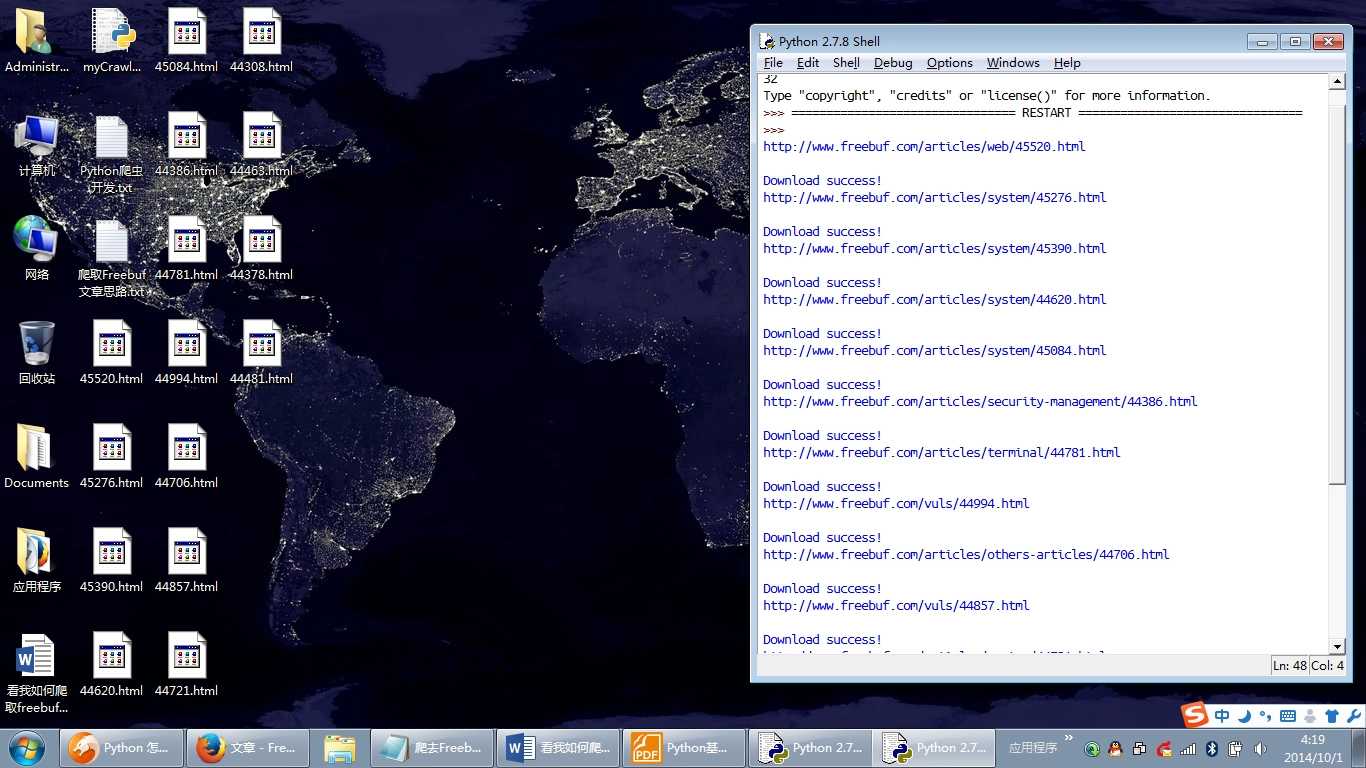
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看
先分析网站内容,红色部分即是网站文章内容div,可以看到,每一页有15篇文章

随便打开一个div来看,可以看到,蓝色部分除了一个文章标题以外没有什么有用的信息,而注意红色部分我勾画出的地方,可以知道,它是指向文章的地址的超链接,那么爬虫只要捕捉到这个地址就可以了。

接下来在一个问题就是翻页问题,可以看到,这和大多数网站不同,底部没有页数标签,而是查看更多,这里让我当时突然有点无从下手。
