摘要:本文从总体架构、数据分布方式、计算下推、数据强一致等方面进行介绍GaussDB(for openGauss)。
1.前言
随着云计算规模越来越大,企业业务数据量呈指数级增长,传统数据库在海量数据存储与管理方面显得力不从心,面临“存不下,算得慢、算不准”的问题。
面对挑战,华为云数据库深度融合华为在数据库领域多年的经验,充分结合了企业级场景需求,基于openGauss自研生态推出了企业级分布式关系型数据库GaussDB(for openGauss)。GaussDB(for openGauss)目前支持单分片和分布式两种部署形态,在支撑传统业务的基础上,持续构建竞争力特性,为企业面向数字化转型提供了无限可能。
4月9日,由华为云主办的GaussDB(for openGauss)系列技术直播第2期《华为云数据库 GaussDB(for openGauss)数据存储与访问》于线上开启,直播详细介绍了GaussDB(for openGauss)的数据分布方式和数据读写流程,为方便大家快速了解GaussDB(for openGauss),本文结合第2场直播内容从总体架构、数据分布方式、计算下推、数据强一致等方面进行介绍。
2.分布式架构
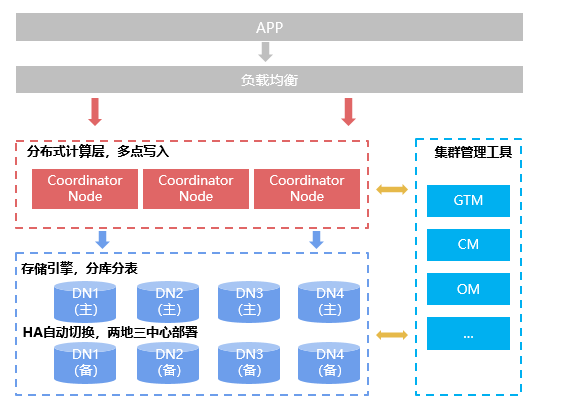
GaussDB(for openGauss)是一个典型的基于数据分片的双层分布式架构(share nothing),数据通过一定的规则比如hash、list或者range等让数据打散分布到不同的数据节点上,计算时底层多个数据节点共同参与,上层协调节点负责执行计划生成和结果汇聚。
3.让数据“存得下、算得快、算得准”
随着5G时代的到来,单一节点是难以应对数据规模的不断增长并确保性能的需要,业务面临“存不下、算得慢、算不准”的问题。而GaussDB(for openGauss)可横向扩展的分布式架构可以很好满足大规模海量数据的计算存储需求,让数据“存得下、算得快、算得准”。
3.1海量数据“存得下”
GaussDB(for openGauss) 支持1000+的数据节点扩展能力,数据通过一定的规则比如hash、list或者range等让数据打散分布到不同的数据节点上,让数据“存得下”。
数据分布方式
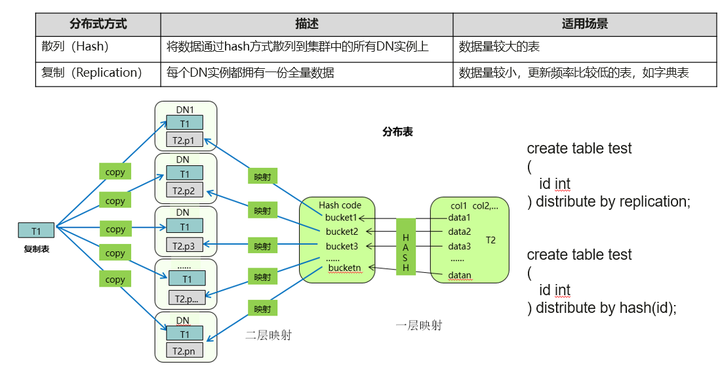
GaussDB(for openGauss)支持hash、list、range、replication分布方式,下图以hash和replication为例,示意了数据在DN节点上的分布情况。create table通过distribute by语法指定表的数据分布方式。hash分布把数据散列存储到所有DN,适合数据量比较大的表;replication分布把数据复制存储到所有DN,数据更新时,会同时更新所有DN,采用2PC(两阶段提交)保证分布式事务的一致性,适合更新频率比较低的小表。
一致性hash
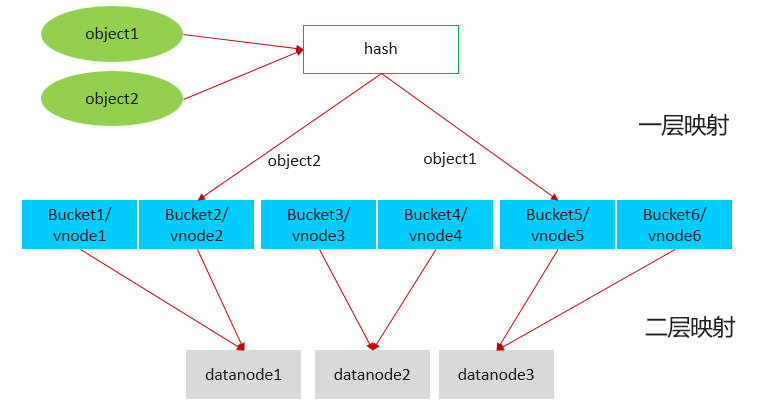
GaussDB的hash分布采用类似一致性hash的方式,数据通过两层映射,第一层通过hash映射把数据映射到N个hash bucket中,或者叫vnode中;第二层映射把vnode映射到物理的datanode上。扩容时,只需要调整二层映射,保证数据搬迁最小:数据只会搬迁到新节点,已有节点之间不会互相搬迁数据;
