摘要:开发者测试是现代软件工程中非常重要的一环,敏捷开发、主干开发这些先进的项目管理方法和流程都基于完善的开发者测试。
一、“开发者测试” 就是“开发者来测试”
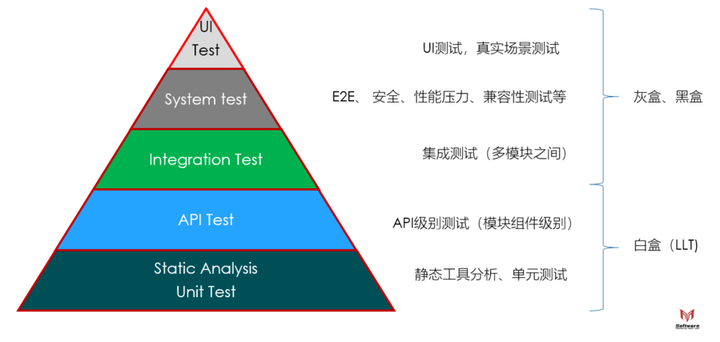
开发者测试是现代软件工程中非常重要的一环,敏捷开发、主干开发这些先进的项目管理方法和流程都基于完善的开发者测试。当每个月甚至每周都要交付一个版本时,不可能投入大量的测试工程师来进行大规模的系统级别测试,这时候就需要把整个测试金字塔中的绝大部分测试通过自动化来完成。
我们今天谈开发者测试,什么是“开发者测试”? 我司有清晰的开发与测试之分。写代码归开发攻城狮,测试归测试攻城狮,大部分情况下双方处于“红蓝对峙”状态。这与我10多年前的研发团队状况非常相似。而现在的软件工程,专职的“测试攻城狮”非常少,很多公司开发测试比例大于10:1,甚至一些部门没有测试攻城狮一说。 而测试攻城狮的角色不再是手动跑测试用例的“苦力”,而是管理产品的测试系统,对产品测试进行规划、分析;归纳功能测试的思维导图、设计测试用例及带领研发团队进行测试工作,更像一位“测试专家/测试教练”。
举个简单的例子,我之前做的产品是在线视频会议协作产品,我们每天的线上例会就是用自己做的产品,而且会使用自己开发的新功能测试站点来开“站会”。除了花少量的时间做dialy update,然后就是测试专家带领团队(包括PO、Architect、SM、Dev)按照计划来进行集中(半个小时)的测试。也就是说不止通常说的UT、API、IT等测试,包括系统级别的测试开发也会去做,所以说“开发者测试”就是“开发者来测试”,而我们传统的众多测试工程师面临三种出路:成长、转型、淘汰。而“测试专家”在项目中的话语权也很高,之前的公司使用主干开发,有个“一进一出”的评审,团队的这种类型的“测试专家”有一票否决权。甚至在公司有Principle Engineer级别的测试专家(相当于我司20-21级的技术专家)。
- 一进:对于一个功能是否能够进入release branch,在release branch打开feature toggle进行发布级别的测试。
- 一出:在engineer release时,该功能质量合格,允许feature toggle进入产线。
二、没有什么测试不可以“自动化测试”
回到测试金字塔,从测试的"开发成本"、“执行成本”、“测试覆盖率”、“问题定位”四个维度来看,基于代码级别的白盒测试是及其重要的。
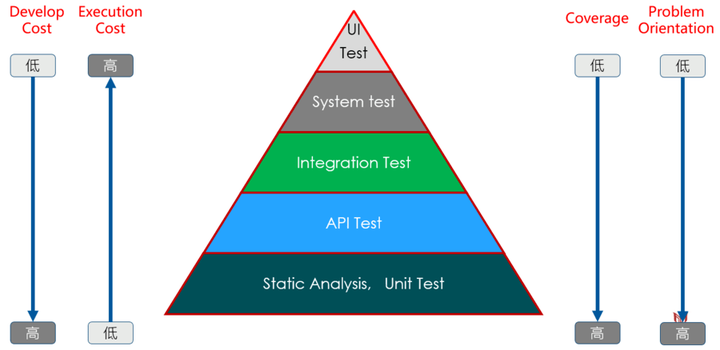
- 开发成本: 实现测试用例的成本。
- 执行成本:运行一次测试用例的成本。
