
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说)、深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云。更多精彩内容请单击此处。
摘要:在2016年开源的高性能、开源联机分析列式数据库管理系统。其数据压缩比高,基于多核并行计算、向量化执行与SIMD,在性能上表现卓越。当前ClickHouse被广泛的应用于互联网广告、App和Web流量、电信、金融、物联网等众多领域,非常适用于商业智能化应用场景,在国内外有大量的应用和实践。
本文分享自华为云社区《【云小课】EI第22课 MRS基础原理之ClickHouse组件介绍》,作者:阅识风云
ClickHouse是一款开源的面向联机分析处理的列式数据库,其独立于Hadoop大数据体系,最核心的特点是极致压缩率和极速查询性能。同时,ClickHouse支持SQL查询,且查询性能好,特别是基于大宽表的聚合分析查询性能非常优异,比其他分析型数据库速度快一个数量级。当前ClickHouse被广泛的应用于互联网广告、App和Web流量、电信、金融、物联网等众多领域,非常适用于商业智能化应用场景,在国内外有大量的应用和实践。

ClickHouse关键特性介绍
完备的DBMS功能
ClickHouse拥有完备的数据库管理功能,具备一个DBMS(Database Management System,数据库管理系统)基本的功能,如下所示:
DDL (数据定义语言):可以动态地创建、修改或删除数据库、表和视图,而无须重启服务。
DML(数据操作语言):可以动态查询、插入、修改或删除数据。
权限控制:可以按照用户粒度设置数据库或者表的操作权限,保障数据的安全性。
数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生产环境的要求。
分布式管理:提供集群模式,能够自动管理多个数据库节点。
列式存储与数据压缩
ClickHouse是一款使用列式存储的数据库,数据按列进行组织,属于同一列的数据会被保存在一起,列与列之间也会由不同的文件分别保存。
在执行数据查询时,列式存储可以减少数据扫描范围和数据传输时的大小,提高了数据查询的效率。
向量化执行引擎
ClickHouse利用CPU的SIMD指令实现了向量化执行。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据,通过数据并行以提高性能的一种实现方式 ( 其他的还有指令级并行和线程级并行 ),它的原理是在CPU寄存器层面实现数据的并行操作,相比同类OLAP产品执行效率更高。
副本机制
ClickHouse利用ZooKeeper,通过ReplicatedMergeTree引擎(Replicated 系列引擎)实现了副本机制。副本机制是多主架构,可以将INSERT语句发送给任意一个副本,其余副本会进行数据的异步复制。
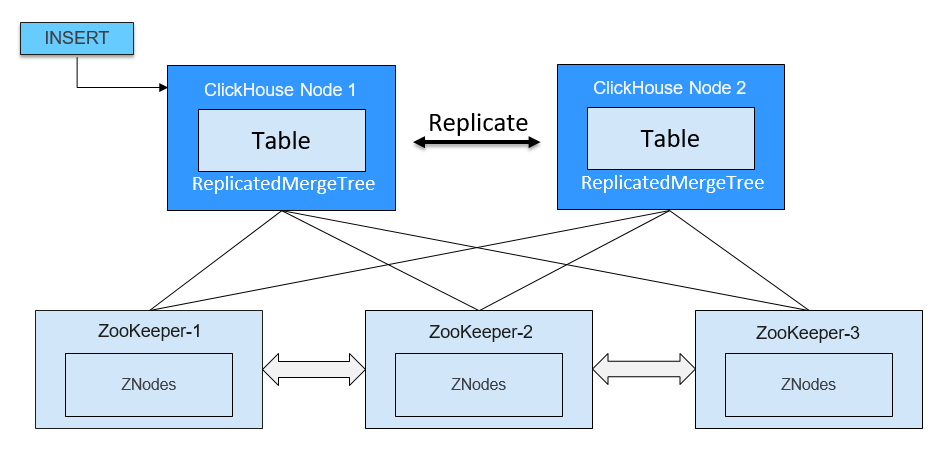
副本机制功能优势如下:
ClickHouse副本机制的设计可以最大限度的减少网络数据传输,用以在不同的数据中心进行同步,可以用来建设多数据中心、异地多活的集群架构。
副本机制是实现高可用、负载均衡、迁移/升级功能的基础。
系统会监视副本数据的同步情况,识别故障节点,并在节点恢复正常时进行故障恢复,保证服务整体高可用。
数据分片与分布式查询
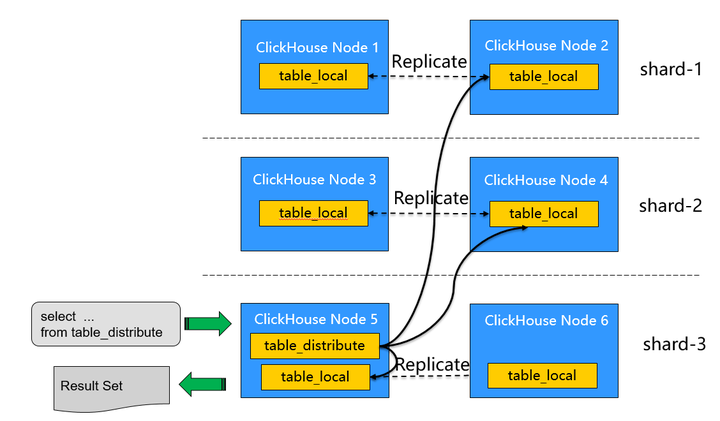
ClickHouse通过分片和分布式表机制提供了线性扩展的能力。
分片机制:用来解决单节点的性能瓶颈,通过将数据进行水平切分,将一张表中的数据拆分到多个节点,不同节点之间的数据没有重复,这样就可以通过增加分片对ClickHouse进行线性扩展。
分布式表:在查询分片的数据时,通过分布式表进行查询,分布式表引擎自身不存储任何数据,仅是一层代理,能够自动路由到集群中的各个分片节点获取数据,即分布式表需要和其他数据表一起协同工作。
如下图所示,在查询时,我们需要查询分布式表 table_distributed,分布式表会将查询请求自动路由到各个分片节点上,并进行结果的汇聚。
讲了这么多,具体怎么使用ClickHouse呢?别急,以下通过ClickHouse客户端使用和数据库基本操作带你快速上手。
操作前准备
- 已创建ClickHouse集群。
- 已安装ClickHouse客户端。
ClickHouse客户端使用
1. 以客户端安装用户,登录安装客户端的节点。
2. 执行以下命令,切换到客户端安装目录。以下目录为举例,具体客户端路径请以实际安装路径为准。
cd /opt/Bigdata/client
3. 执行以下命令配置环境变量。
source bigdata_env
4.执行ClickHouse组件的客户端命令。
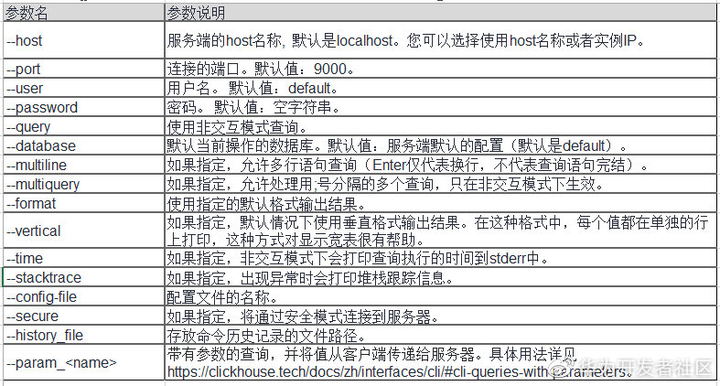
clickhouse client --host ClickHouse的实例IP --user 登录名 --password 密码 --port ClickHouse的端口号
clickhouse client命令行参数说明如下表所示:
ClickHouse数据库基本操作
创建数据库:
基本语法
CREATE DATABASE [IF NOT EXISTS] database_name
使用示例