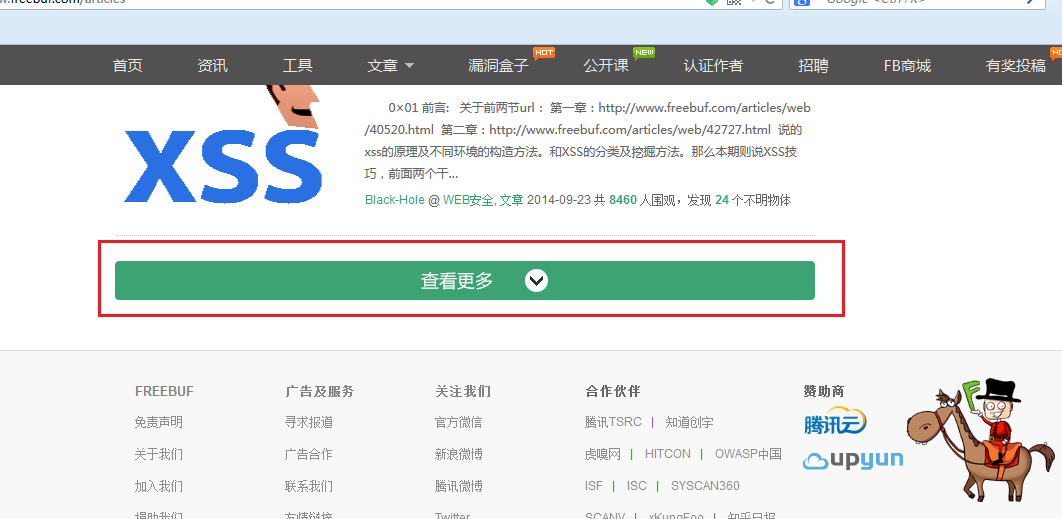
不过在查看源文件时我发现了如下图所示的一个超链接,经测试它指向下一页,那么通过改变其最后的数值,就可以定位到相应的页数上。
那么由以上信息,就可以对爬虫的步骤有一个相应的解决方案
1.抓取每一页上的所有文章的位置
2.捕捉每一页文章的URL
3.处理捕捉到的URL
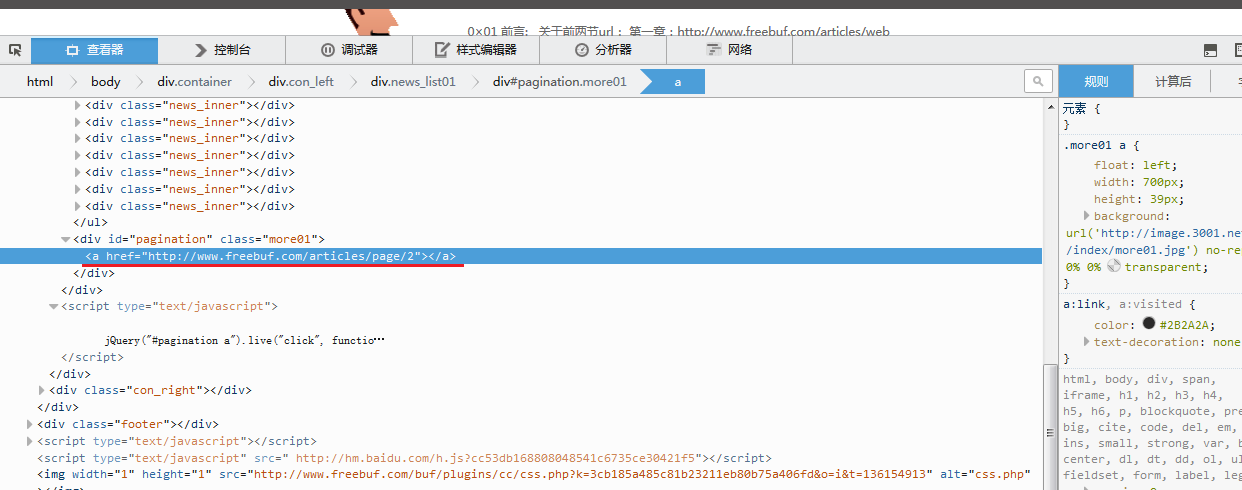
那么问题又来了,我该如何定位每一篇文章在其源代码中的位置呢?