- 测试覆盖率:我们通常所说的line coverage和branch coverage
- 问题定位:测试出现问题,定位问题的效率
通过测试金字塔及其四个测试维度评估,我们可以得出:
- 尽可能地多做Low Level Test :因为他们的执行速度相较于上层的几个测试类型来说快很多且相对稳定,可以一天多次执行。一般来说,LLT灰做到持续集成构建任务中去,甚至在MR中执行,保障进入代码仓库的代码质量。
- 在自动化保障的情况下,执行一定规模的IT、ST、UI Test:因为他们的执行速度较慢,环境依赖较多,测试相对不稳定。通常在一天执行一两次(通常在夜里),阶段性的检查代码质量,反馈代码问题。
- 尽可能地少做大规模的手动测试:因为他们的执行速度相较LLT且不够稳定,人力成本较高,也无法做到一天多次执行,每次执行都要等很久才能获得反馈结果。但是,他们更贴近真实用户场景,所以要确保一定周期内或者关键节点时间进行这种测试以确保软件质量。
现在很多公司已经迭代发布的周期越来越短,甚至做到了2周。手动测试显然无法适应这种开发模式,而把手动测试的测试用例通过各种技术方案自动化是唯一途径。代码层面,从底层业务代码到UI代码,只要架构设计合理,都是可以做UT。最顶层的UI交互测试,测试用例也是可以自动化运行(大部分UI框架都可以通过accessibility的接口进行UI自动化测试),我看到华为手机硬件部门都可以自动化测试“摔手机”这种极端测试,软件有啥做不到?至少有些业界技术大牛公司的某些产品,从代码提交Merge Request,到产品上产线是可以以天来计算的。这种产品的测试是不会也不可能通过手工测试来完成的。
三、开发者测试“利在当下”,“赢得未来”
很多人都认为底层的开发者测试,花了大量的时间,写了大量的代码,然后来保证功能的正确性,但是每次代码功能或者结构的的变更都要修改测试代码。而我手动调试和验证效率更高,甚至一些开发者测试更多的是为了指标。实际上通过UT,API测试来调试代码与自己手动运行调试区别不大,但是通过开发者测试对代码进行调试,从而保证当前项目迭代的质量;但是其更重要的作用不是这个。通常在我们bug分类中有这样一些名词 : Build Regression Bug, Release Regression Bug。
- Build Regression Bug : 开发中同样的功能在新版本出现一个bug,但是在之前的版本没有这个问题,我们叫做Build Regression Bug.
- Release Regression Bug : 产线上同样的功能在新版本出现一个bug,但是在之前的版本没有这个问题,我们叫做Release Regression Bug.