创建表:
基本语法
方法一:在指定的“database_name”数据库中创建一个名为“table_name ”的表。
如果建表语句中没有包含“database_name”,则默认使用客户端登录时选择的数据库作为database_name”。
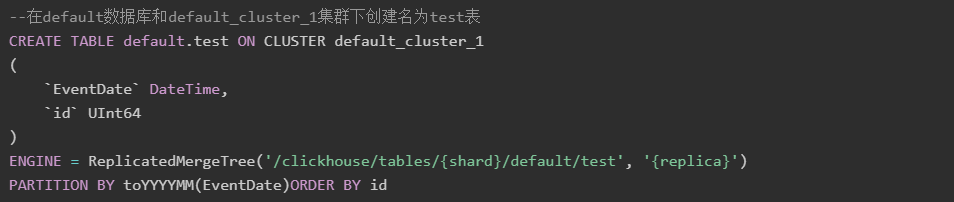
CREATE TABLE [IF NOT EXISTS] [database_name.]table_name [ON CLUSTER Cluster名]
(
name1 [type1] [DEFAULT|materialized|ALIAS expr1],
name2 [type2] [DEFAULT|materialized|ALIAS expr2],
...
) ENGINE = engine
方法二:创建一个与table_name2具有相同结构的表,同时可以对其指定不同的表引擎声明。
如果没有表引擎声明,则创建的表将与database_name2.table_name2使用相同的表引擎。
CREATE TABLE [IF NOT EXISTS] [database_name.]table_name AS [database_name2.]table_name2 [ENGINE = engine]
方法三:使用指定的引擎创建一个与SELECT子句的结果具有相同结构的表,并使用SELECT子句的结果填充它。
CREATE TABLE [IF NOT EXISTS] [database_name.]table_name ENGINE = engine AS SELECT ...
使用示例
插入表数据:
基本语法
方法一:标准格式插入数据。
INSERT INTO [database_name.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23), ...
方法二:使用SELECT的结果写入。
INSERT INTO [database_name.]table [(c1, c2, c3)] SELECT ...
使用示例

