add. 21
-
日期减少函数: date_sub. 21
六、条件函数
-
If函数: if 21
-
非空查找函数: COALESCE. 22
-
条件判断函数:CASE. 22
-
条件判断函数:CASE. 22
七、字符串函数
-
字符串长度函数:length. 23
-
字符串反转函数:reverse. 23
-
字符串连接函数:concat. 23
-
带分隔符字符串连接函数:concat_ws. 23
-
字符串截取函数:substr,substring. 24
-
字符串截取函数:substr,substring. 24
-
字符串转大写函数:upper,ucase. 24
-
字符串转小写函数:lower,lcase. 25
-
去空格函数:trim.. 25
-
左边去空格函数:ltrim.. 25
-
右边去空格函数:rtrim.. 25
-
正则表达式替换函数:regexp_replace. 26
-
正则表达式解析函数:regexp_extract. 26
-
URL解析函数:parse_url 26
-
json解析函数:get_json_object. 27
-
空格字符串函数:space. 27
-
重复字符串函数:repeat. 27
-
首字符ascii函数:ascii 28
-
左补足函数:lpad. 28
-
右补足函数:rpad. 28
-
分割字符串函数: split. 28
-
集合查找函数: find_in_set. 29
八、集合统计函数
-
个数统计函数: count. 29
-
总和统计函数: sum.. 29
-
平均值统计函数: avg. 30
-
最小值统计函数: min. 30
-
最大值统计函数: max. 30
-
非空集合总体变量函数: var_pop. 30
-
非空集合样本变量函数: var_samp. 31
-
总体标准偏离函数: stddev_pop. 31
-
样本标准偏离函数: stddev_samp. 31
-
中位数函数: percentile. 31
-
近似中位数函数: percentile_approx. 32
-
近似中位数函数: percentile_approx. 32
-
直方图: histogram_numeric. 32
九、复合类型构建操作
-
Map类型构建: map. 32
-
Struct类型构建: struct. 33
-
array类型构建: array. 33
十、复杂类型访问操作
-
array类型访问: A[n] 33
-
map类型访问: M[key] 34
-
struct类型访问: S.x. 34
十一、复杂类型长度统计函数
-
Map类型长度函数: size(Map<K.V>) 34
-
array类型长度函数: size(Array<T>) 34
-
类型转换函数... 35
四、hive例子演示
一、关系运算:
1. 等值比较: =
语法:A=B 操作类型:所有基本类型 描述: 如果表达式A与表达式B相等,则为TRUE;否则为FALSE 举例:
hive>select 1 from lxw_dual where 1=1;
1
2、不等值比较: <>
语法: A <> B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A与表达式B不相等,则为TRUE;否则为FALSE 举例:
hive> select1 from lxw_dual where 1 <> 2; 1
-
小于比较: < 语法: A < B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A小于表达式B,则为TRUE;否则为FALSE 举例:
hive> select1 from lxw_dual where 1 < 2; 1
-
小于等于比较: <= 语法: A <= B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A小于或者等于表达式B,则为TRUE;否则为FALSE 举例:
hive> select1 from lxw_dual where 1 <= 1; 1
-
大于比较: > 语法: A > B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A大于表达式B,则为TRUE;否则为FALSE 举例: hive> select1 from lxw_dual where 2 > 1; 1
-
大于等于比较: >= 语法: A >= B 操作类型: 所有基本类型 描述: 如果表达式A为NULL,或者表达式B为NULL,返回NULL;如果表达式A大于或者等于表达式B,则为TRUE;否则为FALSE 举例: hive> select1 from lxw_dual where 1 >= 1; 1
注意:String的比较要注意(常用的时间比较可以先to_date之后再比较)
hive> select* from lxw_dual; OK 201111120900:00:00 2011111209 hive> selecta,b,a<b,a>b,a=b from lxw_dual; 201111120900:00:00 2011111209 false true false
3、空值判断: IS NULL
语法: A IS NULL 操作类型: 所有类型 描述: 如果表达式A的值为NULL,则为TRUE;否则为FALSE 举例:
hive> select1 from lxw_dual where null is null; 1
-
非空判断: IS NOTNULL 语法: A IS NOT NULL 操作类型: 所有类型 描述: 如果表达式A的值为NULL,则为FALSE;否则为TRUE 举例:
hive> select1 from lxw_dual where 1 is not null; 1
4、LIKE比较: LIKE
语法: A LIKE B 操作类型: strings 描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B 的正则语法,则为TRUE;否则为FALSE。B中字符”_”表示任意单个字符,而字符”%”表示任意数量的字符。 举例:
hive> select1 from lxw_dual where 'football' like 'foot%'; 1 hive> select1 from lxw_dual where 'football' like 'foot____'; 1
注意:否定比较时候用NOT ALIKE B
hive> select1 from lxw_dual where NOT 'football' like 'fff%'; 1
-
JAVA的LIKE操作: RLIKE 语法: A RLIKE B 操作类型: strings 描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合JAVA正则表达式B的正则语法,则为TRUE;否则为FALSE。 举例:
hive> select1 from lxw_dual where 'footbar’ rlike '^f.*r$’; 1
注意:判断一个字符串是否全为数字:
hive>select 1from lxw_dual where '123456' rlike '^\d+$'; 1 hive> select1 from lxw_dual where '123456aa' rlike '^\d+$';
3、REGEXP操作: REGEXP 语法: A REGEXP B 操作类型: strings 描述: 功能与RLIKE相同 举例:
hive> select1 from lxw_dual where 'footbar' REGEXP '^f.*r$'; 1
二、数学运算:
1. 加法操作: +
语法: A + B 操作类型:所有数值类型 说明:返回A与B相加的结果。结果的数值类型等于A的类型和B的类型的最小父类型(详见数据类型的继承关系)。比如,int + int 一般结果为int类型,而int + double 一般结果为double类型 举例:
hive> select1 + 9 from lxw_dual; 10 hive> createtable lxw_dual as select 1 + 1.2 from lxw_dual; hive>describe lxw_dual; _c0 double
2、减法操作: -
语法: A – B 操作类型:所有数值类型 说明:返回A与B相减的结果。结果的数值类型等于A的类型和B的类型的最小父类型(详见数据类型的继承关系)。比如,int – int 一般结果为int类型,而int – double 一般结果为double类型 举例:
hive> select10 – 5 from lxw_dual; 5 hive> createtable lxw_dual as select 5.6 – 4 from lxw_dual; hive>describe lxw_dual; _c0 double
3、乘法操作:
语法: A * B 操作类型:所有数值类型 说明:返回A与B相乘的结果。结果的数值类型等于A的类型和B的类型的最小父类型(详见数据类型的继承关系)。注意,如果A乘以B的结果超过默认结果类型的数值范围,则需要通过cast将结果转换成范围更大的数值类型 举例:
hive> select40 * 5 from lxw_dual; 200
4、除法操作: /
语法: A / B 操作类型:所有数值类型 说明:返回A除以B的结果。结果的数值类型为double 举例: hive> select40 / 5 from lxw_dual; 8.0
注意:hive中最高精度的数据类型是double,只精确到小数点后16位,在做除法运算的时候要特别注意 hive>select ceil(28.0/6.999999999999999999999) from lxw_duallimit 1; 结果为4 hive>select ceil(28.0/6.99999999999999) from lxw_dual limit1; 结果为5
5、取余操作: %
语法: A % B 操作类型:所有数值类型 说明:返回A除以B的余数。结果的数值类型等于A的类型和B的类型的最小父类型(详见数据类型的继承关系)。 举例:
hive> select 41 % 5 from lxw_dual; 1 hive> select 8.4 % 4 from lxw_dual; 0.40000000000000036
注意:精度在hive中是个很大的问题,类似这样的操作最好通过round指定精度
hive> select round(8.4 % 4 , 2) from lxw_dual; 0.4
四、操作符
1、位与操作: &
语法: A & B 操作类型:所有数值类型 说明:返回A和B按位进行与操作的结果。结果的数值类型等于A的类型和B的类型的最小父类型(详见数据类型的继承关系)。 举例:
hive> select 4 & 8 from lxw_dual; 0 hive> select 6 & 4 from lxw_dual; 4
2、位或操作: |
语法: A | B 操作类型:所有数值类型 说明:返回A和B按位进行或操作的结果。结果的数值类型等于A的类型和B的类型的最小父类型(详见数据类型的继承关系)。 举例:
hive> select 4 | 8 from lxw_dual; 12 hive> select 6 | 8 from lxw_dual; 14
3、位异或操作: ^
语法: A ^ B 操作类型:所有数值类型 说明:返回A和B按位进行异或操作的结果。结果的数值类型等于A的类型和B的类型的最小父类型(详见数据类型的继承关系)。 举例:
hive> select 4 ^ 8 from lxw_dual; 12 hive> select 6 ^ 4 from lxw_dual; 2
4.位取反操作: ~
语法: ~A 操作类型:所有数值类型 说明:返回A按位取反操作的结果。结果的数值类型等于A的类型。 举例:
hive> select ~6 from lxw_dual; -7 hive> select ~4 from lxw_dual; -5
五、逻辑运算:
1. 逻辑与操作: AND
语法: A AND B 操作类型:boolean 说明:如果A和B均为TRUE,则为TRUE;否则为FALSE。如果A为NULL或B为NULL,则为NULL 举例:
hive> select 1 from lxw_dual where 1=1 and 2=2; 1
2、逻辑或操作: OR
语法: A OR B 操作类型:boolean 说明:如果A为TRUE,或者B为TRUE,或者A和B均为TRUE,则为TRUE;否则为FALSE 举例:
hive> select 1 from lxw_dual where 1=2 or 2=2; 1
3、逻辑非操作: NOT
语法: NOT A 操作类型:boolean 说明:如果A为FALSE,或者A为NULL,则为TRUE;否则为FALSE 举例:
hive> select 1 from lxw_dual where not 1=2; 1
六、数值计算
1、取整函数: round
语法: round(double a) 返回值: BIGINT 说明: 返回double类型的整数值部分(遵循四舍五入) 举例:
hive> select round(3.1415926) from lxw_dual; 3 hive> select round(3.5) from lxw_dual; 4 hive> create table lxw_dual as select round(9542.158) fromlxw_dual; hive> describe lxw_dual; _c0 bigint
2、指定精度取整函数: round
语法: round(double a, int d) 返回值: DOUBLE 说明: 返回指定精度d的double类型 举例:
hive> select round(3.1415926,4) from lxw_dual; 3.1416
3、向下取整函数: floor
语法: floor(double a) 返回值: BIGINT 说明: 返回等于或者小于该double变量的最大的整数 举例:
hive> select floor(3.1415926) from lxw_dual; 3 hive> select floor(25) from lxw_dual; 25
4、向上取整函数: ceil
语法: ceil(double a) 返回值: BIGINT 说明: 返回等于或者大于该double变量的最小的整数 举例:
hive> select ceil(3.1415926) from lxw_dual; 4 hive> select ceil(46) from lxw_dual; 46
5、向上取整函数: ceiling
语法: ceiling(double a) 返回值: BIGINT 说明: 与ceil功能相同 举例:
hive> select ceiling(3.1415926) from lxw_dual; 4 hive> select ceiling(46) from lxw_dual; 46
6、取随机数函数: rand
语法: rand(),rand(int seed) 返回值: double 说明: 返回一个0到1范围内的随机数。如果指定种子seed,则会等到一个稳定的随机数序列 举例:
hive> select rand() from lxw_dual; 0.5577432776034763 hive> select rand() from lxw_dual; 0.6638336467363424 hive> select rand(100) from lxw_dual; 0.7220096548596434 hive> select rand(100) from lxw_dual; 0.7220096548596434
7、自然指数函数: exp
语法: exp(double a) 返回值: double 说明: 返回自然对数e的a次方 举例:
hive> select exp(2) from lxw_dual; 7.38905609893065
8、自然对数函数: ln
语法: ln(double a) 返回值: double 说明: 返回a的自然对数 举例:
hive> select ln(7.38905609893065) from lxw_dual; 2.0
自然对数函数: ln 语法: ln(double a) 返回值: double 说明: 返回a的自然对数 举例: hive> select ln(7.38905609893065) from lxw_dual; 2.0
9、以10为底对数函数: log10
语法: log10(double a) 返回值: double 说明: 返回以10为底的a的对数 举例:
hive> select log10(100) from lxw_dual; 2.0
10、以2为底对数函数: log2
语法: log2(double a) 返回值: double 说明: 返回以2为底的a的对数 举例:
hive> select log2(8) from lxw_dual; 3.0
11、对数函数: log
语法: log(double base, double a) 返回值: double 说明: 返回以base为底的a的对数 举例:
hive> select log(4,256) from lxw_dual; 4.0
12、幂运算函数: pow
语法: pow(double a, double p) 返回值: double 说明: 返回a的p次幂 举例:
hive> select pow(2,4) from lxw_dual; 16.0
13、幂运算函数: power
语法: power(double a, double p) 返回值: double 说明: 返回a的p次幂,与pow功能相同 举例:
hive> select power(2,4) from lxw_dual; 16.0
14、开平方函数: sqrt
语法: sqrt(double a) 返回值: double 说明: 返回a的平方根 举例:
hive> select sqrt(16) from lxw_dual; 4.0
15、二进制函数: bin
语法: bin(BIGINT a) 返回值: string 说明: 返回a的二进制代码表示 举例:
hive> select bin(7) from lxw_dual; 111
17、十六进制函数: hex
语法: hex(BIGINT a) 返回值: string 说明: 如果变量是int类型,那么返回a的十六进制表示;如果变量是string类型,则返回该字符串的十六进制表示 举例:
hive> select hex(17) from lxw_dual; 11 hive> select hex(‘abc’) from lxw_dual; 616263
18、反转十六进制函数: unhex
语法: unhex(string a) 返回值: string 说明: 返回该十六进制字符串所代码的字符串 举例:
hive> select unhex(‘616263’)from lxw_dual; abc hive> select unhex(‘11’)from lxw_dual; - hive> select unhex(616263) from lxw_dual; abc
19、进制转换函数: conv
语法: conv(BIGINT num, int from_base, int to_base) 返回值: string 说明: 将数值num从from_base进制转化到to_base进制 举例:
hive> select conv(17,10,16) from lxw_dual; 11 hive> select conv(17,10,2) from lxw_dual; 10001
20、绝对值函数: abs
语法: abs(double a) abs(int a) 返回值: double int 说明: 返回数值a的绝对值 举例:
hive> select abs(-3.9) from lxw_dual; 3.9 hive> select abs(10.9) from lxw_dual; 10.9
21、正取余函数: pmod
语法: pmod(int a, int b),pmod(double a, double b) 返回值: int double 说明: 返回正的a除以b的余数 举例:
hive> select pmod(9,4) from lxw_dual; 1 hive> select pmod(-9,4) from lxw_dual; 3
22、正弦函数: sin
语法: sin(double a) 返回值: double 说明: 返回a的正弦值 举例:
hive> select sin(0.8) from lxw_dual; 0.7173560908995228
23、反正弦函数: asin
语法: asin(double a) 返回值: double 说明: 返回a的反正弦值 举例:
hive> select asin(0.7173560908995228) from lxw_dual; 0.8
24、余弦函数: cos
语法: cos(double a) 返回值: double 说明: 返回a的余弦值 举例:
hive> select cos(0.9) from lxw_dual; 0.6216099682706644
25、反余弦函数: acos
语法: acos(double a) 返回值: double 说明: 返回a的反余弦值 举例:
hive> select acos(0.6216099682706644) from lxw_dual; 0.9
26、positive函数: positive
语法: positive(int a), positive(double a) 返回值: int double 说明: 返回a 举例:
hive> select positive(-10) from lxw_dual; -10 hive> select positive(12) from lxw_dual; 12
27、negative函数: negative
语法: negative(int a), negative(double a) 返回值: int double 说明: 返回-a 举例:
hive> select negative(-5) from lxw_dual; 5 hive> select negative(8) from lxw_dual; -8
七、日期函数
1、UNIX时间戳转日期函数:from_unixtime
语法: from_unixtime(bigint unixtime[, string format]) 返回值: string 说明: 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数)到当前时区的时间格式 举例:
hive> select from_unixtime(1323308943,'yyyyMMdd') from lxw_dual; 20111208
五、日期函数1. UNIX时间戳转日期函数:from_unixtime 语法: from_unixtime(bigint unixtime[, string format]) 返回值: string 说明: 转化UNIX时间戳(从1970-01-01 00:00:00 UTC到指定时间的秒数)到当前时区的时间格式 举例: hive> select from_unixtime(1323308943,'yyyyMMdd') from lxw_dual; 20111208
2、获取当前UNIX时间戳函数:unix_timestamp
语法: unix_timestamp() 返回值: bigint 说明: 获得当前时区的UNIX时间戳 举例:
hive> select unix_timestamp() from lxw_dual; 1323309615
3、日期转UNIX时间戳函数:unix_timestamp
语法: unix_timestamp(string date) 返回值: bigint 说明: 转换格式为"yyyy-MM-ddHH:mm:ss"的日期到UNIX时间戳。如果转化失败,则返回0。 举例:
hive> select unix_timestamp('2011-12-07 13:01:03') from lxw_dual;
1323234063
4、指定格式日期转UNIX时间戳函数:unix_timestamp
语法: unix_timestamp(string date, string pattern) 返回值: bigint 说明: 转换pattern格式的日期到UNIX时间戳。如果转化失败,则返回0。 举例:
hive> select unix_timestamp('20111207 13:01:03','yyyyMMddHH:mm:ss') from lxw_dual;
1323234063
5、日期时间转日期函数:to_date
语法: to_date(string timestamp) 返回值: string 说明: 返回日期时间字段中的日期部分。 举例:
hive> select to_date('2011-12-08 10:03:01') from lxw_dual;
2011-12-08
6、日期转年函数: year
语法: year(string date) 返回值: int 说明: 返回日期中的年。 举例:
hive> select year('2011-12-08 10:03:01') from lxw_dual;
2011
hive> select year('2012-12-08')from lxw_dual;
2012
7、日期转月函数: month
语法: month (string date) 返回值: int 说明: 返回日期中的月份。 举例:
hive> select month('2011-12-08 10:03:01') from lxw_dual;
12
hive> select month('2011-08-08')from lxw_dual;
8
8、日期转天函数: day
语法: day (string date) 返回值: int 说明: 返回日期中的天。 举例:
hive> select day('2011-12-08 10:03:01') from lxw_dual;
8
hive> select day('2011-12-24')from lxw_dual;
24
9、日期转小时函数: hour
语法: hour (string date) 返回值: int 说明: 返回日期中的小时。 举例:
hive> select hour('2011-12-08 10:03:01') from lxw_dual;
10
10、日期转分钟函数: minute
语法: minute (string date) 返回值: int 说明: 返回日期中的分钟。 举例:
hive> select minute('2011-12-08 10:03:01') from lxw_dual;
3
11、日期转秒函数: second
语法: second (string date) 返回值: int 说明: 返回日期中的秒。 举例:
hive> select second('2011-12-08 10:03:01') from lxw_dual;
1
12、日期转周函数:weekofyear
语法: weekofyear (string date) 返回值: int 说明: 返回日期在当前的周数。 举例:
hive> select weekofyear('2011-12-08 10:03:01') from lxw_dual;
49
13、日期比较函数: datediff
语法: datediff(string enddate, string startdate) 返回值: int 说明: 返回结束日期减去开始日期的天数。 举例:
hive> select datediff('2012-12-08','2012-05-09')from lxw_dual;
213
14、日期增加函数: date_add
语法: date_add(string startdate, int days) 返回值: string 说明: 返回开始日期startdate增加days天后的日期。 举例:
hive> select date_add('2012-12-08',10)from lxw_dual;
2012-12-18
15、日期减少函数: date_sub
语法: date_sub (string startdate, int days) 返回值: string 说明: 返回开始日期startdate减少days天后的日期。 举例:
hive> select date_sub('2012-12-08',10)from lxw_dual;
2012-11-28
八、条件函数
1、If函数: if
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull) 返回值: T 说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNull 举例:
hive> select if(1=2,100,200) from lxw_dual; 200 hive> select if(1=1,100,200) from lxw_dual; 100
2、非空查找函数: COALESCE
语法: COALESCE(T v1, T v2, …) 返回值: T 说明: 返回参数中的第一个非空值;如果所有值都为NULL,那么返回NULL 举例:
hive> select COALESCE(null,'100','50′) from lxw_dual; 100
3、条件判断函数:CASE
语法: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END 返回值: T 说明:如果a等于b,那么返回c;如果a等于d,那么返回e;否则返回f 举例:
hive> Select case 100 when 50 then 'tom' when 100 then 'mary'else 'tim' end from lxw_dual; mary hive> Select case 200 when 50 then 'tom' when 100 then 'mary'else 'tim' end from lxw_dual; tim
4、条件判断函数:CASE
语法: CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END 返回值: T 说明:如果a为TRUE,则返回b;如果c为TRUE,则返回d;否则返回e 举例:
hive> select case when 1=2 then 'tom' when 2=2 then 'mary' else'tim' end from lxw_dual; mary hive> select case when 1=1 then 'tom' when 2=2 then 'mary' else'tim' end from lxw_dual; tom
九、字符串函数
1、字符串长度函数:length
语法: length(string A) 返回值: int 说明:返回字符串A的长度 举例:
hive> select length('abcedfg') from lxw_dual;
7
2、字符串反转函数:reverse
语法: reverse(string A) 返回值: string 说明:返回字符串A的反转结果 举例:
hive> select reverse(abcedfg’) from lxw_dual; gfdecba
3、字符串连接函数:concat
语法: concat(string A, string B…) 返回值: string 说明:返回输入字符串连接后的结果,支持任意个输入字符串 举例:
hive> select concat(‘abc’,'def’,'gh’) from lxw_dual; abcdefgh
4、带分隔符字符串连接函数:concat_ws
语法: concat_ws(string SEP, string A, string B…) 返回值: string 说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符 举例:
hive> select concat_ws(',','abc','def','gh') from lxw_dual;
abc,def,gh
5、字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start) 返回值: string 说明:返回字符串A从start位置到结尾的字符串 举例:
hive> select substr('abcde',3) from lxw_dual;
cde
hive> select substring('abcde',3) from lxw_dual;
cde
hive> selectsubstr('abcde',-1) from lxw_dual; (和ORACLE相同)
e
6、字符串截取函数:substr,substring
语法: substr(string A, int start, int len),substring(string A, intstart, int len) 返回值: string 说明:返回字符串A从start位置开始,长度为len的字符串 举例:
hive> select substr('abcde',3,2) from lxw_dual;
cd
hive> select substring('abcde',3,2) from lxw_dual;
cd
hive>select substring('abcde',-2,2) from lxw_dual;
de
7、字符串转大写函数:upper,ucase
语法: upper(string A) ucase(string A) 返回值: string 说明:返回字符串A的大写格式 举例:
hive> select upper('abSEd') from lxw_dual;
ABSED