分布键的选择
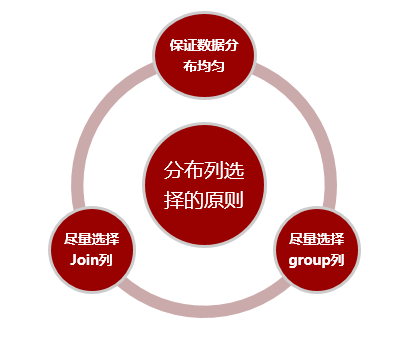
对于数据分布来讲,分布键的选择至关重要,不合适的分布键会导致数据倾斜,导致木桶效应。分布键的选择一般遵循如下原则:
a. 尽量选择distinct值比较多的列,保证数据均匀分布。分布均匀是为了避免木桶效应,各个节点对等执行。
b. 尽量选择Join列或group 列做分布列。尽量选择Join列或group 列是为了避免数据节点之间数据流动, 提高性能。
数据倾斜
当我们选择了一个分布键之后,如何判断数据是否分布均匀呢?GaussDB(for openGauss)提供了SQL语句可以方便的查询是否发生了数据倾斜。
通过如下方法,可以查询数据存储在那个DN,其中xc_node_id就是DN的内部标识,取值于系统表pgxc_node的xc_node_id列。
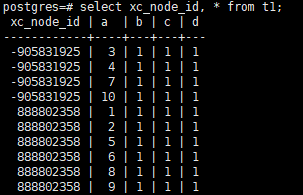
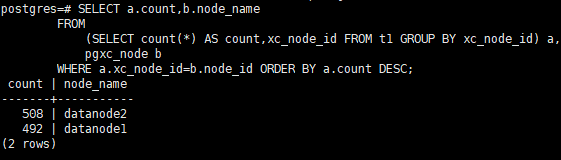
通过如下SQL,就可以查看表在各个DN上的数据分布情况,一般来说,DN的数据量相差10%以上,则可能发生了数据倾斜,就要考虑按照前面的原则调整分布列。
SELECT a.count,b.node_name FROM (SELECT count(*) AS count,xc_node_id FROM tablename GROUP BY xc_node_id) a, pgxc_node b WHERE a.xc_node_id=b.node_id ORDER BY a.count DESC;
3.2计算下推,“算得快”
GaussDB(for openGauss) 的优化器和全并行分布式执行能力,把计算下推到DN节点,减少数据移动,让数据“算得快”。
数据读写流程
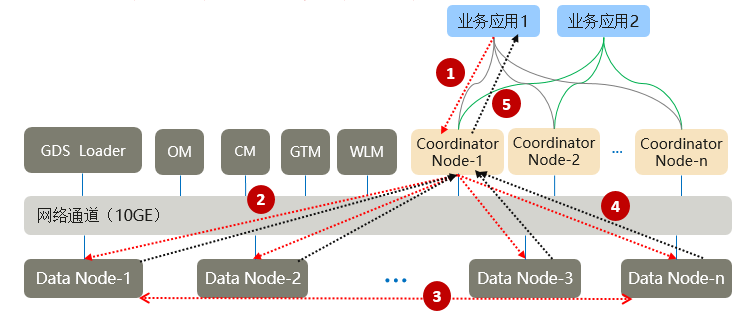
大致执行过程:
- 业务应用下发SQL给Coordinator ,SQL可以包含对数据的CRUD操作;
- Coordinator利用数据库的优化器生成执行计划,每个DN会按照执行计划的要求去处理数据;
- 数据基于一致性Hash算法分布在每个DN,因此DN在处理数据的过程中,可能需要从其他DN获取数据,GaussDB提供三种stream流(广播流、聚合流和重分布流)实现数据在DN间的流动,使得join无需抽取到CN执行;
- DN将结果集返回给Coordinate进行汇总;
- Coordinator将汇总后的结果返回给业务应用。
华为在SQL执行优化方面有多年的沉淀,即使是复杂的SQL、事务分析混合(HTAP)的场景也能得到最佳的执行,我给大家举一些列子:
- 基于代价的优化
- 基数估算:Feedback增强、AI基数增强
- 代价估算:行存/列存代价估算、网络通信代价估算
- 搜索算法:动态规划方法、遗传算法、AI搜索
- 分布式执行计划能力
- Light Proxy
- Fast Query Shipping
- Remote Query Shipping
- 自研Cascade优化器
- 对象化处理规则应用及搜索任务
- 基于分支限界的剪枝技术
计算下推
优化器是GaussDB(for openGauss)关键技术之一,可以把各种复杂的SQL进行下推执行,最小化数据移动,这是GaussDB相对于基于分库分表的中间件方案的核心优势(对于复杂查询,由于计算无法下推,中间件很容易成为性能瓶颈,需要业务做比较大的改造来规避)。