我们每次提交到产品中的代码,没有人可以保证其100%不会出现问题,在敏捷开发的这种快速迭代下,不太可能进行全功能的手动测试,所以开发者测试,特别是底层的UT、API测试、集成测试,能够很容易的识别发现这类问题,也就是开发者测试一个重要的功能是为了防御后面改动的代码对现在代码的影响。所以说开发者测试是”利在当下“,”赢得未来“。
四、灰度TDD,不强求必须先写测试代码
对于TDD,大家的认知是先写测试代码,再在写实现代码,这个说法对也不对。概念上没错,但是如果严格这样做,效率未必最高,这也是TDD很难推广的原因之一。我们把编码实现分成3个部分:实现代码、测试代码、调试代码。按照TDD的概念时先写测试代码、然后编码,最后调试。我们通常在代码实现时,一开始不大可能考虑的非常清晰,把接口定义的完全准确,如果严格按照测试、编码、调试来做,测试代码要随着编码频繁修改。 当然这本身不是什么大问题,在实际执行过程中,很多人习惯先搭好代码框架、测试框架,然后再编码,测试。等测试完成后再进行调试。所以从华为灰度管理的角度上来说,只要单元测试在调试之前,都可以称作TDD开发模式。BTW,当然现在开始流行BDD,这里想说的是如果连我说的TDD都做不到的团队,就不要考虑BDD了。
(Behavior-Driven Development:BDD将TDD的一般技术和原理与领域驱动设计(DDD)的想法相结合。 BDD是一个设计活动,您可以根据预期行为逐步构建功能块。 BDD的重点是软件开发过程中使用的语言和交互。 行为驱动的开发人员使用他们的母语与领域驱动设计的语言相结合来描述他们的代码的目的和好处。 使用BDD的团队应该能够以用户故事的形式提供大量的“功能文档”,并增加可执行场景或示例。 BDD通常有助于领域专家理解实现而不是暴露代码级别测试。它通常以GWT格式定义:GIVEN WHEN&THEN。)
五、UT覆盖率100%真的很不好
于单元测试,我们都会关注一个指标“覆盖率”。不管模块、函数、行、分支覆盖率,必须要有一定比例的覆盖率。但是每一项你都做到了100%,那么会给你打“差评”。不是说你做到不好(这里不谈是不是用了正确的方式),而是成本和性价比问题。以最难达到的分支覆盖率(branch coverage)为例,如果要做到100%的覆盖率,有些内存分配或者容错保护的分支都必须测试到,那么你的测试用例考虑要翻倍,但是并没有带来的相应价值。甚至一些代码条件分支在程序运行的生命周期内都没有被执行过。
- 模块覆盖率:业务模块代码通过UT,架构模块代码通过IT;就从UT的覆盖率的角度上去看,不需要去测试架构代码。
- 函数覆盖率:不要专门为一些无任何逻辑的代码去写UT。比如我们有些函数就是get/set一个属性,内部实现就用一个变量来赋值保存。这种函数写UT就是为了覆盖率而写,没有任何真正的意义。
- 行覆盖率:通常来看平局80%上下的行覆盖率是一个合理的指标,有些可以为0%,而有些需要100%,如果全部代码都超过90%,其成本较高,效率较低,不建议这样做。
- 分支覆盖率:越复杂的业务逻辑,越要写更多的测试用例来覆盖,而一些内存分配出错逻辑判断可以不需要测试。
六、用测试来驱动架构和代码质量
这里谈测试驱动架构和代码质量,主要说的是让代码具备完善的可测试性,什么是代码的可测试性?简单的说就是类与类之间,模块与模块关系解耦,类与类,模块与模块通过接口编程。依赖的接口通过被动注入式传入,而不是主动获取式。对于程序正常运行时,所传入的接口参数是真实的业务对象,而做测试时,可以传入fake的模拟实现。当然不是所有的依赖模块都这样做,一些与业务无关的Utility Library,或者一些特定的数据对象实现,可以直接调用。
这里我们讲到了fake与mock,关于Test Doubles,基本上的概念如下,具体每种代表什么意义,大家可以自行上网搜索
- 虚拟对象(dummy)
- 存根(stub)
- 间谍(spy)
- 模拟对象(mock)
- 伪对象(fake)
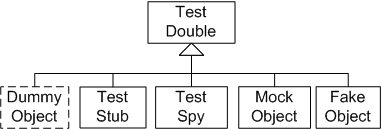