hive> select ucase('abSEd') from lxw_dual;
ABSED
8、字符串转小写函数:lower,lcase
语法: lower(string A) lcase(string A) 返回值: string 说明:返回字符串A的小写格式 举例:
hive> select lower('abSEd') from lxw_dual;
absed
hive> select lcase('abSEd') from lxw_dual;
absed
9、去空格函数:trim
语法: trim(string A) 返回值: string 说明:去除字符串两边的空格 举例:
hive> select trim(' abc ') from lxw_dual;
abc
10、左边去空格函数:ltrim
语法: ltrim(string A) 返回值: string 说明:去除字符串左边的空格 举例:
hive> select ltrim(' abc ') from lxw_dual;
abc
11、右边去空格函数:rtrim
语法: rtrim(string A) 返回值: string 说明:去除字符串右边的空格 举例:
hive> select rtrim(' abc ') from lxw_dual;
abc
12、正则表达式替换函数:regexp_replace
语法: regexp_replace(string A, string B, string C) 返回值: string 说明:将字符串A中的符合java正则表达式B的部分替换为C。注意,在有些情况下要使用转义字符,类似oracle中的regexp_replace函数。 举例:
hive> select regexp_replace('foobar', 'oo|ar', '') from lxw_dual;
fb
13、正则表达式解析函数:regexp_extract
语法: regexp_extract(string subject, string pattern, int index) 返回值: string 说明:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符。 举例:
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 1) fromlxw_dual;
the
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 2) fromlxw_dual;
bar
hive> select regexp_extract('foothebar', 'foo(.*?)(bar)', 0) fromlxw_dual;
foothebar
注意,在有些情况下要使用转义字符,下面的等号要用双竖线转义,这是java正则表达式的规则。
select data_field, regexp_extract(data_field,'.*?bgStart\=([^&]+)',1) as aaa, regexp_extract(data_field,'.*?contentLoaded_headStart\=([^&]+)',1) as bbb, regexp_extract(data_field,'.*?AppLoad2Req\=([^&]+)',1) as ccc from pt_nginx_loginlog_st where pt = '2012-03-26'limit 2;
14、URL解析函数:parse_url
语法: parse_url(string urlString, string partToExtract [, stringkeyToExtract]) 返回值: string 说明:返回URL中指定的部分。partToExtract的有效值为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, and USERINFO. 举例:
hive> selectparse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'HOST') fromlxw_dual;
facebook.com
hive> selectparse_url('http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1', 'QUERY','k1') from lxw_dual;
v1
15、json解析函数:get_json_object
语法: get_json_object(string json_string, string path) 返回值: string 说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL。 举例:
hive> select get_json_object('{"store":
> {"fruit":[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}],
> "bicycle":{"price":19.95,"color":"red"}
> },
> "email":"amy@only_for_json_udf_test.net",
> "owner":"amy"
> }
> ','$.owner') from lxw_dual;
> amy
16、空格字符串函数:space
语法: space(int n) 返回值: string 说明:返回长度为n的字符串 举例:
hive> select space(10) from lxw_dual; hive> select length(space(10)) from lxw_dual; 10
17、重复字符串函数:repeat
语法: repeat(string str, int n) 返回值: string 说明:返回重复n次后的str字符串 举例:
hive> select repeat('abc',5) from lxw_dual;
abcabcabcabcabc
18、首字符ascii函数:ascii
语法: ascii(string str) 返回值: int 说明:返回字符串str第一个字符的ascii码 举例:
hive> select ascii('abcde') from lxw_dual;
97
19、左补足函数:lpad
语法: lpad(string str, int len, string pad) 返回值: string 说明:将str进行用pad进行左补足到len位 举例:
hive> select lpad('abc',10,'td') from lxw_dual;
tdtdtdtabc
注意:与GP,ORACLE不同,pad 不能默认
注意:与GP,ORACLE不同,pad 不能默认
20、右补足函数:rpad
语法: rpad(string str, int len, string pad) 返回值: string 说明:将str进行用pad进行右补足到len位 举例:
hive> select rpad('abc',10,'td') from lxw_dual;
abctdtdtdt
21、分割字符串函数: split
语法: split(string str, stringpat) 返回值: array 说明: 按照pat字符串分割str,会返回分割后的字符串数组 举例:
hive> select split('abtcdtef','t') from lxw_dual;
["ab","cd","ef"]
22、集合查找函数:find_in_set
语法: find_in_set(string str, string strList) 返回值: int 说明: 返回str在strlist第一次出现的位置,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0 举例:
hive> select find_in_set('ab','ef,ab,de') from lxw_dual;
2
hive> select find_in_set('at','ef,ab,de') from lxw_dual;
0
十、集合统计函数
1、个数统计函数: count
语法: count(), count(expr), count(DISTINCT expr[, expr_.]) 返回值: int 说明: count()统计检索出的行的个数,包括NULL值的行;count(expr)返回指定字段的非空值的个数;count(DISTINCTexpr[, expr_.])返回指定字段的不同的非空值的个数 举例:
hive> select count(*) from lxw_dual; 20 hive> select count(distinct t) from lxw_dual; 10
2、总和统计函数: sum
语法: sum(col), sum(DISTINCT col) 返回值: double 说明: sum(col)统计结果集中col的相加的结果;sum(DISTINCT col)统计结果中col不同值相加的结果 举例:
hive> select sum(t) from lxw_dual; 100 hive> select sum(distinct t) from lxw_dual; 70
3、平均值统计函数: avg
语法: avg(col), avg(DISTINCT col) 返回值: double 说明: avg(col)统计结果集中col的平均值;avg(DISTINCT col)统计结果中col不同值相加的平均值 举例:
hive> select avg(t) from lxw_dual; 50 hive> select avg (distinct t) from lxw_dual; 30
4、最小值统计函数: min
语法: min(col) 返回值: double 说明: 统计结果集中col字段的最小值 举例:
hive> select min(t) from lxw_dual; 20
5、最大值统计函数: max
语法: maxcol) 返回值: double 说明: 统计结果集中col字段的最大值 举例:
hive> select max(t) from lxw_dual; 120
6、非空集合总体变量函数:var_pop
语法: var_pop(col) 返回值: double 说明: 统计结果集中col非空集合的总体变量(忽略null) 举例:
7、非空集合样本变量函数:var_samp
语法: var_samp (col) 返回值: double 说明: 统计结果集中col非空集合的样本变量(忽略null) 举例:
8、总体标准偏离函数:stddev_pop
语法: stddev_pop(col) 返回值: double 说明: 该函数计算总体标准偏离,并返回总体变量的平方根,其返回值与VAR_POP函数的平方根相同 举例:
9、样本标准偏离函数:stddev_samp
语法: stddev_samp (col) 返回值: double 说明: 该函数计算样本标准偏离 举例:
10.中位数函数:percentile
语法: percentile(BIGINT col, p) 返回值: double 说明: 求准确的第pth个百分位数,p必须介于0和1之间,但是col字段目前只支持整数,不支持浮点数类型 举例:
11、中位数函数:percentile
语法: percentile(BIGINT col, array(p1 [, p2]…)) 返回值: array<double> 说明: 功能和上述类似,之后后面可以输入多个百分位数,返回类型也为array<double>,其中为对应的百分位数。 举例:
select percentile(score,<0.2,0.4>) from lxw_dual;
取0.2,0.4位置的数据
12、近似中位数函数:percentile_approx
语法: percentile_approx(DOUBLE col, p [, B]) 返回值: double 说明: 求近似的第pth个百分位数,p必须介于0和1之间,返回类型为double,但是col字段支持浮点类型。参数B控制内存消耗的近似精度,B越大,结果的准确度越高。默认为10,000。当col字段中的distinct值的个数小于B时,结果为准确的百分位数 举例:
13、近似中位数函数:percentile_approx
语法: percentile_approx(DOUBLE col, array(p1 [, p2]…) [, B]) 返回值: array<double> 说明: 功能和上述类似,之后后面可以输入多个百分位数,返回类型也为array<double>,其中为对应的百分位数。 举例:
14、直方图:histogram_numeric
语法: histogram_numeric(col, b) 返回值: array<struct {‘x’,‘y’}> 说明: 以b为基准计算col的直方图信息。 举例:
hive> select histogram_numeric(100,5) from lxw_dual;
[{"x":100.0,"y":1.0}]
十一、复合类型构建操作
1、Map类型构建: map
语法: map (key1, value1, key2, value2, …) 说明:根据输入的key和value对构建map类型 举例:
hive> Create table lxw_test as select map('100','tom','200','mary')as t from lxw_dual;
hive> describe lxw_test;
t map<string,string>
hive> select t from lxw_test;
{"100":"tom","200":"mary"}
2、Struct类型构建: struct
语法: struct(val1, val2, val3, …) 说明:根据输入的参数构建结构体struct类型 举例:
hive> create table lxw_test as select struct('tom','mary','tim')as t from lxw_dual;
hive> describe lxw_test;
t struct<col1:string,col2:string,col3:string>
hive> select t from lxw_test;
{"col1":"tom","col2":"mary","col3":"tim"}
3、array类型构建: array
语法: array(val1, val2, …) 说明:根据输入的参数构建数组array类型 举例:
hive> create table lxw_test as selectarray("tom","mary","tim") as t from lxw_dual;
hive> describe lxw_test;
t array<string>
hive> select t from lxw_test;
["tom","mary","tim"]
十二、复杂类型访问操作
1、array类型访问: A[n]
语法: A[n] 操作类型: A为array类型,n为int类型 说明:返回数组A中的第n个变量值。数组的起始下标为0。比如,A是个值为['foo', 'bar']的数组类型,那么A[0]将返回'foo',而A[1]将返回'bar' 举例:
hive> create table lxw_test as selectarray("tom","mary","tim") as t from lxw_dual;
hive> select t[0],t[1],t[2] from lxw_test;
tom mary tim
2、map类型访问: M[key]
语法: M[key] 操作类型: M为map类型,key为map中的key值 说明:返回map类型M中,key值为指定值的value值。比如,M是值为{'f' -> 'foo', 'b'-> 'bar', 'all' -> 'foobar'}的map类型,那么M['all']将会返回'foobar' 举例:
hive> Create table lxw_test as selectmap('100','tom','200','mary') as t from lxw_dual;
hive> select t['200'],t['100'] from lxw_test;
mary tom
3、struct类型访问: S.x
语法: S.x 操作类型: S为struct类型 说明:返回结构体S中的x字段。比如,对于结构体struct foobar {int foo, int bar},foobar.foo返回结构体中的foo字段 举例:
hive> create table lxw_test as select struct('tom','mary','tim')as t from lxw_dual;
hive> describe lxw_test;
t struct<col1:string,col2:string,col3:string>
hive> select t.col1,t.col3 from lxw_test;
tom tim
十三、复杂类型长度统计函数
1、Map类型长度函数: size(Map<K.V>)
语法: size(Map<K.V>) 返回值: int 说明: 返回map类型的长度 举例:
hive> select size(map('100','tom','101','mary')) from lxw_dual;
2
2、array类型长度函数: size(Array<T>)
语法: size(Array<T>) 返回值: int 说明: 返回array类型的长度 举例:
hive> select size(array('100','101','102','103')) from lxw_dual;
4
3、类型转换函数
类型转换函数: cast 语法: cast(expr as <type>) 返回值: Expected "=" to follow "type" 说明: 返回array类型的长度 举例:
hive> select cast(1 as bigint) from lxw_dual;
三、hive企业实战手册
1、Shell脚本实现hive增量加载
实现思路: 1.每天凌晨将前一天增量的数据从业务系统导出到文本,并FTP到hadoop集群某个主节点上上传路径默认为:/mnt/data/crawler/ 2.主节点上通过shell脚本调用hive命令加载本地增量文件到hive临时表 3.shell脚本中,使用hive sql 实现临时表中的增量数据更新或者新增增量数据到hive主数据表中。 实现步骤:
1.建表语句, 分别创建两张表test_temp, test 表
create table crawler.test_temp( a.id string, a.name string, a.email string, create_time string ) row format delimited fields terminated by ',' stored as textfile ; +++++++++++++++++++++++++++++++++ create table crawler.test( a.id string, a.name string, a.email string, create_time string ) partitioned by (dt string) row format delimited fields terminated by ' ' stored as orc ;
2.编写处理加载本地增量数据到hive临时表的shell脚本test_temp.sh
#! /bin/bash ################################## # 调用格式: # # 脚本名称 [yyyymmdd] # # 日期参数可选,默认是系统日期-1 # ################################## dt='' table=test_temp #获取当前系统日期 sysdate=`date +%Y%m%d` #获取昨日日期,格式: YYYYMMDD yesterday=`date -d yesterday +%Y%m%d` #数据文件地址 file_path=/mnt/data/crawler/ if [ $# -eq 1 ]; then dt=$1 elif [ $# -eq 0 ]; then dt=$yesterday else echo "非法参数!" #0-成功,非0-失败 exit 1 fi filename=$file_path$table'_'$dt'.txt' if [ ! -e $filename ]; then echo "$filename 数据文件不存在!" exit 1 fi hive<<EOF load data local inpath '$filename' overwrite into table crawler.$table; EOF if [ $? -eq 0 ]; then echo "" echo $dt "$table 加载成功!" else echo "" echo $dt "$table 加载失败!" fi
3.增量加载临时数据到主数据表的shell脚本test.sh
#! /bin/bash ################################## table=test #获取当前系统日期 sysdate=`date +%Y%m%d` #实现增量覆盖 hive<<EOF set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; insert overwrite table crawler.test partition (dt) select a.id, a.name, a.email, a.create_time, a.create_time as dt from ( select id, name, email, create_time from crawler.test_temp union all select t.id, t.name, t.email, t.create_time from crawler.test t left outer join crawler.test_temp t1 on t.id = t1.id where t1.id is null ) a; quit; EOF if [ $? -eq 0 ]; then echo $sysdate $0 " 增量抽取完成!" else echo $sysdate $0 " 增量抽取失败!" fi
2、如何统计hive的日志数据
1、应用场景
集团搜索刚上线不久,日志量并不大 。这些日志分布在 5 台前端机,按小时保存,并以小时为周期定时将上一小时产生的数据同步到日志分析机,统计数据要求按小时更新。这些统计项,包括关键词搜索量 pv ,类别访问量,每秒访问量 tps 等等。 基于 hive ,我们将这些数据按天为单位建表,每天一个表,后台脚本根据时间戳将每小时同步过来的 5 台前端机的日志数据合并成一个日志文件,导入 hive 系统,每小时同步的日志数据被追加到当天数据表中,导入完成后,当天各项统计项将被重新计算并输出统计结果。 以上需求若直接基于 hadoop 开发,需要自行管理数据,针对多个统计需求开发不同的 map/reduce 运算任务,对合并、排序等多项操作进行定制,并检测任务运行状态,工作量并不小。但使用 hive ,从导入到分析、排序、去重、结果输出,这些操作都可以运用 hql 语句来解决,一条语句经过处理被解析成几个任务来运行,即使是关键词访问量增量这种需要同时访问多天数据的较为复杂的需求也能通过表关联这样的语句自动完成,节省了大量工作量。
2.实战
1、 分隔符问题 首先遇到的是日志数据的分隔符问题,我们的日志数据的大致格式如下: 2010-05-24 00:00:02@$$@QQ2010@$$@all@$$@NOKIA_1681C@$$@1@$$@10@$$@@$$@-1@$$@10@$$@application@$$@1 从格式可见其分隔符是“ @$$@ ”,这是为了尽可能防止日志正文出现与分隔符相同的字符而导致数据混淆。本来 hive支持在建表的时候指定自定义分隔符的,但经过多次测试发现只支持单个字符的自定义分隔符,像“ @$$@ ”这样的分隔符是不能被支持的,但是我们可以通过对分隔符的定制解决这个问题, hive 的内部分隔符是“ �01 ”,只要把分隔符替换成“�01 ”即可。 经过探索我们发现有两条途径解决这个问题。
a) 自定义 outputformat 和 inputformat 。 Hive 的 outputformat/inputformat 与 hadoop 的 outputformat/inputformat 相当类似, inputformat 负责把输入数据进行格式化,然后提供给 hive , outputformat 负责把 hive 输出的数据重新格式化成目标格式再输出到文件,这种对格式进行定制的方式较为底层,对其进行定制也相对简单,重写 InputFormat 中 RecordReader 类中的 next 方法即可。 示例代码如下:
public boolean next(LongWritable key, BytesWritable value)
throws IOException {
while ( reader .next(key, text ) ) {
String strReplace = text .toString().toLowerCase().replace( "@$_$@" , "�01" );
Text txtReplace = new Text();
txtReplace.set(strReplace );
value.set(txtReplace.getBytes(), 0, txtReplace.getLength());
return true ;
}
return false ;
}
重写 HiveIgnoreKeyTextOutputFormat 中 RecordWriter 中的 write 方法,示例代码如下:
public void write (Writable w) throws IOException {
String strReplace = ((Text)w).toString().replace( "�01" , "@$_$@" );
Text txtReplace = new Text();
txtReplace.set(strReplace);
byte [] output = txtReplace.getBytes();
bytesWritable .set(output, 0, output. length );
writer .write( bytesWritable );
}
自定义 outputformat/inputformat 后,在建表时需要指定 outputformat/inputformat ,如下示例:stored as INPUTFORMAT'com.aspire.search.loganalysis.hive.SearchLogInputFormat' OUTPUTFORMAT 'com.aspire.search.loganalysis.hive.SearchLogOutputFormat' b) 通过 SerDe(serialize/deserialize) ,在数据序列化和反序列化时格式化数据。 这种方式稍微复杂一点,对数据的控制能力也要弱一些,它使用正则表达式来匹配和处理数据,性能也会有所影响。但它的优点是可以自定义表属性信息 SERDEPROPERTIES ,在 SerDe 中通过这些属性信息可以有更多的定制行为。 2、 数据导入导出 a) 多版本日志格式的兼容 由于 hive 的应用场景主要是处理冷数据(只读不写),因此它只支持批量导入和导出数据,并不支持单条数据的写入或更新,所以如果要导入的数据存在某些不太规范的行,则需要我们定制一些扩展功能对其进行处理。 我们需要处理的日志数据存在多个版本,各个版本每个字段的数据内容存在一些差异,可能版本 A 日志数据的第二个列是搜索关键字,但版本 B 的第二列却是搜索的终端类型,如果这两个版本的日志直接导入 hive 中,很明显数据将会混乱,统计结果也不会正确。我们的任务是要使多个版本的日志数据能在 hive 数据仓库中共存,且表的 input/output 操作能够最终映射到正确的日志版本的正确字段。 这里我们不关心这部分繁琐的工作,只关心技术实现的关键点,这个功能该在哪里实现才能让 hive 认得这些不同格式的数据呢?经过多方尝试,在中间任何环节做这个版本适配都将导致复杂化,最终这个工作还是在 inputformat/outputformat 中完成最为优雅,毕竟 inputformat 是源头, outputformat 是最终归宿。具体来说,是在前面提到的 inputformat 的 next 方法中和在 outputformat 的 write 方法中完成这个适配工作。
b)Hive 操作本地数据 一开始,总是把本地数据先传到 HDFS ,再由 hive 操作 hdfs 上的数据,然后再把数据从 HDFS 上传回本地数据。后来发现大可不必如此, hive 语句都提供了“ local ”关键字,支持直接从本地导入数据到 hive ,也能从 hive 直接导出数据到本地,不过其内部计算时当然是用 HDFS 上的数据,只是自动为我们完成导入导出而已。
3、数据处理
日志数据的统计处理在这里反倒没有什么特别之处,就是一些 SQL 语句而已,也没有什么高深的技巧,不过还是列举一些语句示例,以示 hive 处理数据的方便之处,并展示 hive 的一些用法。 a) 为 hive 添加用户定制功能,自定义功能都位于 hive_contrib.jar 包中
add jar /opt/hadoop/hive-0.5.0-bin/lib/hive_contrib.jar;
b) 统计每个关键词的搜索量,并按搜索量降序排列,然后把结果存入表 keyword_20100603 中
create table keyword_20100603 as select keyword,count(keyword) as count from searchlog_20100603 group by keyword order by count desc;
c) 统计每类用户终端的搜索量,并按搜索量降序排列,然后把结果存入表 device_20100603 中
create table device_20100603 as select device,count(device) as count from searchlog_20100603 group by device order by count desc;
d) 创建表 time_20100603 ,使用自定义的 INPUTFORMAT 和 OUTPUTFORMAT ,并指定表数据的真实存放位置在 '/LogAnalysis/results/time_20100603' ( HDFS 路径),而不是放在 hive 自己的数据目录中
create external table if not exists time_20100603(time string, count int) stored as INPUTFORMAT 'com.aspire.search.loganalysis.hive.XmlResultInputFormat' OUTPUTFORMAT 'com.aspire.search.loganalysis.hive.XmlResultOutputFormat' LOCATION '/LogAnalysis/results/time_20100603';
e) 统计每秒访问量 TPS ,按访问量降序排列,并把结果输出到表 time_20100603 中,这个表我们在上面刚刚定义过,其真实位置在 '/LogAnalysis/results/time_20100603' ,并且由于 XmlResultOutputFormat 的格式化,文件内容是 XML 格式。
insert overwrite table time_20100603 select time,count(time) as count from searchlog_20100603 group by time order by count desc;
f) 计算每个搜索请求响应时间的最大值,最小值和平均值
insert overwrite table response_20100603 select max(responsetime) as max,min(responsetime) as min,avg(responsetime) as avg from searchlog_20100603;
g) 创建一个表用于存放今天与昨天的关键词搜索量和增量及其增量比率,表数据位于
'/LogAnalysis/results/keyword_20100604_20100603' ,内容将是 XML 格式。 create external table if not exists keyword_20100604_20100603(keyword string, count int, increment int, incrementrate double) stored as INPUTFORMAT 'com.aspire.search.loganalysis.hive.XmlResultInputFormat' OUTPUTFORMAT 'com.aspire.search.loganalysis.hive.XmlResultOutputFormat' LOCATION '/LogAnalysis/results/keyword_20100604_20100603';
h) 设置表的属性,以便 XmlResultInputFormat 和 XmlResultOutputFormat 能根据 output.resulttype 的不同内容输出不同格式的 XML 文件。
alter table keyword_20100604_20100603 set tblproperties ('output.resulttype'='keyword');