以下案例的表结构为:
create table t1(a int, b int, c int) distribute by hash(a);
create table t2(a int, b int, c int) distribute by hash(a);
单表查询下推
单表查询,不管SQL的where条件是否带有分片键,优化器都可以生成下推的执行计划,包括sort/group by等复杂算子,都可以下推。
1)分片键上的where条件,直接下推到DN
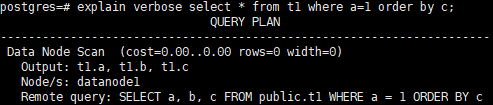
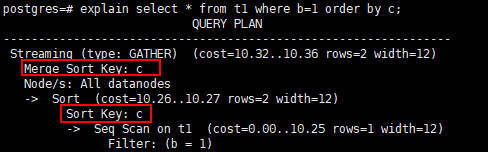
2)非分片键where条件,DN先计算,CN做汇总,sort/group by可以直接下推到DN
Join查询下推
1)分片键上的join条件,直接下推到DN执行
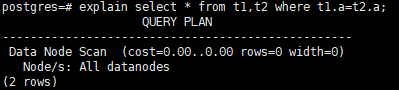
2)非分片键join条件,DN直接做数据交换,避免CN成为性能瓶颈
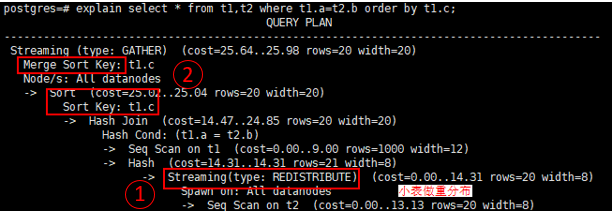
1,Join下推到DN执行,DN之间直接进行数据重分布,交换数据,无需CN参与;CBO优化器选择小表t2做重分布;
2,Sort下推到DN,CN只需做归并排序,避免CN成为性能瓶颈;
3.3数据强一致,“算得准”
数据强一致是GaussDB(for openGauss)相对于基于分库分表的中间件方案的另一个核心优势,基于中间件的方案由于不感知事务的快照逻辑,只能做到最终一致性,部分场景需要业务做比较大的改造来规避陷阱。GaussDB(for openGauss)提供数据强一致能力,让数据“算得准”。
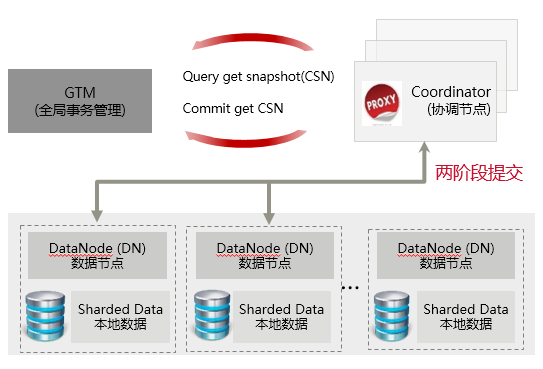
- 分布式强一致:
1)两阶段提交保证写的原子性。
2)两阶段提交对用户透明,写操作如果只涉及一个节点,无需使用两阶段提交。
3)全局CSN保证读的强一致。
- 高性能事务管理:
GTM线程池、原子的CSN分配,中心节点无性能瓶颈。
4.总结
综上所述,GaussDB(for openGauss)基于可横向扩展的分布式架构,提供了海量存储、快速响应、数据强一致的能力,可以很好满足大规模海量数据的计算存储需求,让数据“存得下、算得快、算得准”。
值得一提的是,openGauss是开放的生态:架构开放、代码开放、技术开放和社区开放,方便企业选择开放的生态,让自己的业务具备更好的连续性。毕竟如果让企业从一个封闭的生态走向为另外一个封闭的生态,本质上并没有解决业务连续性的问题,不开放的生态是没有活力的,数据库软件尤甚,所以华为十分重视生态开放。
目前openGauss单分片版本的源代码已经开源,社区地址为:https://opengauss.org,欢迎大家自行下载、安装和体验。
Ps:错过直播的小伙伴不要灰心,点击链接回播视频看起来:https://bbs.huaweicloud.com/live/cloud_live/202104091600.html
本文分享自华为云社区《华为云GaussDB(for openGauss)专场直播第2期:让数据“存得下、算得快、算得准”》,原文作者:心机胖 。