查询表数据:
基本语法
SELECT [DISTINCT] expr_list
[FROM [database_name.]table | (subquery) | table_function] [FINAL]
[SAMPLE sample_coeff]
[ARRAY JOIN ...]
[GLOBAL] [ANY|ALL|ASOF] [INNER|LEFT|RIGHT|FULL|CROSS] [OUTER|SEMI|ANTI] JOIN (subquery)|table (ON <expr_list>)|(USING <column_list>)
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr_list] [WITH TOTALS]
[HAVING expr]
[ORDER BY expr_list] [WITH FILL] [FROM expr] [TO expr] [STEP expr]
[LIMIT [offset_value, ]n BY columns]
[LIMIT [n, ]m] [WITH TIES]
[UNION ALL ...]
[INTO OUTFILE filename]
[FORMAT format]
使用示例
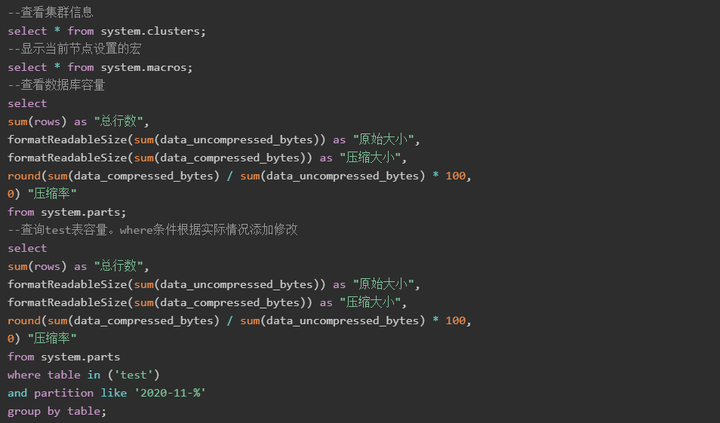
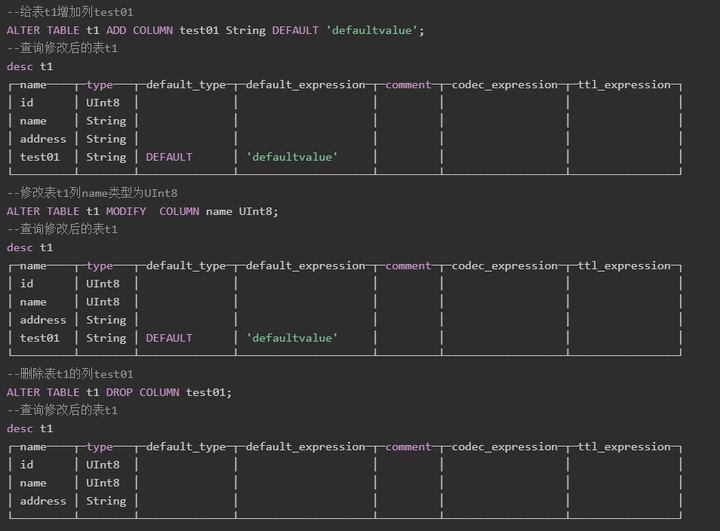
修改表结构:
基本语法
ALTER TABLE [database_name].name [ON CLUSTER cluster] ADD|DROP|CLEAR|COMMENT|MODIFY COLUMN ...
ALTER仅支持 *MergeTree ,Merge以及Distributed等引擎表。
使用示例
显示数据库和表信息
基本语法
show databases
show tables
使用示例

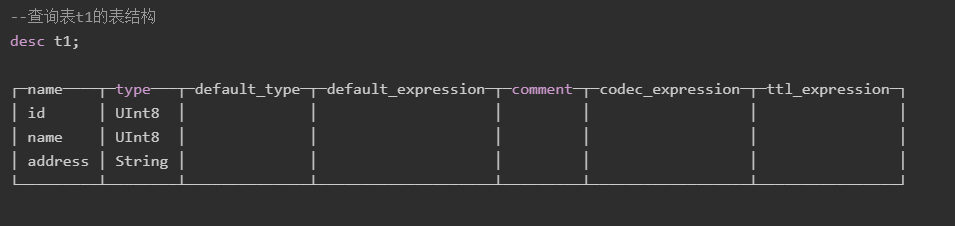
查询表结构
基本语法
DESC|DESCRIBE TABLE [database_name.]table [INTO OUTFILE filename] [FORMAT format]
使用示例
删除表:
基本语法
DROP [TEMPORARY] TABLE [IF EXISTS] [database_name.]name [ON CLUSTER cluster]
使用示例


好了,本期云小课就介绍到这里,快去体验MapReduce(MRS)更多功能吧!猛戳这里