i) 关联今天关键词统计结果表( keyword_20100604 )与昨天关键词统计结果表( keyword_20100603 ),统计今天与昨天同时出现的关键词的搜索次数,今天相对昨天的增量和增量比率,并按增量比率降序排列,结果输出到刚刚定义的 keyword_20100604_20100603 表中,其数据文件内容将为 XML 格式。
insert overwrite table keyword_20100604_20100603 select cur.keyword, cur.count, cur.count-yes.count as increment, (cur.count-yes.count)/yes.count as incrementrate from keyword_20100604 cur join keyword_20100603 yes on (cur.keyword = yes.keyword) order by incrementrate desc;
4、 用户自定义函数 UDF
部分统计结果需要以 CSV 的格式输出,对于这类文件体全是有效内容的文件,不需要像 XML 一样包含 version , encoding 等信息的文件头,最适合用 UDF(user define function) 了。 UDF 函数可直接应用于 select 语句,对查询结构做格式化处理之后,再输出内容。自定义 UDF 需要继承 org.apache.hadoop.hive.ql.exec.UDF ,并实现 evaluate 函数, Evaluate 函数支持重载,还支持可变参数。我们实现了一个支持可变字符串参数的 UDF ,支持把 select 得出的任意个数的不同类型数据转换为字符串后,按 CSV 格式输出,由于代码较简单,这里给出源码示例:
public String evaluate(String... strs) {
StringBuilder sb = new StringBuilder();
for ( int i = 0; i < strs. length ; i++) {
sb.append(ConvertCSVField(strs[i])).append( ',' );
}
sb.deleteCharAt(sb.length()-1);
return sb.toString();
}
需要注意的是,要使用 UDF 功能,除了实现自定义 UDF 外,还需要加入包含 UDF 的包,示例: add jar /opt/hadoop/hive-0.5.0-bin/lib/hive_contrib.jar; 然后创建临时方法,示例: CREATE TEMPORARY FUNCTION Result2CSv AS ‘com.aspire.search.loganalysis.hive. Result2CSv'; 使用完毕还要 drop 方法,示例: DROP TEMPORARY FUNCTION Result2CSv;
5、 输出 XML 格式的统计结果
前面看到部分日志统计结果输出到一个表中,借助 XmlResultInputFormat 和 XmlResultOutputFormat 格式化成 XML 文件,考虑到创建这个表只是为了得到 XML 格式的输出数据,我们只需实现 XmlResultOutputFormat 即可,如果还要支持 select 查询,则我们还需要实现 XmlResultInputFormat ,这里我们只介绍 XmlResultOutputFormat 。 前面介绍过,定制 XmlResultOutputFormat 我们只需重写 write 即可,这个方法将会把 hive 的以 ’�01’ 分隔的多字段数据格式化为我们需要的 XML 格式,被简化的示例代码如下:
public void write(Writable w) throws IOException {
String[] strFields = ((Text) w).toString().split( "�01" );
StringBuffer sbXml = new StringBuffer();
if ( strResultType .equals( "keyword" )) {
sbXml.append( "<record><keyword>" ).append(strFields[0]).append(
"</keyword><count>" ).append(strFields[1]).append( "</count><increment>" ).append(strFields[2]).append(
"</increment><rate>" ).append(strFields[3]).append(
"</rate></result>" );
}
Text txtXml = new Text();
byte [] strBytes = sbXml.toString().getBytes( "utf-8" );
txtXml.set(strBytes, 0, strBytes. length );
byte [] output = txtXml.getBytes();
bytesWritable .set(output, 0, output. length );
writer .write( bytesWritable );
}
其中的 strResultType .equals( "keyword" ) 指定关键词统计结果,这个属性来自以下语句对结果类型的指定,通过这个属性我们还可以用同一个 outputformat 输出多种类型的结果。
alter table keyword_20100604_20100603 set tblproperties ('output.resulttype'='keyword');
仔细看看 write 函数的实现便可发现,其实这里只输出了 XML 文件的正文,而 XML 的文件头和结束标签在哪里输出呢?所幸我们采用的是基于 outputformat 的实现,我们可以在构造函数输出 version , encoding 等文件头信息,在 close() 方法中输出结束标签。
这也是我们为什么不使用 UDF 来输出结果的原因,自定义 UDF 函数不能输出文件头和文件尾,对于 XML 格式的数据无法输出完整格式,只能输出 CSV 这类所有行都是有效数据的文件。
3、用蜂房进行逆回购分析,实现余额宝背后的逻辑
问题导读: 1.什么是逆回购? 2.怎样将CSV数据导入蜂巢? 3.怎样用蜂巢统计股票每天每分钟的均价?
一,项目背景
前两年,支付宝推出的“余额宝”赚尽无数人的眼球,同时也吸引的大量的小额资金进入。“余额宝”把用户的散钱利息提高到了年化收益率4.0%左右,比起银行活期存储存款0.3%左右高出太多了,也正在撼动着银行躺着赚钱的地位。
在金融市场,如果想获得年化收益率4%-5%左右也并非难事,通过“逆回购”一样可以。一旦遇到货币紧张时(银行缺钱),更可达到50%一天隔夜回够利率。我们就可以美美地在家里数钱了!
所谓逆回购:通俗来讲,就是你(A)把钱借给别人(B),到期时,B按照约定利息,还给你(A)本资+利息逆回购本身是无风险的(操作银行储蓄存款类似)。现在火热吵起来的,阿里金融的“余额宝”利息与逆回购持平。我们可以猜测“余额宝”的资金也在操作“逆回购”,不仅保持良好的流通性,同时也提供稳定的利息。
二,项目需求分析
通过历史数据分析,找出走势规律,发现当日高点,进行逆回购,赚取最高利息。
三,项目数据集
猛戳此链接下载数据集
网盘下载 链接:https://pan.baidu.com/s/1qBlu0mKn_HspxYr9ksEpAw密码:3672
数据格式如下:
tradedate:交易日期 tradetime:交易时间 stockid:股票身份证 buyprice:买入价格 buysize:买入数量 卖价:卖出价格 sellsize:卖出数量
四,项目思路分析
基于项目的需求,我们可以使用蜂巢工具完成数据的分析。
如图1所示,首先将数据集total.csv导入配置单元中,用日期做为分区表的分区ID。
2,选取自己的股票编号stockid,分别统计该股票产品每日的最高价和最低价。
3,以分钟做为最小单位,统计出所选股票每天每分钟均价。
五,步骤详解
第一步:将数据导入蜂巢中
在hive中,创建股票表结构。
hive> create table if not exists stock(tradedate string, tradetime string, stockid string, buyprice double, buysize int, sellprice string, sellsize int) row format delimited fields terminated by ',' stored as textfile;
OK
Time taken: 0.207 seconds
hive> desc stock;
OK
tradedate string
tradetime string
stockid string
buyprice double
buysize int
sellprice string
sellsize int
Time taken: 0.147 seconds, Fetched: 7 row(s)
将HDFS中的股票历史数据导入蜂巢中。
[hadoop@master bin]$ cd /home/hadoop/test/
[hadoop@master test]$ sudo rz
hive> load data local inpath ‘/home/handoop/test/stock.csv’ into table stock;
创建分区表stock_partition,用日期做为分区表的分区ID。
hive> create table if not exists stock_partition(tradetime string, stockid string, buyprice double, buysize int, sellprice string, sellsize int) partitioned by (tradedate string) row format delimited fields terminated by ',';
OK
Time taken: 0.112 seconds
hive> desc stock_partition;
OK
tradetime string
stockid string
buyprice double
buysize int
sellprice string
sellsize int
tradedate string
# Partition Information
# col_name data_type comment
tradedate string
如果设置动态分区首先执行。
hive>set hive.exec.dynamic.partition.mode=nonstrict;
创建动态分区,将库存表中的数据导入stock_partition表。
hive> insert overwrite table stock_partition partition(tradedate) select tradetime, stockid, buyprice, buysize, sellprice, sellsize, tradedate from stock distribute by tradedate;
Query ID = hadoop_20180524122020_f7a1b61a-84ed-4487-a37e-64ef9c3abc5f
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1527103938304_0002, Tracking URL = http://master:8088/proxy/application_1527103938304_0002/
Kill Command = /opt/modules/hadoop-2.6.0/bin/hadoop job -kill job_1527103938304_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-05-24 12:20:13,931 Stage-1 map = 0%, reduce = 0%
2018-05-24 12:20:21,434 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.19 sec
2018-05-24 12:20:40,367 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.87 sec
MapReduce Total cumulative CPU time: 5 seconds 870 msec
Ended Job = job_1527103938304_0002
Loading data to table default.stock_partition partition (tradedate=null)
Time taken for load dynamic partitions : 492
Loading partition {tradedate=20130726}
Loading partition {tradedate=20130725}
Loading partition {tradedate=20130724}
Loading partition {tradedate=20130723}
Loading partition {tradedate=20130722}
Time taken for adding to write entity : 6
Partition default.stock_partition{tradedate=20130722} stats: [numFiles=1, numRows=25882, totalSize=918169, rawDataSize=892287]
Partition default.stock_partition{tradedate=20130723} stats: [numFiles=1, numRows=26516, totalSize=938928, rawDataSize=912412]
Partition default.stock_partition{tradedate=20130724} stats: [numFiles=1, numRows=25700, totalSize=907048, rawDataSize=881348]
Partition default.stock_partition{tradedate=20130725} stats: [numFiles=1, numRows=20910, totalSize=740877, rawDataSize=719967]
Partition default.stock_partition{tradedate=20130726} stats: [numFiles=1, numRows=24574, totalSize=862861, rawDataSize=838287]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.87 sec HDFS Read: 5974664 HDFS Write: 4368260 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 870 msec
OK
Time taken: 39.826 seconds
第二步:蜂巢自定义UDF,统计204001该只股票每日的最高价和最低价
Hive自定义Max统计最大值。
package zimo.hadoop.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* @function 自定义UDF统计最大值
* @author Zimo
*
*/
public class Max extends UDF{
public Double evaluate(Double a, Double b) {
if(a == null)
a=0.0;
if(b == null)
b=0.0;
if(a >= b){
return a;
} else {
return b;
}
}
}
Hive自定义Min统计最小值。
package zimo.hadoop.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* @function 自定义UDF统计最小值
* @author Zimo
*
*/
public class Min extends UDF{
public Double evaluate(Double a, Double b) {
if(a == null)
a = 0.0;
if(b == null)
b = 0.0;
if(a >= b){
return b;
} else {
return a;
}
}
}
将自定义的Max和Min分别打包成maxUDF.jar和minUDF.jar,然后上传至/ home / hadoop / hive目录下,添加Hive自定义的UDF函数
[hadoop@master ~]$ cd $HIVE_HOME
[hadoop@master hive1.0.0]$ sudo mkdir jar/
[hadoop@master hive1.0.0]$ ll
total 408
drwxr-xr-x 4 hadoop hadoop 4096 May 24 06:15 bin
drwxr-xr-x 2 hadoop hadoop 4096 May 24 05:53 conf
drwxr-xr-x 4 hadoop hadoop 4096 May 14 23:28 examples
drwxr-xr-x 7 hadoop hadoop 4096 May 14 23:28 hcatalog
drwxrwxr-x 3 hadoop hadoop 4096 May 24 11:50 iotmp
drwxr-xr-x 2 root root 4096 May 24 12:34 jar
drwxr-xr-x 4 hadoop hadoop 4096 May 14 23:41 lib
-rw-r--r-- 1 hadoop hadoop 23828 Jan 30 2015 LICENSE
drwxr-xr-x 2 hadoop hadoop 4096 May 24 03:36 logs
-rw-r--r-- 1 hadoop hadoop 397 Jan 30 2015 NOTICE
-rw-r--r-- 1 hadoop hadoop 4044 Jan 30 2015 README.txt
-rw-r--r-- 1 hadoop hadoop 345744 Jan 30 2015 RELEASE_NOTES.txt
drwxr-xr-x 3 hadoop hadoop 4096 May 14 23:28 scripts
[hadoop@master hive1.0.0]$ cd jar/
[hadoop@master jar]$ sudo rz
[hadoop@master jar]$ ll
total 8
-rw-r--r-- 1 root root 714 May 24 2018 maxUDF.jar
-rw-r--r-- 1 root root 713 May 24 2018 minUDF.jar
hive> add jar /opt/modules/hive1.0.0/jar/maxUDF.jar;
Added [/opt/modules/hive1.0.0/jar/maxUDF.jar] to class path
Added resources: [/opt/modules/hive1.0.0/jar/maxUDF.jar]
hive> add jar /opt/modules/hive1.0.0/jar/minUDF.jar;
Added [/opt/modules/hive1.0.0/jar/minUDF.jar] to class path
Added resources: [/opt/modules/hive1.0.0/jar/minUDF.jar]
创建蜂巢自定义的临时方法maxprice和minprice。
hive> create temporary function maxprice as 'zimo.hadoop.hive.Max';
OK
Time taken: 0.009 seconds
hive> create temporary function minprice as 'zimo.hadoop.hive.Min';
OK
Time taken: 0.004 seconds
统计204001股票,每日的最高价格和最低价格。
hive> select stockid, tradedate, max(maxprice(buyprice,sellprice)), min(minprice(buyprice,sellprice)) from stock_partition where stockid='204001' group by tradedate;
20130722 4.05 0.0
20130723 4.48 2.2
20130724 4.65 2.205
20130725 11.9 8.7
20130726 12.3 5.2
第三步:统计每分钟均价
统计204001这只股票,每天每分钟的均价 hive> select stockid, tradedate, substring(tradetime,0,4), sum(buyprice+sellprice)/(count(*)*2) from stock_partition where stockid='204001' group by stockid, tradedate, substring(tradetime,0,4); 20130725 0951 9.94375 20130725 0952 9.959999999999999 20130725 0953 10.046666666666667 20130725 0954 10.111041666666667 20130725 0955 10.132500000000002 20130725 0956 10.181458333333333 20130725 0957 10.180625 20130725 0958 10.20340909090909 20130725 0959 10.287291666666667 20130725 1000 10.331041666666668 20130725 1001 10.342500000000001 20130725 1002 10.344375 20130725 1003 10.385 20130725 1004 10.532083333333333 20130725 1005 10.621041666666667 20130725 1006 10.697291666666667 20130725 1007 10.702916666666667 20130725 1008 10.78
4、Hive分析窗口函数,立方体。上钻下取等
问题导读 1.GROUPING SETS与另外哪种方式等价? 2.根据GROUP BY的维度的所有组合进行聚合由哪个关键字完成? 3.ROLLUP与ROLLUP关系是什么? 数据准备
2015-03,2015-03-10,cookie1 2015-03,2015-03-10,cookie5 2015-03,2015-03-12,cookie7 2015-04,2015-04-12,cookie3 2015-04,2015-04-13,cookie2 2015-04,2015-04-13,cookie4 2015-04,2015-04-16,cookie4 2015-03,2015-03-10,cookie2 2015-03,2015-03-10,cookie3 2015-04,2015-04-12,cookie5 2015-04,2015-04-13,cookie6 2015-04,2015-04-15,cookie3 2015-04,2015-04-15,cookie2 2015-04,2015-04-16,cookie1 CREATE EXTERNAL TABLE lxw1234 ( month STRING, day STRING, cookieid STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' stored as textfile location '/tmp/lxw11/';
hive> select * from lxw1234; OK 2015-03 2015-03-10 cookie1 2015-03 2015-03-10 cookie5 2015-03 2015-03-12 cookie7 2015-04 2015-04-12 cookie3 2015-04 2015-04-13 cookie2 2015-04 2015-04-13 cookie4 2015-04 2015-04-16 cookie4 2015-03 2015-03-10 cookie2 2015-03 2015-03-10 cookie3 2015-04 2015-04-12 cookie5 2015-04 2015-04-13 cookie6 2015-04 2015-04-15 cookie3 2015-04 2015-04-15 cookie2 2015-04 2015-04-16 cookie1
1、GROUPING SETS
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID FROM lxw1234 GROUP BY month,day GROUPING SETS (month,day) ORDER BY GROUPING__ID; month day uv GROUPING__ID ------------------------------------------------ 2015-03 NULL 5 1 2015-04 NULL 6 1 NULL 2015-03-10 4 2 NULL 2015-03-12 1 2 NULL 2015-04-12 2 2 NULL 2015-04-13 3 2 NULL 2015-04-15 2 2 NULL 2015-04-16 2 2 等价于 SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM lxw1234 GROUP BY month UNION ALL SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM lxw1234 GROUP BY day
再如
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID FROM lxw1234 GROUP BY month,day GROUPING SETS (month,day,(month,day)) ORDER BY GROUPING__ID; month day uv GROUPING__ID ------------------------------------------------ 2015-03 NULL 5 1 2015-04 NULL 6 1 NULL 2015-03-10 4 2 NULL 2015-03-12 1 2 NULL 2015-04-12 2 2 NULL 2015-04-13 3 2 NULL 2015-04-15 2 2 NULL 2015-04-16 2 2 2015-03 2015-03-10 4 3 2015-03 2015-03-12 1 3 2015-04 2015-04-12 2 3 2015-04 2015-04-13 3 3 2015-04 2015-04-15 2 3 2015-04 2015-04-16 2 3 等价于 SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM lxw1234 GROUP BY month UNION ALL SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM lxw1234 GROUP BY day UNION ALL SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM lxw1234 GROUP BY month,day
其中的 GROUPING__ID,表示结果属于哪一个分组集合。
2、CUBE
根据GROUP BY的维度的所有组合进行聚合。
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID FROM lxw1234 GROUP BY month,day WITH CUBE ORDER BY GROUPING__ID; month day uv GROUPING__ID -------------------------------------------- NULL NULL 7 0 2015-03 NULL 5 1 2015-04 NULL 6 1 NULL 2015-04-12 2 2 NULL 2015-04-13 3 2 NULL 2015-04-15 2 2 NULL 2015-04-16 2 2 NULL 2015-03-10 4 2 NULL 2015-03-12 1 2 2015-03 2015-03-10 4 3 2015-03 2015-03-12 1 3 2015-04 2015-04-16 2 3 2015-04 2015-04-12 2 3 2015-04 2015-04-13 3 3 2015-04 2015-04-15 2 3 等价于 SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM lxw1234 UNION ALL SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM lxw1234 GROUP BY month UNION ALL SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM lxw1234 GROUP BY day UNION ALL SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM lxw1234 GROUP BY month,day
3、ROLLUP
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
比如,以month维度进行层级聚合: SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID FROM lxw1234 GROUP BY month,day WITH ROLLUP ORDER BY GROUPING__ID; month day uv GROUPING__ID --------------------------------------------------- NULL NULL 7 0 2015-03 NULL 5 1 2015-04 NULL 6 1 2015-03 2015-03-10 4 3 2015-03 2015-03-12 1 3 2015-04 2015-04-12 2 3 2015-04 2015-04-13 3 3 2015-04 2015-04-15 2 3 2015-04 2015-04-16 2 3 可以实现这样的上钻过程: 月天的UV->月的UV->总UV
--把month和day调换顺序,则以day维度进行层级聚合: SELECT day, month, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID FROM lxw1234 GROUP BY day,month WITH ROLLUP ORDER BY GROUPING__ID; day month uv GROUPING__ID ------------------------------------------------------- NULL NULL 7 0 2015-04-13 NULL 3 1 2015-03-12 NULL 1 1 2015-04-15 NULL 2 1 2015-03-10 NULL 4 1 2015-04-16 NULL 2 1 2015-04-12 NULL 2 1 2015-04-12 2015-04 2 3 2015-03-10 2015-03 4 3 2015-03-12 2015-03 1 3 2015-04-13 2015-04 3 3 2015-04-15 2015-04 2 3 2015-04-16 2015-04 2 3 可以实现这样的上钻过程: 天月的UV->天的UV->总UV (这里,根据天和月进行聚合,和根据天聚合结果一样,因为有父子关系,如果是其他维度组合的话,就会不一样)
5、利用HQL统计: 新增用户数,日活,留存率
问题导读
1.每天新增用户数怎么实现? 2.日活怎么实现? 3.留存率怎么实现?  用户行为触发的日志上报,已经存放在Hive的外部分区表中. 结构如下:
用户行为触发的日志上报,已经存放在Hive的外部分区表中. 结构如下:  主要字段内容: dt表示日期,如20160510 platform表示平台,只有两个选项,苹果和安卓 mid是用户机器码,类似于网卡MAC地址什么的 pver是版本 channel是分发渠道
主要字段内容: dt表示日期,如20160510 platform表示平台,只有两个选项,苹果和安卓 mid是用户机器码,类似于网卡MAC地址什么的 pver是版本 channel是分发渠道
现在需要统计每天用户的新增,日活和留存率. 其中 留存率的概念是,如果用户在5月1日第一次使用我们的产品。 如果5月2日他还使用了,那么5月1日的“一日留存”加一. 同理5月3日他又使用了,5月1日的“两日留存”加一. 5月1日的“一日留存率”=5月1日“一日留存” / 5月1日新增用户数量.
