word2vec主要是把单词表示为向量。当我们处理文本的时候,为了让计算机能够阅读和计算,肯定需要把文字转成数字(向量)。比较naive的方法是直接给按字母顺序标号,也能得到向量。但是这些向量只能表示字母顺序的关系。但是一个单词含有很多含义,存在近义词,反义词等等的关系(其实近义和反义就是对该单词含义的解释,当定义清楚了所有单词之间的关系,那么整个语言就被理解了),我们更希望我们的向量能够在向量空间上表现出这些关系,那么如何让计算机自动的发现这些关系,并把他们表示出来,就是Distributed Representation。那么,我们怎么让机器自己找到单词之间的关系呢?人们觉得可以通过上下文。人们觉得,如果我给出上下文,机器能够找出对应的单词,那么就认为机器学到了词的含义(举个简单的例子:"你今天吃这么多,你肚子会很?的。"比如这里出现了?这个新词,虽然我们以前没有见过这个词,但是根据上下文,我们可以推断出这个词应该和'饱'、'撑'这几个词意思相近,那么机器也会产生相似的词向量)。
word2vec主要采用CBOW(Continuous Bag-of-Words Model,连续词袋)模型和Skip-Gram模型。
One-hot Representation:就是一个词给一个编号
Distributed Representation:根据词的语义进行编号,语义相近的词语距离比较近。由Hinton 在 1986 年的论文《Learning distributed representations of concepts》提出。
统计语言模型:
(1)上下文无关模型
只考虑词的词频分布,不考虑上下文信息。是n-gram中n=1时的情形。也称为一元文法统计模型(Unigram Model)
(2)n-gram模型
n=2时又叫Bigram模型。n-gram模型是向前看n-1个词。
存在问题:(a)n无法取太大,n太大效果不好,n太小无法捕获更长远的信息。(b)没有词间相似度的信息。(c)未出现过的短语概率为0(解决办法:Laplace平滑,回溯剪枝)。
(3)n-pos(Part-of-Speech)模型
就是把每个词映射到了一种类别上。
(4)基于决策树的语言模型
优点:灵活,缺点:构造困难,时空开销大
(5)最大熵模型
(6)自适应语言模型
属于动态模型,
(7)NNLM(Neural Network Language Model)
神经网络语言模型。
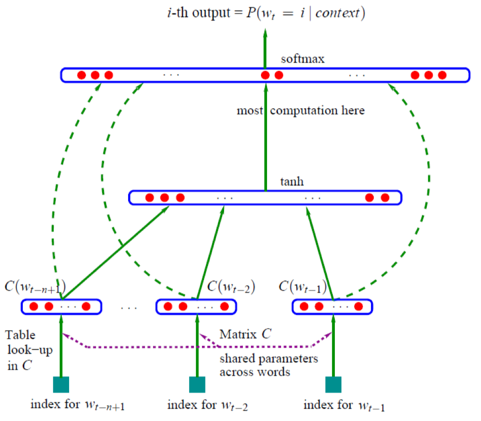