当前我司大家在做开发者测试时,基本上都在用Mock Object(实际上在用的过程中,很多是在用入参返回值控制的Stub)。还记得前些年DHH(David Heinemeier Hansson)的那篇文章《TDD is dead, Long live testing》,其中一点对于TDD中过度的使用Mock/Stub导致架构上诸多问题。而TDD创始人Kent Beck则说他从来不用Mock。 虽然通过Mock的方式也是可以测试代码,但是实际上不得不用Mock基本上意味着我们的代码关联性较强,模块显示依赖较重,模块移植性较差,特别是C语言编程这种问题特别多。以至于现在很多模块根本无法开展单元测试,更多的是在做集成测试。
为什么会出现这种情况? 我们的高级别的架构师更多的在考虑系统级别的架构设计,把系统模块,各个应用之间的关系梳理的非常清晰,通常情况下,高级别的架构师可以把系统模块或应用之间的关系设计的较为合理。然而到了具体的应用业务内部的设计与实现,交给了低级别的架构师来完成。实际上这些模块内部的代码量并不小,很多都是几十万行甚至上百万行的代码量。这时候架构师的水平决定了代码的Clean Code质量。我司目前代码上的问题很多不是系统架构的问题,而是具体业务实现中,缺少严格的要求和合理的架构设计。如果在应用级别有一套架构方案来规范,那么至少在模块的接口以及模块与模块之前的交互上也能达到和系统设计一样较为清晰合理。那么不确定的部分就时每个子模块内部几千上万行的代码部分。
最近做项目技术评审时,遇到一个典型的例子。一个团队写了一个socket库,底层依赖特定平台的系统库。如果要把该socket库移植到linux或者别的平台,就需要较大规模的重构。重构的方法应该很容易理解,就是通过适配器模式,把底层的操作抽象成接口(这里针对socket库来说,底层库是一种依赖,不同的场景要区别对待底层库,不要一概而论),实际代码不关注具体平台的具体实现,而通过实现不同平台的adapter来进行适配解决该问题。然而在开发初期,其设计在搭建代码框架、测试框架时就会发现底层库是一种耦合,测试时不得不做Mock来实现测试替身。如果这时候就考虑解耦式设计,那么当支持不同平台时,架构本身就天然支持而不需要再重构了。
之所以提出用测试驱动架构和代码质量,当给测试提出一个很高的标准时(之前做过的项目中有的项目明确UT不允许使用Mock,测试框架甚至只有单一的Catch2),大家不得不从架构上去解决测试的问题,当测试的问题解决时,代码架构上的Clean Code L3自然而然就达到了。
七、从“我要写测试依赖代码”到“我要写测试依赖代码”
这句话看着很奇怪,实际上是从根本上去解决底层开发者测试的根本方法。 模块之间有依赖,不管是通过Mock还是Fake的方法,不管架构上如何合理,这种依赖是不能消除的,我们做到更多的是合理的设计让依赖与模块解耦。第一个“我要写测试依赖代码”,指的是当我实现我的模块时,我要写测试代码来测试。然而我要考的是如何写我的测试依赖。这时候常常出现了的问题,比如是A1, A2, A3三个模块依赖与B1, B2两个模块,通常情况下我司的做A1,A2,A3的团队或者个人会自己去写B1,B2的依赖,导致重复的测试代码,如果模块设计不合理,测试依赖太多,单元测试成本太高。而第二个“我要写测试依赖代码”指的是,当我实现我的代码时,我要考虑的是依赖我的模块在测试时,对于我的依赖该怎么解决,"我要写测试依赖代码”(就是我说的fake对象与实现)来帮助依赖我的模块解决测试依赖问题。同样的情况在测试A1,A2,A3的时候,B1,B2的依赖已经存在,只要直接关注在测试用例本身就可以了。具体来说:
- 思维转变、测试驱动:开发一个模块,不要先考虑怎么测试自己,先考虑如果别人依赖我,我该怎么让别人更容易测试。模块的提供者,不止要提供模块代码,还要提供一个可复用的Faked对象(调用验证;返回值;参数验证;参数处理;功能模拟等)。
- 模块代码的编写者实现自己的Fake实现,基本上大部分的代码是由模块编写者来完成,同时这是一个可复用的Fake实现。模块依赖方根据自己一些特殊的业务需求来添加自己的代码。基本上遵循80/20原则。
- 架构上依赖解耦,通过注入依赖的方式进行接口编程。产品运行时,模块使用真实的实现对象,而开发者测试使用Fake对象。
- 当编写测试代码时,所有依赖的接口、依赖的实现都基本完成,更多的关注些测试用例而不是测试依赖。