先创建一个表,记录用户首次使用的日期.
 dt是用户首次使用的日期,比如 20160510 cver是版本 pcid是用户机器码,就是原始日志表的mid
dt是用户首次使用的日期,比如 20160510 cver是版本 pcid是用户机器码,就是原始日志表的mid
然后创建一个每天数据的存放表,统计昨天一天的新增,日活和留存.  dt是日期 type 1:新增 2:留存 3:日活 num 是用户数量, dtdiff仅仅用于计算留存,说明用户使用和首次使用的日期间隔多少天.
dt是日期 type 1:新增 2:留存 3:日活 num 是用户数量, dtdiff仅仅用于计算留存,说明用户使用和首次使用的日期间隔多少天.
1.Hive统计每天新增用户
$dt是shell传入的变量 dt=$(date -d last-day +%Y%m%d) 该脚本每天凌晨执行,统计昨天的数据. 每次执行,先清空report_userinfo表
insert into user_login_history select platform,min(dt),channel,cver,mid,1 from log_vvim where mid not in (select pcid from user_login_history where type=1) and mid is not null and dt=$dt group by platform,channel,cver,mid;
这个意思就是 原来没有记录在user_grouproom_login_history表中的pcid,如果出现在昨天的日志表中,则说明用户是新增的.
然后将昨天新增的用户数量写入
insert into report_userinfo select platform,dt,channel,cver,type,count(*) num,-1 from user_login_history where type=1 and dt=$dt group by platform,dt,channel,cver,type;
2.统计每天活跃用户数量
insert into report_userinfo select platform,dt,channel,cver,3,count(distinct mid),-1 from log_vvim where mid is not null and dt=$dt group by dt,platform,channel,cver;
这个倒是简单,根据原始的日志表,统计今天使用过的pcid,经过去重的用户就是今天的日活用户量.
3.统计留存率.
insert into report_userinfo
select
xinzeng.platform,
xinzeng.dt,
xinzeng.channel,
xinzeng.cver,
2,
count(distinct cunliu.pcid),
datediff(
from_unixtime(unix_timestamp(cast(cunliu.dt as string),'yyyyMMdd')),
from_unixtime(unix_timestamp(cast(xinzeng.dt as string),'yyyyMMdd'))
)
from
(
select * from user_login_history where type=1
) xinzeng
inner join
(
select
platform,
dt,
channel,
cver,
mid pcid
from log_vvim
where mid is not null and dt=$dt group by platform,dt,channel,cver,mid
) cunliu on
(
xinzeng.platform=cunliu.platform and
xinzeng.channel=cunliu.channel and
xinzeng.cver=cunliu.cver and
xinzeng.pcid=cunliu.pcid
)
where cunliu.dt>xinzeng.dt
group by
xinzeng.platform,xinzeng.dt,xinzeng.channel,xinzeng.cver,
datediff(
from_unixtime(unix_timestamp(cast(cunliu.dt as string),'yyyyMMdd')),
from_unixtime(unix_timestamp(cast(xinzeng.dt as string),'yyyyMMdd'))
);
该SQL主要计算昨天使用过的用户,他的首次使用日期,然后计算差值  表示安卓平台,20160425那天首次使用的用户,在8天之后,还使用过的用户数量为20人。
表示安卓平台,20160425那天首次使用的用户,在8天之后,还使用过的用户数量为20人。
因为计算新增和日活在计算留存之前, cunliu.dt>xinzeng.dt 主要是确定当天新增的用户不计入留存率计算. 统计完成之后,将hive表导入MySQL
sqoop export --connect jdbc:mysql://IP:端口/report --username uname --password "pwd" --table report_userinfo --export-dir '/user/hive/warehouse/logs.db/report_userinfo' --fields-terminated-by '�01'
最终通过报表展现
6、 基于Hive及Sqoop的每日PV、UV、IP定时分析
基于Hive及Sqoop的每日PV、UV、IP定时分析
1、创建pvuvip的hive表
hive -e "
use stage;
CREATE EXTERNAL TABLE pvuvip(
day string,
pv int,
uv int,
ipcnt int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '
LOCATION '/dw/stage/pvuvip/';"
2、创建mysql关系库的表
CREATE TABLE
pvuvip
(
id INT NOT NULL AUTO_INCREMENT,
DAY VARCHAR(50),
pv INT,
uv INT,
ipcnt INT,
PRIMARY KEY (id)
)
ENGINE=MyISAM DEFAULT CHARSET=latin1
3、每日定时执行的自动化脚本
#!/bin/sh
# upload logs to hdfs
yesterday=`date --date='1 days ago' +%Y%m%d`
hive -e "
use stage;
insert overwrite table pvuvip select day,count(*) pv, count(distinct cookieid) uv , count(distinct ip) ipcnt from ods.tracklog where day='${yesterday}' group by day;"
sqoop export --connect jdbc:mysql://localhost:3306/charts --username root --password 123456 --table pvuvip --fields-terminated-by ' ' --columns "day,pv,uv,ipcnt" --export-dir /dw/stage/pvuvip/;
4、在crontab中增加定时任务
18 06 * * * /opt/bin/sqoop_opt/pvuvip.opt
5、刷新定时任务
/sbin/service crond reload
7、Hive整合HBase——通过Hive读/写 HBase中的表
1、Hive整合HBase原理的实现机制是什么? 2、导入数据的流程有哪些呢? 3、如何分别查看Hive、HBase中的数据?  写在前面一: 本文将Hive与HBase整合在一起,使Hive可以读取HBase中的数据,让Hadoop生态系统中最为常用的两大框架互相结合,相得益彰。
写在前面一: 本文将Hive与HBase整合在一起,使Hive可以读取HBase中的数据,让Hadoop生态系统中最为常用的两大框架互相结合,相得益彰。  写在前面二: 使用软件说明
写在前面二: 使用软件说明  约定所有软件的存放目录: /home/yujianxin
约定所有软件的存放目录: /home/yujianxin
一、Hive整合HBase原理
Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler-0.9.0.jar工具类,如下图  Hive与HBase通信示意图
Hive与HBase通信示意图

二、具体步骤
安装前说明 1、关于Hadoop、HBase、Hive集群的搭建,请参考“基于Hadoop的数据分析综合管理平台之Hadoop、HBase完全分布式集群搭建” 2、本文中Hadoop、HBase、Hive安装路径 2.1、拷贝jar包 删除$HIVE_HOME/lib/下HBase、Zookeeper相关jar
rm -rf $HIVE_HOME/lib/zookeeper-*.jar rm -rf $HIVE_HOME/lib/hbase*.jar
重新拷贝
cp $HBASE_HOME/hbase-0.94.7-security.jar $HIVE_HOME/lib/ cp $HBASE_HOME/lib/zookeeper-3.4.5.jar $HIVE_HOME/lib/
2.2、修改$HIVE_HOME/conf/hive-site.xml mkdir $HIVE_HOME/logs 在尾部添加
<property> <name>hive.querylog.location</name> <value>/home/yujianxin/hive/hive-0.9.0/logs</value> </property> <property> <name>hive.aux.jars.path</name> <value> file:///home/yujianxin/hive/hive-0.9.0/lib/hive-hbase-handler-0.9.0.jar, file:///home/yujianxin/hive/hive-0.9.0/lib/hbase-0.94.7-security.jar, file:///home/yujianxin/hive/hive-0.9.0/lib/zookeeper-3.4.5.jar </value> </property>
修改
<property> <name>hive.zookeeper.quorum</name> <value>master,slave1,slave2</value> </property>
2.3、拷贝hbase-0.94.7-security.jar到所有hadoop节点(包括master)的hadoop/lib下
cp $HBASE_HOME/hbase-0.94.7-security.jar $HADOOP_HOME/lib
2.4、拷贝hbase/conf下的hbase-site.xml文件到所有hadoop节点(包括master)的hadoop/conf下
cp $HBASE_HOME/conf/hbase-site.xml $HADOOP_HOME/conf
三、启动、使用配置后Hive,测试是否配置成功
3.1、启动Hive 集群方式启动
hive --auxpath /home/yujianxin/hive/hive-0.9.0/lib/hive-hbase-handler-0.9.0.jar,/home/ yujianxin/hive/hive-0.9.0/lib/hbase-0.94.7-security.jar,/home/yujianxin/hive/hive-0.9. 0/lib/zookeeper-3.4.5.jar
可以将此启动Hive与HBase整合的命令写成Shell脚本,设置成开机启动  3.2、在Hive中创建HBase识别的表
3.2、在Hive中创建HBase识别的表
CREATE TABLE hbase_hive_1(key int, value string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
TBLPROPERTIES ("hbase.table.name" = "xyz");
hbase.table.name 定义在hbase中的table名称 多列时,data:1,data:2 多列族时,data1:1,data2:1 hbase.columns.mapping 定义在hbase的列族,里面的:key 是固定值而且要保证在表pokes中的foo字段是唯一值
创建有分区的表
CREATE TABLE hbase_hive_2(key int, value string)
partitioned by (day string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val")
TBLPROPERTIES ("hbase.table.name" = "xyz2");
分别查看Hive、HBase中建立的表  3.3、导入数据 新建hive的数据表
3.3、导入数据 新建hive的数据表
create table pokes(foo int,bar string) row format delimited fields terminated by ',';
批量导入数据 
load data local inpath '/home/yujianxin/temp/data1.txt' overwrite into table pokes;
使用sql导入hbase_table_1
SET hive.hbase.bulk=true; insert overwrite table hbase_hive_1 select * from pokes;
导入有分区的表
insert overwrite table hbase_hive_2 partition (day='2012-01-01') select * from pokes;
往Hive中插入数据同时会插入到HBase中
3.4、分别查看Hive、HBase中的数据  OK,到此Hive、HBase整合成功。 下面再给出较复杂的测试例子 情况一、对于在hbase已经存在的表,在hive中使用CREATE EXTERNAL TABLE来建立联系 create external table hive_test (key int,gid map<string,string>,sid map<string,string>,uid map<string,string>) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" ="a:,b:,c:") TBLPROPERTIES ("hbase.table.name" = "test1");
OK,到此Hive、HBase整合成功。 下面再给出较复杂的测试例子 情况一、对于在hbase已经存在的表,在hive中使用CREATE EXTERNAL TABLE来建立联系 create external table hive_test (key int,gid map<string,string>,sid map<string,string>,uid map<string,string>) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" ="a:,b:,c:") TBLPROPERTIES ("hbase.table.name" = "test1");
查询gid字段中value值 
Hive成功读取到HBase中的数据 情况二、如果hbase表test2中的字段为user:gid,user:sid,info:uid,info:level  在hive中建表语句为
在hive中建表语句为
CREATE EXTERNAL TABLE hive_test_2(key int,user map<string,string>,info map<string,string>)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" ="user:,info:")
TBLPROPERTIES ("hbase.table.name" = "test2");
Hive成功读取到HBase中的数据
8、Hive配置文件中配置项的含义详解
问题导读: 1.hive输出格式的配置项是哪个? 2.hive被各种语言调用如何配置? 3.hive提交作业是在hive中还是hadoop中? 4.一个查询的最后一个map/reduce任务输出是否被压缩的标志,通过哪个配置项? 5.当用户自定义了UDF或者SerDe,这些插件的jar都要放到这个目录下,通过那个配置项? 6.每个reducer的大小,默认是1G,输入文件如果是10G,那么就会起10个reducer;通过那个配置项可以配置? 7.group by操作是否允许数据倾斜,通过那个配置项配置? 8.本地模式时,map/reduce的内存使用量该如何配置? 9.在做表join时缓存在内存中的行数,默认25000;通过那个配置项可以修改? 10.是否开启数据倾斜的join优化,通过那个配置项可以优化? 11.并行运算开启时,允许多少作业同时计算,默认是8;该如何修改这个配置项?  hive的配置:
hive的配置:
hive.ddl.output.format:hive的ddl语句的输出格式,默认是text,纯文本,还有json格式,这个是0.90以后才出的新配置;
hive.exec.script.wrapper:hive调用脚本时的包装器,默认是null,如果设置为python的话,那么在做脚本调用操作时语句会变为python <script command>,null的话就是直接执行<script command>;
hive.exec.plan:hive执行计划的文件路径,默认是null,会在运行时自动设置,形如hdfs://xxxx/xxx/xx;
hive.exec.scratchdir:hive用来存储不同阶段的map/reduce的执行计划的目录,同时也存储中间输出结果,默认是/tmp/<user.name>/hive,我们实际一般会按组区分,然后组内自建一个tmp目录存储;
hive.exec.submitviachild:在非local模式下,决定hive是否要在独立的jvm中执行map/reduce;默认是false,也就是说默认map/reduce的作业是在hive的jvm上去提交的;
hive.exec.script.maxerrsize:当用户调用transform或者map或者reduce执行脚本时,最大的序列化错误数,默认100000,一般也不用修改;
hive.exec.compress.output:一个查询的最后一个map/reduce任务输出是否被压缩的标志,默认为false,但是一般会开启为true,好处的话,节省空间不说,在不考虑cpu压力的时候会提高io;
hive.exec.compress.intermediate:类似上个,在一个查询的中间的map/reduce任务输出是否要被压缩,默认false,
hive.jar.path:当使用独立的jvm提交作业时,hive_cli.jar所在的位置,无默认值;
hive.aux.jars.path:当用户自定义了UDF或者SerDe,这些插件的jar都要放到这个目录下,无默认值;
hive.partition.pruning:在编译器发现一个query语句中使用分区表然而未提供任何分区谓词做查询时,抛出一个错误从而保护分区表,默认是nonstrict;(待读源码后细化,网上资料极少)
hive.map.aggr:map端聚合是否开启,默认开启;
hive.join.emit.interval:在发出join结果之前对join最右操作缓存多少行的设定,默认1000;hive jira里有个对该值设置太小的bugfix;
hive.map.aggr.hash.percentmemory:map端聚合时hash表所占用的内存比例,默认0.5,这个在map端聚合开启后使用,
hive.default.fileformat:CREATE TABLE语句的默认文件格式,默认TextFile,其他可选的有SequenceFile、RCFile还有Orc;
hive.merge.mapfiles:在只有map的作业结束时合并小文件,默认开启true;
hive.merge.mapredfiles:在一个map/reduce作业结束后合并小文件,默认不开启false;
hive.merge.size.per.task:作业结束时合并文件的大小,默认256MB;
hive.merge.smallfiles.avgsize:在作业输出文件小于该值时,起一个额外的map/reduce作业将小文件合并为大文件,小文件的基本阈值,设置大点可以减少小文件个数,需要mapfiles和mapredfiles为true,默认值是16MB;
mapred.reduce.tasks:每个作业的reduce任务数,默认是hadoop client的配置1个;
hive.exec.reducers.bytes.per.reducer:每个reducer的大小,默认是1G,输入文件如果是10G,那么就会起10个reducer;
hive.exec.reducers.max:reducer的最大个数,如果在mapred.reduce.tasks设置为负值,那么hive将取该值作为reducers的最大可能值。当然还要依赖(输入文件大小/hive.exec.reducers.bytes.per.reducer)所得出的大小,取其小值作为reducer的个数,hive默认是999;
hive.fileformat.check:加载数据文件时是否校验文件格式,默认是true;
hive.groupby.skewindata:group by操作是否允许数据倾斜,默认是false,当设置为true时,执行计划会生成两个map/reduce作业,第一个MR中会将map的结果随机分布到reduce中,达到负载均衡的目的来解决数据倾斜,
hive.groupby.mapaggr.checkinterval:map端做聚合时,group by 的key所允许的数据行数,超过该值则进行分拆,默认是100000;
hive.mapred.local.mem:本地模式时,map/reduce的内存使用量,默认是0,就是无限制;
hive.mapjoin.followby.map.aggr.hash.percentmemory:map端聚合时hash表的内存占比,该设置约束group by在map join后进行,否则使用hive.map.aggr.hash.percentmemory来确认内存占比,默认值0.3;
hive.map.aggr.hash.force.flush.memeory.threshold:map端聚合时hash表的最大可用内存,如果超过该值则进行flush数据,默认是0.9;
hive.map.aggr.hash.min.reduction:如果hash表的容量与输入行数之比超过这个数,那么map端的hash聚合将被关闭,默认是0.5,设置为1可以保证hash聚合永不被关闭;
hive.optimize.groupby:在做分区和表查询时是否做分桶group by,默认开启true;
hive.multigroupby.singlemr:将多个group by产出为一个单一map/reduce任务计划,当然约束前提是group by有相同的key,默认是false;
hive.optimize.cp:列裁剪,默认开启true,在做查询时只读取用到的列,这个是个有用的优化;
hive.optimize.index.filter:自动使用索引,默认不开启false;
hive.optimize.index.groupby:是否使用聚集索引优化group-by查询,默认关闭false;
hive.optimize.ppd:是否支持谓词下推,默认开启;所谓谓词下推,将外层查询块的 WHERE 子句中的谓词移入所包含的较低层查询块(例如视图),从而能够提早进行数据过滤以及有可能更好地利用索引。
hive.optimize.ppd.storage:谓词下推开启时,谓词是否下推到存储handler,默认开启,在谓词下推关闭时不起作用;
hive.ppd.recognizetransivity:在等值join条件下是否产地重复的谓词过滤器,默认开启;
hive.join.cache.size:在做表join时缓存在内存中的行数,默认25000;
hive.mapjoin.bucket.cache.size:mapjoin时内存cache的每个key要存储多少个value,默认100;
hive.optimize.skewjoin:是否开启数据倾斜的join优化,默认不开启false;
hive.skewjoin.key:判断数据倾斜的阈值,如果在join中发现同样的key超过该值则认为是该key是倾斜的join key,默认是100000;
hive.skewjoin.mapjoin.map.tasks:在数据倾斜join时map join的map数控制,默认是10000;
hive.skewjoin.mapjoin.min.split:数据倾斜join时map join的map任务的最小split大小,默认是33554432,该参数要结合上面的参数共同使用来进行细粒度的控制;
hive.mapred.mode:hive操作执行时的模式,默认是nonstrict非严格模式,如果是strict模式,很多有风险的查询会被禁止运行,比如笛卡尔积的join和动态分区;
hive.exec.script.maxerrsize:一个map/reduce任务允许打印到标准错误里的最大字节数,为了防止脚本把分区日志填满,默认是100000;
hive.exec.script.allow.partial.consumption:hive是否允许脚本不从标准输入中读取任何内容就成功退出,默认关闭false;
hive.script.operator.id.env.var:在用户使用transform函数做自定义map/reduce时,存储唯一的脚本标识的环境变量的名字,默认HIVE_SCRIPT_OPERATOR_ID;
hive.exec.compress.output:控制hive的查询结果输出是否进行压缩,压缩方式在hadoop的mapred.output.compress中配置,默认不压缩false;
hive.exec.compress.intermediate:控制hive的查询中间结果是否进行压缩,同上条配置,默认不压缩false;
hive.exec.parallel:hive的执行job是否并行执行,默认不开启false,在很多操作如join时,子查询之间并无关联可独立运行,这种情况下开启并行运算可以大大加速;
hvie.exec.parallel.thread.number:并行运算开启时,允许多少作业同时计算,默认是8;
hive.exec.rowoffset:是否提供行偏移量的虚拟列,默认是false不提供,Hive有两个虚拟列:一个是INPUTFILENAME,表示输入文件的路径,另外一个是BLOCKOFFSETINSIDE__FILE,表示记录在文件中的块偏移量,这对排查出现不符合预期或者null结果的查询是很有帮助的;
hive.task.progress:控制hive是否在执行过程中周期性的更新任务进度计数器,开启这个配置可以帮助job tracker更好的监控任务的执行情况,但是会带来一定的性能损耗,当动态分区标志hive.exec.dynamic.partition开启时,本配置自动开启;
hive.exec.pre.hooks:执行前置条件,一个用逗号分隔开的实现了org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext接口的java class列表,配置了该配置后,每个hive任务执行前都要执行这个执行前钩子,默认是空;
hive.exec.post.hooks:同上,执行后钩子,默认是空;
hive.exec.failure.hooks:同上,异常时钩子,在程序发生异常时执行,默认是空;
hive.mergejob.maponly:试图生成一个只有map的任务去做merge,前提是支持CombineHiveInputFormat,默认开启true;
hive.mapjoin.smalltable.filesize:输入表文件的mapjoin阈值,如果输入文件的大小小于该值,则试图将普通join转化为mapjoin,默认25MB;
hive.mapjoin.localtask.max.memory.usage:mapjoin本地任务执行时hash表容纳key/value的最大量,超过这个值的话本地任务会自动退出,默认是0.9;
hive.mapjoin.followby.gby.localtask.max.memory.usage:类似上面,只不过是如果mapjoin后有一个group by的话,该配置控制类似这样的query的本地内存容量上限,默认是0.55;
hive.mapjoin.check.memory.rows:在运算了多少行后执行内存使用量检查,默认100000;
hive.heartbeat.interval:发送心跳的时间间隔,在mapjoin和filter操作中使用,默认1000;
hive.auto.convert.join:根据输入文件的大小决定是否将普通join转换为mapjoin的一种优化,默认不开启false;
hive.script.auto.progress:hive的transform/map/reduce脚本执行时是否自动的将进度信息发送给TaskTracker来避免任务没有响应被误杀,本来是当脚本输出到标准错误时,发送进度信息,但是开启该项后,输出到标准错误也不会导致信息发送,因此有可能会造成脚本有死循环产生,但是TaskTracker却没有检查到从而一直循环下去;
hive.script.serde:用户脚本转换输入到输出时的SerDe约束,默认是org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe;
hive.script.recordreader:从脚本读数据的时候的默认reader,默认是org.apache.hadoop.hive.ql.exec.TextRecordReader;
hive.script.recordwriter:写数据到脚本时的默认writer,默认org.apache.hadoop.hive.ql.exec.TextRecordWriter;
hive.input.format:输入格式,默认是org.apache.hadoop.hive.ql.io.CombineHiveInputFormat,如果出现问题,可以改用org.apache.hadoop.hive.ql.io.HiveInputFormat;
hive.udtf.auto.progress:UDTF执行时hive是否发送进度信息到TaskTracker,默认是false;
hive.mapred.reduce.tasks.speculative.execution:reduce任务推测执行是否开启,默认是true;
hive.exec.counters.pull.interval:运行中job轮询JobTracker的时间间隔,设置小会影响JobTracker的load,设置大可能看不出运行任务的信息,要去平衡,默认是1000;
hive.enforce.bucketing:数据分桶是否被强制执行,默认false,如果开启,则写入table数据时会启动分桶,
hive.enforce.sorting:开启强制排序时,插数据到表中会进行强制排序,默认false;
hive.optimize.reducededuplication:如果数据已经根据相同的key做好聚合,那么去除掉多余的map/reduce作业,此配置是文档的推荐配置,建议打开,默认是true;
hive.exec.dynamic.partition:在DML/DDL中是否支持动态分区,默认false;
hive.exec.dynamic.partition.mode:默认strict,在strict模式下,动态分区的使用必须在一个静态分区确认的情况下,其他分区可以是动态;
hive.exec.max.dynamic.partitions:动态分区的上限,默认1000;
hive.exec.max.dynamic.partitions.pernode:每个mapper/reducer节点可以创建的最大动态分区数,默认100;
hive.exec.max.created.files:一个mapreduce作业能创建的HDFS文件最大数,默认是100000;
hive.exec.default.partition.name:当动态分区启用时,如果数据列里包含null或者空字符串的话,数据会被插入到这个分区,默认名字是HIVE_DEFAULT_PARTITION;
hive.fetch.output.serde:FetchTask序列化fetch输出时需要的SerDe,默认是org.apache.hadoop.hive.serde2.DelimitedJSONSerDe;
hive.exec.mode.local.auto:是否由hive决定自动在local模式下运行,默认是false,