(8)log-linear模型

(9)层次化Log-Bilinear模型



(10)CBOW模型
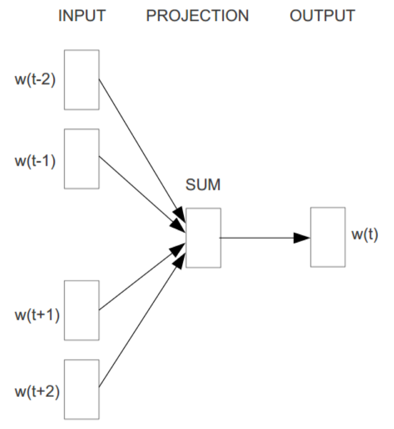
(11)Skip-Gram模型
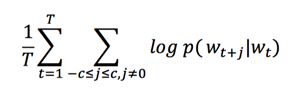
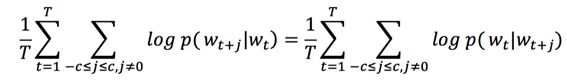
使用例子:http://www.cnblogs.com/hebin/p/3507609.html
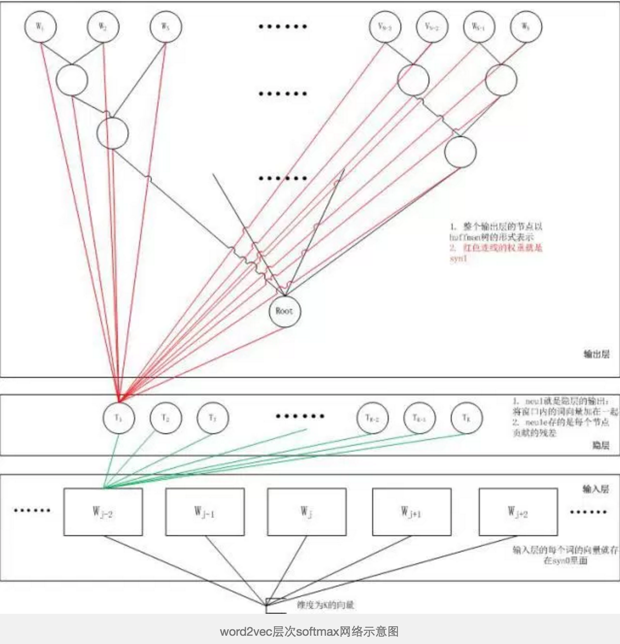
输入层读入窗口内的词,将它们的向量(K维,初始随机)加和在一起,形成隐藏层K个节点。输出层是一个巨大的二叉树,叶节点代表语料里所有的词(语料含有V个独立的词,则二叉树有|V|个叶节点)。而这整颗二叉树构建的算法就是Huffman树。这样,对于叶节点的每一个词,就会有一个全局唯一的编码,形如”010011″。我们可以记左子树为1,右子树为0。接下来,隐层的每一个节点都会跟二叉树的内节点有连边,于是对于二叉树的每一个内节点都会有K条连边,每条边上也会有权值。
这样,整体的结构就清晰了。在训练阶段,当给定一个上下文,要预测后面的词(Wn)的时候(word2vec的CBOW和Skip-gram都不是预测后面的词,都是在中间的词上做文章,但是本文这么写并不影响理解),实际上我们知道要的是哪个词(Wn),而Wn是肯定存在于二叉树的叶子节点的,因此它必然有一个二进制编号,如”010011″,那么接下来我们就从二叉树的根节点一个个地去便利,而这里的目标就是预测这个词的二进制编号的每一位!即对于给定的上下文,我们的目标是使得预测词的二进制编码概率最大。形象地说,我们希望在根节点,词向量和与根节点相连经过logistic计算得到的概率尽量接近0(即预测目标是bit=1);在第二层,希望其bit是1,即概率尽量接近1……这么一直下去,我们把一路上计算得到的概率相乘,即得到目标词Wn在当前网络下的概率(P(Wn)),那么对于当前这个sample的残差就是1-P(Wn)。于是就可以SGD优化各种权值了。
虽然用了huffuman树,但是如果两个词意思基本一样,但是一个词出现频率很低,另一个词出现频率很高,那么效果会变差?或者说两个单词相差很远,但是出现频率相似,那么它们会有很大的相同路径,那么他们的词向量会相似,那么效果变差?难道意思相近的词语出现频率也差不多?
2000 百度 IDL的徐伟 《Can Artificial Neural Networks Learn Language Models? 》
2001 Bengio 《A Neural Probabilistic Language Model》NIPS
2003 Bengio 《A Neural Probabilistic Language Model》JMLR 就是前文第7个模型
2008 Ronan Collobert 和 Jason Weston 《A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning》ICML
2011 Ronan Collobert 和 Jason Weston 《Natural Language Processing (Almost) from Scratch》JMLR
for more to see here: http://licstar.net/archives/328
word2vec的应用主要是要有词,而且不能只有一个词,还要有一定的序列。
比如进行推荐好友,那么每个用户可以看做一个词,好友列表可以看做词序列,然后就可以训练了。然后推荐你好友列表中词向量接近的人。
(这里说说这种推荐和利用LDA进行推荐的区别:首先,这里每个用户被看成词,LDA的话把每个用户看成文档(即用户的详细信息)。word2vec会调用你的好友列表,可能会给你推荐熟人;而LDA会分析每个用户的特点,会给你推荐你感兴趣的人,而这些人不是你的熟人。个人觉得LDA效果会好点(因为文档信息可以包含好友信息),但是LDA计算复杂度高,word2vec计算机复杂度会低一些。但是LDA有个局限,就是LDA必须要足够长度的文档和足够多的文档,如果就是一个小广告,就很难被当成文档,更适合当成单词,用word2vec会好些。但是我们也可以把小的东西,比如小广告进行分组,那么小广告就变成了‘大’广告,这时就可以看成是文档了。)