以第一篇文章为例,在源代码中查询”<dt><a href=”这个字符串,为什么要查询这个字符串呢?因为每一篇文章的url都以它开头,那么我只要找到这个字符串就定位了每一篇文章的开始位置,定位到文章的开始位置后,还必须定位文章的结束位置,才能提取出中间的url,如下图所示

代码:
import urllib
import string
#定义要抓取的页面
url = 'http://www.freebuf.com/articles'
#读取要抓取的页面
globalcontent = urllib.urlopen(url).read()
#捕捉文章列表
#这里在源码中查询"<dt><a href="这个字符串
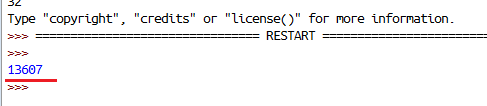
new_inner01_h = globalcontent.find('<dt>a href=')
print news_inner01_h运行结果:可以看到,查到第一篇文章的字符串位置在整个源代码中的第13607个字符,接下来继续查找该文章的url尾部
代码:
import urllib
import string
#定义要抓取的页面
url = 'http://www.freebuf.com/articles'
#读取要抓取的页面
globalcontent = urllib.urlopen(url).read()
#捕捉文章列表
#这里在源码中查询"<dt><a href="这个字符串
new_inner01_h = globalcontent.find('<dt>a href=')
print news_inner01_h
#这里在源码中查询".html"这个字符串
new_inner01_l = globalcontent.find('.html')
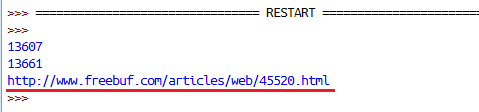
print news_inner01_l运行结果:可以看到,url的结尾位置在第13661个字符上,那么接下来就可以把我想要的真实的文章url地址提取出来

代码:
import urllib
import string
#定义要抓取的页面
url = 'http://www.freebuf.com/articles'
#读取要抓取的页面
globalcontent = urllib.urlopen(url).read()
#捕捉文章列表
#这里在源码中查询"<dt><a href="这个字符串
new_inner01_h = globalcontent.find('<dt>a href=')
print news_inner01_h
#这里在源码中查询".html"这个字符串
new_inner01_l = globalcontent.find('.html')
print news_inner01_l
#这里对文档流进行分片,从查找到的第一篇文章的头部开始,到尾部结束给提取出来
#注意,头部我进行加13,尾部加5,那是因为查找到的指针处于该字符串的开始,如果不做处理那么结果就不是我想要的数据,所以要把指针向前移动
news_inner01 = globalcontent[news_inner01_h+13:news_inner01_l+5]
print news_inner01运行结果:
如下图所示,到这里成功提取出了第一篇文章的url地址,那么后面的事情就好办了,我只需要循环对文档流进行如上操作,得出每一篇文章的地址即可,最后对每一篇文章做处理就行了
以下代码之所以进行异常捕捉,是我发现如果不对异常进行处理,那么,url返回值会多一个空白行,导致不能对抓取到的文章进行处理,所以这里进行异常捕捉,忽略捕捉到的异常
至 此,一个最基本功能的网络爬虫就实现了,当然还可以自己加更多功能,我这里因为我只是写来玩玩,毕竟很晚了,太困了,实在不想写了,想睡觉了,所以就写这 么多了,这里只是一个思路而已,还可以添加很多功能,我这里没有用到面向对象的知识,如果利用面向对象的知识,那么这个爬虫还可以更完善。
import urllib
import string
url = 'http://www.freebuf.com/articles'
globalcontent = urllib.urlopen(url).read()
news_start = globlacontent
cout = 1
while count <= 16:
try:
news_inner_head = news_start.find('<dt><a href=')
news_inner_tail = news_start.find('.html')
news_inner_url = new_start[news_inner_head+13:news_inner_tail+5]
print news_inner_url
news_start = news_start[news_inner_tail+5:]
filename = news_inner_url[-10:]
urllib.urlretrieve(news_inner_url,filename)
count += 1
except:
print 'Download Success!'
finally:
if count == 16:
break好了,不多说 了,上两张效果图,睡觉了!