hive.exec.drop.ignorenoneexistent:在drop表或者视图时如果发现表或视图不存在,是否报错,默认是true;
hive.exec.show.job.failure.debug.info:在作业失败时是否提供一个任务debug信息,默认true;
hive.auto.progress.timeout:运行自动progressor的时间间隔,默认是0等价于forever;
hive.table.parameters.default:新建表的属性字段默认值,默认是empty空;
hive.variable.substitute:是否支持变量替换,如果开启的话,支持语法如${var} ${system:var}和${env.var},默认是true;
hive.error.on.empty.partition:在遇到结果为空的动态分区时是否报错,默认是false;
hive.exim.uri.scheme.whitelist:在导入导出数据时提供的一个白名单列表,列表项之间由逗号分隔,默认hdfs,pfile;
hive.limit.row.max.size:字面意思理解就是在使用limit做数据的子集查询时保证的最小行数据量,默认是100000;
hive.limit.optimize.limit.file:使用简单limit查询数据子集时,可抽样的最大文件数,默认是10;
hive.limit.optimize.enable:使用简单limit抽样数据时是否开启优化选项,默认是false,关于limit的优化问题,在hive programming书中解释的是这个feature有drawback,对于抽样的不确定性给出了风险提示;
hive.limit.optimize.fetch.max:使用简单limit抽样数据允许的最大行数,默认50000,查询query受限,insert不受影响;
hive.rework.mapredwork:是否重做mapreduce,默认是false;
hive.sample.seednumber:用来区分抽样的数字,默认是0;
hive.io.exception.handlers:io异常处理handler类列表,默认是空,当record reader发生io异常时,由这些handler来处理异常;
hive.autogen.columnalias.prefix.label:当在执行中自动产生列别名的前缀,当类似count这样的聚合函数起作用时,如果不明确指出count(a) as xxx的话,那么默认会从列的位置的数字开始算起添加,比如第一个count的结果会冠以列名c0,接下来依次类推,默认值是c,数据开发过程中应该很多人都看到过这个别名;
hive.autogen.columnalias.prefix.includefuncname:在自动生成列别名时是否带函数的名字,默认是false;
hive.exec.perf.logger:负责记录客户端性能指标的日志类名,必须是org.apache.hadoop.hive.ql.log.PerfLogger的子类,默认是org.apache.hadoop.hive.ql.log.PerfLogger;
hive.start.cleanup.scratchdir:当启动hive服务时是否清空hive的scratch目录,默认是false;
hive.output.file.extension:输出文件扩展名,默认是空;
hive.insert.into.multilevel.dirs:是否插入到多级目录,默认是false;
hive.files.umask.value:hive创建文件夹时的dfs.umask值,默认是0002;
hive.metastore.local:控制hive是否连接一个远程metastore服务器还是开启一个本地客户端jvm,默认是true,Hive0.10已经取消了该配置项;
javax.jdo.option.ConnectionURL:JDBC连接字符串,默认jdbc:derby:;databaseName=metastore_db;create=true;
javax.jdo.option.ConnectionDriverName:JDBC的driver,默认org.apache.derby.jdbc.EmbeddedDriver;
javax.jdo.PersisteneManagerFactoryClass:实现JDO PersistenceManagerFactory的类名,默认org.datanucleus.jdo.JDOPersistenceManagerFactory;
javax.jdo.option.DetachAllOnCommit:事务提交后detach所有提交的对象,默认是true;
javax.jdo.option.NonTransactionalRead:是否允许非事务的读,默认是true;
javax.jdo.option.ConnectionUserName:username,默认APP;
javax.jdo.option.ConnectionPassword:password,默认mine;
javax.jdo.option.Multithreaded:是否支持并发访问metastore,默认是true;
datanucleus.connectionPoolingType:使用连接池来访问JDBC metastore,默认是DBCP;
datanucleus.validateTables:检查是否存在表的schema,默认是false;
datanucleus.validateColumns:检查是否存在列的schema,默认false;
datanucleus.validateConstraints:检查是否存在constraint的schema,默认false;
datanucleus.stroeManagerType:元数据存储类型,默认rdbms;
datanucleus.autoCreateSchema:在不存在时是否自动创建必要的schema,默认是true;
datanucleus.aotuStartMechanismMode:如果元数据表不正确,抛出异常,默认是checked;
datanucleus.transactionIsolation:默认的事务隔离级别,默认是read-committed;
datanucleus.cache.level2:使用二级缓存,默认是false;
datanucleus.cache.level2.type:二级缓存的类型,有两种,SOFT:软引用,WEAK:弱引用,默认是SOFT;
datanucleus.identifierFactory:id工厂生产表和列名的名字,默认是datanucleus;
datanucleus.plugin.pluginRegistryBundleCheck:当plugin被发现并且重复时的行为,默认是LOG;
hive.metastroe.warehouse.dir:数据仓库的位置,默认是/user/hive/warehouse;
hive.metastore.execute.setugi:非安全模式,设置为true会令metastore以客户端的用户和组权限执行DFS操作,默认是false,这个属性需要服务端和客户端同时设置;
hive.metastore.event.listeners:metastore的事件监听器列表,逗号隔开,默认是空;
hive.metastore.partition.inherit.table.properties:当新建分区时自动继承的key列表,默认是空;
hive.metastore.end.function.listeners:metastore函数执行结束时的监听器列表,默认是空;
hive.metastore.event.expiry.duration:事件表中事件的过期时间,默认是0;
hive.metastore.event.clean.freq:metastore中清理过期事件的定时器的运行周期,默认是0;
hive.metastore.connect.retries:创建metastore连接时的重试次数,默认是5;
hive.metastore.client.connect.retry.delay:客户端在连续的重试连接等待的时间,默认1;
hive.metastore.client.socket.timeout:客户端socket超时时间,默认20秒;
hive.metastore.rawstore.impl:原始metastore的存储实现类,默认是org.apache.hadoop.hive.metastore.ObjectStore;
hive.metastore.batch.retrieve.max:在一个batch获取中,能从metastore里取出的最大记录数,默认是300;
hive.metastore.ds.connection.url.hook:查找JDO连接url时hook的名字,默认是javax.jdo.option.ConnectionURL;
hive.metastore.ds.retry.attempts:当出现连接错误时重试连接的次数,默认是1次;
hive.metastore.ds.retry.interval:metastore重试连接的间隔时间,默认1000毫秒;
hive.metastore.server.min.threads:在thrift服务池中最小的工作线程数,默认是200;
hive.metastore.server.max.threads:最大线程数,默认是100000;
hive.metastore.server.tcp.keepalive:metastore的server是否开启长连接,长连可以预防半连接的积累,默认是true;
hive.metastore.sasl.enabled:metastore thrift接口的安全策略,开启则用SASL加密接口,客户端必须要用Kerberos机制鉴权,默认是不开启false;
hive.metastore.kerberos.keytab.file:在开启sasl后kerberos的keytab文件存放路径,默认是空;
hive.metastore.kerberos.principal:kerberos的principal,HOST部分会动态替换,默认是hive-metastore/HOST@EXAMPLE.COM;
hive.metastore.cache.pinobjtypes:在cache中支持的metastore的对象类型,由逗号分隔,默认是Table,StorageDescriptor,SerDeInfo,Partition,Database,Type,FieldSchema,Order;
hive.metastore.authorization.storage.checks:在做类似drop partition操作时,metastore是否要认证权限,默认是false;
hive.metastore.schema.verification:强制metastore的schema一致性,开启的话会校验在metastore中存储的信息的版本和hive的jar包中的版本一致性,并且关闭自动schema迁移,用户必须手动的升级hive并且迁移schema,关闭的话只会在版本不一致时给出警告,默认是false不开启;
hive.index.compact.file.ignore.hdfs:在索引文件中存储的hdfs地址将在运行时被忽略,如果开启的话;如果数据被迁移,那么索引文件依然可用,默认是false;
hive.optimize.index.filter.compact.minsize:压缩索引自动应用的最小输入大小,默认是5368709120;
hive.optimize.index.filter.compact.maxsize:同上,相反含义,如果是负值代表正无穷,默认是-1;
hive.index.compact.query.max.size:一个使用压缩索引做的查询能取到的最大数据量,默认是10737418240 个byte;负值代表无穷大;
hive.index.compact.query.max.entries:使用压缩索引查询时能读到的最大索引项数,默认是10000000;负值代表无穷大;
hive.index.compact.binary.search:在索引表中是否开启二分搜索进行索引项查询,默认是true;
hive.exec.concatenate.check.index:如果设置为true,那么在做ALTER TABLE tbl_name CONCATENATE on a table/partition(有索引) 操作时,抛出错误;可以帮助用户避免index的删除和重建;
hive.stats.dbclass:存储hive临时统计信息的数据库,默认是jdbc:derby;
hive.stats.autogather:在insert overwrite命令时自动收集统计信息,默认开启true;
hive.stats.jdbcdriver:数据库临时存储hive统计信息的jdbc驱动;
hive.stats.dbconnectionstring:临时统计信息数据库连接串,默认jdbc:derby:databaseName=TempStatsStore;create=true;
hive.stats.defaults.publisher:如果dbclass不是jdbc或者hbase,那么使用这个作为默认发布,必须实现StatsPublisher接口,默认是空;
hive.stats.defaults.aggregator:如果dbclass不是jdbc或者hbase,那么使用该类做聚集,要求实现StatsAggregator接口,默认是空;
hive.stats.jdbc.timeout:jdbc连接超时配置,默认30秒;
hive.stats.retries.max:当统计发布合聚集在更新数据库时出现异常时最大的重试次数,默认是0,不重试;
hive.stats.retries.wait:重试次数之间的等待窗口,默认是3000毫秒;
hive.client.stats.publishers:做count的job的统计发布类列表,由逗号隔开,默认是空;必须实现org.apache.hadoop.hive.ql.stats.ClientStatsPublisher接口;
hive.client.stats.counters:没什么用~~~
hive.security.authorization.enabled:hive客户端是否认证,默认是false;
hive.security.authorization.manager:hive客户端认证的管理类,默认是org.apache.hadoop.hive.ql.security.authorization.DefaultHiveAuthorizationProvider;用户定义的要实现org.apache.hadoop.hive.ql.security.authorization.HiveAuthorizationProvider;
hive.security.authenticator.manager:hive客户端授权的管理类,默认是org.apache.hadoop.hive.ql.security.HadoopDefaultAuthenticator;用户定义的需要实现org.apache.hadoop.hive.ql.security.HiveAuthenticatorProvider;
hive.security.authorization.createtable.user.grants:当表创建时自动授权给用户,默认是空;
hive.security.authorization.createtable.group.grants:同上,自动授权给组,默认是空;
hive.security.authorization.createtable.role.grants:同上,自动授权给角色,默认是空;
hive.security.authorization.createtable.owner.grants:同上,自动授权给owner,默认是空;
hive.security.metastore.authorization.manager:metastore的认证管理类,默认是org.apache.hadoop.hive.ql.security.authorization.DefaultHiveMetastoreAuthorizationProvider;用户定义的必须实现org.apache.hadoop.hive.ql.security.authorization.HiveMetastoreAuthorizationProvider接口;接口参数要包含org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvider接口;使用HDFS的权限控制认证而不是hive的基于grant的方式;
hive.security.metastore.authenticator.manager:metastore端的授权管理类,默认是org.apache.hadoop.hive.ql.security.HadoopDefaultMetastoreAuthenticator,自定义的必须实现org.apache.hadoop.hive.ql.security.HiveAuthenticatorProvider接口;
hive.metastore.pre.event.listeners:在metastore做数据库任何操作前执行的事件监听类列表;
fs.har.impl:访问Hadoop Archives的实现类,低于hadoop 0.20版本的都不兼容,默认是org.apache.hadoop.hive.shims.HiveHarFileSystem;
hive.archive.enabled:是否允许归档操作,默认是false;
hive.archive.har.parentdir.settable:在创建HAR文件时必须要有父目录,需要手动设置,在新的hadoop版本会支持,默认是false;
hive.support.concurrency:hive是否支持并发,默认是false,支持读写锁的话,必须要起zookeeper;
hive.lock.mapred.only.operation:控制是否在查询时加锁,默认是false;
hive.lock.numretries:获取锁时尝试的重试次数,默认是100;
hive.lock.sleep.between.retries:在重试间隔的睡眠时间,默认60秒;
hive.zookeeper.quorum:zk地址列表,默认是空;
hive.zookeeper.client.port:zk服务器的连接端口,默认是2181;
hive.zookeeper.session.timeout:zk客户端的session超时时间,默认是600000;
hive.zookeeper.namespace:在所有zk节点创建后的父节点,默认是hive_zookeeper_namespace;
hive.zookeeper.clean.extra.nodes:在session结束时清除所有额外node;
hive.cluster.delegation.token.store.class:代理token的存储实现类,默认是org.apache.hadoop.hive.thrift.MemoryTokenStore,可以设置为org.apache.hadoop.hive.thrift.ZooKeeperTokenStore来做负载均衡集群;
hive.cluster.delegation.token.store.zookeeper.connectString:zk的token存储连接串,默认是localhost:2181;
hive.cluster.delegation.token.store.zookeeper.znode:token存储的节点跟路径,默认是/hive/cluster/delegation;
hive.cluster.delegation.token.store.zookeeper.acl:token存储的ACL,默认是sasl:hive/host1@example.com:cdrwa,sasl:hive/host2@example.com:cdrwa;
hive.use.input.primary.region:从一张input表创建表时,创建这个表到input表的主region,默认是true;
hive.default.region.name:默认region的名字,默认是default;
hive.region.properties:region的默认的文件系统和jobtracker,默认是空;
hive.cli.print.header:查询输出时是否打印名字和列,默认是false;
hive.cli.print.current.db:hive的提示里是否包含当前的db,默认是false;
hive.hbase.wal.enabled:写入hbase时是否强制写wal日志,默认是true;
hive.hwi.war.file:hive在web接口是的war文件的路径,默认是lib/hive-hwi-xxxx(version).war;
hive.hwi.listen.host:hwi监听的host地址,默认是0.0.0.0;
hive.hwi.listen.port:hwi监听的端口,默认是9999;
hive.test.mode:hive是否运行在测试模式,默认是false;
hive.test.mode.prefix:在测试模式运行时,表的前缀字符串,默认是test_;
hive.test.mode.samplefreq:如果hive在测试模式运行,并且表未分桶,抽样频率是多少,默认是32;
hive.test.mode.nosamplelist:在测试模式运行时不进行抽样的表列表,默认是空;
9、Hive 窗口与分析型函数

1、计算表中每只股票的两日滑动平均值
数据 计算
计算
2、计算每个部门中谁的收入最高
数据  计算
计算 
3、计算整个公司员工薪水的累积分布
计算  还可以使用 Hive 提供的 CUME_DIST() 来完成相同的计算。PERCENT_RANK() 函数则可以百分比的形式展现薪资所在排名。
还可以使用 Hive 提供的 CUME_DIST() 来完成相同的计算。PERCENT_RANK() 函数则可以百分比的形式展现薪资所在排名。  结果:
结果: 
4.根据点击流的时间间隔来将它们拆分成不同的会话,如超过 30 分钟认为是一次新的会话。我们还将为每个会话赋上自增 ID:
计算  结果:
结果: 
10、hive如何用Java代码通过JDBC连接Hiveserver
1、首先启动HiveServer
[wyp@localhost /home/q/hive-0.11.0]$ bin/hive --service hiveserver -p 10002 Starting Hive Thrift Server
2、提供Java代码链接hive仓库
package com.wyp;
/**
* User: 过往记忆
* Blog: http://www.iteblog.com/
* Date: 13-11-27
* Time: 下午5:52
*/
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcTest {
private static String driverName =
"org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args)
throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
Connection con = DriverManager.getConnection(
"jdbc:hive://localhost:10002/default", "wyp", "");
Statement stmt = con.createStatement();
String tableName = "wyphao";
stmt.execute("drop table if exists " + tableName);
stmt.execute("create table " + tableName +
" (key int, value string)");
System.out.println("Create table success!");
// show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
if (res.next()) {
System.out.println(res.getString(1));
}
// describe table
sql = "describe " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + " " + res.getString(2));
}
sql = "select * from " + tableName;
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(String.valueOf(res.getInt(1)) + " "
+ res.getString(2));
}
sql = "select count(1) from " + tableName;
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
}
}
3、结果展示
Create table success! Running: show tables 'wyphao' wyphao Running: describe wyphao key int value string Running: select count(1) from wyphao 0 Process finished with exit code 0
4、启动hivserver2保证安全和并发问题
$HIVE_HOME/bin/hiveserver2
不过修改以前的Java代码
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
改为
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
Connection con = DriverManager.getConnection(
"jdbc:hive://localhost:10002/default", "wyp", "");
改为
Connection con = DriverManager.getConnection(
"jdbc:hive2://localhost:10002/default", "wyp", "");
5、加入maven中hive的依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.2.0</version>
</dependency>
11、Hive与传统数据库MySQL整合指导
1、首先在hive的lib目录加入MySQL的驱动
MySQL最新的Java驱动版本为:mysql-connector-java-5.1.28-bin.jar,下载后拷贝到:Hive/Lib目录。
2.配置hive-site.xml
<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hivedb?characterEncoding=UTF-8</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.PersistenceManagerFactoryClass</name> <value>org.datanucleus.jdo.JDOPersistenceManagerFactory</value> <description>class implementing the jdo persistence</description> </property> <property> <name>javax.jdo.option.DetachAllOnCommit</name> <value>true</value> <description>detaches all objects from session so that they can be used after transaction is committed</description> </property> <property> <name>javax.jdo.option.NonTransactionalRead</name> <value>true</value> <description>reads outside of transactions</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> <description>password to use against metastore database</description> </property>
3、结果展示
通过进入MySQL中查询 show table
+----------------+ | Tables_in_hive | +----------------+ | BUCKETING_COLS | | COLUMNS | | DBS | | PARTITION_KEYS | | SDS | | SD_PARAMS | | SEQUENCE_TABLE | | SERDES | | SERDE_PARAMS | | SORT_COLS | | TABLE_PARAMS | | TBLS | +----------------+
四、hbase入门手册
1.建表高级属性
建表过程中常用的shell命令
1.1 BLOOMFILTER
默认是 NONE 是否使用布隆过虑及使用何种方式,布隆过滤可以每列族单独启用 使用HColumnDescriptor.setBloomFilterType(NONE|ROW|ROWCOL)对列族单独启用布隆 - Default = ROW 对行进行布隆过滤 - 对 ROW,行键的哈希在每次插入行时将被添加到布隆 - 对 ROWCOL,行键 + 列族 + 列族修饰的哈希将在每次插入行时添加到布隆 使用方法:
create 'table',{BLOOMFILTER =>'ROW'}
作用:用布隆过滤可以节省读磁盘过程,可以有助于降低读取延迟
1.2 VERSIONS
默认是1,这个参数的意思是数据保留1个版本,如果我们认为我们的数据没有这么大的必要保留这么多,随时都在更新,而老版本的数据对我们毫无价值,那将此参数设为1能节约2/3的空间。使用方法:
create 'table',{VERSIONS=>'2'}
附:MIN_VERSIONS => '0'是说在 compact 操作执行之后,至少要保留的版本
1.3 COMPRESSION
默认值是NONE即不使用压缩,这个参数意思是该列族是否采用压缩,采用什么压缩算法,方法:
create 'table',{NAME=>'info',COMPRESSION=>'SNAPPY'}
建议采用 SNAPPY 压缩算法,如果建表之初没有压缩,后来想要加入压缩算法,可以通过 alter 修改 schema
1.4 TTL
默认是2147483647 即:Integer.MAX_VALUE值大概是68年,这个参数是说明该列族数据的存活时间,单位是s。这个参数可以根据具体的需求对数据设定存活时间,超过存过时间的数据将在表中不再显示,待下次major·compact的时候再彻底删除数据 注意的是 TTL 设定之后MIN_VERSIONS=>'0'这样设置之后,TTL时间戳过期后,将全部彻底删除该 family下所有的数据,如果MIN_VERSIONS不等于0那将保留最新的 MIN_VERSIONS 个版本的数据,其它的全部删除,比如MIN_VERSIONS=>'1'届时将保留一个最新版本的数据,其它版本的数据将不再保存。
1.5 alter
使用方法:如修改压缩算法
disable 'table'
alter 'table',{NAME=>'info',COMPRESSION=>'snappy'}
enable 'table'
但是需要执行 major_compact 'table' 命令之后 才会做实际的操作。
1.6 describe/desc
这个命令查看了 create table 的各项参数或者是默认值。使用方式:
describe 'user_info'
1.7 disable_all/enable_all
disable_all 'toplist.*'disable_all支持正则表达式,并列出当前匹配的表的如下:
toplist_a_total_1001 toplist_a_total_1002 toplist_a_total_1008 toplist_a_total_1009 toplist_a_total_1019 toplist_a_total_1035 ... Disable the above 25 tables (y/n)? 并给出确认提示
1.8 drop_all
这个命令和 disable_all 的使用方式是一样的
1.9 hbase 预分区
默认情况下,在创建HBase表的时候会自动创建一个region分区,当导入数据的时候, 所有的 HBase 客户端都向这一个region写数据,直到这个region足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的regions,这样当数据写入 HBase时,会按照region分区情况,在集群内做数据的负载均衡。
1.9.1 命令方式
create table with specific split points
hbase>create 'table1','f1',SPLITS => ['x10x00', 'x20x00', 'x30x00', 'x40x00']
create table with four regions based on random bytes keys
hbase>create 'table2','f1', { NUMREGIONS => 8 , SPLITALGO => 'UniformSplit' }
create table with five regions based on hex keys
hbase>create 'table3','f1', { NUMREGIONS => 10, SPLITALGO => 'HexStringSplit' }
1.9.2 api 的方式
hbase org.apache.hadoop.hbase.util.RegionSplitter test_table HexStringSplit -c 10 -f info hbase org.apache.hadoop.hbase.util.RegionSplitter splitTable HexStringSplit -c 10 -f info
参数: test_table 是表名 HexStringSplit 是split 方式 -c 是分 10 个 region -f 是 family 可在 UI 上查看结果,如图:  这样就可以将表预先分为15个区,减少数据达到storefile大小的时候自动分区的时间 消耗,并且还有以一个优势,就是合理设计rowkey能让各个region的并发请求平均分配(趋于均匀)使IO效率达到最高,但是预分区需要将filesize设置一个较大的值,hbase.hregion.max.filesize 这个值默认是 10G也就是说单个region 默认大小是 10G.
这样就可以将表预先分为15个区,减少数据达到storefile大小的时候自动分区的时间 消耗,并且还有以一个优势,就是合理设计rowkey能让各个region的并发请求平均分配(趋于均匀)使IO效率达到最高,但是预分区需要将filesize设置一个较大的值,hbase.hregion.max.filesize 这个值默认是 10G也就是说单个region 默认大小是 10G.
但是如果MapReduce Input类型为TableInputFormat使用hbase作为输入的时候,每个 region 一个 map,如果数据小于10G那只会启用一个map造成很大的资源浪费, 这时候可以考虑适当调小该参数的值,或者采用预分配region的方式,并将检测如果达到 这个值,再手动分配 region。 回到顶部
2 表设计
2.1 列簇设计
追求的原则是:在合理范围内能尽量少的减少列簇就尽量减少列簇。 最优设计是:将所有相关性很强的key-value都放在同一个列簇下,这样既能做到查询效率最高,也能保持尽可能少的访问不同的磁盘文件。以用户信息为例,可以将必须的基本信息存放在一个列族,而一些附加的额外信息可以放在另一列族。
2.2 RowKey 设计
HBase 中,表会被划分为 1...n 个 Region,被托管在 RegionServer中。Region 二个重要的属性:StartKey与EndKey表示这个Region维护的rowKey范围,当我们要读/写数据时,如果rowKey落在某个start-endkey范围内,那么就会定位到目标 region 并且读/写到相关的数据
2.3 Rowkey 设计三原则
2.3.1 rowkey 长度原则
Rowkey 是一个二进制码流,Rowkey 的长度被很多开发者建议说设计在 10~100 个字节,不过建议是越短越好,不要超过 16 个字节。
原因如下: 数据的持久化文件 HFile 中是按照 KeyValue存储的,如果Rowkey过长比如 100 个字 节,1000 万列数据光 Rowkey 就要占用100*1000万=10亿个字节,将近 1G 数据,这会极大影响 HFile 的存储效率; MemStore 将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率会降低, 系统将无法缓存更多的数据,这会降低检索效率。因此Rowkey的字节长度越短越好。 目前操作系统是都是 64 位系统,内存 8 字节对齐。控制在 16 个字节,8 字节的整数倍利用操作系统的最佳特性。
2.3.2 rowkey 散列原则
如果 Rowkey 是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将 Rowkey 的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个 Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中 在个别 RegionServer,降低查询效率。
2.3.3 rowkey 唯一原则
必须在设计上保证其唯一性。rowkey 是按照字典顺序排序存储的,因此,设计 rowkey 的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
2.4 数据热点
HBase 中的行是按照rowkey的字典顺序排序的,这种设计优化了scan操作,可以将相关的行以及会被一起读取的行存取在临近位置,便于scan。然而糟糕的rowkey 设计是热点的源头。热点发生在大量的client直接访问集群的一个或极少数个节点(访问可能是读,写或者其他操作)。大量访问会使热点region所在的单个机器超出自身承受能力,引起性能下降甚至region不可用,这也会影响同一个RegionServer上的其他 region,由于主机无法服务其他region的请求。设计良好的数据访问模式以使集群被充分,均衡的利用。为了避免写热点,设计rowkey使得不同行在同一个 region,但是在更多数据情况下,数据 应该被写入集群的多个 region,而不是一个。
2.5 防止数据热点的有效措施
2.5.1加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给 rowkey 分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该 和你想使用数据分散到不同的 region 的数量一致。加盐之后的 rowkey 就会根据随机生成的 前缀分散到各个 region 上,以避免热点。
2.5.2 哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用 get 操作准确获取 某一个行数据
2.5.3反转
第三种防止热点的方法是反转固定长度或者数字格式的 rowkey。这样可以使得 rowkey 中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机 rowkey,但是牺 牲了 rowkey 的有序性。
反转 rowkey 的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
2.5.4 时间戳反转
一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey 的一部分对这个问题十分有用,可以用 Long.Max_Value - timestamp追加到 key 的末尾,例 如 [key][reverse_timestamp] , [key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey 的时候,可以这样设计[userId反转][Long.Max_Value-timestamp],在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow 是 [userId 反 转 ][000000000000],stopRow 是 [userId 反 转][Long.Max_Value - timestamp] 如果需要查询某段时间的操作记录,startRow 是[user 反转][Long.Max_Value - 起始时间], stopRow 是[userId 反转][Long.Max_Value - 结束时间]
3.协处理器—Coprocessor
Hbase 作为列族数据库最经常被人诟病的特性包括:无法轻易建立“二级索引”,难以执 行求和、计数、排序等操作。比如,在旧版本的(0.92以前版本)Hbase中,统计数据表的总行数,需要使用Counter方法,执行一次MapReduce.Job才能得到。虽然 HBase 在数据存储层中集成了MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相加或者聚合计算的时候,如果直接将计算过程放置在 server端,能够减少通讯开销,从而获得很好的性能提升。于是,HBase 在 0.92 之后引入了协处理器(coprocessors),实现一些激动人心的新特性:能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
3.1 协处理器分类
协处理器有两种:observer 和 endpoint
3.1.1 observer协处理器
Observer类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被Server端调用。Observer Coprocessor就是一些散布在HBaseServer端代码中的 hook钩子, 在固定的事件发生时被调用。比如:put操作之前有钩子函数prePut,该函数在 put 操作执 行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数.它提供了三种观察者接口: - RegionObserver:提供客户端的数据操纵事件钩子:Get、Put、Delete、Scan 等。 - WALObserver:提供 WAL 相关操作钩子。 - MasterObserver:提供 DDL-类型的操作钩子。如创建、删除、修改数据表等。 - 0.96 版本又新增一个 RegionServerObserver
以 RegionObserver 为例子讲解 Observer 这种协处理器的原理:  客户端发出 put 请求 该请求被分派给合适的 RegionServer 和 region coprocessorHost 拦截该请求,然后在该表上登记的每个 RegionObserver 上调用 prePut() 如果没有被 prePut()拦截,该请求继续送到 region,然后进行处理 region 产生的结果再次被 CoprocessorHost 拦截,调用 postPut() 假如没有 postPut()拦截该响应,最终结果被返回给客户端
客户端发出 put 请求 该请求被分派给合适的 RegionServer 和 region coprocessorHost 拦截该请求,然后在该表上登记的每个 RegionObserver 上调用 prePut() 如果没有被 prePut()拦截,该请求继续送到 region,然后进行处理 region 产生的结果再次被 CoprocessorHost 拦截,调用 postPut() 假如没有 postPut()拦截该响应,最终结果被返回给客户端
3.1.2 EndPoint协处理器
Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些Endpoint 协处 理器执行一段 Server端代码,并将Server端代码的结果返回给客户端进一步处理,最常见 的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即max聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到Client端统一执行,势必效率低下。利用Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层cluster 的多个节点并发执行求最大值的操作。即在每个Region范围内执行求最大值的代码,将每个Region的最大值在Region Server端计算出,仅仅将该max值返回给客 户端。在客户端进一步将多个Region的最大值进一步处理而找到其中的最大值。这样整体 的执行效率就会提高很多
下图是 EndPoint 的工作原理:

3.1.3 observer和endpoint处理器区别
Observer 允许集群在正常的客户端操作过程中可以有不同的行为表现
Endpoint 允许扩展集群的能力,对客户端应用开放新的运算命令
Observer 类似于 RDBMS 中的触发器,主要在服务端工作
Endpoint 类似于 RDBMS 中的存储过程,主要在服务端工作
Observer 可以实现权限管理、优先级设置、监控、ddl 控制、二级索引等功能
Endpoint 可以实现 min、max、avg、sum、distinct、group by 等功能
3.2 协处理加载方式
协处理器的加载方式有两种,我们称之为静态加载方式(Static Load)和动态加载方式 (Dynamic Load)。静态加载的协处理器称之为 System Coprocessor,动态加载的协处理器称之为 Table Coprocessor。
3.2.1 静态加载
通过修改 hbase-site.xml这个文件来实现,启动全局aggregation,能过操纵所有的表上 的数据。只需要添加如下代码:
<property> <name>hbase.coprocessor.user.region.classes</name> <value>org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value> </property>
为所有 table 加载了一个 cp class,可以用”,”分割加载多个 class
3.2.2 动态加载
启用表 aggregation,只对特定的表生效。通过 HBase Shell 来实现。 1. 停用表 disable 'guanzhu'
2.添加协处理器
alter 'guanzhu', METHOD => 'table_att', 'coprocessor' => 'hdfs://myha01/hbase/guanzhu.jar|com.study.hbase.cp.HbaseCoprocessorTest|1001|'
3.启用表
enable 'guanzhu'
3.2.3 协处理器卸载 同样是3步
disable 'mytable' alter 'mytable',METHOD=>'table_att_unset',NAME=>'coprocessor$1' enable 'mytable'
五、hbase高级手册
六、hbase实战手册
1、大数据场景下数据异构之 Mysql实时写入HBase
(借助canal kafka SparkStreaming)
(1)、首先canal解析mysqlbinlog 实时写入kafka:
首先定义抽象类:AbstractCanalClient ,为后面实现
package kafka;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.InvalidProtocolBufferException;
import org.apache.commons.lang.SystemUtils;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import org.springframework.util.Assert;
import org.springframework.util.CollectionUtils;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.List;
import java.util.concurrent.ExecutionException;
public class AbstractCanalClient {
protected final static Logger logger = LoggerFactory
.getLogger(AbstractCanalClient.class);
protected static final String SEP = SystemUtils.LINE_SEPARATOR;
protected static final String DATE_FORMAT = "yyyy-MM-dd HH:mm:ss";
protected volatile boolean running = false;
protected Thread.UncaughtExceptionHandler handler = new Thread.UncaughtExceptionHandler() {
public void uncaughtException(Thread t, Throwable e) {
logger.error("parse events has an error", e);
}
};
protected Thread thread = null;
protected CanalConnector connector;
protected static String context_format = null;
protected static String row_format = null;
protected static String transaction_format = null;
protected String destination;
protected Producer<String, String> kafkaProducer = null;
protected String topic;
protected String table;
static {
context_format = SEP
+ "****************************************************" + SEP;
context_format += "* Batch Id: [{}] ,count : [{}] , memsize : [{}] , Time : {}"
+ SEP;
context_format += "* Start : [{}] " + SEP;
context_format += "* End : [{}] " + SEP;
context_format += "****************************************************"
+ SEP;
row_format = SEP
+ "----------------> binlog[{}:{}] , name[{},{}] , eventType : {} , executeTime : {} , delay : {}ms"
+ SEP;
transaction_format = SEP
+ "================> binlog[{}:{}] , executeTime : {} , delay : {}ms"
+ SEP;
}
public AbstractCanalClient(String destination) {
this(destination, null);
}
public AbstractCanalClient(String destination, CanalConnector connector) {
this(destination, connector, null);
}
public AbstractCanalClient(String destination, CanalConnector connector,
Producer<String, String> kafkaProducer) {
this.connector = connector;
this.destination = destination;
this.kafkaProducer = kafkaProducer;
}
protected void start() {
Assert.notNull(connector, "connector is null");
Assert.notNull(kafkaProducer, "Kafka producer configuration is null");
Assert.notNull(topic, "kafaka topic is null");
Assert.notNull(table,"table is null");
thread = new Thread(new Runnable() {
public void run() {
process();
}
});
thread.setUncaughtExceptionHandler(handler);
thread.start();
running = true;
}
protected void stop() {
if (!running) {
return;
}
running = false;
if (thread != null) {
try {
thread.join();
} catch (InterruptedException e) {
// ignore
}
}
kafkaProducer.close();
MDC.remove("destination");
}
protected void process() {
int batchSize = 1024;
while (running) {
try {
MDC.put("destination", destination);
connector.connect();
connector.subscribe("databaseName\.tableName");
while (running) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
try {
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
} else {
kafkaEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
} catch (Exception e) {
connector.rollback(batchId); // 处理失败, 回滚数据
}
}
} catch (Exception e) {
logger.error("process error!", e);
} finally {
connector.disconnect();
MDC.remove("destination");
}
}
}
private void printSummary(Message message, long batchId, int size) {
long memsize = 0;
for (Entry entry : message.getEntries()) {
memsize += entry.getHeader().getEventLength();
}
String startPosition = null;
String endPosition = null;
if (!CollectionUtils.isEmpty(message.getEntries())) {
startPosition = buildPositionForDump(message.getEntries().get(0));
endPosition = buildPositionForDump(message.getEntries().get(
message.getEntries().size() - 1));
}
SimpleDateFormat format = new SimpleDateFormat(DATE_FORMAT);
logger.info(context_format, new Object[]{batchId, size, memsize,
format.format(new Date()), startPosition, endPosition});
}
protected String buildPositionForDump(Entry entry) {
long time = entry.getHeader().getExecuteTime();
Date date = new Date(time);
SimpleDateFormat format = new SimpleDateFormat(DATE_FORMAT);
return entry.getHeader().getLogfileName() + ":"
+ entry.getHeader().getLogfileOffset() + ":"
+ entry.getHeader().getExecuteTime() + "("
+ format.format(date) + ")";
}
private void kafkaEntry(List<Entry> entrys) throws InterruptedException, ExecutionException {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN
|| entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException(
"ERROR ## parser of eromanga-event has an error , data:"
+ entry.toString(), e);
}
String logfileName = entry.getHeader().getLogfileName();
Long logfileOffset = entry.getHeader().getLogfileOffset();
String dbName = entry.getHeader().getSchemaName();
String tableName = entry.getHeader().getTableName();
EventType eventType = rowChage.getEventType();
if (eventType == EventType.DELETE || eventType == EventType.UPDATE
|| eventType == EventType.INSERT) {
for (RowData rowData : rowChage.getRowDatasList()) {
String tmpstr = "";
if (eventType == EventType.DELETE) {
tmpstr = getDeleteJson(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
tmpstr = getInsertJson(rowData.getAfterColumnsList());
} else if (eventType == EventType.UPDATE) {
tmpstr = getUpdateJson(rowData.getBeforeColumnsList(),
rowData.getAfterColumnsList());
} else {
continue;
}
logger.info(this.topic+tmpstr);
kafkaProducer.send(
new ProducerRecord<String, String>(this.topic,
tmpstr)).get();
}
}
}
}
private JSONObject columnToJson(List<Column> columns) {
JSONObject json = new JSONObject();
for (Column column : columns) {
json.put(column.getName(), column.getValue());
}
return json;
}
private String getInsertJson(List<Column> columns) {
JSONObject json = new JSONObject();
json.put("type", "insert");
json.put("data", this.columnToJson(columns));
return json.toJSONString();
}
private String getUpdateJson(List<Column> befcolumns, List<Column> columns) {
JSONObject json = new JSONObject();
json.put("type", "update");
json.put("data", this.columnToJson(columns));
return json.toJSONString();
}
private String getDeleteJson(List<Column> columns) {
JSONObject json = new JSONObject();
json.put("type", "delete");
json.put("data", this.columnToJson(columns));
return json.toJSONString();
}
protected void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
long executeTime = entry.getHeader().getExecuteTime();
long delayTime = new Date().getTime() - executeTime;
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN
|| entry.getEntryType() == EntryType.TRANSACTIONEND) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN) {
TransactionBegin begin = null;
try {
begin = TransactionBegin.parseFrom(entry
.getStoreValue());
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException(
"parse event has an error , data:"
+ entry.toString(), e);
}
// 打印事务头信息,执行的线程id,事务耗时
logger.info(
transaction_format,
new Object[]{
entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader()
.getLogfileOffset()),
String.valueOf(entry.getHeader()
.getExecuteTime()),
String.valueOf(delayTime)});
logger.info(" BEGIN ----> Thread id: {}",
begin.getThreadId());
} else if (entry.getEntryType() == EntryType.TRANSACTIONEND) {
TransactionEnd end = null;
try {
end = TransactionEnd.parseFrom(entry.getStoreValue());
} catch (InvalidProtocolBufferException e) {
throw new RuntimeException(
"parse event has an error , data:"
+ entry.toString(), e);
}
// 打印事务提交信息,事务id
logger.info("----------------
");
logger.info(" END ----> transaction id: {}",
end.getTransactionId());
logger.info(
transaction_format,
new Object[]{
entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader()
.getLogfileOffset()),
String.valueOf(entry.getHeader()
.getExecuteTime()),
String.valueOf(delayTime)});
}
continue;
}
if (entry.getEntryType() == EntryType.ROWDATA) {
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException(
"parse event has an error , data:"
+ entry.toString(), e);
}
EventType eventType = rowChage.getEventType();
logger.info(
row_format,
new Object[]{
entry.getHeader().getLogfileName(),
String.valueOf(entry.getHeader()
.getLogfileOffset()),
entry.getHeader().getSchemaName(),
entry.getHeader().getTableName(),
eventType,
String.valueOf(entry.getHeader()
.getExecuteTime()),
String.valueOf(delayTime)});
if (eventType == EventType.QUERY || rowChage.getIsDdl()) {
logger.info(" sql ----> " + rowChage.getSql() + SEP);
continue;
}
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
printColumn(rowData.getAfterColumnsList());
}
}
}
}
}
protected void printColumn(List<Column> columns) {
for (Column column : columns) {
StringBuilder builder = new StringBuilder();
builder.append(column.getName() + " : " + column.getValue());
builder.append(" type=" + column.getMysqlType());
if (column.getUpdated()) {
builder.append(" update=" + column.getUpdated());
}
builder.append(SEP);
logger.info(builder.toString());
}
}
public void setConnector(CanalConnector connector) {
this.connector = connector;
}
public void setKafkaProducer(Producer<String, String> kafkaProducer) {
this.kafkaProducer = kafkaProducer;
}
public void setKafkaTopic(String topic) {
this.topic = topic;
}
public void setFilterTable(String table) {
this.table = table;
}
}
继承 AbstractCanalClient 实现需求
package kafka;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import org.apache.commons.lang.exception.ExceptionUtils;
import org.apache.kafka.clients.producer.KafkaProducer;
import java.net.InetSocketAddress;
import java.util.Properties;
public class ClusterCanalClient extends AbstractCanalClient {
public ClusterCanalClient(String destination) {
super(destination);
}
public static void main(String args[]) {
String destination = null;//"example";
String topic = null;
// String canalhazk = null;
String kafka = null;
String hostname = null;
String table = null;
if (args.length != 5) {
logger.error("input param must : hostname destination topic kafka table" +
"for example: localhost example topic 192.168.0.163:9092 tablname");
System.exit(1);
} else {
hostname = args[0];
destination = args[1];
topic = args[2];
// canalhazk = args[2];
kafka = args[3];
table = args[4];
}
// 基于zookeeper动态获取canal server的地址,建立链接,其中一台server发生crash,可以支持failover
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(
hostname, 11111),
destination,
"canal",
"canal");
// CanalConnector connector = CanalConnectors.newClusterConnector(
// canalhazk, destination, "userName", "passwd");
Properties props = new Properties();
props.put("bootstrap.servers", kafka);
props.put("request.required.acks",1);
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);//32m
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
final ClusterCanalClient clientTest = new ClusterCanalClient(destination);
clientTest.setConnector(connector);
clientTest.setKafkaProducer(producer);
clientTest.setKafkaTopic(topic);
clientTest.setFilterTable(table);
clientTest.start();
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
try {
logger.info("## stop the canal client");
clientTest.stop();
} catch (Throwable e) {
logger.warn("##something goes wrong when stopping canal:
{}", ExceptionUtils.getFullStackTrace(e));
} finally {
logger.info("## canal client is down.");
}
}
});
}
}
继承AbstractCanalClient 存入到hbase中
package kafka;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import org.apache.commons.lang.exception.ExceptionUtils;
import org.apache.kafka.clients.producer.KafkaProducer;
import java.net.InetSocketAddress;
import java.util.Properties;
public class ClusterCanalClient extends AbstractCanalClient {
public ClusterCanalClient(String destination) {
super(destination);
}
public static void main(String args[]) {
String destination = null;//"example";
String topic = null;
// String canalhazk = null;
String kafka = null;
String hostname = null;
String table = null;
if (args.length != 5) {
logger.error("input param must : hostname destination topic kafka table" +
"for example: localhost example topic 192.168.0.163:9092 tablname");
System.exit(1);
} else {
hostname = args[0];
destination = args[1];
topic = args[2];
// canalhazk = args[2];
kafka = args[3];
table = args[4];
}
// 基于zookeeper动态获取canal server的地址,建立链接,其中一台server发生crash,可以支持failover
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(
hostname, 11111),
destination,
"canal",
"canal");
// CanalConnector connector = CanalConnectors.newClusterConnector(
// canalhazk, destination, "userName", "passwd");
Properties props = new Properties();
props.put("bootstrap.servers", kafka);
props.put("request.required.acks",1);
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);//32m
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
final ClusterCanalClient clientTest = new ClusterCanalClient(destination);
clientTest.setConnector(connector);
clientTest.setKafkaProducer(producer);
clientTest.setKafkaTopic(topic);
clientTest.setFilterTable(table);
clientTest.start();
Runtime.getRuntime().addShutdownHook(new Thread() {
public void run() {
try {
logger.info("## stop the canal client");
clientTest.stop();
} catch (Throwable e) {
logger.warn("##something goes wrong when stopping canal:
{}", ExceptionUtils.getFullStackTrace(e));
} finally {
logger.info("## canal client is down.");
}
}
});
}
}
2、hbase入库有几种方式?
(1) 预先生成HFile入库
/**
* Copyright 2009 The Apache Software Foundation
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package insert.tools.hfile;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import java.util.TreeSet;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HConstants;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.io.hfile.Compression;
import org.apache.hadoop.hbase.io.hfile.HFile;
import org.apache.hadoop.hbase.mapreduce.KeyValueSortReducer;
import org.apache.hadoop.hbase.mapreduce.hadoopbackport.TotalOrderPartitioner;
import org.apache.hadoop.hbase.regionserver.StoreFile;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import com.google.common.base.Preconditions;
/**
* Writes HFiles. Passed KeyValues must arrive in order. Currently, can only
* write files to a single column family at a time. Multiple column families
* requires coordinating keys cross family. Writes current time as the sequence
* id for the file. Sets the major compacted attribute on created hfiles.
*
* @see KeyValueSortReducer
*/
public class HFileOutputFormat extends
FileOutputFormat {
static Log LOG = LogFactory.getLog(HFileOutputFormat.class);
public RecordWriter getRecordWriter(
final TaskAttemptContext context) throws IOException,
InterruptedException {
// Get the path of the temporary output file
final Path outputPath = FileOutputFormat.getOutputPath(context);
final Path outputdir = new FileOutputCommitter(outputPath, context)
.getWorkPath();
Configuration conf = context.getConfiguration();
final FileSystem fs = outputdir.getFileSystem(conf);
// These configs. are from hbase-*.xml
// revise
// final long maxsize = conf.getLong("hbase.hregion.max.filesize",
// 268435456);
// final int blocksize = conf.getInt("hfile.min.blocksize.size", 65536);
final long maxsize = conf.getLong("hbase.hregion.max.filesize",
HConstants.DEFAULT_MAX_FILE_SIZE);
final int blocksize = conf.getInt("hfile.min.blocksize.size",
HFile.DEFAULT_BLOCKSIZE);
// -revise
// Invented config. Add to hbase-*.xml if other than default
// compression.
final String compression = conf.get("hfile.compression",
Compression.Algorithm.NONE.getName());
return new RecordWriter() {
// Map of families to writers and how much has been output on the
// writer.
private final Map<byte[], WriterLength> writers = new TreeMap<byte[], WriterLength>(
Bytes.BYTES_COMPARATOR);
private byte[] previousRow = HConstants.EMPTY_BYTE_ARRAY;
private final byte[] now = Bytes
.toBytes(System.currentTimeMillis());
// add
private boolean rollRequested = false;
// -add
public void write(ImmutableBytesWritable row, KeyValue kv)
throws IOException {
// add
// null input == user explicitly wants to flush
if (row == null && kv == null) {
rollWriters();
return;
}
byte[] rowKey = kv.getRow();
// -add
long length = kv.getLength();
byte[] family = kv.getFamily();
WriterLength wl = this.writers.get(family);
// revise
// if (wl == null
// || ((length + wl.written) >= maxsize)
// && Bytes.compareTo(this.previousRow, 0,
// this.previousRow.length, kv.getBuffer(), kv
// .getRowOffset(), kv.getRowLength()) != 0) {
// // Get a new writer.
// Path basedir = new Path(outputdir, Bytes.toString(family));
// if (wl == null) {
// wl = new WriterLength();
// this.writers.put(family, wl);
// if (this.writers.size() > 1)
// throw new IOException("One family only");
// // If wl == null, first file in family. Ensure family
// // dir exits.
// if (!fs.exists(basedir))
// fs.mkdirs(basedir);
// }
// wl.writer = getNewWriter(wl.writer, basedir);
// LOG
// .info("Writer="
// + wl.writer.getPath()
// + ((wl.written == 0) ? "" : ", wrote="
// + wl.written));
// wl.written = 0;
// }
// If this is a new column family, verify that the directory
// exists
if (wl == null) {
fs.mkdirs(new Path(outputdir, Bytes.toString(family)));
}
// If any of the HFiles for the column families has reached
// maxsize, we need to roll all the writers
if (wl != null && wl.written + length >= maxsize) {
this.rollRequested = true;
}
// This can only happen once a row is finished though
if (rollRequested
&& Bytes.compareTo(this.previousRow, rowKey) != 0) {
rollWriters();
}
// create a new HLog writer, if necessary
if (wl == null || wl.writer == null) {
wl = getNewWriter(family);
}
// we now have the proper HLog writer. full steam ahead
// -revise
kv.updateLatestStamp(this.now);
wl.writer.append(kv);
wl.written += length;
// Copy the row so we know when a row transition.
// revise
// this.previousRow = kv.getRow();
this.previousRow = rowKey;
// -revise
}
// revise
// /*
// * Create a new HFile.Writer. Close current if there is one.
// *
// * @param writer
// *
// * @param familydir
// *
// * @return A new HFile.Writer.
// *
// * @throws IOException
// */
// private HFile.Writer getNewWriter(final HFile.Writer writer,
// final Path familydir) throws IOException {
// close(writer);
// return new HFile.Writer(fs, StoreFile.getUniqueFile(fs,
// familydir), blocksize, compression,
// KeyValue.KEY_COMPARATOR);
// }
private void rollWriters() throws IOException {
for (WriterLength wl : this.writers.values()) {
if (wl.writer != null) {
LOG.info("Writer="
+ wl.writer.getPath()
+ ((wl.written == 0) ? "" : ", wrote="
+ wl.written));
close(wl.writer);
}
wl.writer = null;
wl.written = 0;
}
this.rollRequested = false;
}
/*
* Create a new HFile.Writer.
*
* @param family
*
* @return A WriterLength, containing a new HFile.Writer.
*
* @throws IOException
*/
private WriterLength getNewWriter(byte[] family) throws IOException {
WriterLength wl = new WriterLength();
Path familydir = new Path(outputdir, Bytes.toString(family));
wl.writer = new HFile.Writer(fs, StoreFile.getUniqueFile(fs,
familydir), blocksize, compression,
KeyValue.KEY_COMPARATOR);
this.writers.put(family, wl);
return wl;
}
// -revise
private void close(final HFile.Writer w) throws IOException {
if (w != null) {
w.appendFileInfo(StoreFile.BULKLOAD_TIME_KEY, Bytes
.toBytes(System.currentTimeMillis()));
w.appendFileInfo(StoreFile.BULKLOAD_TASK_KEY, Bytes
.toBytes(context.getTaskAttemptID().toString()));
w.appendFileInfo(StoreFile.MAJOR_COMPACTION_KEY, Bytes
.toBytes(true));
w.close();
}
}
// revise
// public void close(TaskAttemptContext c) throws IOException,
// InterruptedException {
// for (Map.Entry e : this.writers
// .entrySet()) {
// close(e.getValue().writer);
// }
// }
public void close(TaskAttemptContext c) throws IOException,
InterruptedException {
for (WriterLength wl : this.writers.values()) {
close(wl.writer);
}
}
// -revise
};
}
/*
* Data structure to hold a Writer and amount of data written on it.
*/
static class WriterLength {
long written = 0;
HFile.Writer writer = null;
}
/**
* Return the start keys of all of the regions in this table, as a list of
* ImmutableBytesWritable.
*/
private static List getRegionStartKeys(HTable table)
throws IOException {
byte[][] byteKeys = table.getStartKeys();
ArrayList ret = new ArrayList(
byteKeys.length);
for (byte[] byteKey : byteKeys) {
ret.add(new ImmutableBytesWritable(byteKey));
}
return ret;
}
/**
* Write out a SequenceFile that can be read by TotalOrderPartitioner that
* contains the split points in startKeys.
*
* @param partitionsPath
* output path for SequenceFile
* @param startKeys
* the region start keys
*/
private static void writePartitions(Configuration conf,
Path partitionsPath, List startKeys)
throws IOException {
Preconditions.checkArgument(!startKeys.isEmpty(), "No regions passed");
// We're generating a list of split points, and we don't ever
// have keys < the first region (which has an empty start key)
// so we need to remove it. Otherwise we would end up with an
// empty reducer with index 0
TreeSet sorted = new TreeSet(
startKeys);
ImmutableBytesWritable first = sorted.first();
Preconditions
.checkArgument(
first.equals(HConstants.EMPTY_BYTE_ARRAY),
"First region of table should have empty start key. Instead has: %s",
Bytes.toStringBinary(first.get()));
sorted.remove(first);
// Write the actual file
FileSystem fs = partitionsPath.getFileSystem(conf);
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf,
partitionsPath, ImmutableBytesWritable.class,
NullWritable.class);
try {
for (ImmutableBytesWritable startKey : sorted) {
writer.append(startKey, NullWritable.get());
}
} finally {
writer.close();
}
}
/**
* Configure a MapReduce Job to perform an incremental load into the given
* table. This
*
*
Inspects the table to configure a total order partitioner
*
Uploads the partitions file to the cluster and adds it to the
* DistributedCache
*
Sets the number of reduce tasks to match the current number of
* regions
*
Sets the output key/value class to match HFileOutputFormat's
* requirements
*
Sets the reducer up to perform the appropriate sorting (either
* KeyValueSortReducer or PutSortReducer)
*
* The user should be sure to set the map output value class to either
* KeyValue or Put before running this function.
*/
public static void configureIncrementalLoad(Job job, HTable table)
throws IOException {
Configuration conf = job.getConfiguration();
job.setPartitionerClass(TotalOrderPartitioner.class);
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(KeyValue.class);
job.setOutputFormatClass(HFileOutputFormat.class);
// Based on the configured map output class, set the correct reducer to
// properly
// sort the incoming values.
// TODO it would be nice to pick one or the other of these formats.
if (KeyValue.class.equals(job.getMapOutputValueClass())) {
job.setReducerClass(KeyValueSortReducer.class);
} else if (Put.class.equals(job.getMapOutputValueClass())) {
job.setReducerClass(PutSortReducer.class);
} else {
LOG.warn("Unknown map output value type:"
+ job.getMapOutputValueClass());
}
LOG.info("Looking up current regions for table " + table);
List startKeys = getRegionStartKeys(table);
LOG.info("Configuring " + startKeys.size() + " reduce partitions "
+ "to match current region count");
job.setNumReduceTasks(startKeys.size());
Path partitionsPath = new Path(job.getWorkingDirectory(), "partitions_"
+ System.currentTimeMillis());
LOG.info("Writing partition information to " + partitionsPath);
FileSystem fs = partitionsPath.getFileSystem(conf);
writePartitions(conf, partitionsPath, startKeys);
partitionsPath.makeQualified(fs);
URI cacheUri;
try {
cacheUri = new URI(partitionsPath.toString() + "#"
+ TotalOrderPartitioner.DEFAULT_PATH);
} catch (URISyntaxException e) {
throw new IOException(e);
}
DistributedCache.addCacheFile(cacheUri, conf);
DistributedCache.createSymlink(conf);
LOG.info("Incremental table output configured.");
}
}
(2)通过MapReduce入库
/* MapReduce 读取hdfs上的文件,以HTable.put(put)的方式在map中完成数据写入,无reduce过程*/
import java.io.IOException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class HBaseImport extends Configured implements Tool{
static final Log LOG = LogFactory.getLog(HBaseImport.class);
public static final String JOBNAME = "MRImport ";
public static class Map extends Mapper<LongWritable , Text, NullWritable, NullWritable>{
Configuration configuration = null;
HTable xTable = null;
private boolean wal = true;
static long count = 0;
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
// TODO Auto-generated method stub
super.cleanup(context);
xTable.flushCommits();
xTable.close();
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String all[] = value.toString().split("/t");
If(all.length==2){
put = new Put(Bytes.toBytes(all[0]))); put.add(Bytes.toBytes("xxx"),Bytes.toBytes("20110313"),Bytes.toBytes(all[1]));
}
if (!wal) {
put.setWriteToWAL(false);
}
xTable.put(put);
if ((++count % 100)==0) {
context.setStatus(count +" DOCUMENTS done!");
context.progress();
System.out.println(count +" DOCUMENTS done!");
}
}
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
// TODO Auto-generated method stub
super.setup(context);
configuration = context.getConfiguration();
xTable = new HTable(configuration,"testKang");
xTable.setAutoFlush(false);
xTable.setWriteBufferSize(12*1024*1024);
wal = true;
}
}
@Override
public int run(String[] args) throws Exception {
String input = args[0];
Configuration conf = HBaseConfiguration.create(getConf());
conf.set("hbase.master", "m0:60000");
Job job = new Job(conf,JOBNAME);
job.setJarByClass(HBaseImport.class);
job.setMapperClass(Map.class);
job.setNumReduceTasks(0);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, input);
job.setOutputFormatClass(NullOutputFormat.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
int res = 1;
try {
res = ToolRunner.run(conf, new HBaseImport (), otherArgs);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(res);
}
}
(3) 通过Java程序入库
/* Java多线程读取本地磁盘上的文件,以HTable.put(put)的方式完成数据写入*/
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
public class InsertContactJava {
public static long startTime;
public static long rowkey = 0; //起始rowkey
public static final int lineCount = 100000; //每次提交时录入的行数
public static String tableName = "usercontact_kang"; //录入目的表名
public static int countLie = 8; //表的列数
public static void main(String[] args) throws IOException {
startTime = System.currentTimeMillis() / 1000;
System.out.println("start time = " + startTime);
Thread t1 = new Thread() {
@Override
public void run() {
try {
insert_one("/run/jar/123");
//loadByLieWithVector("/run/jar/123");
//loadByLieWithArrayList("/run/jar/123");
} catch (IOException e) {
e.printStackTrace();
}
}
};
t1.start();
}
public static void insert_one(String path) throws IOException {
Configuration conf = HBaseConfiguration.create();
HTable table = new HTable(conf, tableName);
File f = new File(path);
ArrayList<Put> list = new ArrayList<Put>();
BufferedReader br = new BufferedReader(new FileReader(f));
String tmp = br.readLine();
int count = 0;
while (tmp != null) {
if (list.size() > 10000) {
table.put(list);
table.flushCommits();
list.clear();
} else {
String arr_value[] = tmp.toString().split("/t", 10);
String first[] = arr_value[0].split("~", 5);
String second[] = arr_value[1].split("~", 5);
String rowname = getIncreasRowKey();
String firstaccount = first[0];
String firstprotocolid = first[1];
String firstdomain = first[2];
String inserttime = Utils.getToday("yyyyMMdd");
String secondaccount = second[0];
String secondprotocolid = second[1];
String seconddomain = second[2];
String timescount = Integer.valueOf(arr_value[2]).toString();
Put p = new Put(rowname.getBytes());
p.add(("ucvalue").getBytes(), "FIRSTACCOUNT".getBytes(),
firstaccount.getBytes());
p.add(("ucvalue").getBytes(), "FIRSTDOMAIN".getBytes(),
firstdomain.getBytes());
p.add(("ucvalue").getBytes(), "FIRSTPROTOCOLID".getBytes(),
firstprotocolid.getBytes());
p.add(("ucvalue").getBytes(), "INSERTTIME".getBytes(),
inserttime.getBytes());
p.add(("ucvalue").getBytes(), "SECONDACCOUNT".getBytes(),
secondaccount.getBytes());
p.add(("ucvalue").getBytes(), "SECONDDOMAIN".getBytes(),
seconddomain.getBytes());
p.add(("ucvalue").getBytes(), "SECONDPROTOCOLID".getBytes(),
secondprotocolid.getBytes());
p.add(("ucvalue").getBytes(), "TIMESCOUNT".getBytes(),
timescount.getBytes());
list.add(p);
}
tmp = br.readLine();
count++;
}
if (list.size() > 0) {
table.put(list);
table.flushCommits();
}
table.close();
System.out.println("total = " + count);
long endTime = System.currentTimeMillis() / 1000;
long costTime = endTime - startTime;
System.out.println("end time = " + endTime);
System.out.println(path + ": cost time = " + costTime);
}
3、直接使用HTable进行导入
package hbase.curd;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.util.Bytes;
public class HTableUtil {
private static HTable table;
private static Configuration conf;
static{
conf =HBaseConfiguration.create();
conf.set("mapred.job.tracker", "hbase:9001");
conf.set("fs.default.name", "hbase:9000");
conf.set("hbase.zookeeper.quorum", "hbase");
try {
table = new HTable(conf,"testtable");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Configuration getConf(){
return conf;
}
public static HTable getHTable(String tablename){
if(table==null){
try {
table= new HTable(conf,tablename);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return table;
}
public static byte[] gB(String name){
return Bytes.toBytes(name);
}
}
package hbase.curd;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class PutExample {
/**
* @param args
* @throws IOException
*/
private HTable table = HTableUtil.getHTable("testtable");
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
PutExample pe = new PutExample();
pe.putRows();
}
public void putRows(){
List<Put> puts = new ArrayList<Put>();
for(int i=0;i<10;i++){
Put put = new Put(Bytes.toBytes("row_"+i));
Random random = new Random();
if(random.nextBoolean()){
put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual1"), Bytes.toBytes("colfam1_qual1_value_"+i));
}
if(random.nextBoolean()){
put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual2"), Bytes.toBytes("colfam1_qual1_value_"+i));
}
if(random.nextBoolean()){
put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual3"), Bytes.toBytes("colfam1_qual1_value_"+i));
}
if(random.nextBoolean()){
put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual4"), Bytes.toBytes("colfam1_qual1_value_"+i));
}
if(random.nextBoolean()){
put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("qual5"), Bytes.toBytes("colfam1_qual1_value_"+i));
}
puts.add(put);
}
try{
table.put(puts);
table.close();
}catch(Exception e){
e.printStackTrace();
return ;
}
System.out.println("done put rows");
}
}
4、从HDFS文件导入HBase,继承自Mapper
package hbase.mr;
import java.io.IOException;
import hbase.curd.HTableUtil;
import org.apache.commons.cli.CommandLine;
import org.apache.commons.cli.CommandLineParser;
import org.apache.commons.cli.HelpFormatter;
import org.apache.commons.cli.Option;
import org.apache.commons.cli.Options;
import org.apache.commons.cli.PosixParser;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class ImportFromFile {
/**
* 从文件导入到HBase
* @param args
*/
public static final String NAME="ImportFromFile";
public enum Counters{LINES}
static class ImportMapper extends Mapper<LongWritable,Text,
ImmutableBytesWritable,Writable>{
private byte[] family =null;
private byte[] qualifier = null;
@Override
protected void setup(Context cxt){
String column = cxt.getConfiguration().get("conf.column");
byte[][] colkey = KeyValue.parseColumn(Bytes.toBytes(column));
family = colkey[0];
if(colkey.length>1){
qualifier = colkey[1];
}
}
@Override
public void map(LongWritable offset,Text line,Context cxt){
try{
String lineString= line.toString();
byte[] rowkey= DigestUtils.md5(lineString);
Put put = new Put(rowkey);
put.add(family,qualifier,Bytes.toBytes(lineString));
cxt.write(new ImmutableBytesWritable(rowkey), put);
cxt.getCounter(Counters.LINES).increment(1);
}catch(Exception e){
e.printStackTrace();
}
}
}
private static CommandLine parseArgs(String[] args){
Options options = new Options();
Option o = new Option("t" ,"table",true,"table to import into (must exist)");
o.setArgName("table-name");
o.setRequired(true);
options.addOption(o);
o= new Option("c","column",true,"column to store row data into");
o.setArgName("family:qualifier");
o.setRequired(true);
options.addOption(o);
o = new Option("i", "input", true,
"the directory or file to read from");
o.setArgName("path-in-HDFS");
o.setRequired(true);
options.addOption(o);
options.addOption("d", "debug", false, "switch on DEBUG log level");
CommandLineParser parser = new PosixParser();
CommandLine cmd = null;
try {
cmd = parser.parse(options, args);
} catch (Exception e) {
System.err.println("ERROR: " + e.getMessage() + "
");
HelpFormatter formatter = new HelpFormatter();
formatter.printHelp(NAME + " ", options, true);
System.exit(-1);
}
return cmd;
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = HTableUtil.getConf();
String[] otherArgs = new GenericOptionsParser(conf, initialArg()).getRemainingArgs();
CommandLine cmd = parseArgs(otherArgs);
String table = cmd.getOptionValue("t");
String input = cmd.getOptionValue("i");
String column = cmd.getOptionValue("c");
conf.set("conf.column", column);
Job job = new Job(conf, "Import from file " + input + " into table " + table);
job.setJarByClass(ImportFromFile.class);
job.setMapperClass(ImportMapper.class);
job.setOutputFormatClass(TableOutputFormat.class);
job.getConfiguration().set(TableOutputFormat.OUTPUT_TABLE, table);
job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Writable.class);
job.setNumReduceTasks(0);
FileInputFormat.addInputPath(job, new Path(input));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
private static String[] initialArg(){
String []args = new String[6];
args[0]="-c";
args[1]="fam:data";
args[2]="-i";
args[3]="/user/hadoop/input/picdata";
args[4]="-t";
args[5]="testtable";
return args;
}
}
第二章、hive实战
一、topN实战
一、项目需求
1.统计视频观看数 Top10
2.统计视频类别热度Top10
3.统计出视频观看数最高的20个视频的所属类别以及类别包含这Top20视频的个数
4.统计视频观看数Top50所关联视频的所属类别的热度排名
5.统计每个类别中的视频热度Top10,以 Music为例
6.统计每个类别中视频流量 Top10 ,以 Music为例
7.统计上传视频最多的用户Top10以及他们上传的观看次数在前20的视频
8.统计每个类别视频观看数Top10(分组取topN)
二、数据介绍
1.视频数据表:

2.用户表:

三、创建表结构
1.视频表:
create table youtube_ori( videoId string, uploader string, age int, category array<string>, length int, views int, rate float, ratings int, comments int, relatedId array<string>) row format delimited fields terminated by " " collection items terminated by "&" ; create table youtube_orc( videoId string, uploader string, age int, category array<string>, length int, views int, rate float, ratings int, comments int, relatedId array<string>) clustered by (uploader) into 8 buckets row format delimited fields terminated by " " collection items terminated by "&" stored as orc;
2.用户表:
create table youtube_user_ori( uploader string, videos int, friends int) clustered by (uploader) into 24 buckets row format delimited fields terminated by " "; create table youtube_user_orc( uploader string, videos int, friends int) clustered by (uploader) into 24 buckets row format delimited fields terminated by " " stored as orc;
四、数据清洗
通过观察原始数据形式,可以发现,视频可以有多个所属分类,每个所属分类用&符号分割, 且分割的两边有空格字符,同时相关视频也是可以有多个元素,多个相关视频又用“ ”进 行分割。为了分析数据时方便对存在多个子元素的数据进行操作,我们首先进行数据重组清 洗操作。即:将所有的类别用“&”分割,同时去掉两边空格,多个相关视频 id 也使用“&” 进行分割。
1.ETLUtil
package com.company.sparksql;
public class ETLUtil {
public static String oriString2ETLString(String ori){
StringBuilder etlString = new StringBuilder();
String[] splits = ori.split(" ");
if(splits.length < 9) return null;
splits[3] = splits[3].replace(" ", "");
for(int i = 0; i < splits.length; i++){
if(i < 9){
if(i == splits.length - 1){
etlString.append(splits[i]);
}else{
etlString.append(splits[i] + " ");
}
}else{
if(i == splits.length - 1){
etlString.append(splits[i]);
}else{
etlString.append(splits[i] + "&");
}
}
}
return etlString.toString();
}
}
2.DataCleaner
package com.company.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object DataCleaner {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName(DataCleaner.getClass.getSimpleName)
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
val lineDS = spark.read.textFile("e:/0.txt")
import spark.implicits._
val splitedDS = lineDS.map(ETLUtil.oriString2ETLString(_))
splitedDS.write.format("text").save("e:/movie")
}
}
五、数据加载
1.视频表:
加载清洗之后的数据到原始视频表
load data local inpath "/opt/datas/cleaned.txt" into table youtube_ori;
加载数据到视频的ORC表
insert overwrite table youtube_orc select * from youtube_ori;
2、用户表:
加载清洗之后的数据到原始用户表
load data local inpath "/opt/datas/user.txt" into table user_ori;
加载数据到用户的ORC表
insert overwrite table user_orc select * from user_ori;
六、业务数据分析
1.统计视频观看数 Top10
select videoId, uploader, age , category , length , views , rate , ratings , comments from youtube_orc order by views desc limit 10;
2.统计视频类别热度Top10
第一种方式:
select category_name, count(videoId) as video_num from youtube_orc lateral view explode(category) youtube_view as category_name group by category_name order by video_num desc limit 10;
第二种方式:
select category_name as category,
count(t1.videoId) as hot
from (select
videoId,
category_name
from youtube_orc lateral view explode(category) t_catetory as category_name) t1
group by t1.category_name
order by hot desc
limit 10;
3.统计出视频观看数最高的20个视频的所属类别以及类别包含这Top20视频的个数
select category_name, count(videoId) as videonums from ( select videoId, category_name from (select category, videoId, views from youtube_orc order by views desc limit 20) top20view lateral view explode(category) t1_view as category_name )t2_alias group by category_name order by videonums desc;
4.统计视频观看数Top50所关联视频的所属类别的热度排名
select
category_name,
count(relatedvideoId) as hot
from
(select
relatedvideoId,
category
from
(select
distinct relatedvideoId
from (select
views,
relatedId
from
youtube_orc
order by views desc
limit 50 )t1 lateral view explode(relatedId) explode_viedeo as relatedvideoId)t2 join youtube_orc on youtube_orc.videoId = t2.relatedvideoId)t3 lateral view explode(category) explode_category as category_name
group by category_name
order by hot desc;
5.统计每个类别中的视频热度Top10,以 Music为例
select videoId, views from youtube_orc lateral view explode(category) t1_view as category_name where category_name = "Music" order by views desc limit 10 ;
6.统计每个类别中视频流量 Top10 ,以 Music为例
select videoId , ratings from youtube_orc lateral view explode(category) t1_view as category_name where category_name = "Music" order by ratings desc limit 10 ;
7.统计上传视频最多的用户Top10以及他们上传的观看次数在前20的视频
select t1.uploader,youtube_orc.videoId,youtube_orc.views from (select uploader,videos from youtube_user_orc order by videos desc limit 10) t1 inner join youtube_orc on t1.uploader = youtube_orc.uploader order by views desc limit 20 ;
8.统计每个类别视频观看数Top10(分组取topN)
select
t2_alias.category_name,
t2_alias.videoId,t2_alias.views
from
(
select
category_name,
videoId,views ,
row_number() over(partition by category_name order by views desc) rank
from
youtube_orc lateral view explode(category) t1_view as category_name ) t2_alias where rank <= 10;
二、成绩分析
1、场景举例
北京市学生成绩分析
2、成绩的数据格式
exercise5_1.txt 文件中的每一行就是一个学生的成绩信息。字段之间的分隔符是","
时间,学校,年纪,姓名,科目,成绩
3、样例数据
2013,北大,1,黄渤,语文,972013,北大,1,徐峥,语文,522013,北大,1,刘德华,语文,852012,清华,0,马云,英语,612015,北理工,3,李彦宏,物理,812016,北科,4,马化腾,化学,922014,北航,2,刘强东,数学,702012,清华,0,刘诗诗,英语,592014,北航,2,刘亦菲,数学,492014,北航,2,刘嘉玲,数学,7
4、建表导数据
create database if not exists exercise;use exercise;drop table if exists exercise5_1;create table exercise5_1(year int, school string, grade int, name string, course string, score int) row format delimited fields terminated by ',';load data local inpath "/home/hadoop/exercise5_1.txt" into table exercise5_1;select * from exercise5_1;desc exercise5_1;
5、需求
1、分组TopN,选出今年每个学校、每个年级、分数前三的科目
select t.* from (select school, grade, course, score,row_number() over (partition by school, grade, course order by score desc) rank_code from exercise5_1 where year = "2017") twhere t.rank_code <= 3;
详解如下: row_number函数:row_number() 按指定的列进行分组生成行序列,从 1 开始,如果两行记录的分组列相同,则行序列 +1。 over 函数:是一个窗口函数。 over (order by score) 按照 score 排序进行累计,order by 是个默认的开窗函数。 over (partition by grade) 按照班级分区。 over (partition by grade order by score) 按照班级分区,并按着分数排序。 over (order by score range between 2 preceding and 2 following) 窗口范围为当前行的数据幅度减2加2后的范围内的数据求和。
2、今年,北航,每个班级,每科的分数,及分数上下浮动2分的总和
select school, grade, course, score,sum(score) over (order by score range between 2 preceding and 2 following) sscorefrom exercise5_1 where year = "2017" and school="北航";
3、where与having:今年,清华1年级,总成绩大于200分的学生以及学生数
select school, grade, name, sum(score) as total_score,count(1) over (partition by school, grade) nctfrom exercise5_1where year = "2017" and school="清华" and grade = 1group by school, grade, namehaving total_score > 200;
having 是分组(group by)后的筛选条件,分组后的数据组内再筛选,也就是说 HAVING 子句可以让我们筛选成组后的各组数据。 where 则是在分组,聚合前先筛选记录。也就是说作用在 GROUP BY 子句和 HAVING 子句前。
三、实战三
1、英雄的出场排名top3的出场次数及出场率
1、有如下数据:(建表语句+sql查询)
id names 1 aa,bb,cc,dd,ee 2 aa,bb,ff,ww,qq 3 aa,cc,rr,yy 4 aa,bb,dd,oo,pp
2、求英雄的出场排名top3的出场次数及出场率
create table if not exists t_names( id int, names array ) row format delimited fields terminated by ‘ ’ collection items terminated by ‘,’ ; select * from ( select name,cc,cc / (sum(cc) over()) as ccl, rank() over(sort by cc desc) as rk from ( select name, count(1) as cc from t_names lateral view explode(names) tt as name group by name ) a ) aa where aa.rk <= 3 ;
2、共同通话时长
1、有如下通话记录:
Zhangsan Wangwu 01:01:01 Zhangsan Zhaoliu 00:11:21 Zhangsan Yuqi 00:19:01 Zhangsan Jingba 00:21:01 Zhangsan Wuxi 01:31:17 Wangwu Zhaoliu 00:51:01 Wangwu Zhaoliu 01:11:19 Wangwu Yuqi 00:00:21 Wangwu Yuqi 00:23:01 Yuqi Zhaoliu 01:18:01 Yuqi Wuxi 00:18:00 Jingba Wangwu 00:01:01 Jingba Wangwu 00:00:06 Jingba Wangwu 00:02:04 Jingba Wangwu 00:02:54 Wangwu Yuqi 01:00:13 Wangwu Yuqi 00:01:01 Wangwu Zhangsan 00:01:01
2、统计两个人的通话总时长(用户之间互相通话的时长)
create table relations( fromstr string, tostr string, time string ) row format delimited fields terminated by ’ ’ ; select fromstr, tostr, sum(duration) as durations from ( Select Case when fromstr >= tostr then fromstr else tostr end fromstr, Case when fromstr >= tostr then tostr else fromstr end tostr, Split(time,’:’)[0] * 60 * 60 + Split(time,’:’)[1] * 60 + Split(time,’:’)[2] duration from relations ) a group by fromstr,tostr ;
3、销售数据分析
1、有如下销售数据:(建表语句+sql查询)
店铺 月份 金额
a,01,150 a,01,200 b,01,1000 b,01,800 c,01,250 c,01,220 b,01,6000 a,02,2000 a,02,3000 b,02,1000 b,02,1500 c,02,350 c,02,280 a,03,350 a,03,250
2、编写Hive的HQL语句求出每个店铺的当月销售额和累计到当月的总销售额
create table t_store( name string, months int, money int ) row format delimited fields terminated by “,”; select name,months,amoney,sum(amoney) over(distribute by name sort by months asc rows between unbounded preceding and current row) as totalmomey from ( Select name,months,sum(money) as amoney From t_store Group by name,months ) a ;
4、统计amt连续3个月,环比增长>50%
1、[Hive SQL]统计amt连续3个月,环比增长>50%的user
user_id month amt 1,20170101,100 3,20170101,20 4,20170101,30 1,20170102,200 2,20170102,240 3,20170102,30 4,20170102,2 1,20170101,180 2,20170101,250 3,20170101,30 4,20170101,260 … …
select user_id from( select user_id,month,mon_amt,pre_mon_amt, sum(case when ((mon_amt - pre_mon_amt) / pre_mon_amt * 100) > 50 and datediff(to_date(month,‘yyyymm’),to_date(pre2_month,‘yyyymm’),‘mm’) = 2 then 1 else 0 end) over(partition by user_id order by month asc rows between current row and 2 following) as flag from ( select user_id, substr(month,0,6) as month, sum(amt) as mon_amt, lag(sum(amt),1,0.00001) over(partition by user_id order by substr(month,0,6) asc ) as pre_mon_amt, substr(lag(substr(month,0,6),2,‘199001’) over(partition by user_id order by substr(month,0,6) asc),0,6) as pre_2_mon from amt group by user_id,substr(month,0,6) ) t1 ) t2 where t2.flag >=3;
四、求波峰和波谷
1、首先按照股票的代码分类,以时间排序
create table t2 as select code,time,price,row_number() over(partition by code order by time) rn from t1;
2、最后通过case when then else end 求出波峰和波谷
select a.code,a.time,a.price,
case when b.price is null then "未知"
when c.price is null then "未知"
when a.price>b.price and a.price>c.price then "波峰"
when a.price<b.price and a.price<c.price then "波谷"
else "中间" end as mark,a.rn
from t2 a
left join
t2 b on a.code=b.code and b.rn=a.rn-1
left join
t2 c on a.code=c.code and c.rn=a.rn+1
order by a.code,a.rn;
第三章、hive面试
1、Hive 最常见的几个面试题
1.hive 的使用, 内外部表的区别,分区作用, UDF 和 Hive 优化 (1)hive 使用:仓库、工具 (2)hive 内部表:加载数据到 hive 所在的 hdfs 目录,删除时,元数据和数据文件都删除 外部表:不加载数据到 hive 所在的 hdfs 目录,删除时,只删除表结构。 (3)分区作用:防止数据倾斜 (4)UDF 函数:用户自定义的函数 (主要解决格式,计算问题 ),需要继承 UDF 类 java 代码实现 class TestUDFHive extends UDF { public String evalute(String str){ try{ return "hello"+str }catch(Exception e){ return str+"error" }
}
}
(5)sort by和order by之间的区别?
使用order by会引发全局排序;
select * from baidu_click order by click desc;
使用 distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
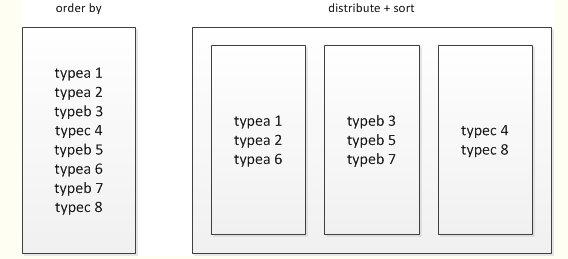
sort by的排序发生在每个reduce里,order by和sort by之间的不同点是前者保证在全局进行排序,而后者仅保证在每个reduce内排序,如果有超过1个reduce,sort by可能有部分结果有序。
注意:它也许是混乱的作为单独列排序对于sort by和cluster by。不同点在于cluster by的分区列和sort by有多重reduce,reduce内的分区数据时一致的。
(6)Hive 优化:看做 mapreduce 处理